【图像分割 2024 ICLR】Conv-LoRA
论文题目:CONVOLUTION MEETS LORA: PARAMETER EFFICIENT FINETUNING FOR SEGMENT ANYTHING MODEL
中文题目:卷积满足lora:分段任意模型的参数有效微调
论文链接:https://arxiv.org/abs/2401.17868
论文代码:https://github.com/autogluon/autogluon
论文团队:清华大学
发表时间:
DOI:
引用:
引用数:
摘要
分割任意模型(SAM)是图像分割的基本框架。虽然它在典型场景中表现出显著的零射击泛化,但当应用于医学图像和遥感等专业领域时,其优势就会减弱。为了解决这一限制,本文介绍了一种简单而有效的参数高效微调方法——卷积- lora。通过将超轻量级卷积参数集成到低秩自适应(Low-Rank Adaptation, LoRA)中,卷积LoRA可以将图像相关的归纳偏差注入到普通的ViT编码器中,进一步强化SAM的局部先验假设。值得注意的是,卷积lora不仅保留了SAM广泛的分割知识,而且恢复了SAM受前景-背景分割预训练限制的高级图像语义学习能力。在跨多个领域的各种基准测试中进行的综合实验强调了ConvLoRA在将SAM应用于现实世界的语义分割任务方面的优势
1. 介绍
近年来,AI社区出现了一系列基础模型的爆炸式发展,如CLIP (Radford et al ., 2021)、GPT-4 (OpenAI, 2023)和viti - 22b (Dehghani et al ., 2023)。最近,Segment Anything (SAM) (Kirillov et al, 2023)作为图像分割的基础模型出现了,SAM是一个在超过10亿个掩模和1100万张图像上进行预训练的提示模型。尽管它在通用目标分割上的零射击性能令人印象深刻,但在某些领域的许多现实世界分割任务上表现不佳(Tang等人,2023;Ji et al ., 2023;Zhou et al ., 2023),例如自然图像(Borji et al ., 2019;Fan et al ., 2020a)、农业(Sriwastwa et al ., 2018)、遥感(Xu et al ., 2018)和医学图像(Fan et al ., 2020b)。
遵循预训练-调整范式(Dosovitskiy et al ., 2020;他等人,2022;Liu et al ., 2021a),在下游任务上对SAM进行微调以提高其性能是很自然的。然而,现有的作品(Zhang & Liu, 2023;Chen et al ., 2023;Shaharabany等人,2023)未能分析或解决SAM固有的某些限制。1) SAM的图像编码器是一个普通的ViT,众所周知,它缺乏视觉特定的归纳偏差(Chen et al, 2022),这对密集预测很有用。2) SAM的预训练本质上是一个二元掩码预测任务,在给定一个提示的情况下,它将前景对象从背景中分离出来。低级掩模预测预训练阻碍了SAM捕获高级图像语义信息的能力,这些信息对于多类语义分割等任务至关重要。
为了解决上述限制并保留SAM在预训练中获得的有价值的分割知识,我们对一小部分(额外的)模型参数进行微调,同时冻结SAM的大部分预训练权值,因此称为参数有效微调(PEFT)。这就提出了一个问题:PEFT能不能
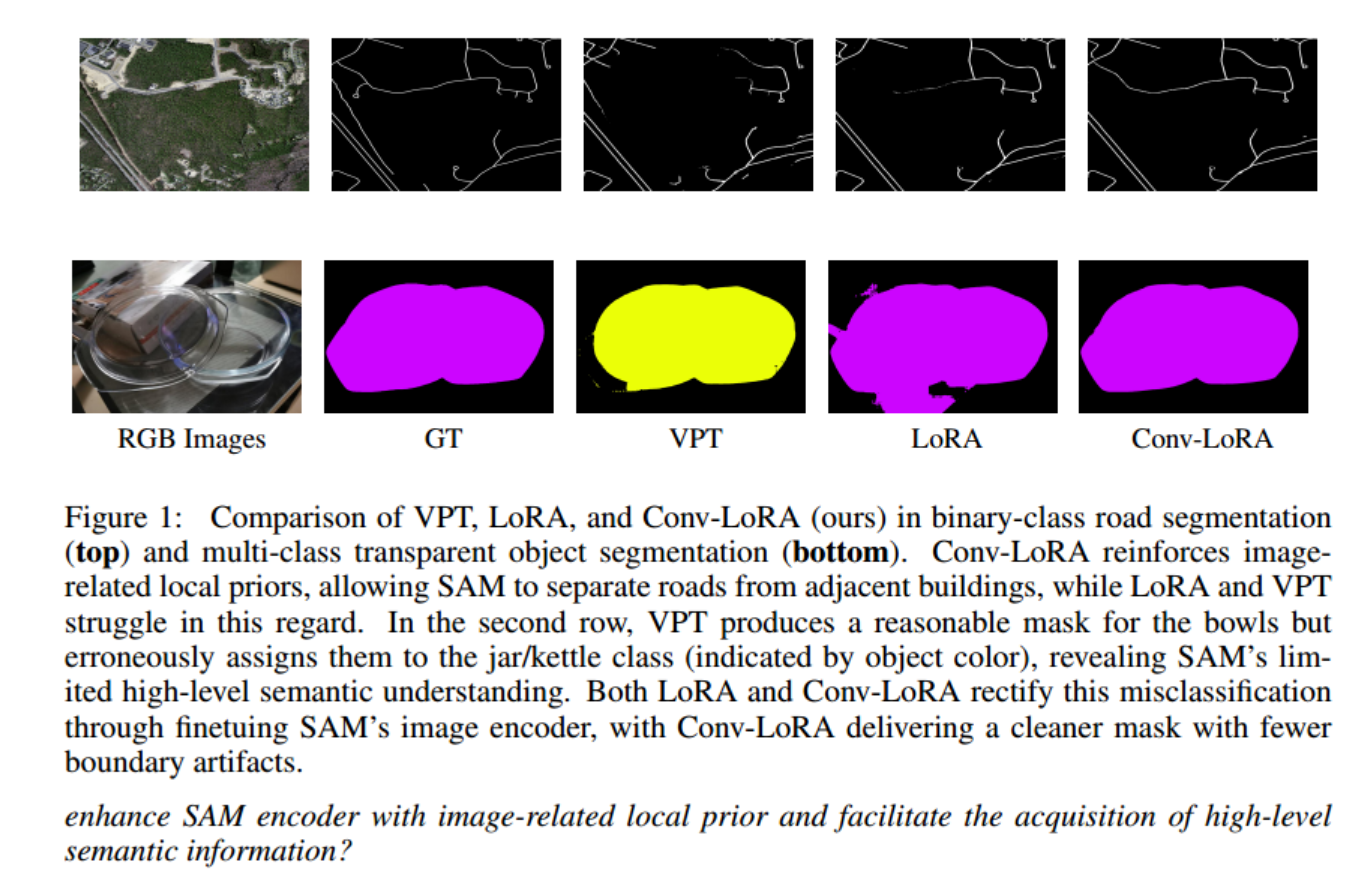
在本文中,我们通过深入研究低秩自适应(Low-Rank Adaptation, LoRA),提出了一种新的PEFT方法,命名为卷积-LoRA (Hu et al ., 2021)。LoRA在SAM编码器的每个变压器层中引入了精简的可训练线性投影层,从而帮助恢复SAM编码器提取高级语义信息的能力。我们的实验表明,LoRA优于广泛采用的视觉提示调优(visual prompt tuning, VPT) (Jia et al ., 2022),特别是在多类语义分割任务中。在LoRA的基础上,卷积-LoRA在瓶颈结构中集成了轻量级卷积层。卷积可以通过局部空间操作引入与图像相关的局部先验(即像素与其相邻像素的相关性强于其远处像素)(Chen et al, 2022)。
此外,考虑到目标尺度的潜在变化,必须将局部先验注入到图像特征的适当尺度中。为此,卷积- lora从混合专家(MoE)的概念中获得灵感(Shazeer等人,2017),并结合了多个并行卷积专家,每个专家都专注于不同的特征尺度。考虑到ViT以固定的尺度处理图像特征,通常从原始分辨率降采样16倍,卷积- lora中的每个专家最初以特定的尺度恢复图像特征,应用卷积操作,然后将特征恢复到默认尺度。与vit适配器(Chen et al ., 2022)和Swin Transformer等视觉专用变压器(Liu et al ., 2021a)相比,卷积- lora提供了一种隐式的方式来强制执行多尺度局部先验,假设它可以利用默认尺度的图像特征来重建更高尺度的特征信息。幸运的是,SAM的监督预训练涉及到各种尺度的掩模,使ViT能够获得超出默认尺度的图像特征知识。
本着PEFT的精神,我们还删除了提示编码器,并在掩码解码器中添加了轻量级mlp,用于多类预测。这个简单的修改将SAM转换为一个端到端模型,可以在二进制和多类语义分割应用程序上进行微调。总的来说,我们的贡献可以总结如下:
- 我们提出了一种创新的pet技术convo - lora。通过引入补充卷积运算,convl - lora从处理普通ViT的局限性的角度加强了SAM的局部先验。
- 卷积- lora使用MoE对动态选择适当特征尺度的过程进行建模,以注入特定于视觉的归纳偏差。
- 我们的研究表明,SAM的预训练阻碍了其ViT编码器学习高级图像语义信息的能力。但是,LoRA展示了帮助SAM恢复这一关键能力的潜力。
- 我们进行了广泛的基准测试,涵盖不同的领域,包括自然图像、农业、遥感和医疗保健。卷积- lora在各种下游任务中始终表现出优于其他PEFT技术的性能。
2. 相关工作
2.1 参数有效微调(PEFT)。
参数高效微调(PEFT)通过有选择地微调一小部分模型参数,同时保持大部分参数不变,从而最大限度地减少计算和存储需求。PEFT包括基于适配器的技术、选择性参数调优、提示驱动的微调和自然语言处理(NLP)中出现的低秩自适应(LoRA)等方法。在适配器范式中(Houlsby等人,2019;Hu et al ., 2021;Sung等人,2022),在变压器层内插入紧凑型模块,以及其他方法(Guo等人,2020;Zaken等人,2021)涉及对预训练主干的一小部分参数进行微调。即时调谐(Lester et al ., 2021;Li & Liang, 2021)为输入或中间序列添加了自适应令牌,LoRA (Hu et al, 2021)在变压器层中引入了可训练的低秩矩阵,用于权重更新。
PEFT技术在计算机视觉(CV)领域也被证明是有效的。视觉提示调谐(VPT) (Jia et al ., 2022)将提示调谐概念(Lester et al ., 2021)应用于图像分类,而尺度和移位特征调制(SSF) (Lian et al ., 2022)使用尺度和移位参数来调制图像分类器中的视觉特征。Convpass (Jie & Deng, 2022)引入了卷积瓶颈来提高ViT在图像分类中的性能。在我们的研究中,我们专注于在语义分割任务中为SAM开发PEFT,特别是在默认尺度之外执行多尺度局部先验,将我们的方法与Convpass区分开来。
2.2 分割模型。
FCN (Long et al ., 2015)是一种关键的深度图像分割模型,它直接从图像中生成逐像素分割图。U-Net (Ronneberger et al ., 2015)采用具有跳过连接的编码器-解码器结构来保留细粒度的空间信息。Deeplab (Chen et al ., 2017a)为多尺度上下文集成了非均匀(扩展)卷积,而PSPNet (Zhao et al ., 2017)使用金字塔池模块。DANet (Fu et al ., 2019)、SANet (Zhong et al ., 2020)和EMA (Li et al ., 2019)利用了上下文依赖的注意机制。变压器架构,如PVT (Wang等人,2021)、Swin (Liu等人,2021b)、CvT (Wu等人,2021)、CoaT (Xu等人,2021)、LeViT (Graham等人,2021)、Segformer (Xie等人,2021a)和PVT v2 (Wang等人,2022)带来了各种改进。SAM (Ji et al, 2023)是分割领域的最新突破,它提供了一种通用的方法来分割图像中不同的物体和区域。由于预训练数据集中缺乏高级语义信息和潜在的领域偏差,建议对下游任务进行微调SAM。
2.3 微调SAM
一些先前的作品(Chen et al ., 2023;张刘,2023;Wu等,2023;Chai et al ., 2023;Shaharabany等,2023;Hu et al ., 2023;Wang等人,2023)探索下游任务的微调SAM。这些方法包括调整SAM的掩码解码器或将参数有效的调整方法与SAM的图像编码器集成。其中一些(例如,Chen et al ., 2023;张刘,2023;Shaharabany等人,2023))提供端到端解决方案来自动化SAM。我们的方法进一步解决了SAM图像编码器的结构限制,通过引入卷积操作来捕获视觉特定的归纳偏差。SAM的预训练阻碍了其ViT编码器学习高级语义信息的能力。我们还将SAM转换为端到端的语义分割模型,并对体系结构进行了较小的调整。
2.4 Mixture-of-Experts
混合专家(MoE)的目的是扩大模型容量,同时引入较小的计算开销。MoE层利用多个专家来增强模型容量,同时使用门控网络来调节稀疏性以节省计算量。前馈网络(FFN)通常被用作专家的默认选择(Shazeer等人,2017;Riquelme等人,2021;Bao等,2022;Du et al ., 2022;Zhou et al ., 2022;Fedus et al, 2022)。一些努力(Zuo et al ., 2021;Zhou et al ., 2022)专注于更有效的门控机制。
在我们的工作中,我们利用了MoE的概念,而不是为了改进它。我们从三个方面比较了我们工作中使用的MoE与原始MoE: 1) MoE的原始目标是在不过度增加计算开销的情况下扩展模型容量,而我们的目标是在不同尺度的特征映射中动态注入局部先验。2) MoE专家的结构通常是相同的,而我们的不是。每个专家都专门从事特定的缩放操作在我们的方法中。3)虽然MoE主要用于预训练,但我们将MoE作为下游任务的参数高效调优的一部分。
3. 方法
3.1 Conv-LoRA
LoRa。首先,让我们简要回顾一下LoRA的设计(Hu等人,2021),它使用编码器-解码器结构对权重更新施加低秩约束(图2 (a))。它冻结了预训练的模型权重,并将小的可训练秩分解矩阵注入到变压器体系结构的每一层。具体来说,给定一个预训练的权矩阵 W 0 ∈ R b × a W_0\in\mathbb{R}^{b\times a} W0∈Rb×a, LoRA在其旁边增加一对线性编码器 W e W_e We和解码器 W d W_d Wd,即可训练的秩分解矩阵。我们和Wd满足低秩约束,我们 W e ∈ R r × a , W d ∈ R b × r \begin{aligned}W_{e}\in\mathbb{R}^{r\times a},W_{d}\in\mathbb{R}^{b\times r}\end{aligned} We∈Rr×a,Wd∈Rb×r, r ≪ m i n ( a , b ) r\ll min(a,b) r≪min(a,b)。
使用LoRA时,正向传递由 h = W 0 x h=W_{0}x h=W0x变为:
h = W 0 x + W d W e x h=W_0x+W_dW_ex h=W0x+WdWex
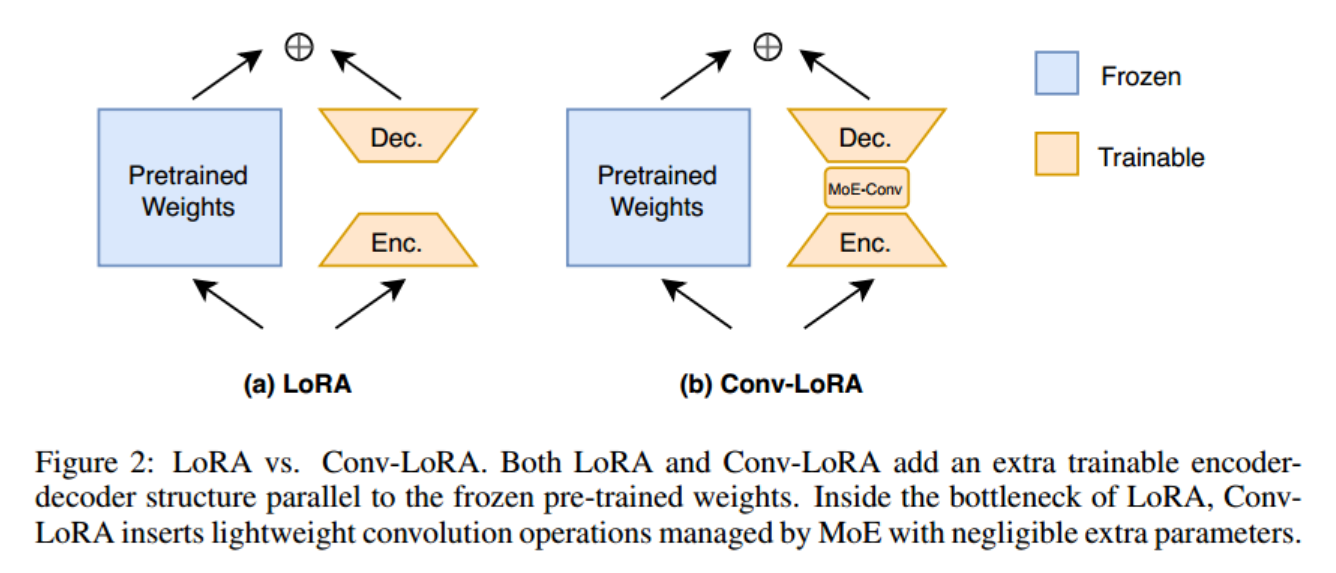
Conv-LoRA旨在将LoRA的编码器和解码器组件之间的卷积操作结合起来(图2 (b))。一方面,卷积可以注入图像相关的局部先验,解决了传统ViT的基本限制;另一方面,低秩约束确保卷积层保持非常轻量级,保留了卷积- lora的PEFT性质。
在设计卷积lora时,需要考虑的一个关键问题是确定特征映射的尺度,在该尺度上引入局部先验。虽然ViT中的特征映射在比例上是统一的,但对象掩码通常包含广泛的比例。因此,在合适的尺度上应用卷积运算是至关重要的。为了应对这一挑战,我们从混合专家(MoE)的概念中汲取灵感(Shazeer等人,2017)。MoE由多个专家网络和一个门控模块组成,门控模块动态选择在前向传递过程中激活哪些专家(图3)。将这一概念应用于卷积- lora,每个专家专攻特定比例的特征映射的卷积,一个紧凑的门控模块学习根据输入数据动态选择专家。数学上,通过卷积lora, eq.(1)变为:
h = W 0 x + W d ( ∑ i n G ( W e x ) i E i ( W e x ) ) h=W_0x+W_d(\sum_i^nG(W_ex)_iE_i(W_ex)) h=W0x+Wd(i∑nG(Wex)iEi(Wex))
式中, W 0 ∈ R C o u t × C i n , W e ∈ R r × C i n , W d ∈ R C o u t × r , x ∈ R B × C i n × H × W W_0\in\mathbb{R}^{C_{out}\times C_{in}},W_e\in\mathbb{R}^{r\times C_{in}},W_d\in\mathbb{R}^{C_{out}\times r},x\in\mathbb{R}^{B\times C_{in}\times H\times W} W0∈RCout×Cin,We∈Rr×Cin,Wd∈RCout×r,x∈RB×Cin×H×W。B为批量大小, C i n / C o u t C_{in}/C_{out} Cin/Cout为输入/输出通道数,H和W分别对应高度和宽度。
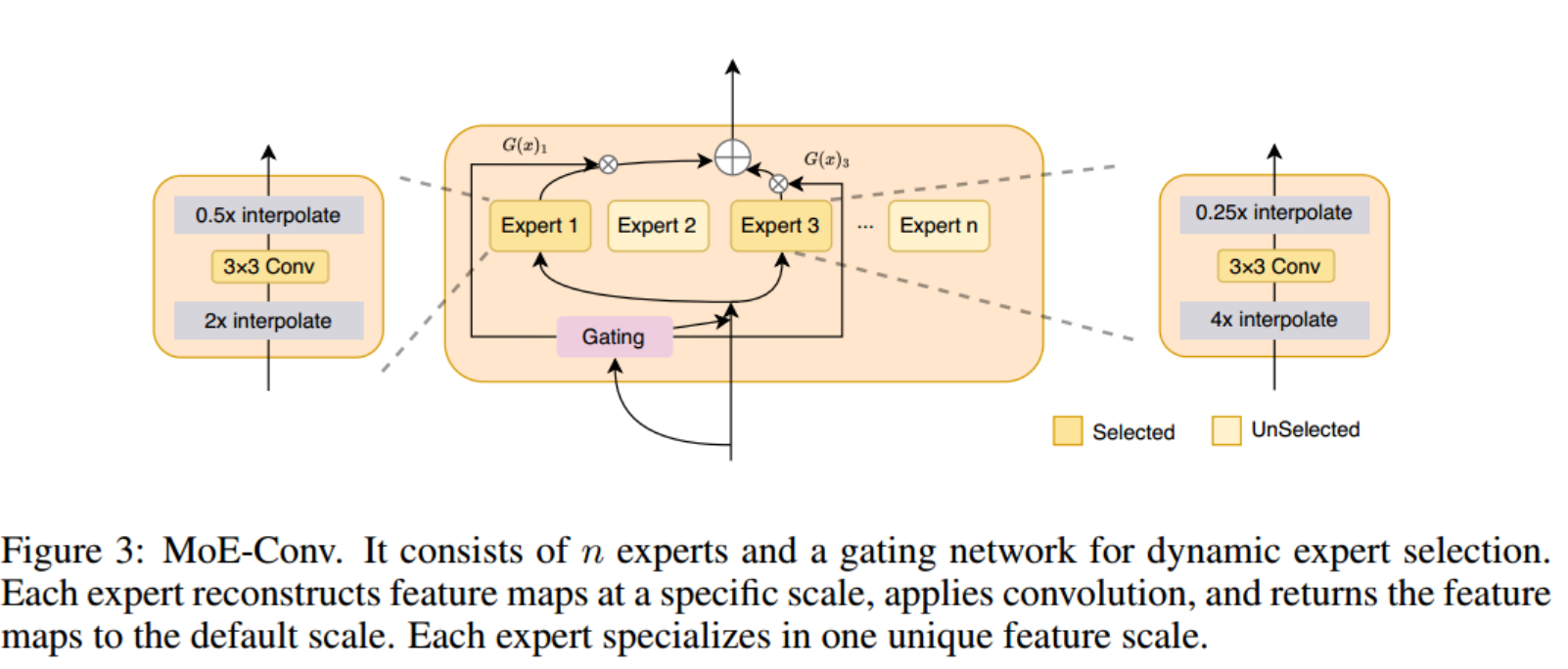
他是n个专家中的第1个。G是仅激活top-k(默认为1)值的门控网络。有关门控的更多细节,请参阅附录A。
在每个专家层中,三个关键操作依次进行:按特定比例重建特征图的插值函数、3 × 3 卷积层和随后的插值函数。以特定比例重建特征图、3 × 3 卷积层,以及随后的插值操作,将特征图映射回 ViT 的默认特征比例。假设专家 Ei 负责比例 s i s_i si,我们可以将其表述为
E i ( x ) = Interpolate ( Conv 3 × 3 ( Interpolate ( x , s i ) ) , 1 / s i ) E_i(x)=\text{Interpolate}(\text{Conv}_{3\times3}(\text{Interpolate}(x,s_i)),1/s_i) Ei(x)=Interpolate(Conv3×3(Interpolate(x,si)),1/si)
例如,如果 s i = 4 , s_{i}=4, si=4,专家Ei最初会将特征映射放大4倍,应用 C o n v 3 × 3 \mathrm{Conv}_{3\times3} Conv3×3操作,最后将特征映射缩小4倍。
MoE vs.多尺度。与教育部相比,另一种解决不同规模的方法是采用多规模战略。该方法利用多个分支在不同尺度上并发注入局部先验,并对结果进行聚合。虽然看起来更直接,但与MoE相比,这种方法的计算成本更高。MoE的效率源于它有选择地激活稀疏专家的能力,从而最小化了计算开销。鉴于我们优先考虑高效的微调,我们支持MoE作为一个有洞察力的选择。
3.2 使用Sam进行端到端多类分割
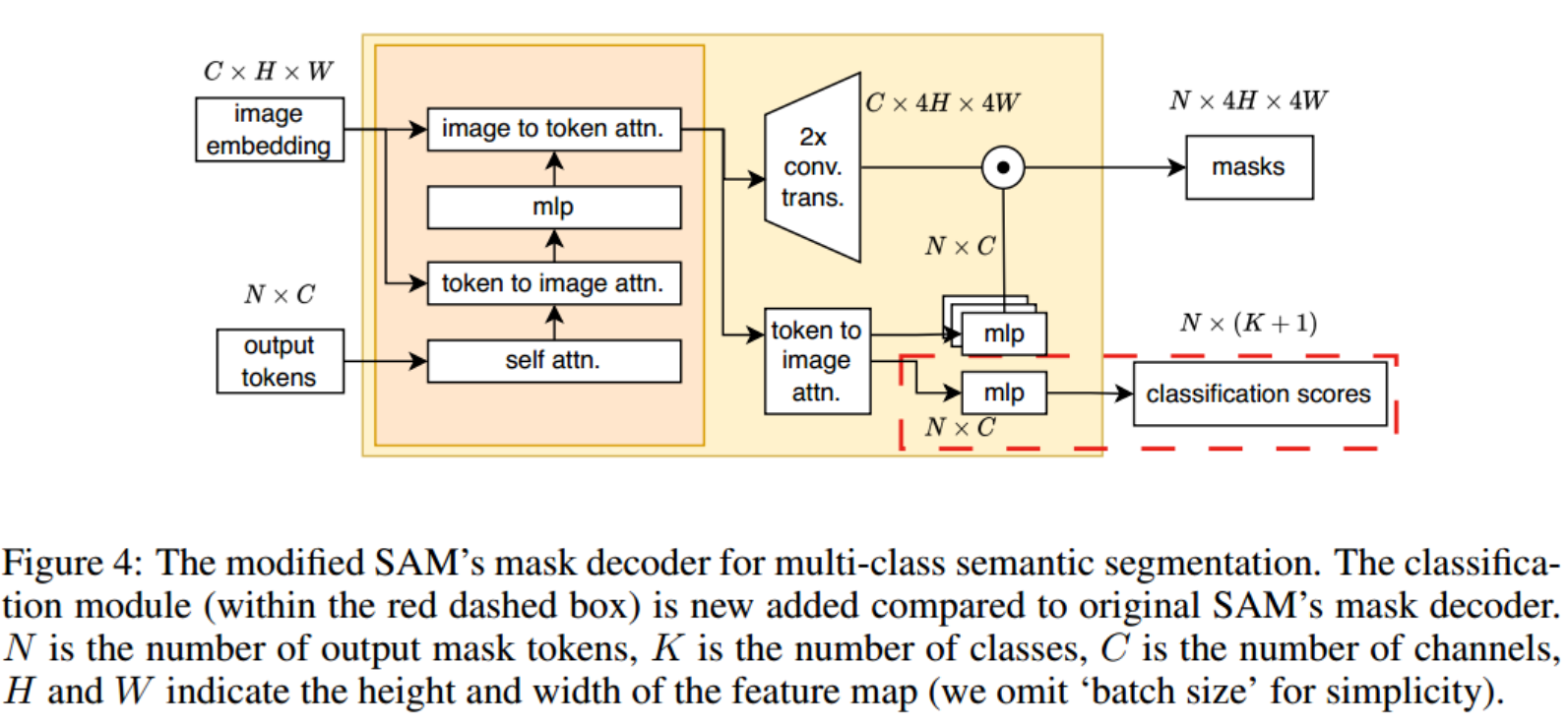
SAM包括三个基本组件:图像编码器、提示编码器和掩码解码器。当提供可以采取点、框、掩码或文本形式的图像和提示时,掩码解码器生成与给定提示相关联的对象的掩码。虽然这种基于提示的方法使SAM能够灵活地集成到更大的系统中,例如交互式分割或检测和后续分割的组合,但在实际应用中使SAM成为端到端模型确实存在挑战。为了实现SAM的自动化,我们冻结了提示编码器,因此在对下游任务进行微调时,总是使用恒定的提示令牌来屏蔽解码器。此外,原始掩码解码器设计用于预测二进制掩码,根据给定的提示区分前景和背景。为了使SAM适应多类语义分割任务,我们在掩码解码器中引入了一个简单的分类分支(如图4中红色虚线框所示)。这个额外的分支负责预测分类分数。此外,我们对掩码解码器进行了全面微调,因为它是一个轻量级模块。如需更全面的信息,请参见附录B。
4. 实验
设置。
我们在医学图像、自然图像、农业和遥感四种现实场景下进行了一些实验。我们使用批大小为4和Adam优化器,学习率为1×10−4作为默认值,权重衰减为1×10−4。对于我们在农业和遥感中使用的数据集,发现3 × 10−4的较大学习率是有用的。在训练过程中,随机水平翻转作为数据增强。除非另有说明,否则所有方法都训练30个具有结构损失(即加权IoU损失和二元交叉熵损失的组合)的epoch。此外,我们的卷积lora遵循Shazeer等人(2017),引入额外的损失来平衡专家之间的利用率。对于二类和多类语义分割,额外损失的权重分别设置为1.0和2.0。默认情况下,我们将专家的数量设置为8,每个专家专门研究一个缩放比例连续范围为1 ~ 8。我们将卷积LoRA应用于自关注层的查询、键和值矩阵,与LoRA的方法相同。
数据集。
我们的实验涵盖了来自各个领域的语义分割数据集,包括自然图像、医学图像、农业和遥感。在自然图像领域,我们探索了两个特定的任务:伪装对象分割(Fan et al ., 2020a;Skurowski等人,2018;Le et al, 2019)和阴影检测(Vicente et al, 2016)。在医学分割中,我们研究了息肉分割(Jha等,2020;Bernal et al, 2015;Tajbakhsh等,2015;Vazquez等人,2017;Silva等人,2014)和皮肤病变分割(Codella等人,2018)。对于农业和遥感,我们分别采用叶片病害分割(Rath, 2023)和道路分割(Mnih, 2013)数据集作为代表性示例。我们还使用具有3个类的Trans10K-v1 (Xie et al ., 2020)和具有12个细粒度类的Trans10K-v2 (Xie et al ., 2021b)探索了多类透明对象分割。关于每个数据集的更多细节可以在附录C中找到。
基线。
我们将该方法与以下方法进行了比较:
- 只微调SAM的掩码解码器。
- BitFit (Zaken et al, 2021),它只对预训练模型中的偏差项进行微调。
- 适配器(Houlsby等人,2019),在变压器层之间插入可训练的瓶颈层。
- SAM-Adapter (Chen等人,2023),它进一步调整补丁嵌入特征,并为低级语义分割任务学习高频组件的额外嵌入。这是将PEFT方法应用于SAM的先驱性工作之一。
- VPT (Jia et al, 2022),它为每个变压器层的隐藏状态插入可学习的令牌。
- LST (Sung et al ., 2022),它插入了一个与冷冻骨干网平行的可训练侧网络。为了控制可训练参数的数量,侧适配器网络采用预训练的viti - tiny模型,类似于SAN (Xu et al ., 2023)。冻结骨干网和侧适配器网络的特征在SAM的全局关注层融合。
- SSF (Lian et al ., 2022),它在训练过程中插入可学习的尺度和移位参数来调节视觉特征。
- LoRA (Hu et al ., 2021)插入平行于冻结线性权值的可训练瓶颈层。
为了遵守页面限制,我们选择了不同领域的代表性数据集来报告主要实验结果。完整的实验结果见附录D。所有PEFT方法的实验都运行了三次,以减轻随机性。平均值和标准误差见表1。