论文标题:VIMA: General Robot Manipulation with Multimodal Prompts
论文作者:Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, Linxi Fan
作者单位:Stanford; Macalester College, now at Allen Institute for AI; NVIDIA; Caltech; Tsinghua; UT Austin
论文原文:https://arxiv.org/abs/2210.03094
论文出处:ICML 2023
论文被引:112(01/05/2024)
项目主页:https://vimalabs.github.io/
论文代码:https://github.com/vimalabs/VIMA,590 star
Abstract
基于提示(prompt)的学习已经成为自然语言处理领域的一个成功范例,在这种范例中,一个通用语言模型可以在输入提示的指示下执行任何指定任务。然而,机器人技术中的任务指定有多种形式,例如模仿单次演示,遵循语言指令和到达视觉目标。它们通常被视为不同的任务,并由专门的模型来处理。我们的研究表明,机器人的各种操作任务都可以用多模态提示来表达,文字和视觉标记(tokens)交织在一起。因此,我们开发了一个新的模拟基准,其中包括数千个程序化生成的带有多模态提示的桌面任务,用于模仿学习的 600K+ 专家轨迹,以及用于系统泛化的四级评估协议。我们设计了一个基于Transformer的机器人智能体(Agent)VIMA,它能处理这些提示并自动输出运动动作。VIMA 采用的配方具有很强的模型可扩展性和数据效率。在训练数据相同的情况下,它在最难的零样本泛化设置中的任务成功率最高可达 2.9 倍,优于其他设计。在训练数据减少 10 倍的情况下,VIMA 的表现仍比最佳竞争变体高出 2.7 倍。
1. Introduction
Transformer模型已经在许多人工智能领域实现了显著的多任务整合。例如,用户可以使用自然语言提示向 GPT-3 描述一项任务,让同一个模型执行问题解答,机器翻译,文本总结等任务。基于提示的学习提供了一个方便灵活的接口(interface),可将自然语言理解任务传达给通用模型。
我们设想,通用机器人应该有一个类似的直观而又富有表现力的任务指定接口。这样的机器人学习接口是什么样的呢?作为一个激励性的例子,我们不妨考虑一个负责家务活动的个人机器人。我们可以用简单的自然语言指令让机器人给我们倒一杯水。如果我们需要更具体的指令,我们可以指示机器人 “bring me ”。对于需要新技能的任务,机器人应该能够适应,最好是通过一些视频演示。对于需要与不熟悉的物体进行交互的任务,可以通过一些图像示例进行简单解释,以实现新概念的执行(grounding)。最后,为了确保安全部署,我们可以进一步指定视觉约束,如 “do not enter room”。
为了使单个Agent具备所有这些能力,我们在这项工作中做出了三大贡献:
- 1)新颖的多模态提示表述,可将广泛的机器人操作任务转换为一个序列建模问题;
- 2)具有不同任务的大规模基准,可系统地评估Agent的可扩展性和泛化能力;
- 3)多模态提示机器人Agent能够胜任多任务和零样本泛化。
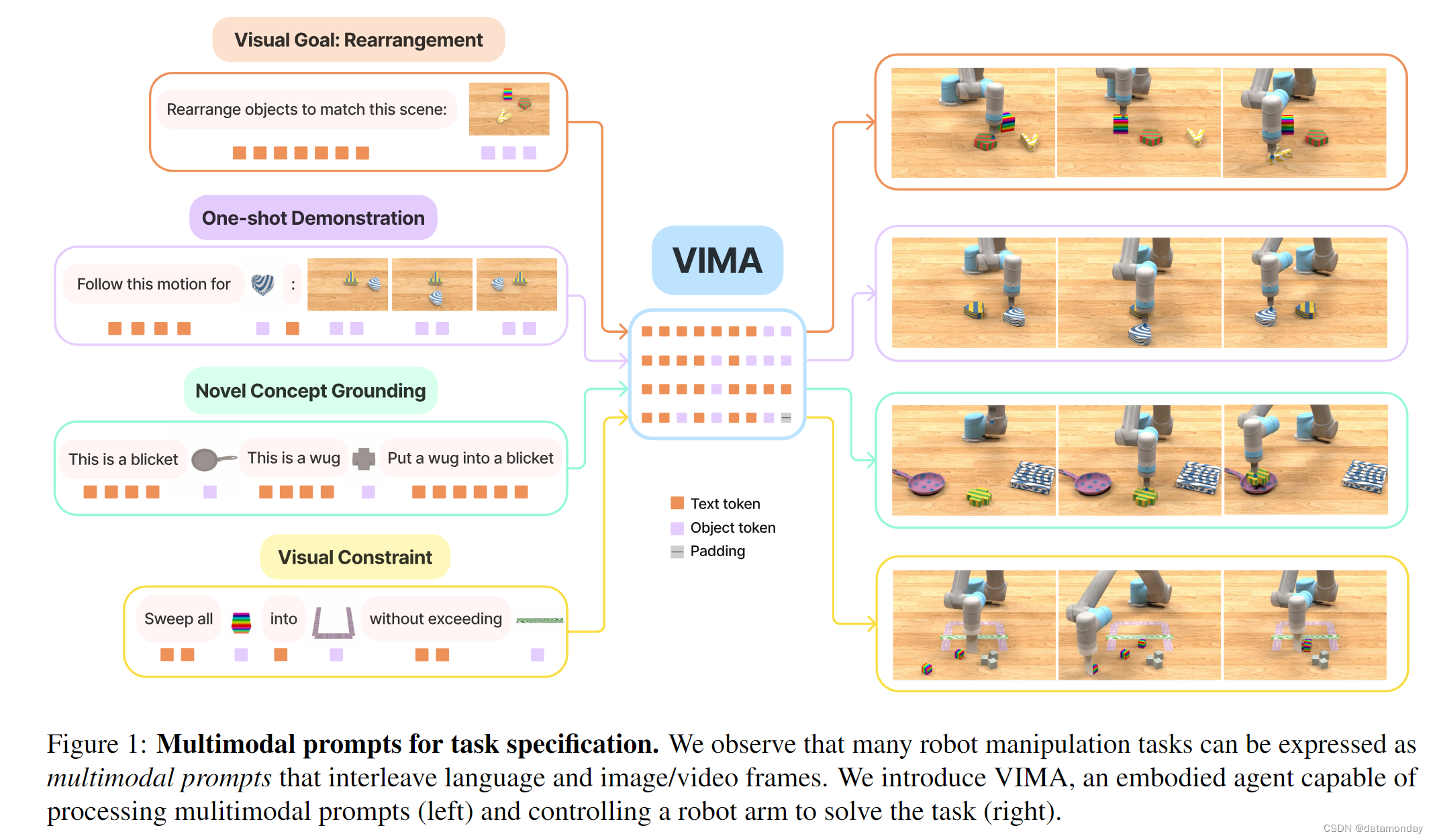
我们首先发现,许多机器人操作任务都可以通过语言与图像或视频帧交错的多模态提示来制定(图 1)。例如,Rearrangement 是视觉目标的一种,可以表述为 “Please rearrange objects to match this {scene image}”;Few-shot Imitation 可以在提示中嵌入视频片段:"“Follow this motion trajectory for the wooden cube:{frame1}, {frame2}, {frame3}, {frame4}”。多模态提示不仅比单个模态具有更强的表现力,还能为通用机器人的训练提供统一的序列 IO 接口。以前,不同的机器人操作任务需要不同的策略架构,目标函数,数据管道和训练程序,这就导致机器人系统各自为政,无法轻松地组合出丰富的使用案例。相反,我们的多模态提示接口使我们能够利用大型Transformer模型的最新进展,开发可扩展的多任务机器人学习器。
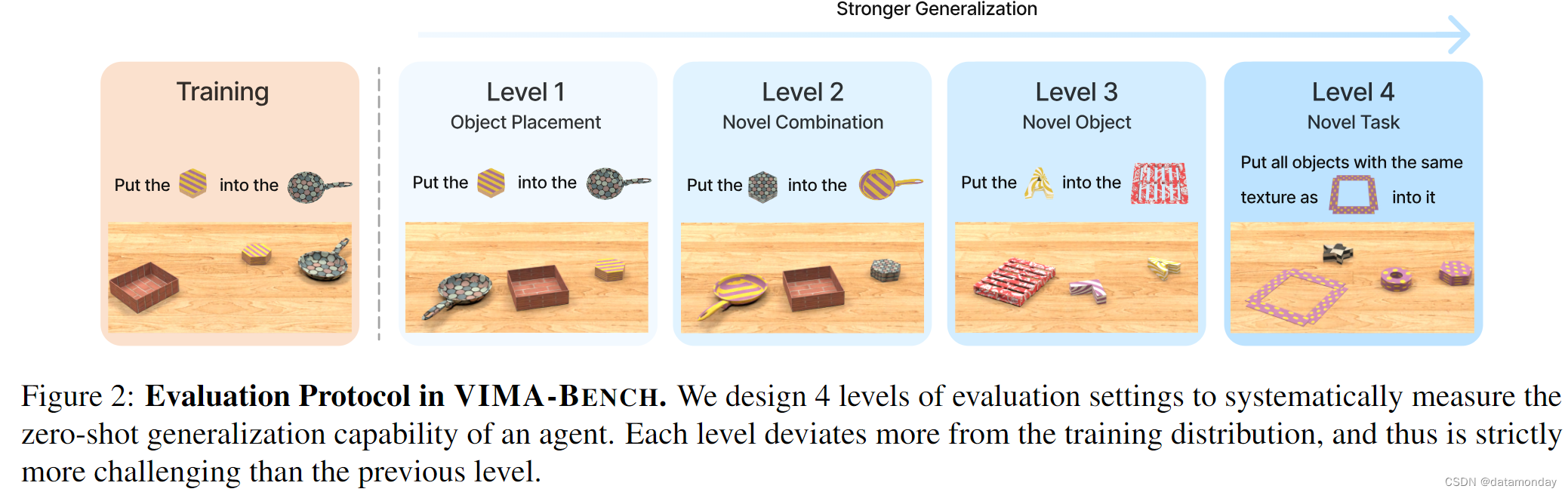
为了系统地评估使用多模态提示的Agent,我们在 Ravens 模拟器上开发了一个名为 VIMA-BENCH 的新基准。我们提供了 17 个带有多模态提示模板的代表性任务。每个任务都可以通过纹理和桌面物体的不同组合,程序化地实例化为数千个实例。VIMA-BENCH 建立了一个四级协议,以评估从随机物体放置到新任务的逐步增强的泛化能力(图 2)。
为此,我们引入了 VisuoMotor Attention agent(VIMA),以便从多模态提示中学习机器人操作。该模型架构采用了在 NLP 中被证明有效且可扩展的编码器-解码器Transformer设计。VIMA 使用预先训练好的语言模型对交错的文本和视觉提示标记的输入序列进行编码,并对每个环境交互步骤的机器人控制动作进行自回归解码。Transformer解码器通过交叉注意层与通常的因果自我注意交替进行提示。VIMA 采用以物体为中心的方法,而不是对原始图像进行处理。我们通过现成的,经过领域微调的检测器将提示或观察中的所有图像解析为物体,并将其平铺为物体标记序列。为了证明 VIMA 的可扩展性,我们训练了从 200 万到 2 亿个参数的 7 个模型。我们的方法优于其他设计方案,如 image patch tokens,image Perceiver 和 decoder-only conditioning。VIMA 在所有四个级别的零样本泛化和所有模型能力方面都获得了一致的性能提升,在某些情况下提升幅度还很大(在训练数据量相同的情况下,任务成功率可达 2.9 倍,即使数据量少 10 倍,也能提高 2.7 倍)。我们开源了仿真环境,训练数据集,算法代码和预训练模型检查点,以确保可重复性并促进社区未来的工作。这些资料和视频演示可在 vimalabs.github.io 上获取。
2. Multimodal Prompts for Task Specification
机器人学习的一个核心问题是任务规范。在之前的文献中,不同的任务往往需要不同的,不兼容的接口,导致机器人系统各自为政,不能很好地在不同任务间通用。我们的主要见解是,各种任务规范范式(如目标条件,视频演示,自然语言指令)都可以实例化为多模态提示(图 1)。具体来说,长度为 l 的多模态提示 P 被定义为任意交错的文本和图像的有序序列 P := [x1, x2, … , xl],其中每个元素 xi ∈ {text, image}。
Task Suite.
多模态提示所提供的灵活性使我们能够为各种任务规范格式指定和建立模型。在此,我们将考虑以下六个类别。
- Simple object manipulation。简单的任务,如 “put into ”,提示中的每个图像对应一个物体;
- Visual goal reaching。操作物体以达到目标配置,如重新排列 (Batra et al., 2020)
- Novel concept grounding。提示中包含 “dax” 和 “blicket” 等不熟悉的单词,提示中的图像对这些单词进行了解释,然后立即用于指令中。这可以测试 Agent 快速内化新概念的能力;
- One-shot video imitation。观看视频演示并学习对特定物体复制相同的运动轨迹;
- Visual constraint satisfaction。机器人必须小心操作物体,避免违反(安全)约束条件;
- Visual reasoning。需要推理技能的任务,如外观匹配 “move all objects with same textures as into ”,以及视觉记忆 “put in and then restore to their original position”。
请注意,这六个类别并不相互排斥。例如,一项任务可能会通过播放视频演示来介绍一个以前从未见过的动词(新概念),或者将目标达成与视觉推理相结合。有关任务套件的更多详情请参见附录 B 部分。
3. VIMA-BENCH: Benchmark for Multimodal Robot Learning
Simulation Environment.
现有的基准通常针对特定的任务规范。据我们所知,目前还没有一个基准可以提供丰富的多模态任务套件和全面的测试平台,用于有针对性地探测机器人的能力。为此,我们推出了一套新的多模态机器人学习基准,名为 VIMA-BENCH。我们通过扩展机器人模拟器 Ravens,VIMA-BENCH 支持物体和纹理的可扩展集合,以组成多模态提示并按程序生成大量任务。具体来说,我们提供了 17 个具有多模态提示模板的任务,这些模板可实例化为数千个任务实例。每个任务都属于上述 6 个任务类别中的一个或多个。VIMA-BENCH 可以通过脚本 Oracle Agent 生成大量的模仿学习数据。更多详情见附录 A 部分。
Observation and Actions.
我们模拟器的观测空间包括从正面和俯视渲染的 RGB 图像。我们还提供了真实物体分割和边界框,用于训练以物体为中心的模型(第 4 章)。我们继承了 Zeng 等人的高层次动作空间,其中包括 “pick and place” 和 “wipe” 等原始运动技能。这些技能的参数由终端执行器的姿态决定。我们的模拟器还具有脚本Oracle程序,可通过使用特许模拟器状态信息(如所有物体的精确位置)和多模态指令的解释生成专家示范。
Training Dataset.
我们利用Oracle生成了一个大型离线专家轨迹数据集,用于模仿学习。我们的数据集包括每个任务的 50K 条轨迹,以及总共 650K 条成功轨迹。我们保留了一个物体和纹理子集进行评估,并指定 17 个任务中的 4 个作为零样本泛化的试验平台。
Evaluating Zero-Shot Generalization.
VIMA-BENCH 中的每个任务都有一个二进制成功标准,并且不提供部分奖励。在测试期间,我们会在模拟器中执行多个Agent策略,以计算成功率百分比。所有评估任务的平均成功率将是最终报告的指标。
我们设计了一个四级评估协议(图 2),以系统地探测学习Agent的泛化能力。每一级都偏离训练分布更多,因此难度严格高于前一级。
- 摆放泛化。在训练过程中,所有提示都会被逐字看到,但在测试时,只有桌面上物体的摆放位置是随机的;
- 组合泛化。所有纹理和物体在训练中都会出现,但在测试中会出现新的组合;
- 新物体泛化。测试提示和模拟工作区包括新的纹理和物体;
- 新任务泛化。测试时使用新提示模板的新任务。
4. VIMA: Visuomotor Attention Agent
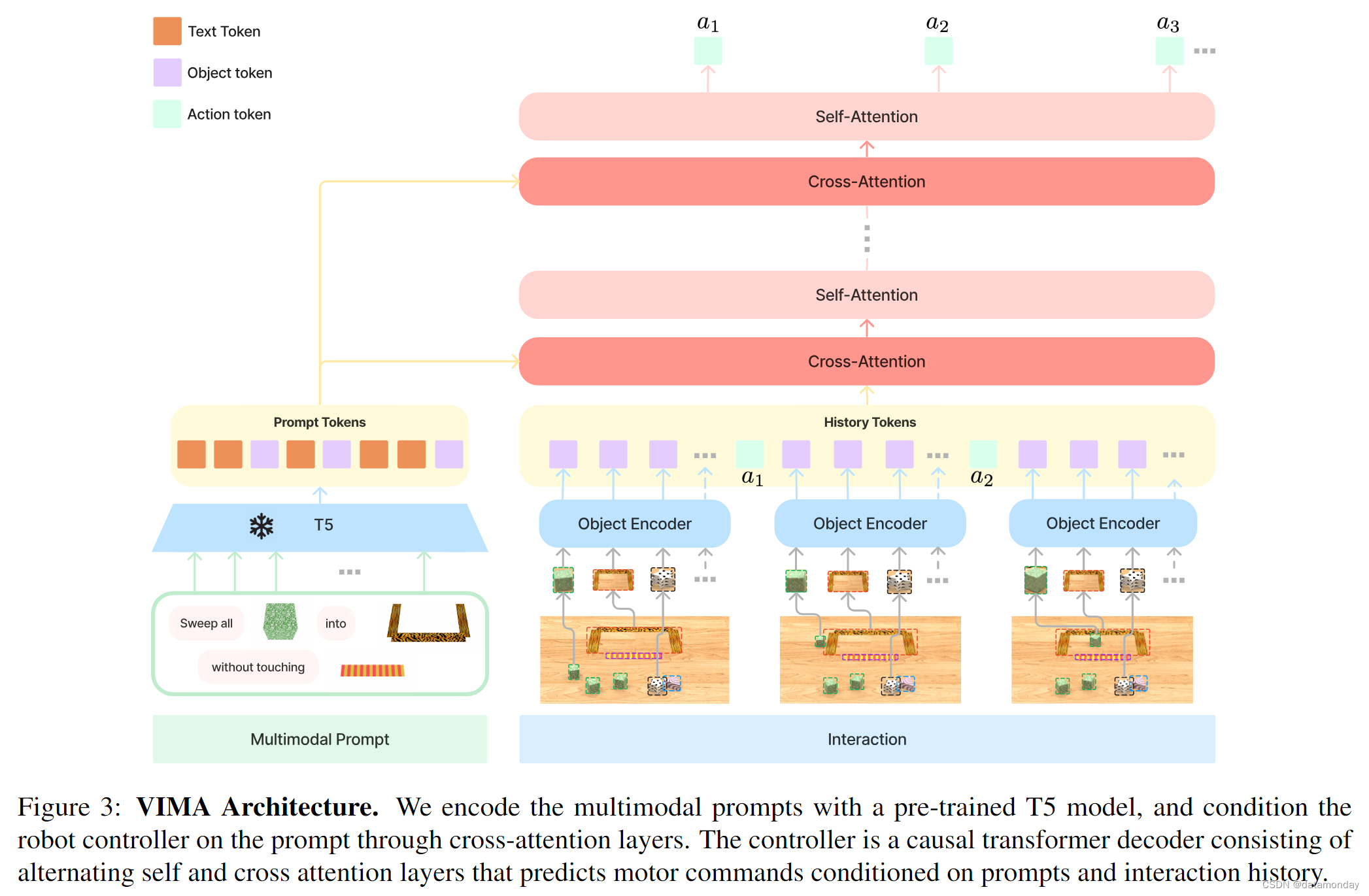
我们的目标是建立一个机器人Agent,能够执行多模态提示指定的任何任务。目前还没有一种方法能在开箱即用的情况下执行多模态提示。为了学习有效的多任务机器人策略,我们提出了 VIMA,一种采用多任务编码器-解码器架构和以物体为中心设计的机器人Agent(图 3)。具体来说,我们学习机器人策略 π ( a t ∣ P , H ) π(at_|P, H) π(at∣P,H),其中 H : = [ o 1 , a 1 , o 2 , a 2 , . . . , o t ] \mathcal{H} := [o_1, a_1, o_2, a_2, ..., o_t] H:=[o1,a1,o2,a2,...,ot] 表示过去的交互历史,ot ∈ O, at ∈ A 表示每个交互步骤的观察结果和行动。我们通过一个冻结的预训练语言模型对多模态提示进行编码,并通过交叉注意层对以编码提示为条件的机器人航点指令进行解码。与之前的工作不同,VIMA 采用了以物体为中心的表示方法,通过边界框坐标和裁剪的 RGB 补丁来计算标记。
Tokenization.
提示中的原始输入有三种格式:文本,单个物体的图像和完整桌面场景的图像(例如,用于重排或模仿视频帧)。对于文本输入,我们使用预先训练好的 T5 标记化器和词嵌入来获取词标记。对于完整场景的图像,我们首先使用域微调 Mask R-CNN 提取单个物体(附录 C.4 节)。每个物体都以边界框和裁剪图像的形式表示。然后,我们分别用边界框编码器和 ViT 对它们进行编码,从而计算出物体标记。由于 Mask R-CNN 并不完善,因此边界框可能存在噪声,裁剪后的图像也可能存在无关像素。对于单个物体的图像,我们用同样的方法获取标记,只不过使用了一个虚边界框。即时标记化会产生一系列交错的文本和视觉标记。然后,我们按照 Tsimpoukelli 等人的做法,通过预先训练好的 T5 编码器对提示进行编码。由于 T5 编码器已在大型文本语料库中进行过预先训练,因此 VIMA 继承了 T5 编码器的语义理解能力和鲁棒性。为了适应新模态的标记,我们在非文本标记和 T5 之间插入了 MLP。
Robot Controller.
设计多任务策略的一个挑战在于选择合适的调节机制。在我们的方案中(图 3),机器人控制器(解码器)通过 P 和轨迹历史序列 H 之间的一系列交叉注意层对提示序列 P 进行调节。我们按照 Raffel 等人的编码器-解码器惯例,从提示序列中计算键 KP 和值 VP 序列,从轨迹历史序列中计算查询 QH。然后,每个交叉注意层生成一个输出序列:

其中 d 是嵌入维度。剩余连接被添加到更高层与输入滚动轨迹序列的连接中。交叉注意设计有三个优点: 1) 加强与提示符的连接;2) 原提示符的完整和深度流动;3) 更高的计算效率。VIMA 解码器由 Lalternating 交叉注意层和自注意层组成。最后,我们按照惯例 Baker 等人将预测的动作标记映射到机器人手臂的离散姿态。详见附录 C.2 节。
Training.
我们按照行为克隆的方法,通过最小化预测行动的负对数似然来训练模型。具体来说,对于有 T 个步骤的轨迹,我们优化 m i n θ ∑ t = 1 T − l o g π θ ( a t ∣ P , H ) min_θ \sum^T_{t=1} - log π_θ (a_t|P, H) minθ∑t=1T−logπθ(at∣P,H)。整个训练都是在离线数据集上进行的,不允许访问模拟器。为了使 VIMA 对检测不准确和失败具有鲁棒性,我们通过随机注入假阳性检测输出来进行物体增强。训练结束后,我们会根据保留验证集上的综合准确率选择模型检查点进行评估。评估涉及与物理模拟器的交互。我们遵循最佳实践来训练Transformer模型。有关全面的训练超参数,请参见附录 D 章。
5. Experiments
在本节中,我们旨在回答三个主要问题:
- 构建基于Transformer的多任务,多模态提示机器人Agent的最佳方法是什么?
- 我们的方法在模型容量和数据大小方面有哪些扩展特性?
- 视觉标记器,提示条件和提示编码等不同组件对机器人性能有何影响?
5.1. Baselines
由于目前还没有一种方法能与我们的多模态提示设置兼容,因此我们尽最大努力选择了一些具有代表性的基于Transformer的Agent架构作为基线,并对其进行了重新解释,使其与 VIMA-BENCH 兼容:
Gato 引入了一个纯解码器模型,可解决多个领域的任务,其中任务是通过向模型提示观察和动作子序列来指定的。为了进行公平比较,我们提供了与 VIMA 相同的条件,即我们的多模态编码提示。输入图像被分割成不同的片段,并由 ViT 模型进行编码,生成观察标记。这种变体被称为 VIMA-Gato。
Flamingo 是一种视觉语言模型,可根据多模态提示学习生成文本补全。它通过 Perceiver 将数量可变的提示图像嵌入到固定数量的标记中,并通过交叉注意将语言解码器设定为编码提示的条件。Flamingo 并不能直接与具身Agent协同工作。我们将其调整为支持决策,用机器人行动头取代输出层。我们将这种方法命名为 VIMA-Flamingo。
VIMA-GPT 是一种以标记化多模态提示为条件的纯解码器架构。它能根据指令和交互历史自动回归解码下一步操作。与之前的工作类似,它通过 ViT 编码器将图像编码为单个状态标记,并在滚动轨迹前加上提示标记。该基线不使用交叉注意。
这些变体之间更详细的比较见附录 C.1 节。
5.2. Evaluation Results
我们将 VIMA 与基准变体进行了比较,在不同模型和训练数据集大小的情况下,VIMA 的泛化程度达到了基准变体的四个水平。我们的实证结果表明,在我们所考虑的模型设计中,VIMA 对物体标记的选择与交叉注意条件的结合是最有效的方法。
Model Scaling.
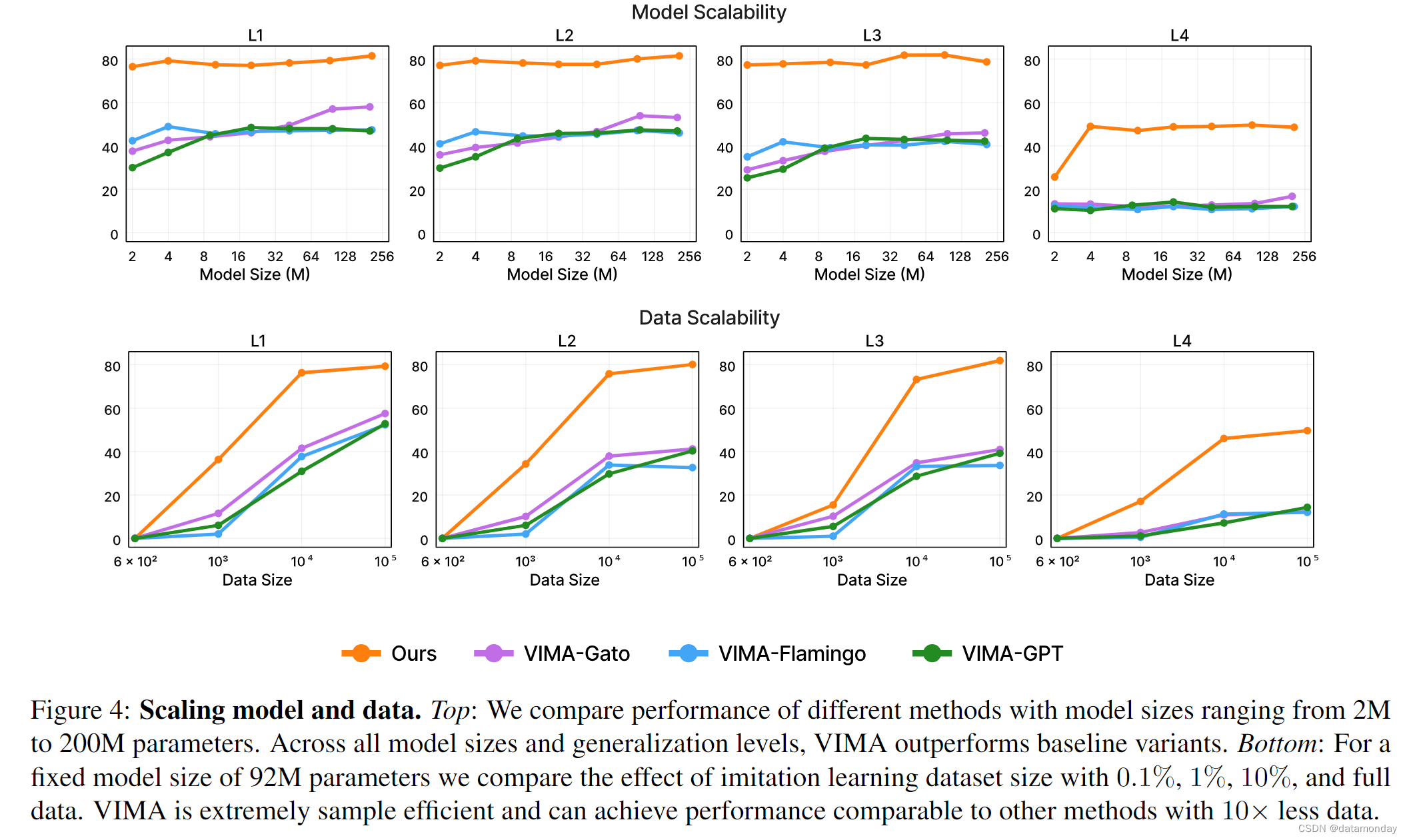
我们对所有方法进行了训练,模型容量从 200 万到 2 亿个参数不等,在对数尺度上均匀分布(图 4)。所有方法的编码器大小保持不变(T5-Base,1.11 亿),并且不计入参数数。我们发现,在所有级别的零样本泛化中,VIMA 都大大优于其他替代方法。虽然 VIMA-Gato 和 VIMA-Flamingo 等模型的性能随着模型规模的增大而提高,但 VIMA 在所有模型规模下都始终保持着优异的性能。我们注意到,这只能通过交叉注意力和物体标记序列表示法来实现——改变任何部分都会显著降低性能,尤其是在模型容量较低的情况下(第 5.3 节中的消融)。
Data Scaling.
接下来,我们研究了不同方法在不同数据集规模下的扩展情况。我们比较了模型在 0.1%,1%,10% 和 VIMA-BENCH 提供的全部模仿学习数据集上的性能(图 4)。需要注意的是,为了确保所有方法都在相同数据量上进行了公平的预训练,我们使用 MVP 预训练 ViT 对直接从原始像素学习的基线变体进行了初始化。使用与 Mask R-CNN 物体检测器相同的域内数据,进一步对其进行 MAE 微调。详细设置见附录 E.3 节。VIMA 的采样效率极高,在 L1 和 L2 泛化水平上,仅用 1%的数据就能达到与用多 10 倍数据训练的基线方法相似的性能。事实上,在 L4 级,我们发现只需 1%的训练数据,VIMA 就能超越使用整个数据集训练的其他变体。最后,在所有级别中,只需 10%的数据,VIMA 就能以显著的优势超越使用全部数据集训练的其他架构。我们推测,数据效率可归因于 VIMA 配方中采用的以物体为中心的表示方法,在低数据量时,这种方法比直接从像素学习更不容易出现过拟合。这与 Sax 等人的研究结果一致,该研究表明,以中层视觉表征为条件的具身Agent往往比从原始像素进行端到端控制的样本效率要高得多。
Progressive Generalization.
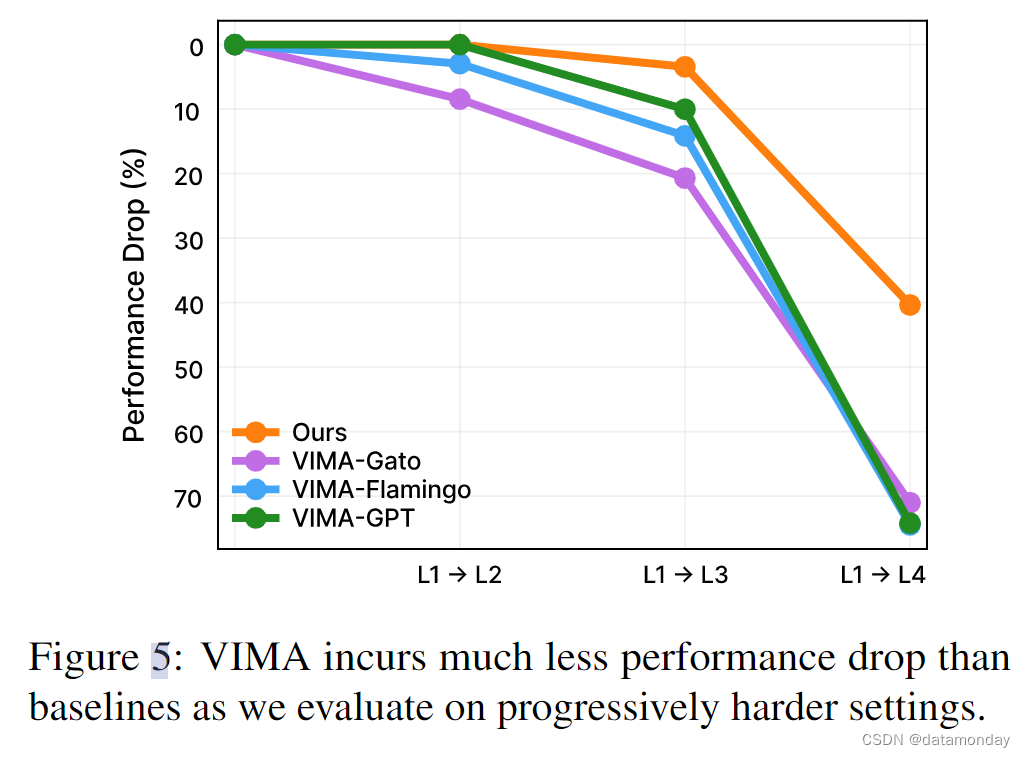
最后,我们比较了在没有进一步微调的情况下,在逐渐具有挑战性的零样本评估水平上测试模型时的相对性能下降情况(图 5)。我们的方法表现出最小的性能退步,尤其是在 L1 → L2 和 L1 → L3 之间。相比之下,基线方法的性能下降高达 20%,尤其是在更困难的泛化场景中。虽然在 L4(新任务)上评估时,所有方法的性能都有明显下降,但 VIMA 的性能下降幅度仅为所有其他基线的一半。这些结果表明,与其他方法相比,VIMA 开发出了更具通用性的策略和稳健的表示方法。
5.3. Ablation Studies
通过大量实验,我们分析了 VIMA 中的不同设计选择,并研究了它们对机器人决策的影响。我们重点关注四个方面:视觉标记化,提示条件,提示编码语言模型,以及策略对干扰和破坏的稳健性。
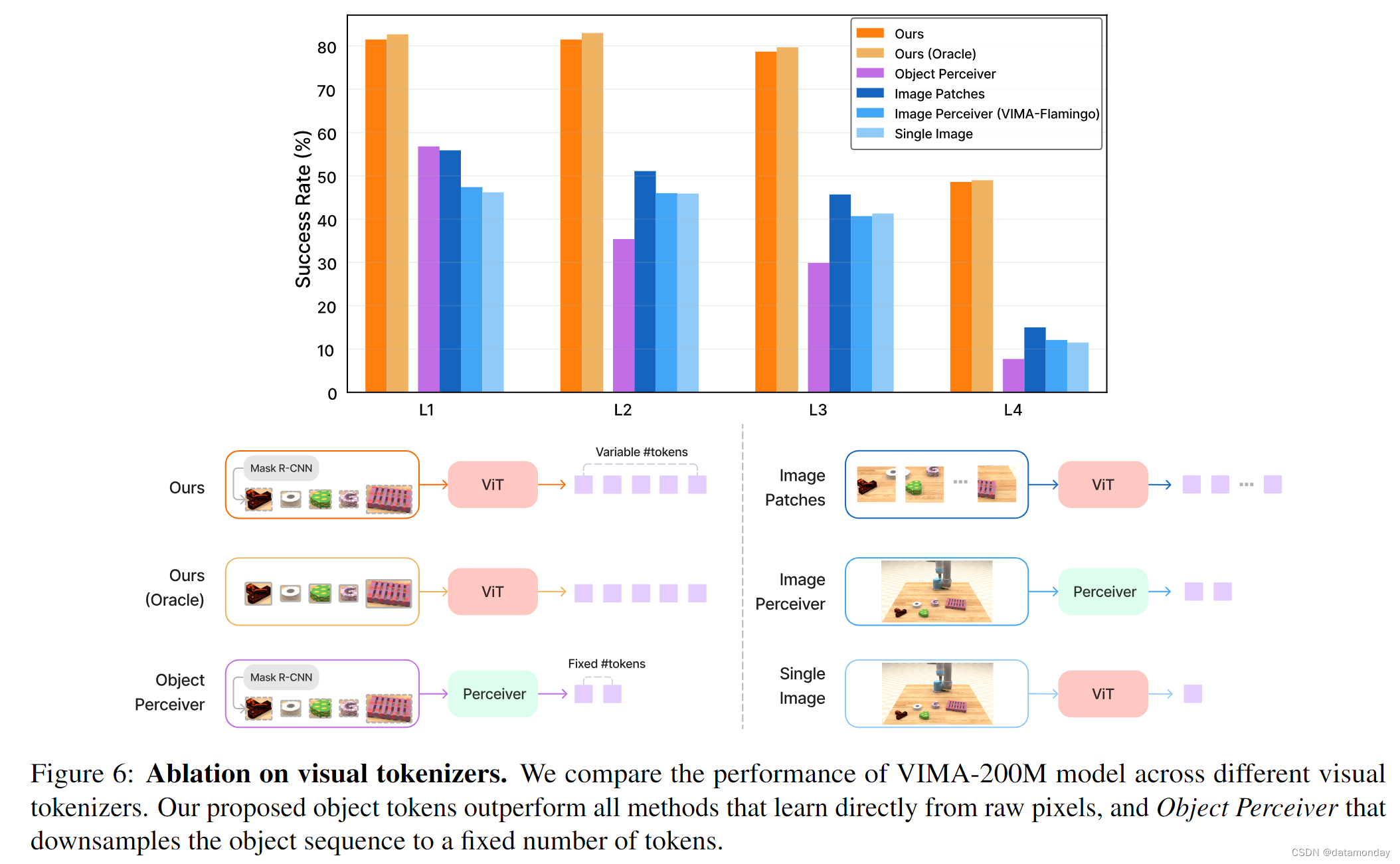
Visual Tokenization.
如第 4 节所述,VIMA 通过领域微调掩码 R-CNN 实现,将提示图像和观察图像处理成数量可变的物体标记。
视觉标记符号生成器的这一特定选择有多重要?我们研究了 5 种不同的变体,并对它们在 VIMA-BENCH 上的 4 级泛化性能进行了实证评估。
1)我们的(Oracle):我们不使用 Mask R-CNN,而是直接从模拟器中读出地面真实边界框。换句话说,我们使用一个完美的物体检测器来估算本研究的性能上限;
2)物体感知器:我们使用感知器模块将每帧中检测到的可变物体数量转换为固定数量的标记。Perceiver 的计算效率更高,因为它能减少序列的平均长度;
3)图像 Perceiver:与 VIMA-Flamingo 中的 Perceiver 重采样器架构相同,它能将图像转换为少量固定数量的标记;
4)图像补丁:仿效 VIMA-Gato,我们将 RGB 帧划分为正方形补丁,并提取 ViT 嵌入标记。补丁的数量大于图像感知器的输出;
5)单幅图像:VIMA -GPT 的标记化器可将一幅图像编码为一个标记。
图 6 显示了消融结果。我们重点介绍几项发现。
- 首先,我们注意到我们的 Mask R-CNN 检测管道(附录,第 C.4 节)与Oracle边界框相比性能损失极小,这要归功于物体增强(第 4 节)在训练过程中增强了鲁棒性。
- 其次,从原始像素(Image Perceiver,补丁或单一嵌入)进行标记的性能始终低于我们以物体为中心的格式。我们假设,这些标记化器必须分配额外的内部容量来解析低级像素中的物体,这很可能会阻碍学习。Sax 等人与我们的发现不谋而合,即与端到端管道相比,使用中层视觉可以大大提高Agent的泛化能力。
- 第三,尽管 Ours 和 Object Perceiver 都使用相同的物体边界框输入,但后者在决策制定方面明显更差。
我们的结论是,直接将可变长度的物体序列传递给机器人控制器,而不是降低采样到固定的标记数,这一点非常重要。
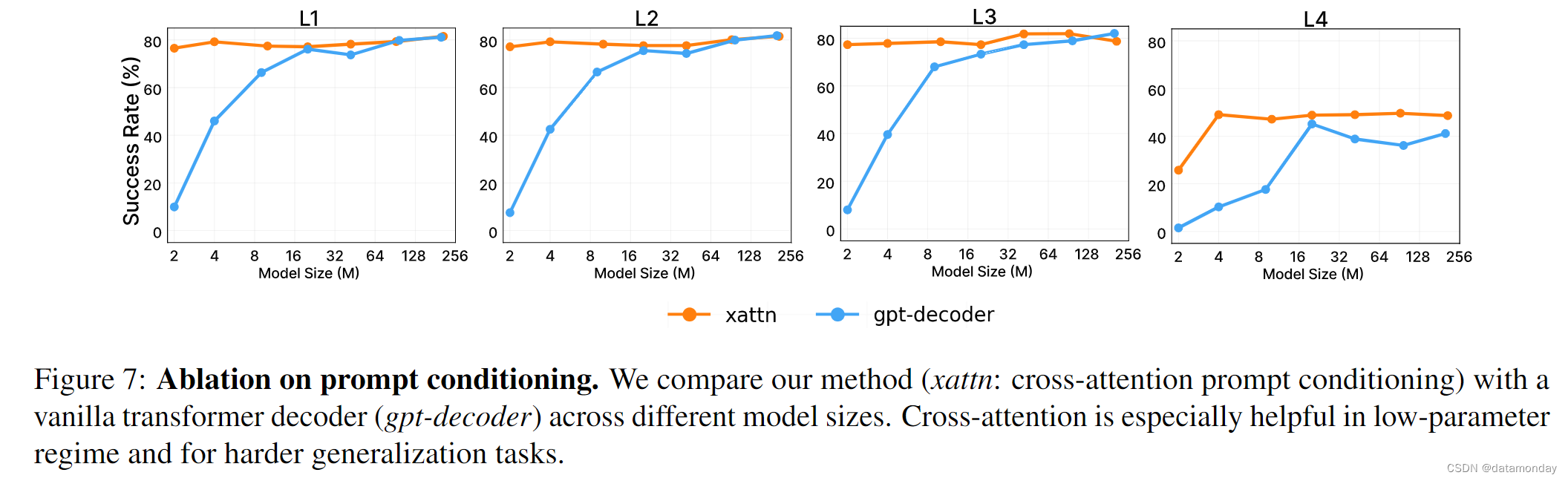
Prompt Conditioning.
VIMA 通过交叉注意的方式,使机器人控制器(解码器)以编码提示为条件。一个简单的替代方法是将提示 P 和交互历史 H 连接成一个大序列,然后应用类似 GPT 的解码器Transformer来预测动作。在这种消融中,我们保持物体标记器不变,只是将条件机制转换为因果序列建模。请注意,这一变体在概念上是 “带有物体标记的 VIMA-Gato”。图 7 显示了 VIMA (xattn) 和 gpt-decoder variant 在 4 个泛化级别上的比较。虽然该变体在较大的模型中性能相当,但交叉注意在小容量范围内仍占主导地位,在最具挑战性的 L4(新任务)设置中泛化效果更好。我们的假设是,交叉注意有助于控制器在每个交互步骤中更好地专注于提示指令。这与 Sanh 等人和 Wang 等人的经验结果相似,后者表明经过良好微调的编码器-解码器架构在零样本泛化方面优于 GPT-3。
Prompt Encoding.
我们改变了预训练 T5 编码器的大小,以研究及时编码的效果。我们试验了三种 T5 容量:small (30M), base(111M), and large (368M)。我们进一步将决策部分的参数数固定为 200M。对于所有 T5 变体,我们微调了最后两层,冻结了所有其他层。我们发现各变体之间没有明显差异(附录,第 E.4 节),因此我们将所有模型的默认值设为 base。
Policy Robustness.
我们研究了该策略在分心者数量不断增加和任务规格被破坏的情况下的稳健性,包括不完整的提示(用 标记随机屏蔽掉单词)和被破坏的提示(随机交换单词,这可能会完全改变任务的含义)。具体设置和结果见附录 E.5 节。VIMA 在分心因素增加时表现出最小的性能下降,而在提示语被破坏时表现出轻微的性能下降。我们将这种鲁棒性归功于高质量的预训练 T5 骨干。
6. Related Work
Multi-Task Learning by Sequence Modeling.
Transformer 实现了许多人工智能领域的任务统一。例如,
在 NLP 领域,
- Natural Language Decathlon 为一套 10 个 NLP 任务采用了一致的问题解答格式。
- T5 将所有语言问题统一为相同的文本到文本格式。
- GPT-3 和Megatron 通过零样本提示展示了直观任务规范的新兴行为。
在计算机视觉领域,
- Pix2Seq 将许多视觉问题转化为统一的序列格式。
- Florence,BiT 和 MuST 针对一般视觉表征大规模预训练共享骨干模型,并将其迁移到下游任务中。
在多模态学习方面,
- Perceiver 提出了一种处理结构化输入和输出的高效架构。
- Flamingo 和 Frozen 设计了一种通用应用程序接口,可接收图像和文本交错序列并生成自由格式文本。
- Gato 是一个横跨 NLP,视觉和具身Agent的大规模多任务模型。我们的工作在精神上与 Gato 最为相似,但我们主要侧重于为通用机器人Agent提供直观的多模态提示接口。
Foundation Models for Embodied Agents.
基础模型已经展示了强大的涌现特性。许多人正在努力将这一成功复制到具身Agent上,主要集中在三个方面。
1)Transformer Agent架构:
-
Decision Transformer 和 Trajectory Transformer 利用强大的自我注意模型进行连续决策。
-
CLIPort,Perceiver-Actor 和 RT-1 将大型Transformer应用于机器人操作任务。
-
BeT 和 C-BeT 设计了新颖的技术,从带有Transformer的多种模态演示中学习。
2)预训练以获得更好的表征:
- MaskViT ,R3M,VIP 和 VC-1 对机器人感知的一般视觉表征进行了预训练。
- Li 等人根据 LLM 检查点进行微调,以加速策略学习。
- MineDojo 和 Ego4D 提供了大规模多模态数据库,以促进可扩展的策略训练。
3)用于机器人学习的 LLMs:
- SayCan 利用 PaLM 进行零样本 concept grounding。
- Inner Monologue 和 LM-Nav 将 LLM 应用于长视距机器人规划。
- PaLM-E 是一种多模态语言模型,可重新用于顺序机器人操作规划。
我们与这些研究的不同之处在于我们新颖的多模态提示表述,而现有的 LLM 并不容易支持这种表述。
Robot Manipulation and Benchmarks.
各种机器人操作任务需要不同的技能和任务规范格式,如
- 指令跟随
- 单样本模仿
- 重新排列
- 约束满足
- 推理
为研究上述任务,引入了多种物理模拟基准。例如,
- iGibson 模拟了交互式家庭场景。
- Ravens 和 Robosuite 利用逼真的机械臂设计各种桌面操作任务。
- CALVIN 开发了长视距语言条件任务。
- Meta-World 是一个广泛使用的模拟器基准,用于研究桌面设置的机器人操作。
- CausalWorld 是一个在操作中进行因果结构和转移学习的基准,需要长视距规划和精确的低级运动控制。
- AI2-THOR 是一个支持视觉物体操作和环境程序生成的框架。
我们的 VIMA-BENCH 是首个支持多模态提示任务的机器人学习基准。我们还对评估协议进行了标准化,以系统地衡量机器人的泛化能力。
An extended review can be found in Appendix, Sec. F.
Multi-Task Learning by Sequence Modeling.
在计算机视觉领域,Mask R-CNN,UberNet 和 12-in-1 利用一个单一的骨干模型与多个独立的头部来完成不同的任务。UVim 是另一种统一的视觉方法,它使用语言模型为第二个模型生成指导代码,以预测原始视觉输出。在多模态学习方面,许多工作研究了图像,视频,音频和/或语言模态的统一,以提供多用途基础模型,不过其中大多数都不具备决策能力。BEiT-3 对图像,文本和图像-文本对进行掩码数据建模,为各种下游任务预先训练骨干。MetaMorph 通过模块化机器人设计空间学习通用控制器。
Foundation Models for Embodied Agents.
具身Agent研究正在采用大规模预训练范式,由一系列学习环境提供支持。
- Reid 等人从预训练以获得更好的表征方面出发,从 LLM 检查点进行微调,以加速策略学习。
- LaTTe 和 Embodied-CLIP 利用CLIP 的冻结视觉和文本表征进行机器人操作。
- MaskDP 则为各种下游体现任务预先训练双向Transformer。
- 从利用Transformer作为Agent架构的角度来看,Dasari & Gupta 和 MOSAIC 等方法在单次视频模仿任务中取得了优异的性能。它们都使用自我注意机制和辅助损失,如反动态损失和对比损失来学习机器人控制器。
- InstructRL 利用联合预训练的视觉语言模型作为机器人Agent来执行操作任务。
- 从用于机器人学习的大型语言模型的角度来看,Socratic Models 将多个视觉和语言基础模型组合在一起,用于视频中的多模态推理。
- ROSIE 利用文本到图像的扩散模型,通过 inpainting 来增强现有的机器人数据集。
- MOO 采用了与我们类似的以物体为中心的表示方法,用于开放世界的物体操作。
- Voyager 开发了一个在开放式虚拟世界中运行的 LLM 驱动的Agent。
Robot Manipulation and Benchmarks.
有许多未在正文中提及的前人著作研究了不同的机器人操作任务,如:
- 指令跟随
- 约束满足
- 单样本模仿
- 重排
- 推理
为研究上述任务,引入了多个仿真基准:
- 1)室内模拟环境: Habitat 配备了高性能3D模拟器,可快速渲染,并为辅助机器人提出了一套常见任务。
- 2)桌面环境:RLBench 和 SURREAL 是其他广泛使用的模拟器基准,研究桌面设置下的机器人操作。STRETCH-P&P(Zhang & Weihs,2023 年)研究无重置强化学习的跨目标泛化。
上述所有模拟器和基准都不支持任务指定和多模态提示。
7. Conclusion
在这项工作中,我们介绍了一种新颖的多模态提示方法,它能将各种机器人操作任务转化为统一的序列建模问题。我们在 VIMA-BENCH 中实例化了这一表述,VIMA-BENCH 是一个具有多模态任务和系统评估协议的多样化通用基准。我们提出的 VIMA 是一种概念简单的基于Transformer的Agent,能够用单一模型解决视觉目标达成,单次视频模仿和新概念接地等任务。通过综合实验,我们发现 VIMA 具有很强的模型可扩展性和零样本泛化能力。因此,我们建议将我们的Agent设计作为未来工作的坚实起点。
A. Simulator Details
我们在 Ravens 物理模拟器的基础上构建了 VIMA-BENCH 模拟套件。具体来说,它由 PyBullet 和 Universal Robot UR5 机械臂支持。桌面工作空间的大小为 0.5 × 1m。我们的基准包含可扩展的3D物体和纹理集。所有物体实例均可通过物体-纹理组合实例化,以 RGB 图像的形式出现在多模态提示中。图 A.1 显示了所有3D物体。图 A.2 显示了所有纹理。

VIMA-BENCH 的观测空间包括正面和俯视的 RGB 图像。它还包括一个单样本向量∈{0, 1}2,用于表示末端执行器的类型∈{suction cup, spatula}。suction cup 适用于大多数操作任务,而 spatula 则特别适用于视觉约束任务,即要求Agent 擦拭物体。VIMA-BENCH 从 Zeng 等人和 Shridhar 等人那里继承了相同的动作空间,对于使用吸盘作为末端执行器的任务,动作空间由取放(pick and place)和推(push)这两种原始动作组成,对于使用刮铲的任务,动作空间由推(push)和取放(pick and place)这两种原始动作组成。这两个原始动作都包含两个姿态∈SE(2),指定了终端执行器的目标姿态。对于取放基元动作,它们分别代表取的姿态和放的姿态。对于推基元,它们代表推的起始姿态和推的结束姿态。
与之前的工作类似,VIMA-BENCH 提供了脚本指令,可为所有任务生成成功的演示。我们利用它们构建了一个离线模仿数据集,用于行为克隆。根据提示,这些编程机器人可以获取特权信息,例如正确的挑选物体和目标位置。
B. Task Suite
我们开发了属于 6 个不同类别的 17 个任务模板。数以千计的单个任务实例及其相应的多模态提示可以从这些任务模板中程序化地生成。我们使用 PyBullet 作为后端和默认渲染器,为训练数据和交互式测试环境生成 RGB 框架。出于演示目的,我们应用了 NVISII 光线追踪技术来提高视觉质量。我们将在下面的小节中详细介绍每项任务。
B.1. Simple Object Manipulation
B.2. Visual Goal Reaching
B.3. Novel Concept Grounding
B.4. One-Shot Video Imitation
B.5. Visual Constraint Satisfaction
B.6. Visual Reasoning
C. Model Architecture
C.1. Summary of Different Methods
C.2. VIMA Architecture
C.3. Baselines Architectures
C.4. Mask R-CNN Detection Model
D. VIMA Training Details
E. Extended Experiment Results
F. Extended Related Work
已添加到正文中