1.Spark程序中的相关端口
4040:是一个运行的Application在运行的过程中临时绑定的端口,用以查看当前任务的状态。4040被占用会顺延到4041,4042等。4040是一个临时端口,当前程序运行完成后,4040就会被注销。
4040和Driver相关联,一个Driver启动起来,一个4040端口就被绑定起来,并可以查看该程序的运行状态。
8080:默认情况是StandAlone下,Master角色(进程)的WEB端口,用以查看当前Master(集群)的状态。(Driver和Master是两个东西,Master进程用于管理集群,Driver用于管理某次运行的程序,某个Driver程序运行完成,其所绑定的4040端口释放,但不会影响到Master进程)
18080:默认是历史服务器的端口,由于每个程序运行完成后,4040端口就要被注销,在以后想回看某个程序的运行状态就可以通过历史服务器查看,历史服务器长期稳定运行,可供随时查看记录的程序的运行过程。
2.Spark程序运行的层次结构
在Spark程序中,一个Driver程序运行,会分为多个Job程序来执行;在一个Job程序中又可以分为多个阶段来执行;一个阶段又可以分为多个Task来执行(可以理解为多个线程并行执行)。
打扫学校举例eg:

3.StandAlone阶段小总结
StandAlone原理?
Master和Worker角色以独立进程的形式存在,并且它们之间相互通讯,组成Spark运行时环境(集群)
Spark角色在StandAlone中的分布?
Master角色:Master进程;Worker角色:Worker进程;Driver角色:以线程运行在Master进程中;Executor角色:以线程运行在Worker中。
StandAlone如何提交Spark应用?
bin/spark-submit -- master spark://server:7077
4040\8080\18080分别是什么?
4040是单个程序运行的时候绑定的端口可供查看本任务运行情况。
8080是Master进程运行时默认的WEB ui端口,Master是独立的进程,不和Worker也不和Driver绑定,所以Driver运行完不会影响Master进程的运行,Driver关闭不影响Master进程。
18080是历史服务器的端口,可以供我们查看历史运行的程序(Driver)的运行状态。
Job\State\Task的关系?
一个Spark程序会被分为多个子任务(Job)运行,每一个Job会被分为多个State(阶段)来运行,每一个State(阶段)内会被分为多个Task(线程)来执行具体的任务。
4.Spark StandAlone HA集群模式(其实就是高可用的StandAlone模式,引入了zookeeper来做主节点切换/“灾备”/“主备切换”)
Spark StandAlone集群是Master-Slaves架构的集群模式,和大部分主从结构集群一样会存在主节点故障的问题。
由于上述StandAlone集群模式存在的问题,引出了高可用HA
提出了基于zookeeper的Standby Master架构模式:zookeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个Active的,其他都是Standby。当Active的Master出现故障时,另外Standby Master会被选举出来。由于集群的信息,包括Master,Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何影响。加入zookeeper的集群架构如下图所示:

5.StandAlone HA的搭建
搭建很简单,就是在StandAlone集群模式的配置文件中修改一两个配置项就好了。
6.StandAlone HA的原理
基于zookeeper做状态的维护,开启多个Master进程,一个作为活跃Master,其他的作为备份,当活跃进程宕机了,备份的Master来接管。
7.Spark on YARN(重点)
出现背景:按照前面所述,如果我们想要一个稳定的用于生产的Spark环境,那么最优秀的选择是构建HA StandAlone集群。但是,在企业中服务器资源通常有限,不过许多企业基本上都有Hadoop集群,也就是会有YARN集群。因此,对于企业来说,在已有YARN集群的前提下单独的搭建Spark StandAlone集群,对资源的利用率不高,所以,在企业中,多数场景下,会将Spark运行到YARN集群中。
YARN本身是一个资源调度框架,负责对运行在内部的计算框架进行资源调度管理。
作为典型的计算框架,Spark本身也是直接运行在YARN中,并接受YARN调度的。
所以,对于Spark on YARN,无需部署Spark集群,只要找一台服务器,从当Spark的客户端,即可提交任务到YARN集群中运行。(部署的时候,无需前面所述:在每一台服务器上安装Spark,然后启动Master,启动Worker,以及zookeeper什么的。。。,只需要在已有的YARN集群的基础上,找到一台服务器,充当Spark的客户端就可以了)
8.Spark on YARN的本质
Master角色由YARN的ResourceManager来担任。
Worker角色由YARN的NodeManager来担任。
Driver角色运行在YARN容器内 或者 提交任务的客户端进程中。
真正干活的Executor运行在YARN提供的容器内。
Spark on YARN集群架构图示:

9.Spark on YARN只需要注意配置好两个环境变量,HADOOP_CONF_DIR和YARN_CONF_DIR就好了。Spark会根据这两个环境变量的值自行的去找诸如ResourceManager这些东西。
10.Spark on YARN个人认为就是借助已有的YARN集群平台,来做Spark集群分布式计算操作(把计算任务提交到YARN集群中,以Spark的模式去运行),目的就是节约服务器资源
11.Spark on YARN的两种运行模式(两种模式的区别就是Driver运行的位置)
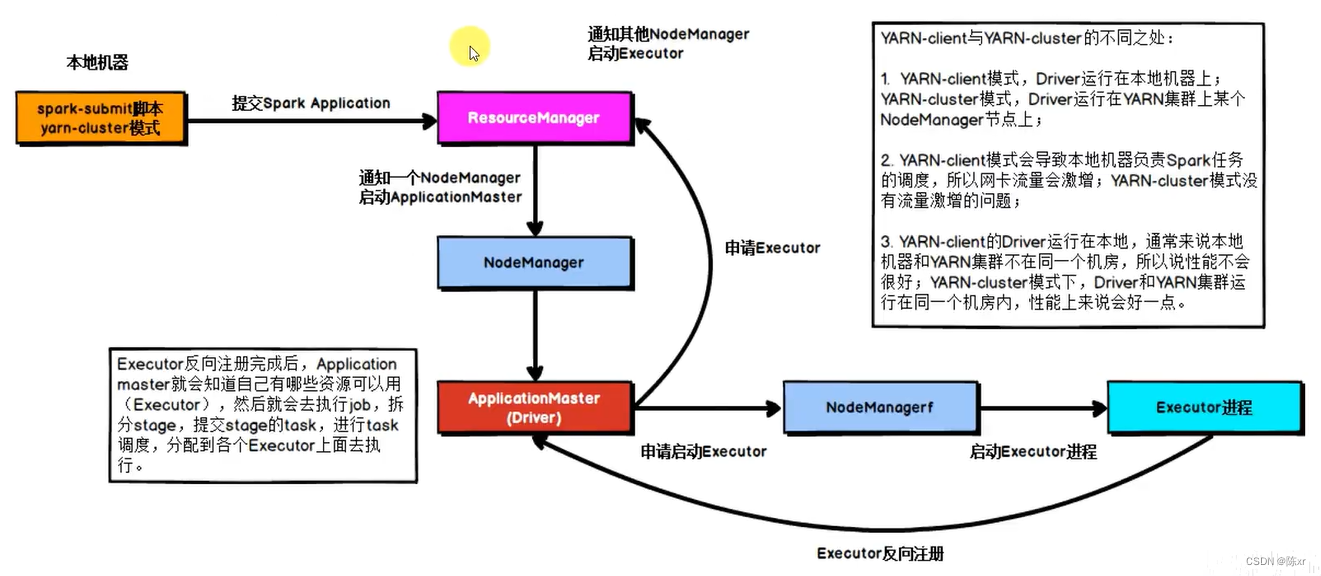
一种是Cluster模式:Driver运行在YARN容器内部,和ApplicationMaster在同一个容器内

一种是Client模式:Driver运行在客户端进程中,比如Driver运行在Spark-submit程序的进程中

集群(Cluster)模式的优点:各NodeManager和Driver之间的通信成本低,效率高;缺点:不方便查看日志,因为Driver运行在某个容器当中,日志会输出到某个容器当中,因此在查看日志这个方面,客户端(Client)模式具有优势,不过客户端的通信性能当然就没有集群模式高了。
对比图:

两种模式对比总结:

12.Spark on YARN两种模式的流程
客户端模式流程:

集群模式流程:
13.Spark on YARN小总结
Spark on YARN本质?
Master由ResourceManager代替
Worker由NodeManager代替
Driver可以运行容器内(Cluster模式)或者客户端进程中(Client模式)
Executor全部运行在YARN提供的容器内
为什么要用spark on YARN?
提高资源利用率,在已有YARN的场景下让Spark收到YARN的调度可以更好地管控资源提高利用率并方便管理。
14.类库和框架
类库:一堆别人写好的代码,你可以导入使用。
框架:可以独立运行,并提供编程结构的一种软件产品,Spark就是一个独立的框架。
15.PySpark
前面使用的bin/pyspark程序,注意这是一个应用程序,提供一个python解释器执行环境来运行spark任务
而PySpark,指的是Python的运行类库,就是可以在python代码中:import pyspark; 这种操作
概念:PySpark是Spark官方提供的一个Python类库,内置了完全的Spark API,可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行。