说明
向量化将会是下一阶段演进的目标。
在过去的实践中,向量或者矩阵其实是最贴近工具端的。
以sklearn为例,虽然原始数据可能还是自然语言,但是在最终执行 fit或者predict之前,数据一般都转为了矩阵形态(numpy)。也就是说,在pandas(原始数据)和最终结果(predict result)之间,是(短暂且必然)存在过矩阵的。
后来,应该是有过类似以图搜图类的应用,向量化且持久化在数据库中开始兴起。
之后,大规模向量化且持久化是从大语言模型爆火开始的:因为大量的中间结果需要重算(为向量),那么不如将中间结果固定住,需要的时候调用存储就可以了。
所以一个明显的趋势是,如果某项业务需要长期的演进,就需要大量的迭代计算。这些计算很难直接在原始数据上进行,所以将原始数据保存为向量既是一种规范(即进行特征与计算机语言的转译),同时也是迭代计算的前提。其重要性和必要性应该无需再进行讨论。
在当前的工作中,我恰好需要对文本进行更深入的处理 ,所以借着机会,边做边梳理。
PS: 大约在几年前,甚至我开始用Bert时,我并没有意识到这个领域的突破会如此具有开创性,我认为至少相当长一段水平,这个领域会保持在差不多的状态。所以过去我一直是抱着以用为主,适当了解的心态做这个领域的事。现在这个观念转变了,以transformer结构为基础的深度学习已经证明可以做到足够商业化的效果。对这个领域进行深入的研究和开发–即使是从现在开始–也会带来巨大的收益。
内容
1 word2vec
早前有整理过word2vec的一些资料(之后要review),这里只是把基本的概念稍微强化一下。
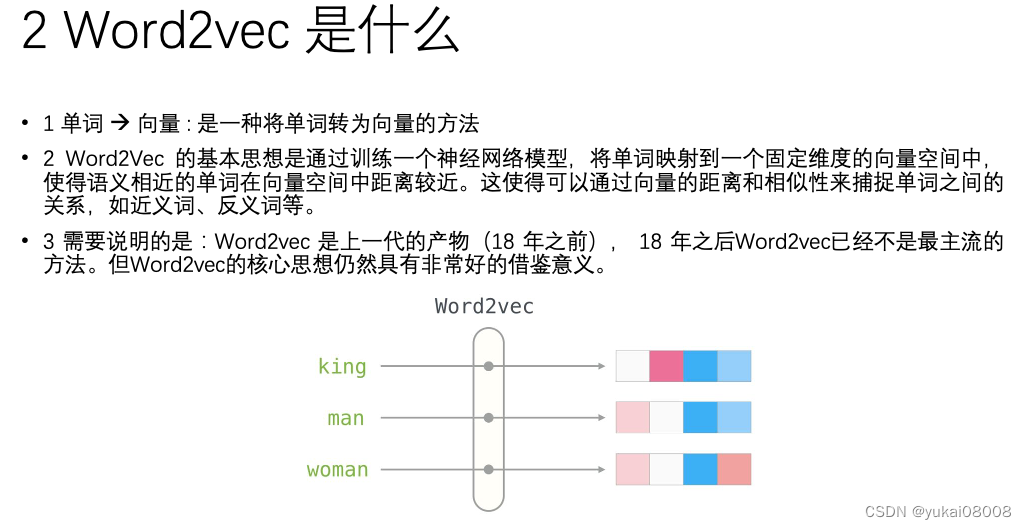
首先,在2018年以前,word2vec还算是比较主流的,是不是bert的出现撼动了它的地位?

其次,word2vec的思想,也就是将单词转为向量,且可进行语义度量(近义词距离近,反义词距离远)应该还是一个比较不变的。
2 m3e
先来看一些实际的使用/测试结果。
首先下载模型包 m3e-base
然后安装一个包
!pip3 install sentence_transformers -i https://mirrors.aliyun.com/pypi/simple/
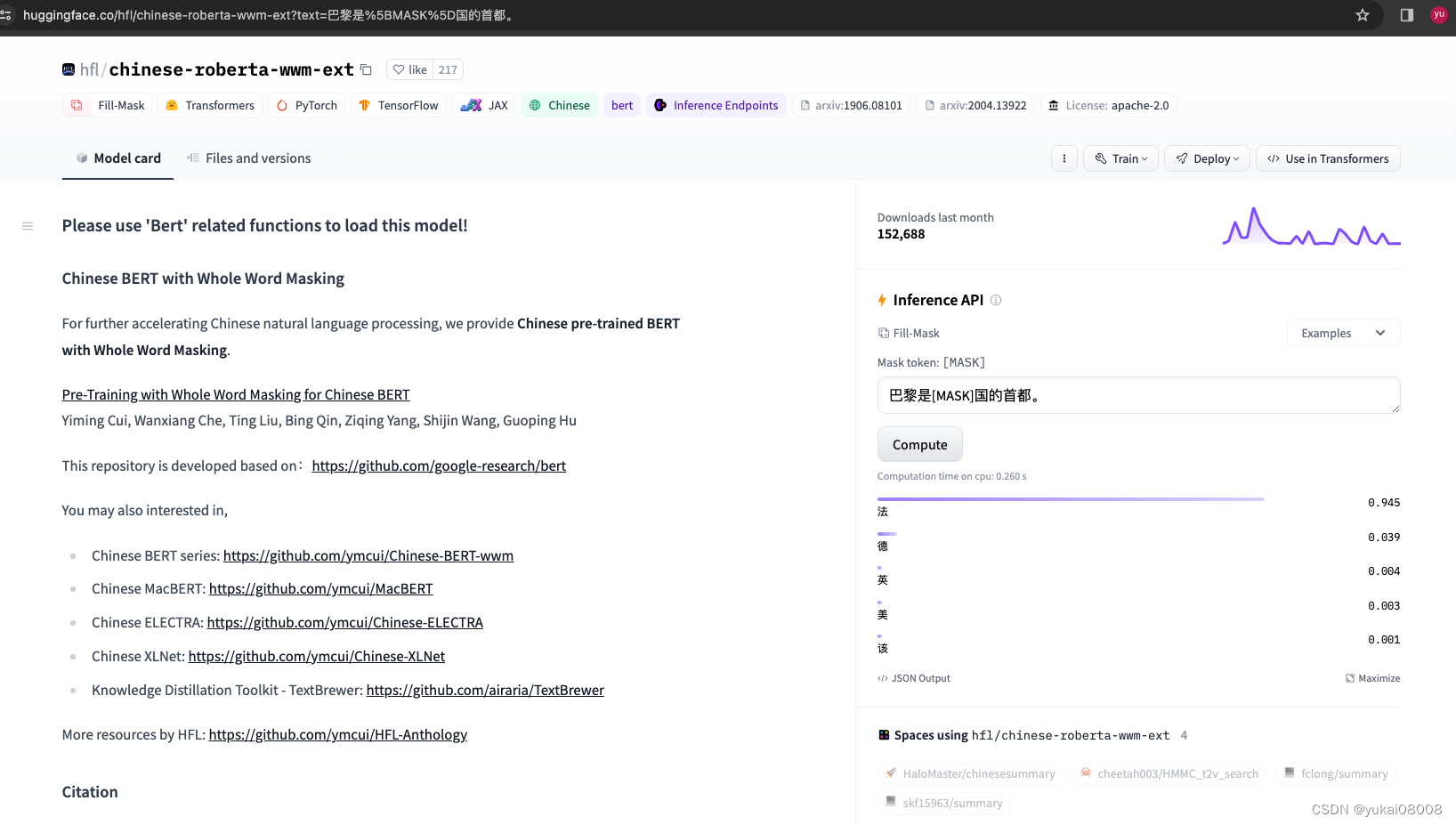
假设我现在有3个query和3个answer,我需要对它们分别进行转换,然后计算他们之前的距离(相似度)。
先导入包,并对查询进行向量转换
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('m3e-base',cache_folder="./m3e-base")
questions = ['存文件', '读取文件','排序']
embeddings = model.encode(questions)
array([[-0.04188242, 0.8120958 , 0.75951165, ..., -0.7462918 ,-0.37102422, -1.1583616 ],[-0.18861888, 0.45038733, 0.7915643 , ..., -0.8806971 ,-0.35007524, -0.9292178 ],[-0.3631838 , 0.10787209, 0.55987704, ..., -1.1905028 ,-1.2330985 , -0.6836705 ]], dtype=float32)
然后对答案也进行向量转换
answer1 = '''import json
# 文件的路径+名称 -> json字符串
def read_file_as_json(fpath = None ):# 读取一个文件with open(fpath, 'r') as f:content = f.read()json_content = json.dumps(content)return json_content'''
answer2 = '''import json
# 存一个文件
def write_json_to_file(json_str = None, fpath = None):rev_content = json.loads(json_str)with open(fpath, 'w') as f:f.write(rev_content)return True
'''
answer3 = '''import json
# 字符串到文件
def write_str_to_file(some_str = None, fpath = None):json_str = json.dumps(some_str)write_json_to_file(json_str, fpath)
'''answers = [answer1, answer2, answer3]
res_embeddings = model.encode(answers)
假设现在计算最符合第一个查询的结果,对应的向量是embeddings[0], 对应的原始查询是「存文件」
import numpy as np
# 计算欧几里得距离
distance1 = np.linalg.norm(embeddings[0] - res_embeddings[0])
distance2 = np.linalg.norm(embeddings[0] - res_embeddings[1])
distance3 = np.linalg.norm(embeddings[0] - res_embeddings[2])
print("欧几里得距离:", distance1,distance2, distance3 )
欧几里得距离: 14.339659 12.545303 13.624656
看起来与第二个答案的向量最为相似,里面有’存…文件’的类似文本。
如果要并发执行距离计算,那么通过
# 一次计算欧式距离
distances = np.linalg.norm(embeddings[0]-res_embeddings, axis=1)
array([14.339659, 12.545303, 13.624656], dtype=float32)
如果answer集合的向量特别大,那么可以通过类似milvus这样的向量数据库完成查询。其实本质上也就是分布式并行计算向量。
这算是完成向量转换与相似性计算的使用验证。
整体上说使用还算是比较简单,效果也不错。但是在使用GPU计算上比较麻烦,反正我按说明试着搞了一下,但是还是没成功,也就算了。实际在使用CPU计算速度也还可以,这倒是说明了向量转换这步的计算开销并没有那么大,在工业量产上是可行的。未来自己再开发一版模型就好了。
再测试一下对于长本文的支持,以下是一段测试文本,长度大约为1000
test_txt ='''根据提供的接口文档,ESIO(Elastic Search IO)是用于存储和搜索元数据的服务,它提供了一系列接口来执行数据的存储、查询和删除操作。以下是文档中提到的主要接口和功能的简要说明:### 1. 功能简述ESIO提供数据的存储和查询功能,主要包括以下操作:- 连通性测试:通过访问`/info/`接口来测试服务是否可用。
- 状态检查:通过访问`/stat/`接口查看当前数据库的状态。
- 存一条记录:通过`/save_a_rec/`接口存储一条记录。
- 匹配查询:使用词进行匹配查询,例如按照"first_name"字段进行匹配查询。
- 短语查询:使用短语进行查询,例如要同时满足"rock climbing"短语存在才返回。### 2. 部署方式ESIO依赖ES数据库,使用一键部署方式部署。您可以执行提供的脚本来完成部署。请注意,文档中提供的脚本可能已经过时,因此建议根据实际情况进行调整。### 3. 请求说明文档中提供了不同类型的请求说明,包括:- 连通性测试:通过访问`/info/`接口来测试连接。
- 状态检查:通过访问`/stat/`接口查看数据库状态。
- 存储记录:使用`/save_a_rec/`接口存储一条记录。
- 匹配查询:使用词进行匹配查询,例如按照"first_name"字段进行匹配查询。
- 短语查询:使用短语进行查询,例如要同时满足"rock climbing"短语存在才返回。### 4. v1.1 丰富增删改查文档还提到了v1.1版本的功能增强,包括更多的增删改查操作。这些操作包括:- 创建记录:使用`create_a_rec_with_id`接口以主键存入一条记录。
- 覆盖存入记录:使用`index_a_rec_with_id`接口以主键覆盖存入一条记录。
- 删除记录:使用`del_a_rec_with_id`接口以主键删除一条记录。
- 获取记录:使用`get_a_rec_with_id`接口获取一条记录。
- 更新记录:使用`update_a_rec_with_id`接口以主键覆盖更新一条记录。
- 批量操作:使用`bulk_opr`接口实现批量操作,包括创建、删除、更新和索引。
- 批量获取:使用`mget_with_id_list`接口根据id批量获取记录。这些功能可以帮助用户进行更灵活的数据操作和管理。请注意,具体的请求和响应参数需要根据实际使用情况和数据结构进行配置。文档中提供了一些示例代码,可供参考。'''
在原始长度上乘以200倍,大约为20万字。
embeddings = model.encode([test_txt*200])
结果是仍然可以很快转为768维向量,测试结束。
3 关于m3e
既然m3e的向量化可以满足需求,这时候不妨回过头看看这个模型本身的信息。

可参考文章1
发布的公司:似乎是一家叫闻达的公司
适用的场景:主要是中文,少量英文的情况,支持文本相似度、文本检索
版本:base版的相对好
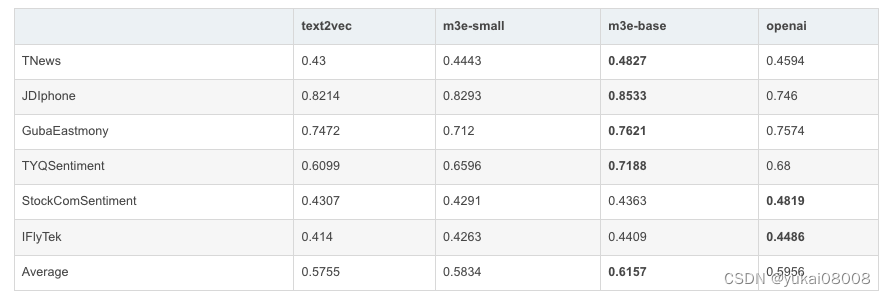
关于几类任务的表现
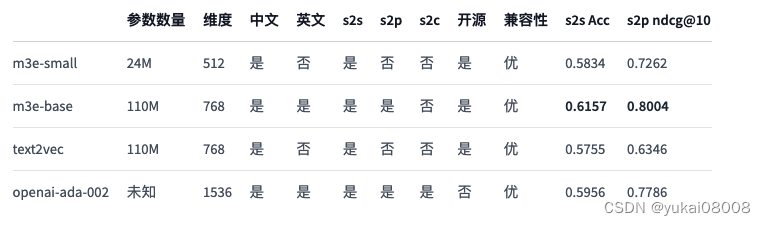

就目前而言,我更关注s2s的应用:相似度、重复、分类。

注意,这里提到了m3e是基于bert模型训练的。
联想到m3e的向量长度是768,和Bert一致,这说明了在这个长度上,应当足以应对一般的语言问题。当然,如果条件允许的话,用更长的向量应该也是ok的。768或者可以被视为一个下限。

另外transformer架构是成功的,bert和gpt两个家族都是基于这个基础架构衍生出来的。所以,我可以从这个架构开始仔细的研究,从头开始做。
现在重头开始做的最大好处是很多路都有人探过了,资料很多,不会走歪路。另外就是算力供应还算是不错,现在可以租算力搞。
另外,Bert家族的模型证明是比较轻的,容易并行化、工业化;GPT家族相对重一些,但是在一个较小的参数空间上也是可行的,例如6B模型,个人完全也可以搞。
最大的工作和价值则是在于:能不能对attention方法进行更有效的设计;能不能采用类似ensemable的方法,训练较多的小模型综合增强;能不能采用一个体系来进行流水线的生成;能不能采用更好的agent来进行自我调节。
所以下一步,就是开始实践,目标是可以完全自主的重头搭建完全可控的Bert和GPT类模型。
4 部署
4.1 本地镜像
目前本地算力不是那么充足,不过我还是将其作为一项基本任务将其完成,这样未来万一需要长期部署的时候可以省事。
在已有的pytorch镜像上修改,考入模型文件并建立tornado服务的文件
m3e-base server.py server_funcs.py
server.py
from server_funcs import *
import tornado.httpserver # http服务器
import tornado.ioloop # ?
import tornado.options # 指定服务端口和路径解析
import tornado.web # web模块
from tornado.options import define, options
import os.path # 获取和生成template文件路径# 引入模型
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('m3e-base',cache_folder="./m3e-base")app_list = []IndexHandler_path = r'/'
class IndexHandler(tornado.web.RequestHandler):def get(self):self.write('【GET】This is Website for Internal API System')self.write('Please Refer to API document')print('Get got a request test')# print(buffer_dict)def post(self):request_body = self.request.bodyprint('Trying Decode Json')some_dict = json.loads(request_body)print(some_dict)msg_dict = {}msg_dict['info'] = '【POST】This is Website for Internal API System'msg_dict['input_dict'] = some_dictself.write(json.dumps(msg_dict))print('Post got a request test')
IndexHandler_tuple = (IndexHandler_path,IndexHandler)
app_list.append(IndexHandler_tuple)M3EHandler_path = r'/m3e/'
class M3EHandler(tornado.web.RequestHandler):def get(self):self.write('【GET】文本向量化')self.write('Please Refer to API document')print('Get got a request test')def post(self):request_body = self.request.bodyinput_list = json.loads(request_body)res_list = model.encode(input_list)self.write(json.dumps(res_list.tolist()))M3EHandler_tuple = (M3EHandler_path,M3EHandler)
app_list.append(M3EHandler_tuple)if __name__ == '__main__':#tornado.options.parse_command_line()apps = tornado.web.Application(app_list, **settings)http_server = tornado.httpserver.HTTPServer(apps)define('port', default=8000, help='run on the given port', type=int)http_server.listen(options.port)# 单核# 多核打开注释# 0 是全部核# http_server.start(num_processes=10) # tornado将按照cpu核数来fork进程# ---启动print('Server Started')tornado.ioloop.IOLoop.instance().start()server_funcs.py
# 保留,用于提供server.py的引入
# 【引入时处于和GlobalFunc同级别的位置】import json
from json import JSONEncoder
class MyEncoder(JSONEncoder):def default(self, obj):if isinstance(obj, np.integer):return int(obj)elif isinstance(obj, np.floating):return float(obj)elif isinstance(obj, np.ndarray):return obj.tolist()if isinstance(obj, datetime):return obj.__str__()if isinstance(obj, dd.timedelta):return obj.__str__()else:return super(MyEncoder, self).default(obj)# 【创建tornado所需问文件夹】
import os
# 如果路径不存在则创建
def create_folder_if_notexist(somepath):if not os.path.exists(somepath):os.makedirs(somepath)return Truem_static = os.path.join(os.getcwd(),'m_static')
m_template = os.path.join(os.getcwd(),'m_template')create_folder_if_notexist(m_static)
create_folder_if_notexist(m_template)settings = {
'static_path':m_static,
'template_path':m_template
}调用
import requests as req questions = ['存文件', '读取文件','排序']res_list = req.post('http://127.0.0.1:8000/m3e/',json = questions).json()import numpy as np res_arr = np.array(res_list)
这样就完成了镜像准备,以后要用的时候起一个服务就可以了,这个服务只有一个功能:输入文本列表,返回向量列表。
4.2 外部部署
如果短时间有大量的需求,我更情愿使用弹性的算力来解决问题。
用自己的镜像打开一个新容器,root用户的秘钥已经允许m0主机和算网机登录,这样方便从m7拷贝模型文件过去。
其中 /root/autodl-tmp 是系统盘免费30G,/root/autodl-pub 是数据盘,免费50G。
ps: 我发现要用pytorch2.0的容器创建,所以之前的那个镜像不能用

步骤0:修改ssh
在.ssh下面增加秘钥,增加后即刻生效,然后立即禁用密码登录
vim /etc/ssh/sshd_config
PermitRootLogin prohibit-password
MaxAuthTries 6
ClientAliveInterval 60
ClientAliveCountMax 10
PasswordAuthentication no
RSAAuthentication yes
PubkeyAuthentication yes
MaxSessions 10
步骤1:将数据从m7拷贝到/root/autodl-tmp/
rsync -rvltz -e 'ssh -p 18045' --progress /data/model_file/m3e-base root@connect.southb.gpuhub.com:/root/autodl-tmp/
步骤2:安装包pip3 install sentence_transformers -i https://mirrors.aliyun.com/pypi/simple/
步骤3:将server.py和server_funcs.py也拷贝到/root/autodl-tmp/目录下。
步骤4:启动服务。
┌─root@autodl-container-824347b459-10803d25:~/autodl-tmp
└─ $ python3 server.py
Server Started
autodl给了一个jupyter,可以测试

镜像是可以保存的,而且非常厚道,只算用户额外挂载的私有数据,等下次真的需要的时候再保存。