浅谈缓存
- 一、背景
- 二、缓存分类
- 1.本地缓存
- 2.分布式缓存
- 三、缓存读写模式
- 1.读请求
- 2.写请求
- 四、缓存穿透
- 1.缓存空对象
- 2.请求校验
- 3.请求来源限制
- 4.布隆过滤器
- 五、缓存击穿
- 1.改变过期时间
- 2.串行访问数据库
- 六、缓存雪崩
- 1.避免集中过期
- 2.提前更新缓存
- 七、缓存与数据库一致性
- 1.设置缓存过期时间
- 2.更新缓存/更新数据库
- 2.1 先更新数据库再更新缓存
- 2.2 先更新缓存再更新数据库
- 3.先删除缓存再更新数据库
- 3.1 两个操作事务性操作情况如下:
- 3.2 数据一致性问题
- 4.先更新数据库再删除缓存
- 4.1 两个操作事务性操作情况如下:
- 4.2 补偿机制
- 4.3 数据一致性问题
- 5.延时双删
- 5.1 延时双删操作流程:
- 5.2 延迟双删优化
- 总结
一、背景
互联网相关业务相对于传统场景普遍存在高并发高流量的情况,因此在实际业务场景中,都会通过在业务和存储中间添加缓存层来减轻数据库的压力。使用缓存主要是为了提升响应速度和并发量,并减轻数据库的访问压力。在实际使用过程中需要解决缓存穿透、缓存击穿和缓存雪崩的发生,并且需要考虑缓存与数据库数据一致性问题。
二、缓存分类
缓存根据保存的位置不同分为本地缓存和分布式缓存。本地缓存就是保存在服务所在机器上,占用jvm内存空间;分布式缓存就是保存在独立的服务上如Redis集群上。
1.本地缓存
将一些只读基础数据进行本地缓存减轻数据库访问压力加快程序访问速度。这类数据特点变更不频繁,对缓存与数据库中数据不一致容忍度较高。服务启动时进行本地缓存加载,可以采用定时刷新缓存或者监听消息的方式重新加载缓存来保证本地缓存数据的实时性。
- 缺点:占用本地内存,数据量受限;每个服务都需要保存,副本较多;服务启动时需要加载,可能导致启动时间较长;
- 优点:本地缓存访问速度更快,独立缓存不互相影响
2.分布式缓存
将非只读数据保存在分布式缓存集群中可以提高服务的灵活度,提升响应速度提高并发量,这些数据基本都是程序运行过程中加载到缓存并在一段时间后会从缓存卸载。
- 缺点:需要部署额外缓存集群;需要提供多副本防止单点故障;业务集群共用,缓存污染容易导致整个业务不可用;
- 优点:不占用本地内存,数据量不受限制;与业务集群结偶,缓存保存在缓存集群中;服务运行过程中加载和卸载,不影响服务启动耗时;
三、缓存读写模式
经典的缓存+数据库读取 Cache Aside Pattern模型。
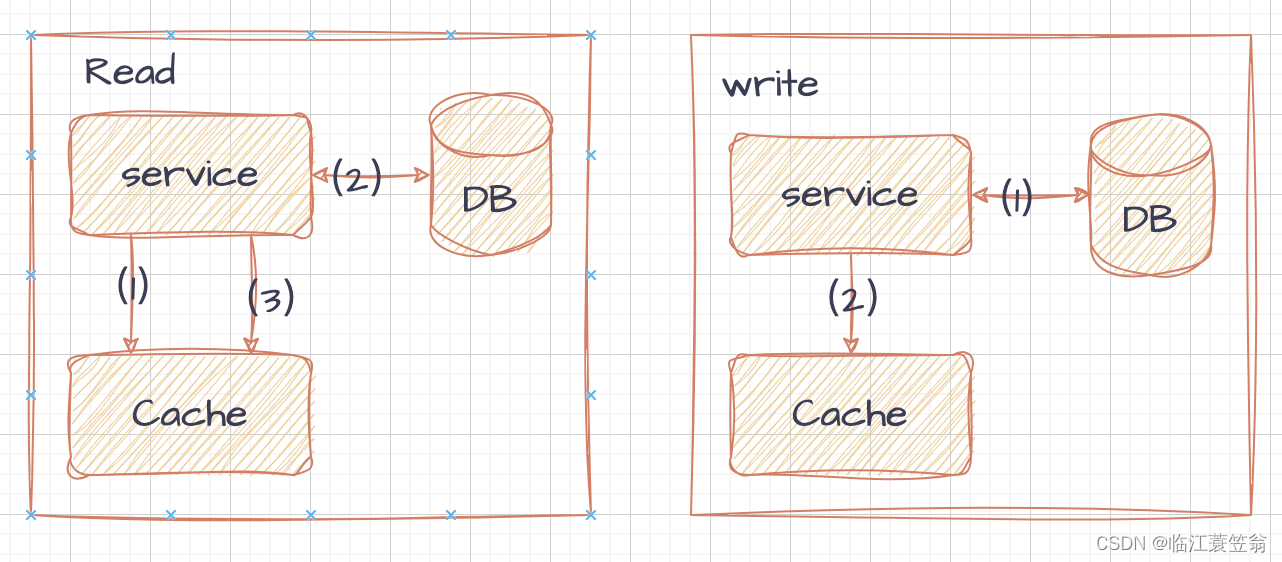
1.读请求
- 读的时候先从缓存读取
- 如果缓存中不存在,则需要从数据库中读取
- 数据取出后需要写入到缓存中
2.写请求
- 更新时需要先更新数据库
- 然后删除缓存
四、缓存穿透
缓存穿透是指查询了一个在数据库和缓存中都不存在的数据。由经典 Cache Aside Pattern模型可知,所有请求都会进行数据库查询,如果请求非常多会给数据库造成访问压力乃至奔溃。造成这种场景有可能是误删除数据或者恶意攻击导致的。
为了防止此问题,基本都是采用空间换时间,也就是对访问请求进行一定拦截和过滤。
1.缓存空对象
当查询数据库无结果时,将空对象保存到缓存中并设置一个过期时间。当在缓存过期时间内,相同的请求在缓存中都可以查询到结果而不会访问到数据库。过期时间内数据库即使新增了数据也不会加载到缓存,因此需要合理设置过期时间长度。
2.请求校验
对于请求进行数据合法性校验,将不合法校验直接拦截,不进行缓存和数据库的查询操作。
3.请求来源限制
可以通过设置黑白名单,对请求来源进行限制,保证没有恶意攻击行为和非法请求。
4.布隆过滤器
将数据库中数据保存到布隆过滤器中,当请求过来先经过布隆过滤器,如果不存在直接拒绝,如果存在则继续查询。
五、缓存击穿
缓存击穿是查询的数据在缓存中不存在,但是数据库中存在。当缓存中key过期,而此时有大量并发请求此key会导致数据库压力剧增。可以通过限制同时查询数据库的请求或者缓存的过期时间避免此问题。
1.改变过期时间
设置热点数据永不过期
2.串行访问数据库
缓存击穿是大量并发请求同时进行数据库查询导致的。可以在进行对应数据库查询之前进行加锁操作。
2.1 当查询key时,首先查询缓存,如果没有。需要先获取分布式锁才能进入数据库查询然后将查询结果保存到缓存,然后解锁。
2.2 如果发现查询锁被占用,则说明有线程正在获取。所以等待锁接触后可以直接访问缓存而不必进行数据库查询操作。
六、缓存雪崩
缓存雪崩是指缓存中大批量key同时过期,而此时又是流量高峰导致后端数据库压力暴增,甚至会导致数据库挂掉。缓存击穿是指单个key过期,缓存雪崩是指大量key同时过期。
1.避免集中过期
将缓存中的数据缓存时间在原有的失效时间基础上加一个随机值,这样可以避免集体失效引发雪崩。
2.提前更新缓存
可以在缓存中数据过期前,主动更新缓存中的数据,防止数据到达TTL。
七、缓存与数据库一致性
由于缓存和数据库是两个数据源,如果想要保证两个数据源的强一致性需要对读写操作进行加锁处理和事务处理,但是加锁之后会影响整个系统的响应速度,基本不会采用此方式进行处理。在实际场景中,在强一致性和系统性能上采取一个妥协,基本上都是要求缓存和数据库在短时间内一致即可,也就是最终一致性而不要求强一致性。
1.设置缓存过期时间
此方案针对数据要求一致性比较低或者读多写少的业务场景。读时缓存如果没有数据,从数据库读取后写入缓存并设置过期时间。写时直接写入数据库,不操作缓存。
2.更新缓存/更新数据库
由于更新数据库和更新缓存有可能有一定的延迟和间隔。在并发写请求的情况下,不论先更新缓存后更新数据库,还是先更新数据库后更新缓存,都可能存在数据库和缓存数据不一致的情况。由于数据库和缓存都更新成功都有很大概率出现数据不一致的情况,所以不讨论其中一个失败的情况。
2.1 先更新数据库再更新缓存
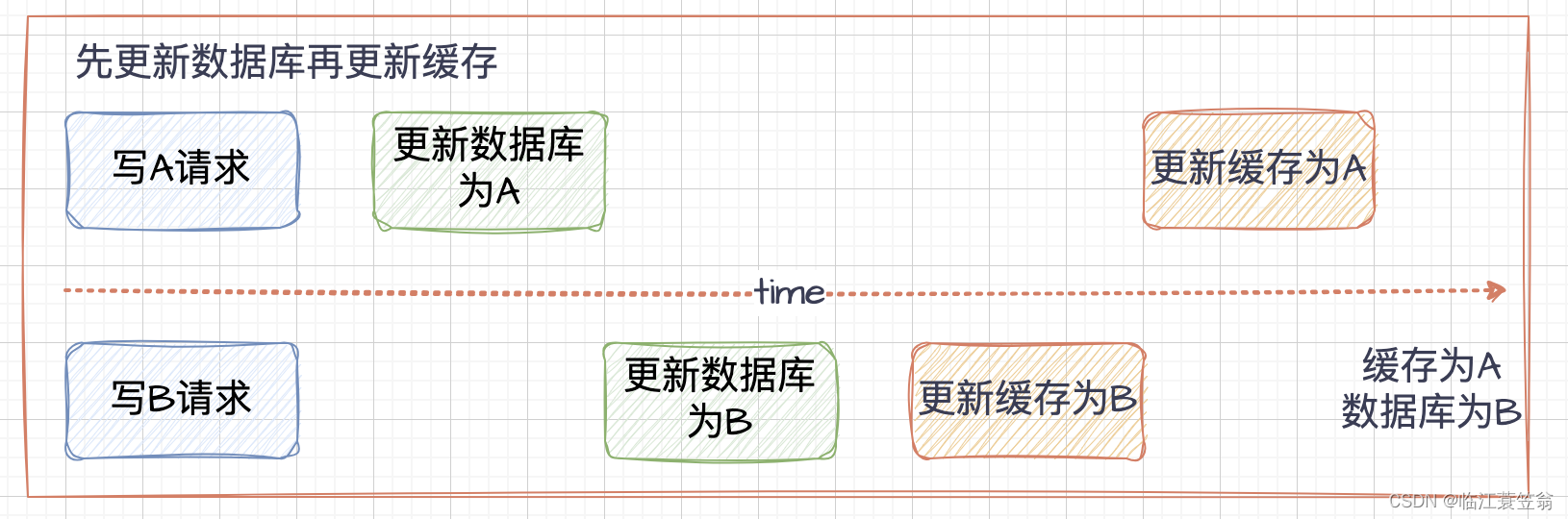
2.2 先更新缓存再更新数据库
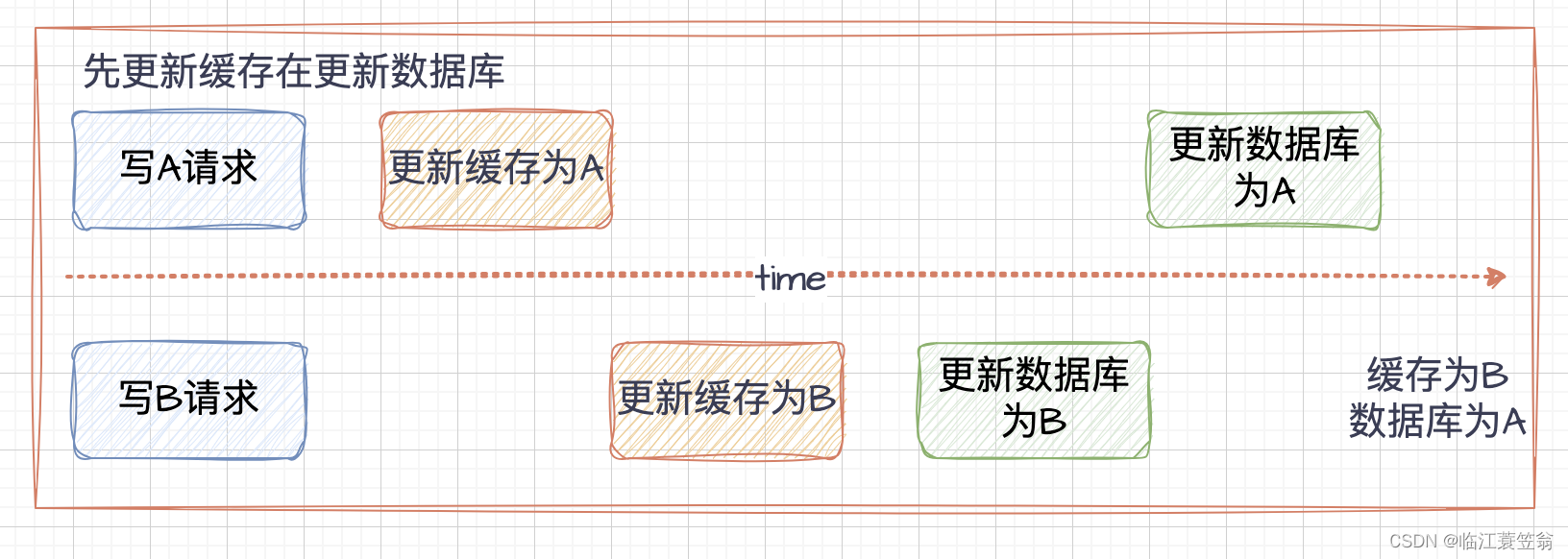
3.先删除缓存再更新数据库
3.1 两个操作事务性操作情况如下:
1) 删除缓存成功,更新数据库成功
2 )删除缓存失败,程序异常,不会进行更新数据库操作
3 )删除缓存成功,更新数据库失败,由于数据库还是旧数据,缓存中为空,数据不会不一致
3.2 数据一致性问题
在删除缓存和更新数据库操作之间的读请求,会从数据库读取旧数据然后写入到缓存中导致数据不一致。
4.先更新数据库再删除缓存
4.1 两个操作事务性操作情况如下:
1) 更新数据库成功,删除缓存成功
2 )更新数据库失败,程序异常,不会进行删除缓存操作
3 )更新数据库成功,删除缓存失败,由于数据库是新数据,缓存是旧数据,数据出现不一致
4.2 补偿机制
- 删除失败重试,如果删除缓存失败,需要把此信息发送到消息队列,进行异步删除
- 监听数据库变更,建立一个服务监听binlog变化,然后删除缓存。
4.3 数据一致性问题
出现数据不一致的条件是否苛刻,基本不会出现
5.延时双删
先更新数据库再删除缓存已经很好的解决了缓存和数据库一致性问题。但是现在的数据库基本都是进行了主从配置,也就是主库负责数据写入,从库负责数据读取。这样在数据同步到从库之前,可能读取从库旧数据然后写入缓存导致数据不一致。
5.1 延时双删操作流程:
1) 先删除缓存,可以加快缓存与数据库数据同步速度(高并发时可能数据库不断有值写入)
2 )更新数据库
3 )延迟一段时间(大于主从同步时间)删除缓存(等待新数据同步到从库)
5.2 延迟双删优化
延迟双删数据库与缓存至少需要等待数据同步到从库才会数据一致。可以在更新数据库之后,将key进行标记,然后立刻删除缓存。当读数据时,如果缓存中没有数据,需要看key是否进行了标记,如果标记了需要从主库读取数据人然后保存到缓存,并删除此标记。
此方案相当于牺牲了主库的一部分性能,来尽可能保证数据一致性。
总结
缓存是提高系统响应和吞吐量的一个方法,但是使用过程中需要解决缓存穿透、缓存击穿、缓存雪崩等问题,并且需要考虑缓存和数据库的数据一致性问题。如果考虑到程序的可靠性,建议程序对缓存是弱依赖,也就是即使缓存系统完全不可用,也可以保证程序在响应速度和吞吐量降低的情况下,运行的正确性和数据的完整性。