Kafka 中,Producer采用push模型,而Consumer采用pull模型。
Topic
Topic(主题)是消息的逻辑分类或通道。它是Kafka中用于组织和存储消息的基本单元。一个Topic可以被看作是一个消息发布的地方,生产者将消息发布到一个特定的Topic,而消费者则订阅一个或多个Topic以接收消息。
Consumer group
Consumer Group(消费者组): 为了扩展消费者并实现并行处理,多个消费者可以组成一个消费者组。每个分区只能由消费者组内的一个消费者处理,这样可以确保消息在每个分区内的有序处理。
每个消费者组都有一个组id!同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据。
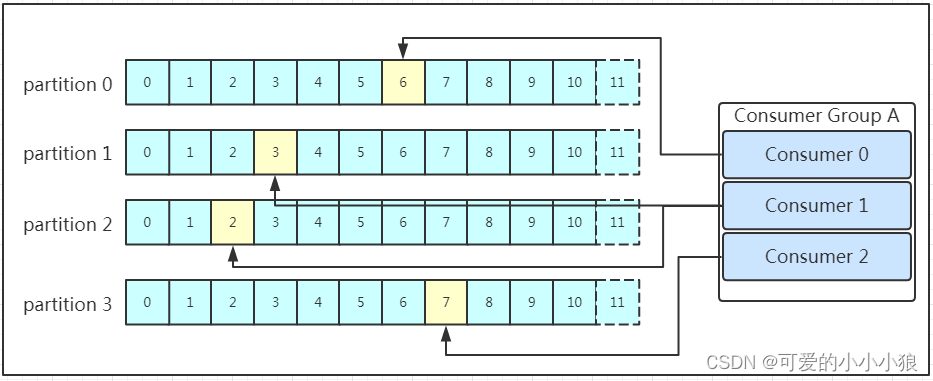
在实际的应用中,建议消费者组的consumer的数量与partition的数量一致
Partition
每个topic可以有多个分区,每个分区中的消息是有序的。
生产者将消息发布到topic时,Kafka会根据一定的策略将消息分配到不同的分区。
消费者可以订阅整个topic,也可以选择订阅topic的特定partition。
每个topic可以划分为一个或多个partition,分区是Kafka中的基本存储单元。
分区允许水平扩展,每个分区可以独立地分布在不同的机器上,提高了Kafka的伸缩性和性能。
那么当Producer将消息发送给broker,
分区的原因
-
提高吞吐量: 分区允许Kafka集群并行处理消息。每个分区都是一个独立的有序队列,多个分区可以同时进行读写操作,使得整个系统能够更有效地处理大量的消息。这种并行性是Kafka实现高吞吐量的关键。
-
实现水平扩展: 通过将消息分布在多个分区上,Kafka可以轻松地在集群中添加更多的Broker来实现水平扩展。每个Broker只需要负责一部分分区,从而有效地分担了负载。这种扩展性使得Kafka能够适应不断增长的数据量和流量。
-
容错性: 每个分区的数据都可以有多个副本(Replica)在集群的不同Broker上存储。如果某个Broker或分区发生故障,其他副本依然可用。这种冗余机制提高了系统的容错性,确保了数据的可用性和持久性。
-
有序性: 分区内的消息是有序的,而分区间的消息不做有序保证。这使得Kafka在保持消息的有序性的同时,可以在不同的分区上实现并行处理,使系统更加灵活。
-
提供灵活的消息处理模型: 分区允许消费者以消费者组的形式协同处理消息。每个分区只能被同一个消费者
Parition的副本replice
为了提高可靠性和容错性,每个分区可以有多个副本(replica)。这些副本分布在不同的Broker上,确保即使其中一个Broker失效,仍然有其他副本可用。
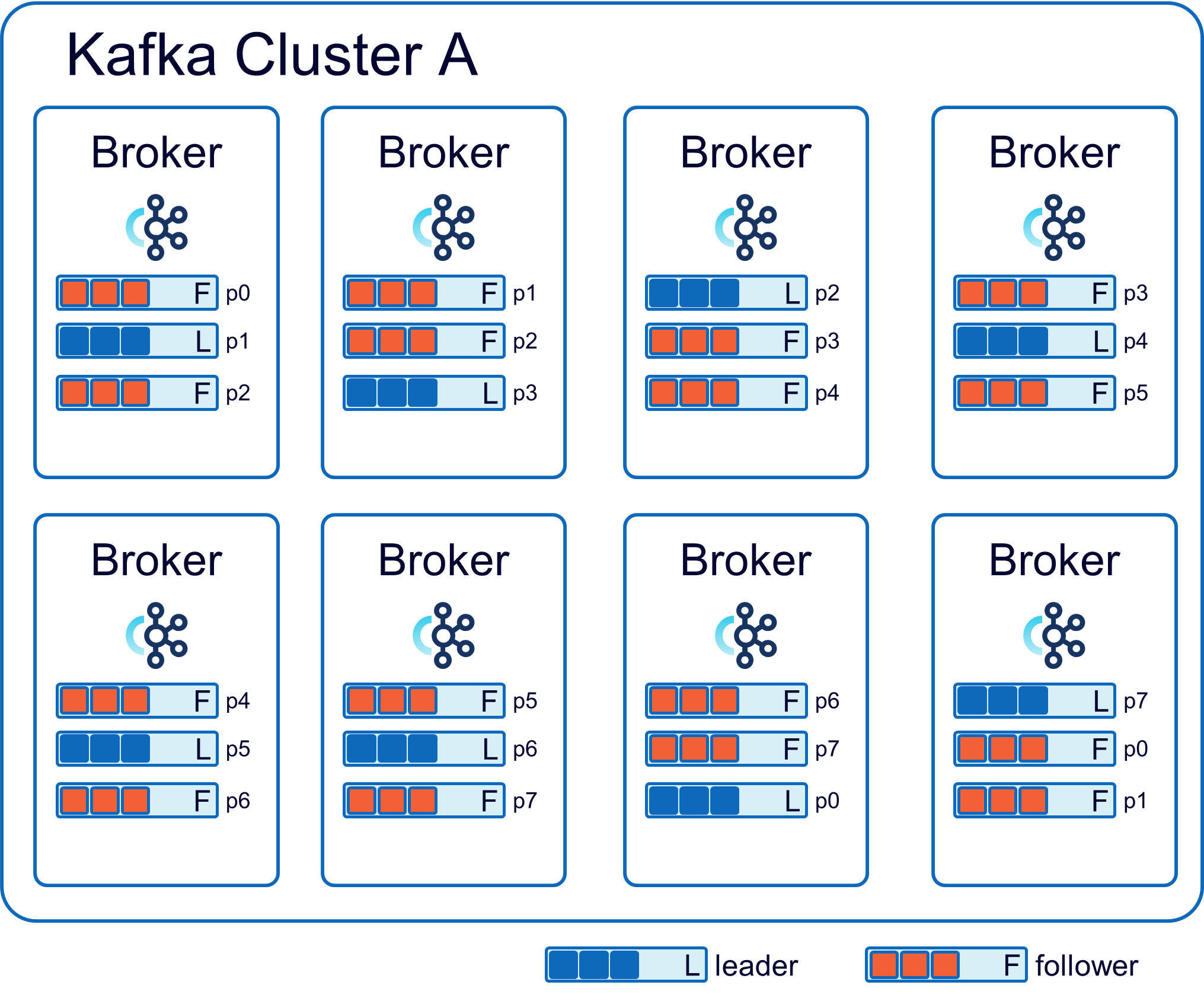
Broker
Broker是一个独立的Kafka服务器实例,负责处理消息的生产和消费。
-
存储: Broker存储了消息的持久化副本,以确保消息的持久性。每个Topic的分区被分布在不同的Broker上,以实现分布式存储和水平扩展。
-
Leader和Follower: 对于每个Topic的分区,一个Broker被选举为Leader,其余的为Follower。Leader负责处理读写请求,而Follower则同步Leader的数据,以提供容错和冗余。
-
消息的生产和消费: 生产者将消息发送到Topic,而消费者从Topic中消费消息。Broker协调这两个过程,确保消息被正确地传递给订阅了相应Topic的消费者。
-
Broker负责存储和管理所有Topic的Partition数据,并协调Partition之间的数据同步和复制。
Producer
将消息发送给broker的过程:
-
选择 Topic: 生产者选择一个或多个目标 Topic。
-
选择分区: 如果生产者选择将消息发送到特定的分区,它可以指定分区,否则,Kafka 会使用一种策略(例如轮询或哈希)来决定将消息发送到哪个分区。
-
构造消息: 生产者构造要发送的消息,这可以是文本、二进制数据等。
-
发送消息: 生产者将消息发送给 Kafka 集群中的 Broker。生产者需要知道 Broker 的地址(通常至少提供一个 Broker 的地址),然后将消息发送给指定的 Topic 和分区。
Producer选择发送的分区过程
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
- 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
Kafka将数据顺序存储在磁盘上
Kafka既将数据写入磁盘,也在内存中进行一些操作。Kafka的设计目标之一是提供持久性和高吞吐量。因此,它会将消息写入磁盘以确保数据的持久性,这使得即使在Broker重启后,数据仍然可用。
具体来说,Kafka使用了一种称为写入日志(write-ahead log)的机制。当消息被生产者发布到一个Topic时,Kafka首先将消息追加到该Topic的日志文件中。这些日志文件通常位于磁盘上。写入日志的方式使得消息的添加成为原子操作,并且消息按顺序写入。
同时,Kafka还利用内存来提高性能。在Broker内,Kafka会维护一个称为Page Cache的内存区域,用于缓存最近使用的数据块。这使得在读取数据时,可以在内存中快速获取,提高读取性能。
日志段
Partition在服务器上的表现形式就是一个一个的文件夹存储在磁盘上,每个partition的文件夹下面会有多组segment文件,每个segment文件中又包含.index文件、.log文件、.timeindex文件三个文件。
每个日志段包含三个主要文件:
.log 文件: 这个文件是实际存储消息的地方。消息以追加的方式写入这个文件,并且按顺序存储。这种追加写入的方式使得写入操作是高效的,同时也有助于提高读取性能。
.index 文件: 这个文件是索引文件,用于快速定位消息。它包含消息的物理偏移(offset)和消息的逻辑偏移(相对于分区的偏移)之间的映射。索引文件的存在使得 Kafka 能够更有效地执行消息的检索操作,而不必扫描整个日志文件。
.timeindex 文件: 这个文件是时间索引文件,在某些版本的 Kafka 中引入。它提供了消息时间戳和物理偏移之间的映射,以支持按时间范围检索消息。

每个分区由多个这样的日志段组成。当一个日志段达到一定的大小或者时间限制时,Kafka会创建一个新的日志段。这种机制有助于管理磁盘空间,同时也有利于日志的压缩和维护。
查找消息的时候是怎么利用segment+offset配合查找的呢?假如现在需要查找一个offset为368801的message是什么样的过程呢?我们先看看下面的图:
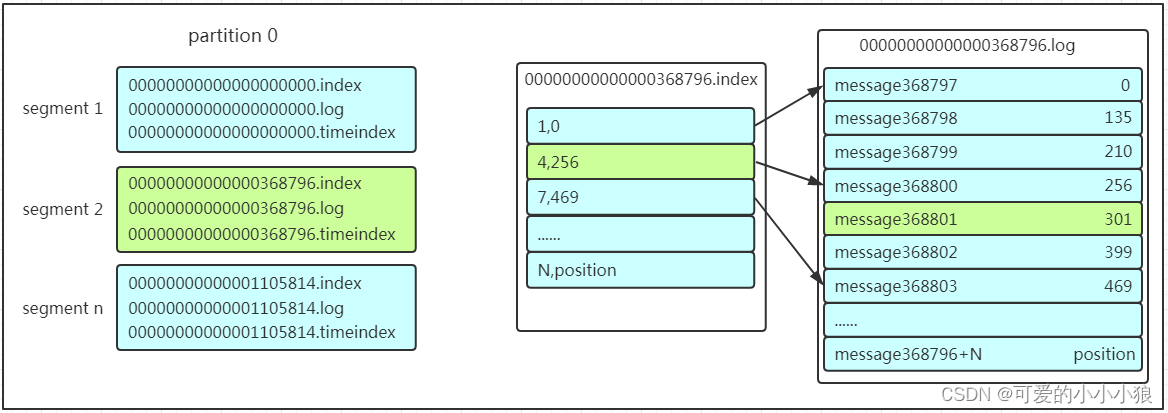
1、 先找到offset的368801message所在的segment文件(利用二分法查找),这里找到的就是在第二个segment文件。
2、 打开找到的segment中的.index文件(也就是368796.index文件,该文件起始偏移量为368796+1,我们要查找的offset为368801的message在该index内的偏移量为368796+5=368801,所以这里要查找的相对offset为5)。由于该文件采用的是稀疏索引的方式存储着相对offset及对应message物理偏移量的关系,所以直接找相对offset为5的索引找不到,这里同样利用二分法查找相对offset小于或者等于指定的相对offset的索引条目中最大的那个相对offset,所以找到的是相对offset为4的这个索引。
3、 根据找到的相对offset为4的索引确定message存储的物理偏移位置为256。打开数据文件,从位置为256的那个地方开始顺序扫描直到找到offset为368801的那条Message。
这套机制是建立在offset为有序的基础上,利用segment+有序offset+稀疏索引+二分查找+顺序查找等多种手段来高效的查找数据!