清华大学驭风计划课程链接
学堂在线 - 精品在线课程学习平台 (xuetangx.com)
代码和报告均为本人自己实现(实验满分),只展示主要任务实验结果,如果需要详细的实验报告或者代码可以私聊博主
有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~
案例简介
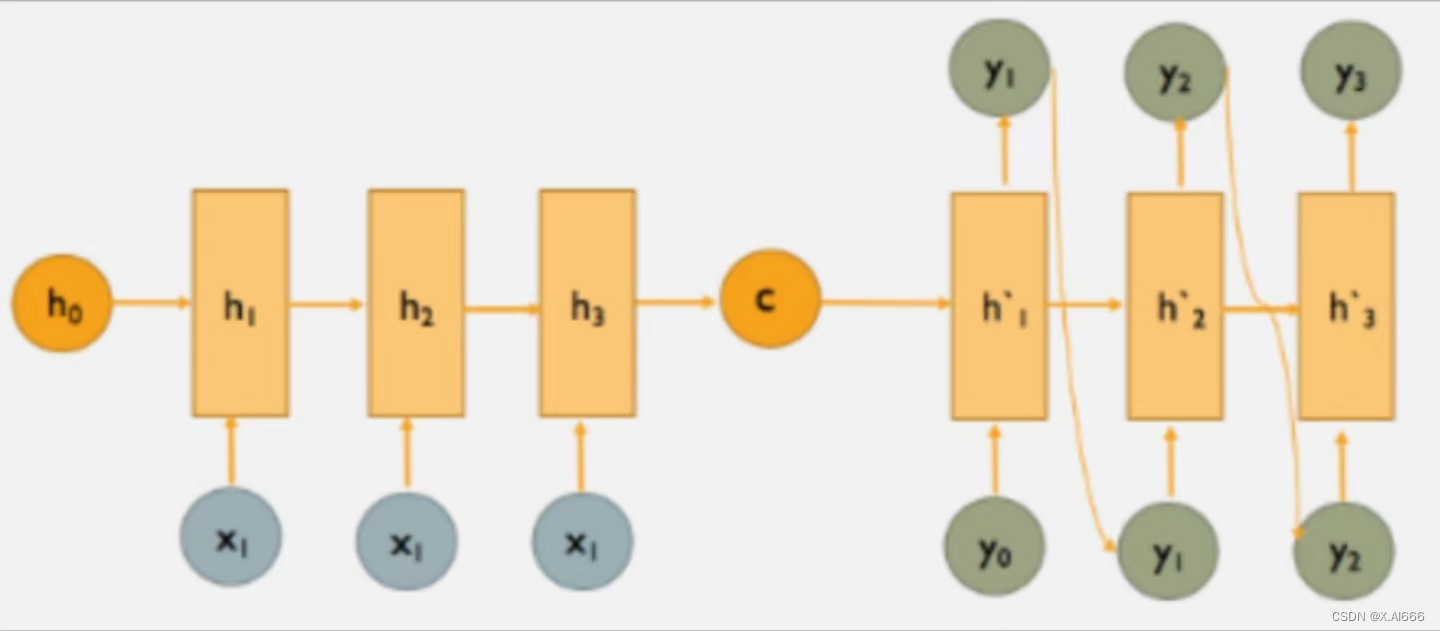
seq2seq是神经机器翻译的主流框架,如今的商用机器翻译系统大多都基于其构建,在本案例中,我们将使用由NIST提供的中英文本数据训练一个简单的中英翻译系统,在实践中学习seq2seq的具体细节,以及了解机器翻译的基本技术。
seq2seq模型
从根本上讲,机器翻译需要将输入序列(源语言中的单词)映射到输出序列(目标语言中的单词)。正如我们在课堂上讨论的那样,递归神经网络(RNN)可有效处理此类顺序数据。机器翻译中的一个重要难题是输入和输出序列之间没有一对一的对应关系。即,序列通常具有不同的长度,并且单词对应可以是不平凡的(例如,彼此直接翻译的单词可能不会以相同的顺序出现)。
为了解决这个问题,我们将使用一种更灵活的架构,称为seq2seq模型。该模型由编码器和解码器两部分组成,它们都是RNN。编码器将源语言中的单词序列作为输入,并输出RNN层的最终隐藏状态。解码器与之类似,除了它还具有一个附加的全连接层(带有softmax激活),用于定义翻译中下一个单词的概率分布。以此方式,解码器本质上用作目标语言的神经语言模型。关键区别在于,解码器将编码器的输出用作其初始隐藏状态,而不是零向量。
数据和代码
本案例使用了一个小规模的中英平行语料数据,并提供了一个简单的seq2seq模型实现,包括数据的预处理、模型的训练、以及简单的评测。
评分要求
分数由两部分组成,各占50%。第一部分得分为对于简单seq2seq模型的改进,并撰写实验报告,改进方式多样,下一小节会给出一些可能的改进方向。第二分部得分为测试数据的评测结果,我们将给出一个中文测试数据集(test.txt),其中每一行为一句中文文本,需要同学提交模型做出的对应翻译结果,助教将对于大家的提交结果统一机器评测,并给出分数。请以附件形式提交实验报告!
改进方向
初级改进:
进阶改进:
复杂改进:
实验结果
1,首先运行原代码,得出结果
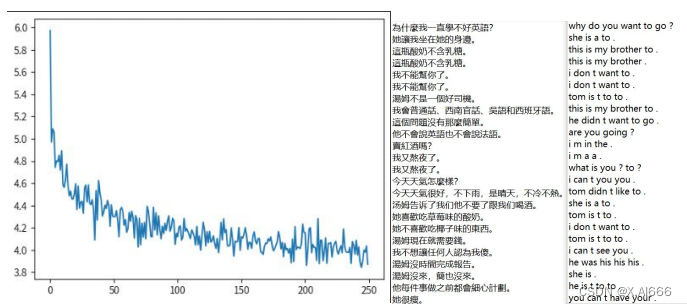
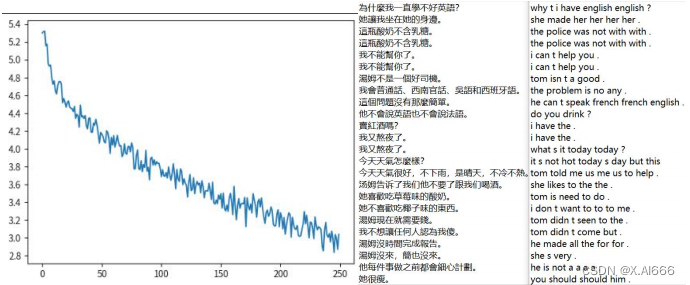
从 loss 图来看最低达到 3.9 ,通过翻译的结果对比,原始代码的翻译效果几乎没有,我认为 RNN 在这次文本翻译中表现较差主要因其难以捕捉长期依赖性、容易出现梯度问题、记忆容量有限、缺乏并行性而造成的。
2,将 RNN 模型替换成 GRU 和 LSTM

在模型替换为 GRU 的时候明显 loss 下降了更多而且翻译效果也相对于原来 RNN模型有一定提升。比如句子‘为什么我一直学习不好英语 ’ GRU 模型的翻译为why is i speak english english ?而 RNN 模型的翻译为 why do you want to go ? ,可以看出虽然两者都不完全对,但是 GRU 模型的翻译很接近正确答案了,而 RNN 的翻译基本不沾边,所以在这次 RNN 模型替换为 GRU 的实验中效果明显提升。
改进为 LSTM
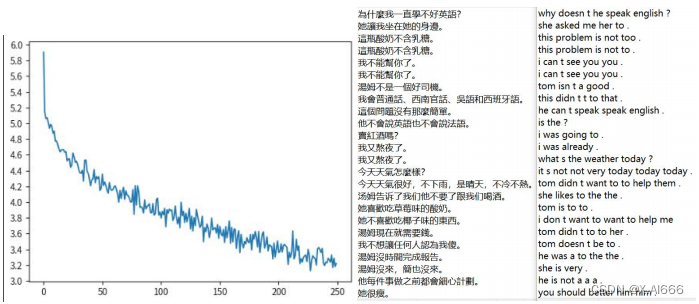
从 loss 图来看比起原始的 RNN 有明显更多的下降,从翻译效果来看也是如此。比如句子‘今天天气怎么样’在 LSTM 模型的翻译是 what s the weather today ? 而在 RNN 模型的翻译是 what is you ? to ? 。明显 LSTM 完全翻译正确,而 RNN 的翻译压根不搭边,所以这次 RNN 模型替换成 LSTM 的效果有明显提升。
RNN 模型替换成 GRU 和 LSTM 的总结 : GRU 和 LSTM 相对于 RNN 在这次文本翻译任务中翻译效果更好的原因我认为主要包括以下几点:
处理长距离依赖关系 : RNN 在处理长句子或序列时,由于梯度消失 / 爆炸的问题,往往难以捕捉长距离的依赖关系。GRU 和 LSTM 引入了门控机制,可以更有效地处理长距离依赖,因此在翻译中能够更好地捕捉句子中的语法和语义信息。
防止梯度消失 : GRU 和 LSTM 通过门控单元,如遗忘门和更新门,可以选择性地记住或忘记先前的信息。这有助于减轻梯度消失问题,使模型能够在训练期间更好地传播梯度,从而学习到更好的参数。
处理序列中的不同时间尺度 : GRU 和 LSTM 能够处理不同时间尺度的信息,因为它们在每个时间步都有不同的门控单元来控制信息流。这使得它们可以更好地适应不同长度和复杂度的句子,而 RNN 不太适合这种任务。
更好的记忆能力 : GRU 和 LSTM 通过细致的控制信息流,具有更好的记忆能力,可以更好地处理文本中的长距离依赖和序列中的重要信息。
综上所述 , GRU 和 LSTM 相对于 RNN 在文本翻译中表现更好,因为它们克服了RNN 的一些限制,提供了更好的建模能力,更好地处理了长句子中的依赖关系,因此在这次文本翻译的实验中更有效
3,使用双向的 encoder 获得更好的源语言表示
(这里我完成了双向的 GRU 和双向的 LSTM )
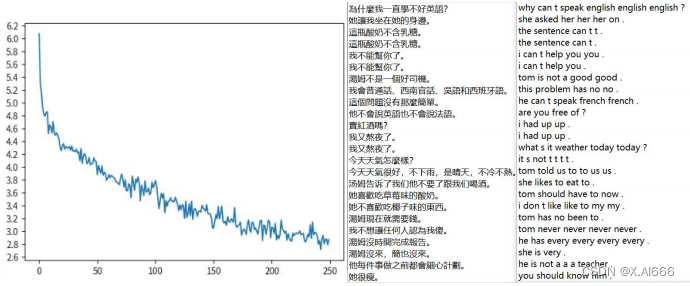
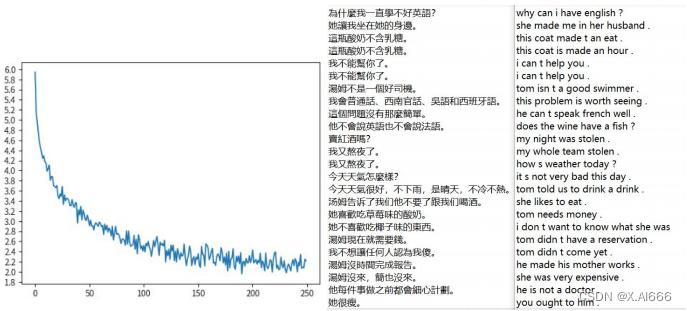
从 loss 图可以看出 loss 明显比原来单向的 GRU 的时候下降更多了,最低达到了2.8,并且从翻页的结果来看也明显优于原来单向的 GRU ,比如在我不能帮你了。翻译成了 i can t help you ,而在单向的 GRU 中翻译成了 i can t you you you you 。有明显的效果提升,
我认为造成这样的原因 是因为双向的 GRU 能够同时利用输入序列的前向和后向信息,提供更丰富的上下文信息,缓解梯度消失问题,增加模型的建模能力,以及更好地表达输入序列的结构。
双向的 LSTM
从 loss 图来看相对于单向的 LSTM 的 loss 下降了更多,最低达到 2.95 ,然后再从翻译结果来看也比单向的 LSTM 要更好一点,比如句子‘他不会说法语也不会说英语’,单向 LSTM 的翻译结果是 he can t speak speak english ,而双向的 LSTM的翻译是 he can t speak french french english . 虽然结果都与实际结果有差距,但是也可以看出双向的 LSTM 翻译的更好,因为它翻译出来法语,英语。而单向的LSTM 只翻译出英语,这就是差距。
使用双向的 encoder 获得更好的源语言表示结果总结 :双向 encoder 在这次文本翻译的实验中表现更好,因为它具有更好的上下文理解和信息获取能力。以下是我认为的一些原因:
双向信息获取 :双向编码器同时处理输入序列的前向和后向信息。这意味着对于每个输入位置,它能够考虑其之前和之后的单词,从而获得更全面的上下文信息。这对于理解句子中的复杂依赖关系非常重要,特别是在涉及长距离依赖的任务中。
更好的信息传递 :在双向编码中,前向和后向信息通过不同的隐藏状态进行编码,然后合并在一起。这种信息合并允许模型更好地捕捉不同方向上的相关信息,有助于更好地表示输入序列。
降低信息丢失 :单向编码器在处理每个单词时只能看到之前的单词,这可能导致信息丢失,尤其是在句子末尾。双向编码器通过处理输入的两个方向,有助于减少这种信息丢失。
总之 ,双向 encoder 的能力更强,能够更好地捕捉输入序列的语法和语义信息,使其的翻译效果比单向 encoder 的更好。
4,实现注意力机制(实现点积注意力,加法注意力,乘法注意力)
在这里我使用 GRU 和注意力机制共同实现,因为在前面的实验中,GRU 的运行 时间和得出的 loss 图都比 LSTM 要更低,且两者翻译的结果差别不大的情况下, 选择 GRU 更适合此次的文本翻译,因为 GRU 在于其更简洁的结构和较少的参数 量,使得模型更具计算效率(运行时间更快)和抗过拟合能力。此外,GRU 还能 够有效地处理长序列,对于文本翻译中的长句子表现更出色。并且在这次运行中我选择的是点积注意力(运算简单,速度更快)
运行结果


首先从 loss 图来看,最终的下降达到的值比没有加注意力机制的 GRU 要稍微低一点,差 0.1 左右,从实际的翻译效果看加了注意力机制的更好,比如句子今天天气怎么样?,没有加注意力机制的 GRU 翻译结果是 how s it weather today today?而加了注意力机制的 GRU 翻译结果为 what s the weather like today ? 可以说是完全正确。再比如句子‘她喜欢吃草莓味的酸奶’普通 GRU 的翻译结果是 she likes to eat sushi,意思是她喜欢吃寿司,而加了注意力机制的 GRU 的翻译结果是 she likes to drink milk 意思是她喜欢喝牛奶。明显可以看出加了注意力机制的 GRU 翻译结果更接近真实的意思。
注意力机制性能提升总结
注意力机制 GRU 的翻译效果比不加注意力机制的 GRU 要好的原因我认为主要有以下两点:
处理长序列 : RNN 在处理长序列时可能会出现梯度消失或爆炸的问题,导致信息丢失。注意力机制允许模型根据需要选择性地关注输入序列的不同部分,从而更好地捕捉长距离的依赖关系,提高性能。
提高记忆能力 : GRU 本身是一种改进的 RNN 单元,它具有较长的记忆窗口,但仍然可能无法处理非常长的序列。注意力机制增加了模型的记忆能力,因为它可以在生成每个输出时选择性地关注与当前任务相关的信息。
5 ,对于现有超参数进行调优,这里划分出一个开发集,在开发集上 进行 grid search ,并且报告结果
最终组合所有的最佳参数来进行训练,结果如下
学习率 : 0.0005
层数 : 2
注意力种类 :加法注意力
Dropout 概率值 :0.05
强制学习概率: 1
不管是从 loss 来看还是翻译结果来看,都比之前的好不少,这也是我能调出的最好翻译效果。比如句子汤姆不是一个好司机,翻译是 tom isn t a good swimmer .意思是汤姆不是一个好游泳员,已经很接近正确答案,而在之前的改进中这个翻译几乎不沾边,还有其他句子也有类似情况,最终的超参数调整的改进相对来说还是比较成功的,提升了句子翻译的效果。