学习目标
-
了解数据库,能够说出数据库的概念、特点和分类
-
熟悉Flask-SQLAlchemy的安装,能够在Flask程序中独立安装扩展包Flask-SQLAlchemy
-
掌握数据库的连接方式,能够通过设置配置项SQLALCHEMY_DATABASE_URI的方式连接数据库
-
掌握模型的定义,能够在Flask程序中定义模型
-
掌握数据表的创建,能够使用create_all()方法创建数据表
-
掌握模型关系,能够在模型类中定义一对多、一对一、多对多的关系
-
掌握数据操作,能够独立完成增加数据、查询数据、更新数据和删除数据
在开发Web程序时,绝大多数的网页中动态加载的数据通常会存储在数据库中,这样做的目的是将页面层面和数据层面的逻辑进行分离,也就是说涉及页面展示的逻辑交由模板文件处理,涉及数据层面的逻辑交由数据库处理。Flask中提供了一个扩展包Flask-SQLAlchemy,使用该扩展包可以轻松地对数据库进行操作。本章先为大家介绍数据库,再针对扩展包Flask-SQLAlchemy的相关内容进行介绍。
5.1 数据库概述
数据库是按照一定的数据结构组织、存储和管理数据的仓库,它可以被看作电子化的文件柜——存储文件的处所,用户可以对文件中的数据进行增加、删除、修改、查找等操作。值得一提的是,这里所说的数据不仅包括普通意义上的数字,还包括文字、图像、声音等。
大多数初学者会认为数据库就是数据库系统,其实数据库系统的范围要比数据库大很多。数据库系统是指在计算机系统中引入数据库后的系统,除了数据库还包括数据库管理系统、数据库应用程序等。需要说明的是,后续内容提到的数据库均指的是数据库管理系统。
根据存储数据时所用数据模型的不同,当今互联网中的数据库主要分成两大类,分别是关系型数据库和非关系型数据库。
关系型数据库是指采用关系模型(即二维表格模型)组织数据的数据库系统,它主要由数据库、数据表、记录和字段组成。
数据库:数据表的集合,可以包含一个或多个数据表。 数据表:记录的集合。 记录:由若干个字段组成,每条记录相当于表中的一行数据。 字段:每个字段相当于表中的一列数据。

关系型数据库历经了几十年的发展,技术已经非常成熟,这类数据库具有容易理解、操作简单、易于维护的特点,被广泛应用到各行业的数据管理工作中。目前主流的关系型数据库有Oracle、MySQL、IBM Db2、PostgreSQL、SQL Server、Microsoft Access等,其中使用较多的有Oracle和MySQL数据库。
非关系型数据库也被称为NoSQL(Not Only SQL)数据库,相比关系型数据库,非关系型数据库没有固定的结构,它无需事先为要存储的数据建立字段,既可以拥有不同的字段,也可以存储各种格式的数据。 非关系型数据库的优点是易扩展、高读写性能、格式灵活,缺点是对复杂查询的业务支持较差,它只适合存储一些结构比较简单的数据。
非关系型数据库的种类繁多,主要可以分为键值存储数据库、列存储数据库、文档型数据库。
键值存储数据库采用键值结构存储数据,每个键分别对应一个特定的值。这类数据库具有易部署、查询速度快、存储量大等特点,适用于日志系统等。键值存储数据库的典型代表有Redis、Flare、MemcacheDB等。
列式存储数据库采用列式结构存储数据,将同一列数据存储到一起。这类数据库具有查询速度快、可扩展性强等特点,更容易进行分布式扩展,适用于分布式的文件系统。列式存储数据库的典型代表有Hbase、Cassandra等。
文档型存储数据库的结构与键值存储数据库类似,采用文档(如JSON或XML等格式)结构存储数据,每个文档中包含多个键值对。这类数据库的数据结构要求并不严格,具有表结构可变、查询速度更快的特点,适用于Web应用的场景。文档型数据库的典型代表有MongoDB、CouchDB等。
5.2 安装Flask-SQLAlchchemy
Flask-SQLAlchemy是Flask中用于操作关系型数据库的扩展包,该扩展包内部集成了SQLAlchemy,并简化了在Flask程序中使用SQLAlchemy操作数据库的功能。SQLAlchemy是由Python实现的框架,该框架内部封装了ORM和原生数据库的操作,可以让开发人员在不用编写SQL语句的前提下,通过Python对象操作数据库及其内部的数据。
扩展包Flask-SQLAlchemy的安装方式与其他扩展包类似,都是通过pip命令进行安装。例如,在命令行窗口中输入安装Flask-SQLAlchemy扩展包的命令,具体如下所示。
(flask_env) E:\env_space> pip install flask-sqlalchemy
SQLAlchemy一般会让其内部的Dialect组件与数据库API进行交流,并根据不同的配置文件调用不同的数据库API,比如第三方库Pymysql,从而实现对数据库的操作。为此,我们还需要在当前Python环境中安装Pymysql库,具体的安装命令如下所示。
(flask_env) E:\env_space> pip install Pymysql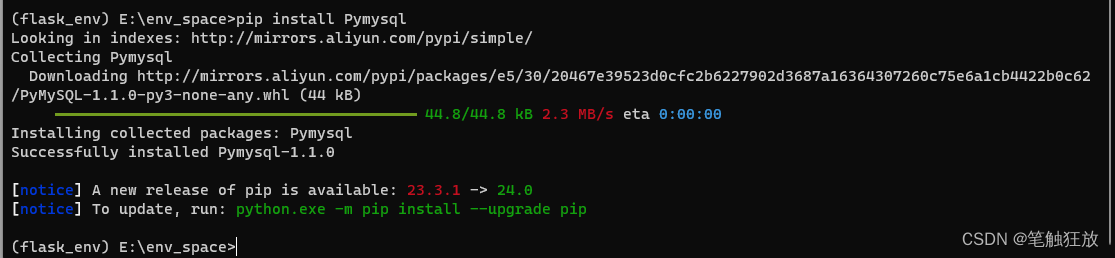
多学一招:ORM
在Web程序中开发人员若使用原生SQL语句操作数据库,主要会存在以下两个问题:
(1)过多的SQL语句会降低代码的易读性,另外也容易出现诸如SQL注入(一种网络攻击方式,它利用开发人员编写SQL语句时的疏忽,使用SQL语句实现无账号登录甚至篡改数据库)等安全问题。 (2)开发人员开发时通常会使用SQLite数据库,而在部署时会切换到诸如MySQL等更为健壮的数据库,由于不同数据库需要用到不同的Python库,所以切换数据库就需要对代码中使用的Python库进行同步修改,增加了一定的工作量。
Python中引入了ORM技术。ORM的全称为Object Relational Mapping,表示对象关系映射,它是一种解决面向对象与关系数据库存在的互不匹配现象的技术,用于实现面向对象编程语言中模型对象到关系数据库数据的映射。 对于Python语言来说,ORM会将底层的SQL语句操作的数据实体转化成Python对象,这样一来,我们无需了解 SQL语句的编写规则,通过Python代码即可完成数据库操作。ORM 主要实现了以下三种映射关系。 数据表→Python类。 字段(列)→类属性。 记录(行)→ 类实例。
5.3 使用Flask-SQLAlchemy操作MySQL
5.3.1 连接数据库
在操作数据库之前,我们需要先建立Flask程序与数据库的连接,这样才能让Flask程序访问数据库,并进一步对数据库中的数据进行操作。Flask 为Flask-SQLAlchemy扩展包提供了一个配置项SQLALCHEMY_DATABASE_URI,该配置项用于指定数据库的连接,它的值是一个有着特殊格式的URI,URI涵盖了连接数据库所需要的全部信息,包括用户名、密码、主机名、数据库名称以及用于额外配置的可选关键字参数。
URI的典型格式如下所示。
dialect+driver://username:password@host:port/databasedialect+driver:表示数据库类型和驱动程序。数据库类型的取值可以为postgresql(PostgreSQL 数据库)、mysql(MySQL数据库)、oracle(Oracle数据库)、sqlite(SQLite数据库)等。如果未指定驱动程序,则说明选择默认的驱动程序,这时可以省略加号。 username:表示数据库的用户名。 password:表示数据库的密码。 host:表示主机地址。 port:表示端口号。 database:表示连接的数据库名。
常见数据库的URI。
| 数据库 | URL |
|---|---|
| PostgreSQL | postgresql://root:123@localhost/flask_data |
| MySQL | mysql://root:123@localhost/flask_data |
| Oracle | oracle://root:123@127.0.0.1:1521/flask_data |
| SQLite(Windows平台) | sqlite:///C:\absolute\path\to\foo.db |
| SQLite(Unix/Mac平台) | sqlite:absolute/path/to/foo.db |
通过一个示例演示如何在Flask程序中连接MySQL数据库。创建一个名称为Chapter05的项目,在该项目中新建app.py文件,并在app.py文件中编写连接MySQL数据库的代码。
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 通过URI连接数据库
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:1234567@localhost/flask_data'db = SQLAlchemy(app)在app.py文件中添加设置SQLALCHEMY_TRACK_MODIFICATIONS配置项的代码,具体代码如下所示。
# 动态追踪数据库的修改,不建议开启
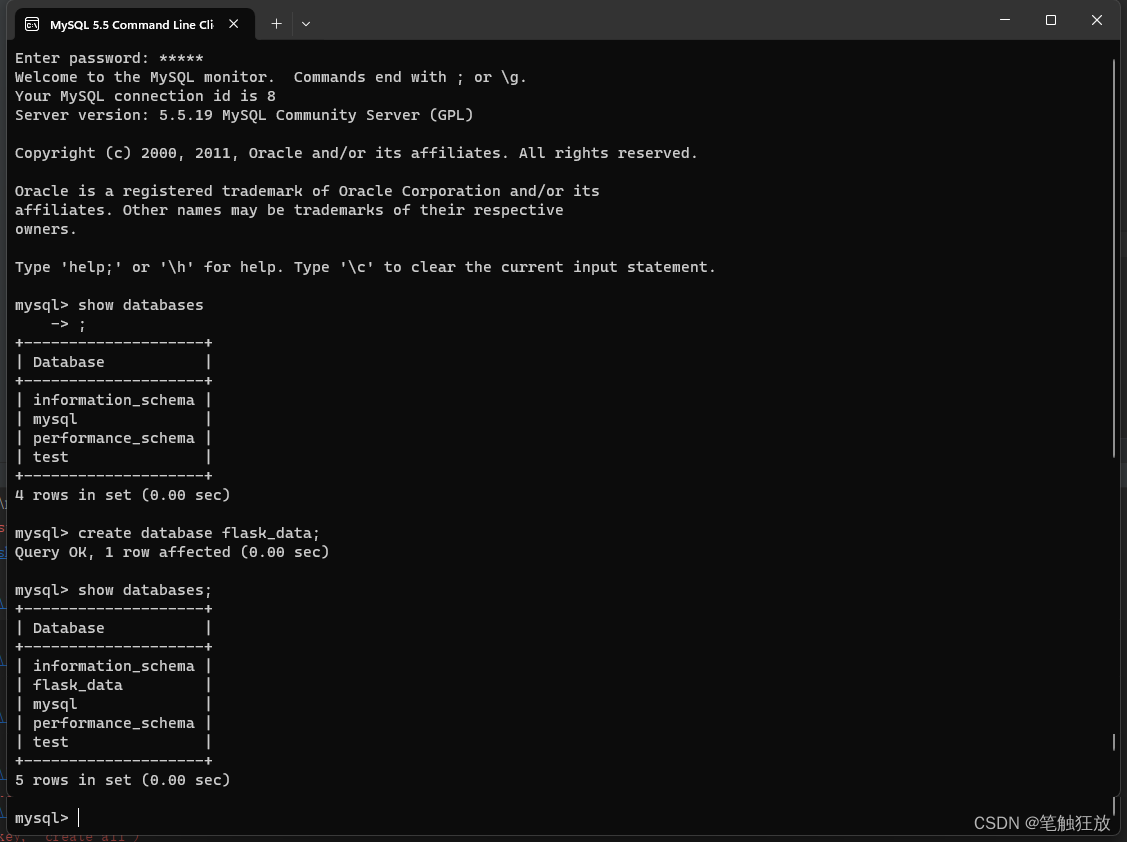
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False由于数据库flask_data还没有被创建,所以我们需要手动创建flask_data数据库,既可以通过MySQL命令的方式进行创建,也可以通过Navicat工具的方式进行创建。
以MySQL的方式创建flask_data数据库,数据库的安装和使用这里不再赘述,其他文章篇幅中已讲解。
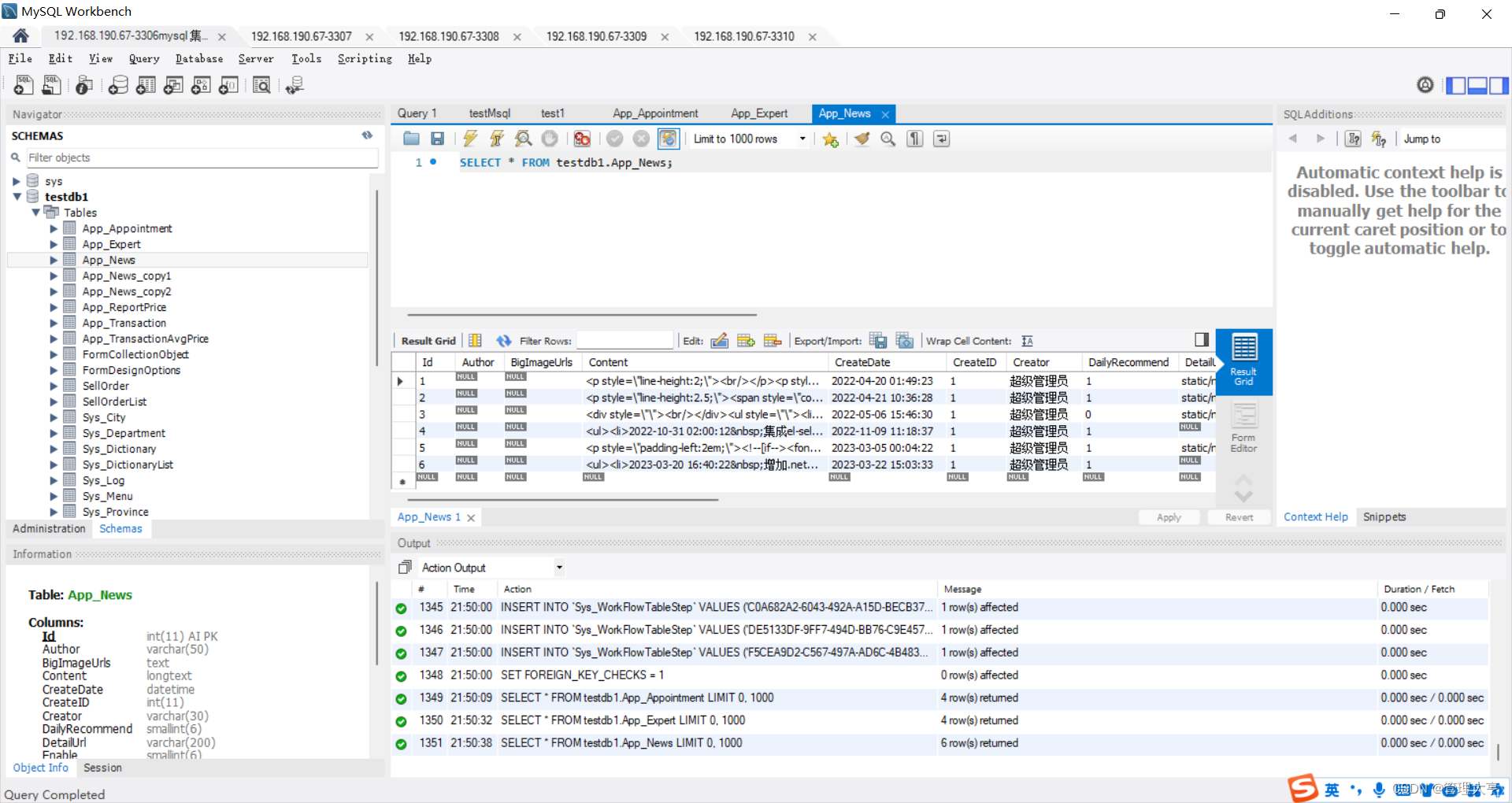
5.3.2 定义模型
Flask中的模型以Python类的形式进行定义,所有的模型类都需要继承Flask-SQLAlchemy提供的基类db.Model,通常保存在Flask程序的model.py文件中。Flask-SQLAlchemy会按照ORM的映射关系将模型类转换成数据表,数据表的名称具体分成以下两种情况: (1)若模型类中包含类属性tablename,则会将类属性tablename的值作为数据表的名称。 (2)若模型类中没有包含类属性tablename,则会将模型类的名称按照一定的规则转换成数据表的名称。 转换的规则主要有两种情况:若模型类的名称是一个单词,则会将所有字母转换为小写的单词作为数据表的名称,例如,模型类User对应的数据表为user;若模型类的名称是多个单词,则会将所有字母转换为小写,以下画线连接的多个单词作为数据表的名称,例如,模型类MyUser对应的数据表为my_user。
定义一个表示用户的模型类User,具体代码如下所示。
from app import dbclass User(db.Model):id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True, nullable=False)email = db.Column(db.String(120), unique=True, nullable=False)在上述代码中,定义了一个继承自db.Model的模型类User,User类中包含id、username和email共3个属性,每个属性的值是db.Column类的对象。db.Column类封装了字段的相关属性或方法。
db.Column类构造方法的声明如下所示。
__init__(name, type_, autoincrement, default, doc, key, index, info, nullable, onupdate, primary_key, server_default, server_onupdate,quote, unique, system, comment, *args, **kwargs)name:表示数据表中此列的名称。若省略,默认使用类属性的名称。 type_:表示字段的类型。若该参数的值为None或省略,则将使用默认类型NullType,表示未知类型。 default:表示为字段设置默认值。 index:表示是否为字段创建索引。 nullable:确定字段的值是否为空,若设置为False,则会在为此列生成DDL时加上NOT NULL语句;若设置为True,通常不会生成任何内容。 primary_key:表示是否将字段设置为主键,若设为True,则会将此列标记为主键列。多个列可以设置此标志以指定复合主键。 unique:表示该字段是否具有唯一约束,若设为True,则该字段将不允许出现重复值。 *args:其他位置参数,该参数的值可以为Constraint(表级SQL约束)、ForeignKey(外键)、ColumnDefault、Sequence和Computed Identity类实例。
db.Column类构造方法的type_参数用于指定字段的类型,比如User类中的Integer和String都属于字段类型。常用的字段类型如下表所示。
| 字段类型 | 说明 |
|---|---|
| Integer | 整数 |
| String(size) | 字符串,可通过size设置最大长度 |
| Text | 较长的Unicode文本 |
| DateTime | 日期和时间,存储Python的 datetime对象 |
| Float | 浮点数 |
| Boolean | 布尔值 |
| PickleType | 存储Pickle列化的Python对象 |
| LargeBinary | 存储任意二进制数据 |
若字段的类型为String,则建议为其指定长度,这是因为有些数据库会要求限制字符串的长度。
5.3.3 创建数据表
定义了模型类以后,如果希望根据模型类生成一个对应的数据表,这时我们可以通过db对象调用create_all()方法实现。以定义的模型类User为例,演示如何通过create_all()方法创建数据表。在命令行窗口中进入虚拟环境,输入flask shell命令启用Flask Shell工具,在该工具中输入创建数据表的命令,具体命令如下所示。
执行创建数据表命令后,会在数据库flask_data中增加一张名称为user的数据表。为了能够直观看到user表的结构,我们可以在Navicat工具中打开user表。user表的结构如下图所示。
数据表中的每个字段对应着模型类User中的每个属性。若希望删除数据表,则可以通过db对象调用drop_all()方法实现。
5.3.4 模型关系
在MySQL数据库中,我们可以通过关系让不同数据表之间的字段建立联系,数据表的关系包括一对多关系、一对一关系和多对多关系,模型类之间也需要根据实际需要建立这些关系。在Flask的模型类中,建立关系一般需要两步实现,分别是创建外键和定义关系属性。
1.创建外键
外键是数据表的一个特殊字段,它经常与主键约束一起搭配使用,用于将两张或多张数据表之间进行关联。对于两张有关联关系的数据表来说,关联字段中主键所在的表就是主表(也称为父表),外键所在的表就是从表(也称为子表)。 当在模型类中通过Column类的构造方法创建字段时,可以传入一个db.ForeignKey类的对象,用于将关联表中的字段指定为外键。db.ForeignKey类的构造方法中必须传入一个column参数,column参数表示外键关联表的字段,该参数支持两种取值,第1种取值是_schema.Column类的对象,第2种取值为包含字段名称的字符串,字符串的格式为“数据表名.字段名”或“schema.数据表名.字段名”。
2.定义关系属性
定义关系属性通过db.relationship()函数实现。大多数情况下,db.relationship()函数能够自行找到关系中的外键,但在关系另一侧的模型类中有两个或两个以上的外键时无法决定将哪个字段作为外键。此时,我们根据需要可以给db.relationship()函数传入相应的参数,从而确定所用的外键。
db.relationship()函数中常用参数如下所示。 argument:表示关系建立的另一侧模型类的名称。 back_populates:定义反向引用,用于建立数据表之间的双向关系。 backref:添加反向引用,自动在另一侧建立关系属性。 primaryjoin:明确指定两个模型之间使用的联结条件,只在模棱两可的关系中需要指定。
db.relationship()函数中常用参数如下所示。 lazy:用于指定加载相关记录的方式,默认值为'select',代表在必要时一次性加载全部记录,作用等同于lazy=True。 order_by:指定加载相关记录时的排序方式。 secondary:表示多对多关系中指定的关联表。 uselist:指定是否使用列表的形式加载记录。若设为False,则会用标量的形式加载记录。
使用示例演示Flask-SQLAlchemy建立模型之间的一对多、一对一、多对多关系。
一个用户可以发表多篇文章,反过来讲一篇文章只能属于一个用户,像用户与文章之间的对应关系就是一对多关系。在模型类中定义一对多关系时,一般是在“多”这一侧对应的模型类中创建外键,在“一”这一侧对应的模型类中定义关系属性。
定义分别表示用户和文章的类User和Article,在“一”这一侧的User类中定义关系属性,在“多”这一侧对应的Article类中创建外键,具体代码如下所示。
class User(db.Model):id = db.Column(db.Integer, primary_key=True)username = db.Column(db.String(80), unique=True, nullable=False)email = db.Column(db.String(120), unique=True, nullable=False)# 定义关系属性article = db.relationship("Article", backref='user', lazy='dynamic')class Article(db.Model):id = db.Column(db.Integer, primary_key=True)title = db.Column(db.String(20), nullable=False)# 创建外键author_id = db.Column(db.Integer, db.ForeignKey('user.id'))使用示例演示Flask-SQLAlchemy建立模型之间的一对多、一对一、多对多关系。
一个国家只能有一个总统,一个总统也只能属于一个国家,像国家与总统之间的对应关系就是一对一关系。在定义一对一关系时,我们需要确保关系两侧的模型类中的关系属性都是标量属性,也就是说调用db.relationship()函数时需要将uselist参数的值设为False。
定义分别表示国家和总统的类Country和President,在Country和President类中定义关系属性,并设置以标量的形式加载记录,具体代码如下所示。
class Country(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(80), unique=True, nullable=False)# 定义关系属性,并以标量的形式加载记录president = db.relationship("President", back_populates='country', uselist=False)
class President(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(20), unique=True)# 创建外键country_id = db.Column(db.Integer, db.ForeignKey('country.id'))# 定义关系属性,并以标量的形式加载记录president = db.relationship("Country", back_populates='president')使用示例演示Flask-SQLAlchemy建立模型之间的一对多、一对一、多对多关系。
每个学生可以有多个老师,而每个老师也可以有多个学生,像学生与老师的这种对应关系就是多对多的关系。定义多对多关系时,由于每个记录可以与关系另一侧的多个记录建立关系,所以关系两侧的模型中都需要存储一组外键。 为了降低多对多关系的难度,我们可以创建一个关联表,通过这个关联表来存储关系两侧模型类的外键对应关系,而不会存储任何数据。在SQLAlchemy中,关联表使用db.Table类定义,当使用db.Table类的构造方法实例化对象时需要传入关联表的名称。
先定义分别表示老师和学生的类Teacher和Student,在Teacher和Student类中分别定义关系属性,并设置以标量的形式加载记录,再定义一个关联表,具体代码如下所示。
# 创建关联表
association_table = db.Table('association',db.Column('student_id', db.Integer,db.ForeignKey('student.id'),db.Column('teacher_id', db.Integer, db.ForeignKey('teacher.id'),primary_key=True))
class Student(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(20), unique=True)gender = db.Column(db.String(10), nullable=False)teacher = db.relationship('Teacher', secondary=association_table,back_populates='student')
class Teacher(db.Model):id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(20), unique=True)5.4 数据操作
5.4.1 增加数据
在Flask-SQLAlchemy中,db.session提供了增加数据的add()和add_all()方法,其中add()方法用于向数据库中增加一条记录,add_all()方法用于向数据库中增加多条记录。
from flask import Flask
import pymysql
app = Flask(__name__)"""
5.4.1 增加数据
"""
@app.route("/")
def hello_flask():# 获得数据库连接con = pymysql.connect(host="127.0.0.1", port=3306,user="root", password="admin",db="flask_data", charset="utf8")# 获得游标cursor=con.cursor()# 执行添加操作cursor.execute("insert into user values(%s,%s,%s)",("0","小明","123@qq.com"))cursor.execute("insert into user values(%s,%s,%s)", ("0", "小红", "456@qq.com"))cursor.execute("insert into user values(%s,%s,%s)", ("0", "小王", "789@qq.com"))con.commit()return "OK"
if __name__ == "__main__":app.run()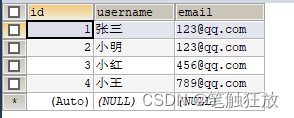
5.4.2 查询数据
通过示例演示如何使用这些方法查询数据库flask_data中的记录,具体代码如下所示。
from flask import Flask, render_template
import pymysql
app = Flask(__name__)@app.route("/select")
def hello_flask():# 获得数据库连接con = pymysql.connect(host="127.0.0.1", port=3306,user="root", password="admin",db="flask_data", charset="utf8")# 获得游标cursor=con.cursor()# 执行查询操作cursor.execute("select * from user")users=cursor.fetchall()return render_template("home.html",users=users)if __name__ == "__main__":app.run()<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<table border="1" style="border-collapse: collapse;width: 400px;text-align: center"><tr><th>学号</th><th>用户名</th><th>邮箱</th></tr>{% for user in users %}<tr><td>{{user[0]}}</td><td>{{user[1]}}</td><td>{{user[2]}}</td></tr>{% endfor %}</table>
</body>
</html>
5.4.3 更新数据
更新数据的方式比较简单,它只需要为模型类的字段重新赋值便可以将字段原先的值进行修改,修改完成后需要调用commit()方法提交至数据库。
例如,将数据库flask_data中的主键值为2的记录中字段username的值由小明修改为小兰,具体代码如下所示。
from flask import Flask, render_template
import pymysql
app = Flask(__name__)@app.route("/update")
def hello_flask():# 获得数据库连接con = pymysql.connect(host="127.0.0.1", port=3306,user="root", password="admin",db="flask_data", charset="utf8")# 获得游标cursor=con.cursor()# 执行查询操作cursor.execute("update user set username=%s where id=2",("小兰"))con.commit()return "修改成功"if __name__ == "__main__":app.run()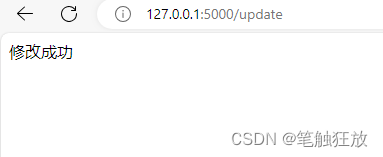

5.4.4 删除数据
删除数据可以使用数据库会话提供的delete()方法,删除完成后同样需要调用commit()方法提交至数据库。
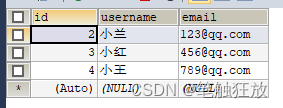
例如,将数据库flask_data中的id值为1的记录直接删除,具体代码如下所示。
from flask import Flask, render_template
import pymysql
app = Flask(__name__)@app.route("/delete")
def hello_flask():# 获得数据库连接con = pymysql.connect(host="127.0.0.1", port=3306,user="root", password="admin",db="flask_data", charset="utf8")# 获得游标cursor=con.cursor()# 执行查询操作cursor.execute("delete from user where id=%s",("1"))con.commit()return "删除成功"if __name__ == "__main__":app.run()
5.5 本章小结
本章围绕着数据库操作的相关内容进行了讲解,重点讲解了如何使用Flask-SQLAlchemy扩展包操作数据库,包括连接数据库、定义模型、创建数据表和模型关系。通过学习本章的内容,希望读者能够使用Flask-SQLAlchemy熟练地操作数据库,为后续开发真实项目打好扎实的基础。