NIO基础
1.三大组件
1.1. Channel & Buffer

Channel
在Java NIO(New I/O)中,“Channel”(通道)是一个重要的概念,用于在非阻塞I/O操作中进行数据的传输。Java NIO提供了一种更为灵活和高效的I/O处理方式,相比于传统的I/O,它具有更好的性能和可扩展性。
常见的Java NIO中的通道类型:
- FileChannel(文件通道):
- 用于文件I/O操作的通道,可以在文件中进行读取、写入和操作。
- SocketChannel(套接字通道):
- 用于TCP协议的通道,可以在网络套接字连接中进行读取和写入数据。(客户端,服务器端都能用)
- ServerSocketChannel(服务器套接字通道):
- 监听新的TCP连接的通道,当有新的连接进来时,可以接受并创建对应的SocketChannel。(只能用于服务器端)
- DatagramChannel(数据报通道):
- 用于UDP协议的通道,可以在网络中发送和接收数据报。
通过使用这些通道,Java NIO可以提供非阻塞的I/O操作,允许程序在一个线程中管理多个I/O操作,提高了系统的并发处理能力和性能表现。通道和缓冲区(Buffer)结合使用,能够实现更灵活、高效的数据传输和处理。
Buffer
在Java NIO中,Buffer(缓冲区)是一个核心概念,用于在通道(Channel)和数据源之间进行数据交互。Buffer实际上是一个容器,用于存储特定类型的数据,并提供了方便的方法来读取和写入数据。
常见的Java NIO中的Buffer类型:
-
ByteBuffer:
- ByteBuffer是最基本的缓冲区类型,用于存储字节数据。
- MappedByteBuffer:
- MappedByteBuffer是ByteBuffer的一个子类,它通过文件通道直接映射到内存中,可以实现高效的文件I/O操作。
- MappedByteBuffer:
- ByteBuffer是最基本的缓冲区类型,用于存储字节数据。
-
CharBuffer:
- CharBuffer用于存储字符数据。
-
ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer:
- 这些是用于存储各种基本数据类型的缓冲区,分别用于存储short、int、long、float和double类型的数据。
这些缓冲区提供了一种灵活的方式来管理数据,可以在缓冲区和通道之间进行数据传输,也可以在缓冲区内部进行数据处理。通过缓冲区,Java NIO实现了高效的I/O操作,可以在同一线程内处理多个通道,提高了系统的并发性能。
1.2.Selector

当使用 Java NIO 进行非阻塞 I/O 操作时,Selector(选择器)是一种关键的组件。它允许单个线程有效地管理多个 Channel,监视它们的状态并且在
至少一个 Channel 准备好进行读取、写入或者连接时,唤醒线程。Selector 的作用是配置一个线程来管理多个 Channel,获取这些 Channel 上发生的事件。这些 Channel 通常工作在非阻塞模式下,因此不会让线程阻塞在一个 Channel 上。Selector 适用于连接数量特别多但流量低的场景,因为它可以有效地利用一个线程来处理多个连接,降低线程创建和上下文切换的开销。
- 非阻塞 I/O:
- Selector 允许程序使用单个线程处理多个 Channel,而不是为每个 Channel 都创建一个线程。这样可以显著减少线程的数量,提高系统的并发处理能力。
- Channel 注册:
- 在使用 Selector 之前,需要将每个 Channel 注册到 Selector 上,并指定感兴趣的事件类型,如读、写、连接等。
- 事件就绪集合:
- Selector 会不断轮询注册在其上的 Channel,当一个或多个 Channel 准备好进行 I/O 操作时,Selector 将返回一个就绪事件的集合。
- 事件驱动的编程模型:
- 应用程序通过监听就绪事件的方式,实现了一种事件驱动的编程模型,根据不同的事件类型执行相应的操作。
- 资源管理:
- 使用完 Selector 后,应及时关闭以释放资源,避免资源泄漏和性能问题。
通过 Selector,Java NIO 提供了一种高效的非阻塞 I/O 模型,使得应用程序能够更好地处理大量并发连接,提高系统的性能和可伸缩性。
2.ByteBuffer
ByteBuffer 是 Java NIO 中用于处理字节数据的缓冲区类之一。它提供了一种灵活的方式来处理字节数据,例如读取、写入、修改、复制等操作。
以下是关于 ByteBuffer 的一些重要特点和用法:
- 容量和位置:
- ByteBuffer 有一个固定的容量,表示它可以存储的最大字节数量。它还有一个位置(position),表示下一个读取或写入操作将要发生的位置。
- 读写操作:
- ByteBuffer 可以被用来进行读取和写入操作。它提供了诸如 put()、get()、putInt()、getInt() 等方法来读取和写入字节数据。
- 字节顺序(Byte Order):
- ByteBuffer 可以配置为使用不同的字节顺序,例如大端字节序(Big Endian)或小端字节序(Little Endian),以适应不同的数据格式。
- 直接缓冲区和非直接缓冲区:
- ByteBuffer 可以是直接缓冲区或非直接缓冲区。直接缓冲区使用操作系统的内存空间,通常性能更好,而非直接缓冲区使用 Java 虚拟机的堆内存。
- 清除、翻转和重绕:
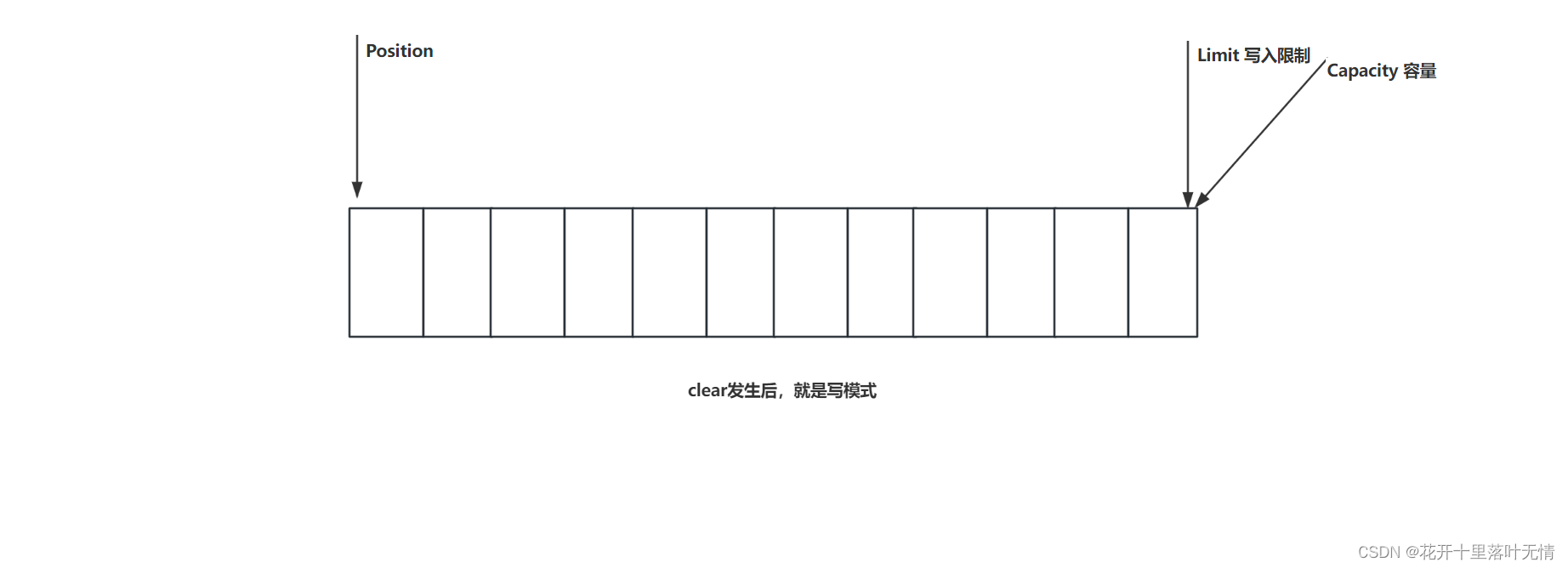
- ByteBuffer 提供了一些方法来处理缓冲区的状态,例如 clear() 方法清除缓冲区中的数据(写模式)、flip() 方法翻转缓冲区以便读取已写入的数据(读模式)、rewind() 方法重绕缓冲区以便重新读取已读数据(写模式)。
- 其他操作:
- ByteBuffer 还提供了一些其他的操作,如 compact() 方法压缩缓冲区、slice() 方法创建一个新的缓冲区视图等。
ByteBuffer 在网络编程、文件 I/O、数据处理等领域广泛应用,它是 Java NIO 中处理字节数据的重要工具之一,提供了高效、灵活的字节数据处理方式。
2.1.案例1-读取文件内容
/*** ByteBuffer 测试测试读取文件* @author 13723* @version 1.0* 2024/2/19 21:30*/
public class ByteBufferTest {private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Test@DisplayName("测试读取文件")public void testReadFile() {// 1.读取文件try (FileChannel channel = new FileInputStream("data.txt").getChannel()) {while (true){// 1.1 创建一个缓冲区(划分一块内存作为缓冲区) 每次读取只取5个字节 5个字节读取完毕后再读取下一个5个字节ByteBuffer byteBuffer = ByteBuffer.allocate(5);// 1.2 读取数据到缓冲区int len = channel.read(byteBuffer);// 读取到文件末尾 len = -1 退出循环if (len == -1) {break;}// 1.3 打印缓冲区的内容// 切换到读模式byteBuffer.flip();while (byteBuffer.hasRemaining()){ // 检查是否存在未读取的数据byte b = byteBuffer.get();logger.error("读取到的字节为:{}", (char) b);}// 1.4 每次读取完成切换为写模式byteBuffer.clear();}} catch (IOException e) {}}
}

2.2.ByteBuffer结构
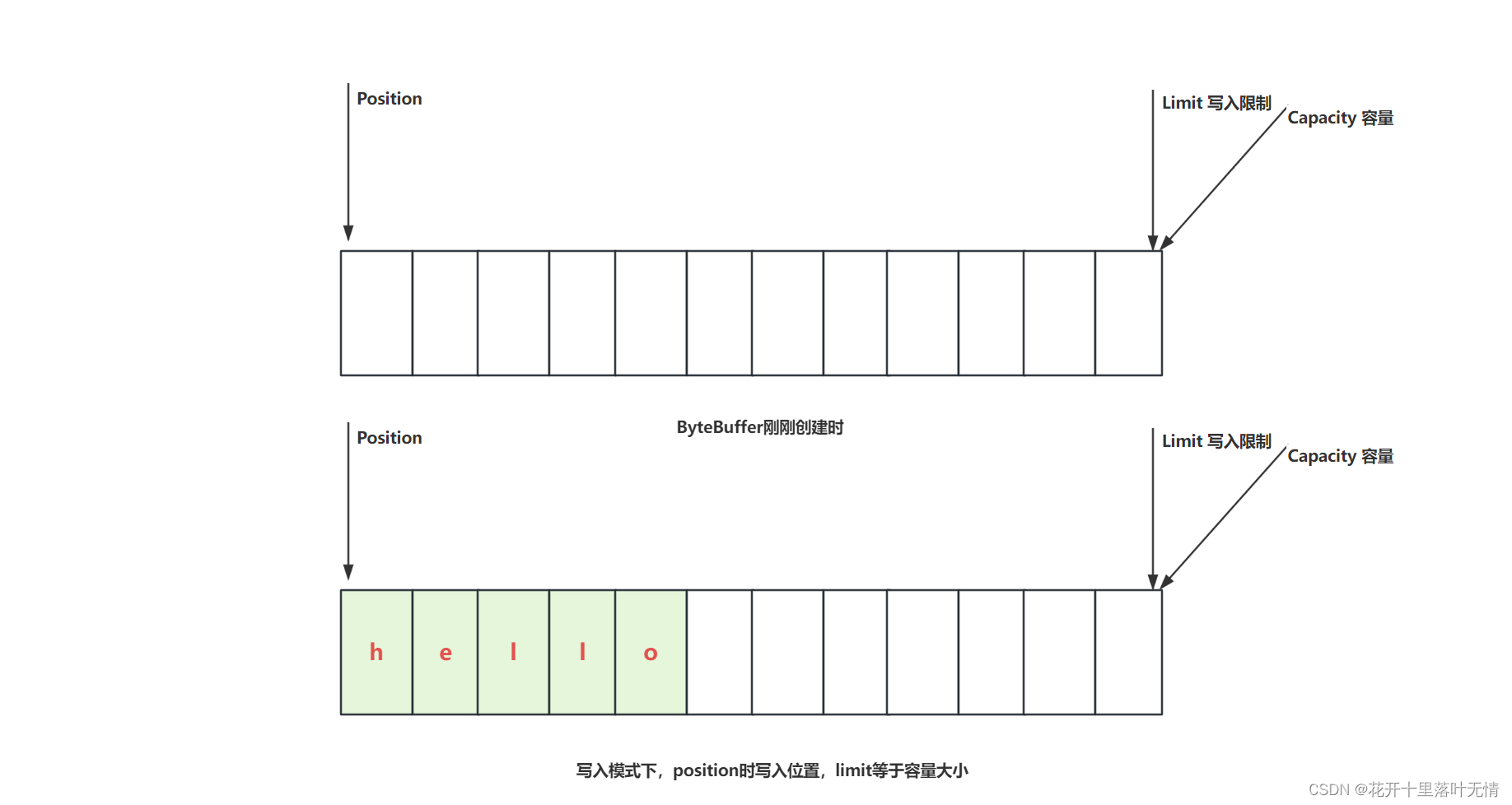
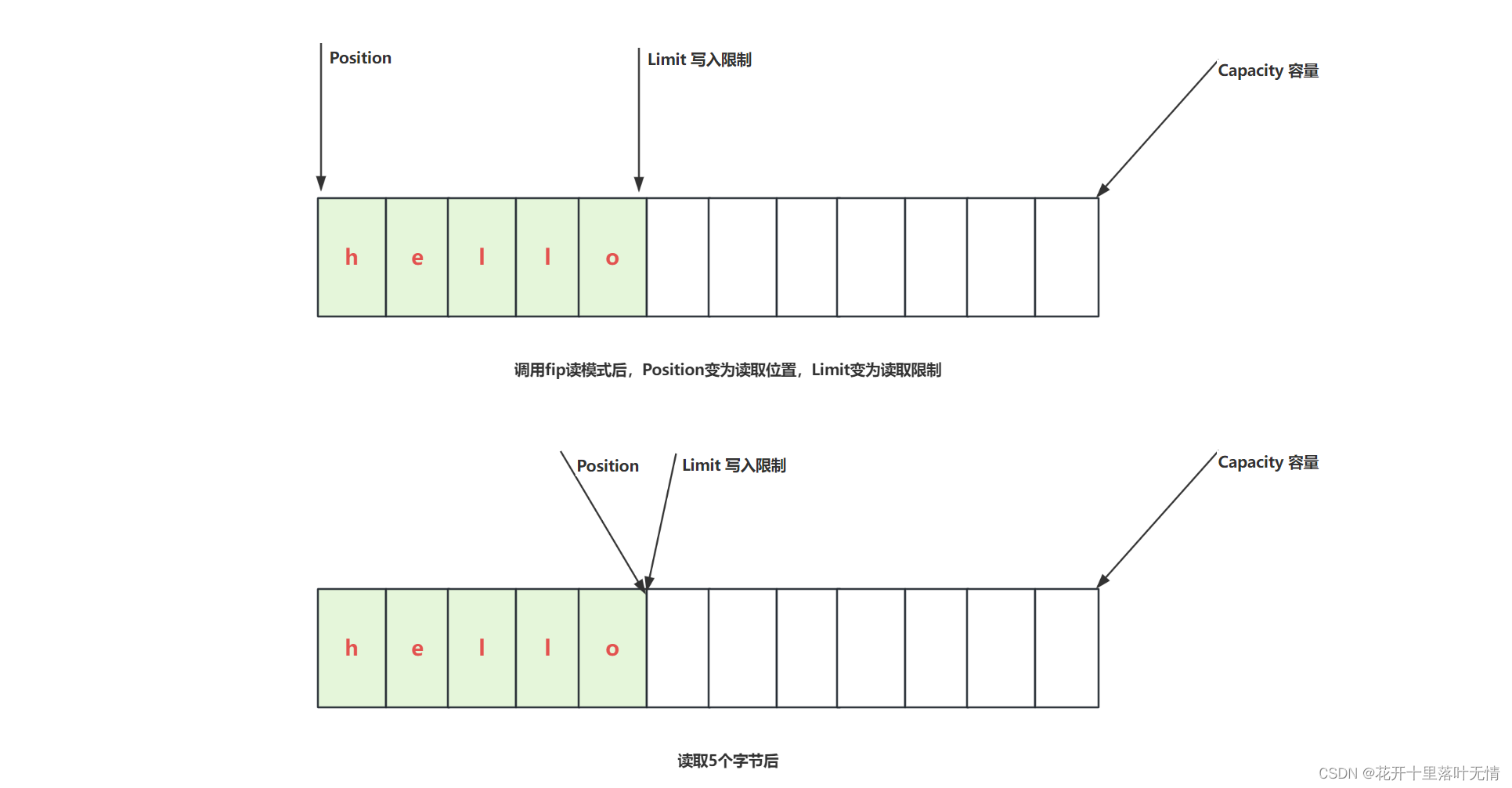
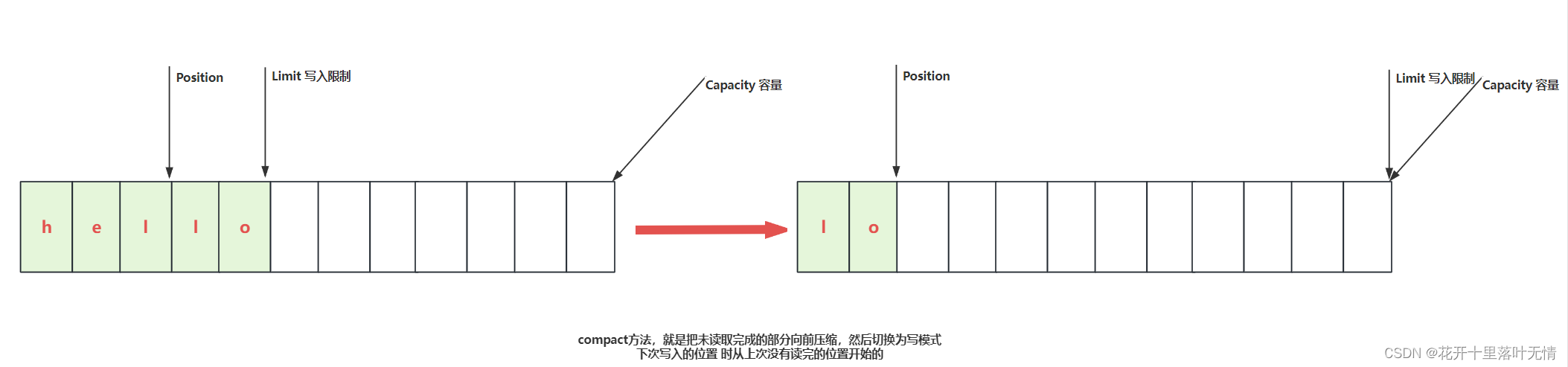
compact方法,就是把未读取完成的部分向前压缩,然后切换为写模式下次写入的位置,是从上次没有读完的位置开始的
2.3.案例2-读取写入数据
@Test@DisplayName("测试ByteBuffer写入读取数据")public void test2(){ByteBuffer buffer = ByteBuffer.allocate(10);// 写入一个字节 ‘a’buffer.put((byte) 'a');// 打印字符debugAll(buffer);// 再写入两个字节buffer.put(new byte[]{'b', 'c'});debugAll(buffer);// 切换成模式,此时position = 0, limit = 3buffer.flip();byte b = buffer.get();System.out.println((char) b);debugRead(buffer);buffer.compact();debugAll(buffer);}

- 调用compact方法

2.4.ByteBuffer常见方法
2.4.1.分配空间
可以使用 allocate 方法为 ByteBuffer 分配空间,其他 Buffer 类也有该方法 不能动态调整容量 netty对ByteBuffer这里做了增强,可以动态调整
它使用的是 Java 堆内存(Heap Memory)。allocate 方法分配的是一个非直接缓冲区,即缓冲区的数据存储在 Java 虚拟机的堆内存中。
堆内存的优势在于它的管理由 Java 虚拟机负责,而且垃圾回收器可以有效地回收不再使用的对象,但是在进行 I/O 操作时,需要将数据从堆内存复制到内核空间,存在额外的拷贝开销。
读写效率低
ByteBuffer buffer = ByteBuffer.allocate(10);allocateDirect(10),它使用的是直接缓冲区(Direct Buffer),可以通过 ByteBuffer.allocateDirect() 方法来创建。直接缓冲区的数据存储在操作系统的内存中(不会受到垃圾回收的影响),减少了数据在 Java 堆和本地堆之间的拷贝操作,提高了 I/O 操作的效率。但是,直接缓冲区的分配和释放通常更昂贵,可能导致内存泄漏问题。、
读写效率高(少一次拷贝)
ByteBuffer buffer1 = ByteBuffer.allocateDirect(10);
2.4.2.包装现有数组
如果有现有的字节数组,可以使用 wrap 方法将其包装成 ByteBuffer
byte[] byteArray = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(byteArray);
2.4.3.获取和设置容量
获取 ByteBuffer 的容量(capacity)
int capacity = buffer.capacity();
设置 ByteBuffer 的容量(慎用,可能导致数据丢失)
buffer.capacity(20);
2.4.4.获取和设置位置
获取 ByteBuffer 的位置(position)
int position = buffer.position();
设置 ByteBuffer 的位置(position),用于读取或写入数据
buffer.position(5);
2.4.5.获取限制和设置限制
获取 ByteBuffer 的限制(limit),即可以读取或写入的最大位置
int limit = buffer.limit();
设置 ByteBuffer 的限制(limit)
buffer.limit(8);
2.4.6.读取和写入数据
从 ByteBuffer 中读取字节数据
也可也调用
channel的wirte方法
byte b = buffer.get();
int r = channel.wite(buffer);
向 ByteBuffer 中写入字节数据
int read = channel.read();
也可也调用
channel的read方法
buffer.put((byte) 10);
channel.read(buffer);
2.4.7.翻转缓冲区
将 ByteBuffer 从写模式切换到读模式,通常在写入数据后调用
buffer.flip();
2.4.8.清空缓冲区
清空 ByteBuffer 中的数据,通常在读取数据后调用
buffer.clear();
2.4.9.倒带缓冲区
将 ByteBuffer 的位置设置为 0,通常在重新读取数据时调用
buffer.rewind();
2.4.10.压缩缓冲区
将未读取的数据复制到缓冲区的开始处,然后将位置设置为复制的数据末尾,通常在写入部分数据后调用
buffer.compact();
2.4.11.标记和重置位置
标记当前的位置,通常与 reset 方法一起使用,用于返回到之前标记的位置,,比如中间某些数据重要需要返回读取
buffer.mark();
重置位置到之前标记的位置
buffer.reset();