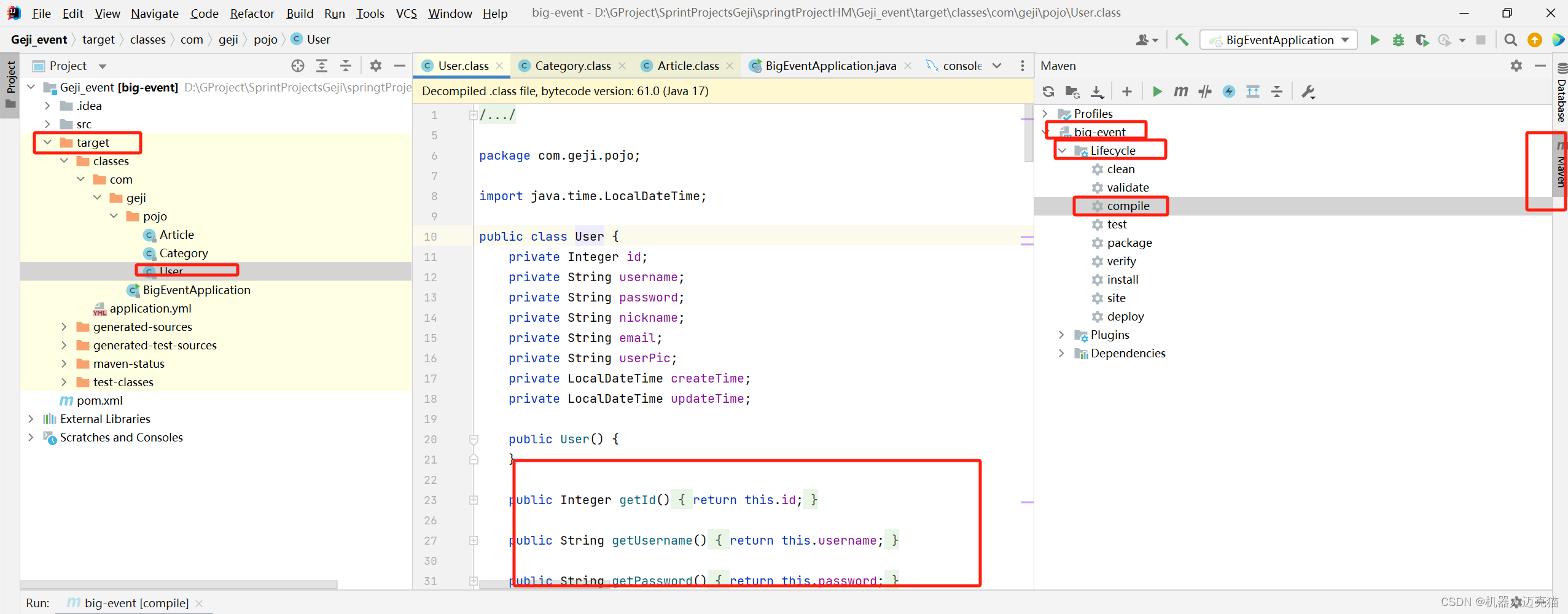
数据密集型应用系统设计

原文完整版PDF:https://pan.quark.cn/s/d5a34151fee9
这本书的作者是少有的从工业界干到学术界的牛人,知识面广得惊人,也善于举一反三,知识之间互相关联,比如有个地方把读路径比作programming language的lazy evaluation而写路径比作eager evaluation,令人拍案。这一本数囊括了几乎所有数据处理相关工作中可能遇到了的内容,而且也有非常棒的实操经验。比如书的一开始,作者反复强调监控中分位数的作用,可以揭示一些被平均数掩盖的事实,我也正好有一个监控从都是监控平均值变成主要监控若干p99分位数的经历,看到这里,不由得掩卷叹息。
我做数据处理也就是不到三年,接触过不少相关的工具,可以说Hadoop啊,pig啊,Hive啊,Storm啊,你的确不去了解它们背后的原理理念也可以用,但是真正要整合它们,做一个容错,可扩展,可维护的数据产品,则需要相当的分布式和数据系统的insight。帮助你建立这样的insight的书,应该是比较缺乏的,你可以去刷分布式系统的课程,看paper,但是阅读一本one in all的书,ROI可能是最高的。之前也有人尝试过,比如有国人写的《大数据日知录》,其实写得也算不错,但是不知道是笔力不济还是什么缘故,最后也是沦为技术文档的罗列。
这本书循循善诱的写作手法应该是相当高超了,讲解得非常深入浅出,一般照着提出问题 -> 解决方案 -> 这个方案的长处短处 -> 发散到其它方案这个模式讲解,看起来可以说是不知不觉,非常轻松,也没有有些作者的拽文习惯,几乎全部是中学词汇,句子也不复杂,保证非英语母语的人可以流畅阅读,这点可以说是非常良心了。
当然,这本书没有介绍什么新技术,很多内容都是我们所熟悉的。也没有具体讲解某一种技术的细节,不能期望读完本书后成为某种专家。
本书的意义在于,一方面是百科全书式的广度科普,涉及大家耳熟能详的技术名词:NoSQL, 大数据,最终一致性,CAP,MapReduce,流处理等,讨论他们背后遵循的不变的原则,知晓这些技术做的取舍,探索它们的设计选择。帮助我们更好地使用这些技术,不仅知道how,更加知道why。对我们有经验的工程师来说,可以查漏补缺,完善知识图谱上的拼图。
另一方面是思想深度上的升华。我们虽然有一定的开发经验,掌握了一些知识和技巧,但这些知识在我们的头脑中是比较散乱的,没有很好的组织起来,点和点之间也没产生联系。这本书就是将各个知识点串联起来,我们可以看到,同一种思想在多个章节中出现,反映出这些各种技术本质上是某种思想在不同问题层面上的投射。让我们能够站在一个高度上审视,自己的工作本质上是在做什么事,是在何种假设下解决什么类型的问题,得以从繁多的技术细节中抬起头来,看一看知识体系的全貌。
这本书还有一个优点,把复杂的东西简单化,之前总也搞不明白的概念,看了这本书就懂了。
书的最后一章升华了整本书。Martin Kleppmann 不仅是个牛逼的程序员,更是一个极富社会责任和人文关怀的牛逼程序员。而这是更难能可贵的。
习武之人讲究“习武先修德”。Martin Kleppmann 亦是如此。他用前十一章教会我们如何处理海量数据,用最后一章告诉我们如何正确使用数据。要保护用户隐私、要对自己的算法负责、要保障弱势群体的权利……他旗帜鲜明地说道:“盲目相信数据决策至高无上,这不仅仅是一种妄想,而是有切实危险的。”
原文很长,完整版PDF已整理好了(在文章开头),感兴趣的小伙伴可以去看看。