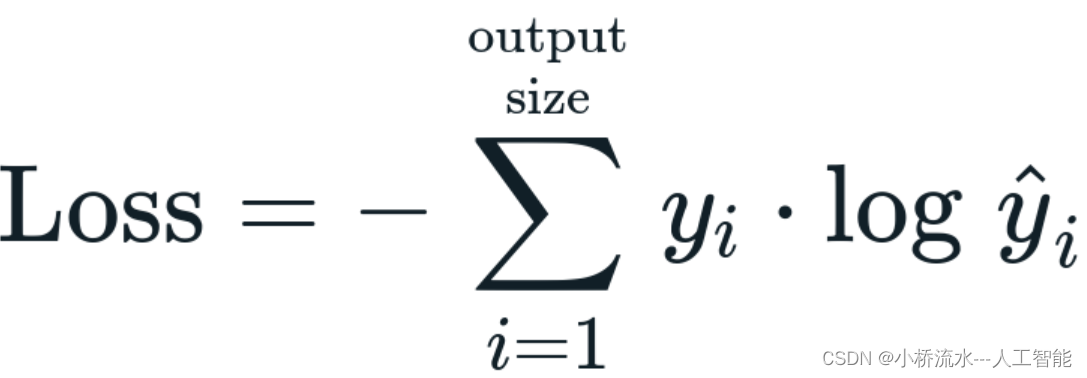
交叉熵损失函数(Cross-Entropy Loss)是机器学习和深度学习中常用的损失函数之一,用于分类问题。其基本概念如下:
1. 基本解释:
交叉熵损失函数衡量了模型预测的概率分布与真实概率分布之间的差异。在分类问题中,通常有一个真实的类别标签,而模型会输出一个概率分布,表示样本属于各个类别的概率。交叉熵损失函数通过比较这两个分布来计算损失,从而指导模型的优化。
具体来说,对于二分类问题,真实标签通常表示为0或1,而模型输出一个介于0和1之间的概率值。交叉熵损失函数计算的是真实标签与模型预测概率之间的负对数似然。如果真实标签为1,则损失函数关注模型预测为正类的概率的对数值;如果真实标签为0,则损失函数关注模型预测为负类的概率的对数值。
对于多分类问题,真实标签通常使用one-hot编码表示,即只有一个位置为1,其余位置为0。模型输出一个概率向量,表示样本属于各个类别的概率。交叉熵损失函数计算的是真实标签中每个位置对应的模型预测概率的负对数似然之和。
2. Python程序代码:
在Python中,可以使用NumPy库或深度学习框架(如TensorFlow、PyTorch)来计算交叉熵损失函数。以下是使用NumPy计算二分类和多分类交叉熵损失函数的示例代码:
import numpy as np# 二分类交叉熵损失函数
def binary_cross_entropy_loss(y_true, y_pred):return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))# 多分类交叉熵损失函数
def categorical_cross_entropy_loss(y_true, y_pred):num_classes = y_true.shape[1]return -np.mean(np.sum(y_true * np.log(y_pred + 1e-9), axis=1))# 示例用法
# 二分类
y_true_binary = np.array([[0], [1], [1], [0]])
y_pred_binary = np.array([[0.1], [0.9], [0.8], [0.4]])
loss_binary = binary_cross_entropy_loss(y_true_binary, y_pred_binary)
print("Binary Cross-Entropy Loss:", loss_binary)# 多分类
y_true_categorical = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]])
y_pred_categorical = np.array([[0.7, 0.2, 0.1], [0.1, 0.8, 0.1], [0.2, 0.2, 0.6]])
loss_categorical = categorical_cross_entropy_loss(y_true_categorical, y_pred_categorical)
print("Categorical Cross-Entropy Loss:", loss_categorical)
请注意,上述代码示例仅用于演示目的,实际使用中可能会使用深度学习框架提供的交叉熵损失函数,因为它们通常更加优化和稳定。例如,在TensorFlow中,可以使用tf.keras.losses.BinaryCrossentropy和tf.keras.losses.CategoricalCrossentropy类来计算二分类和多分类交叉熵损失函数。在PyTorch中,可以使用torch.nn.BCELoss和torch.nn.CrossEntropyLoss类来计算相应的损失函数。