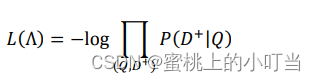有没有想过今天的一些应用程序是如何看起来几乎神奇地智能的?这种魔力很大一部分来自于一种叫做RAG和LLM的东西。把RAG(Retrieval Augmented Generation)想象成人工智能世界里聪明的书呆子,它会挖掘大量信息,准确地找到你的问题所需要的信息。然后,还有LLM(大型语言模型),就像著名的GPT系列一样,它将基于其令人印象深刻的文本生成功能生成平滑的答案。把这两者结合在一起,你就得到了一个人工智能,它不仅智能,而且具有超强的相关性和上下文感知能力。这就像是把一个超快速的研究助理和一个机智的健谈者结合在一起。这个组合非常适合任何事情,从帮助你快速找到特定信息到进行令人惊讶的真实聊天。
但问题是:我们如何知道我们的人工智能是否真的很有帮助,而不仅仅是在说花里胡哨的胡话?这就是评估的意义所在。我们需要确保我们的人工智能不仅准确,而且相关、有用,不会偏离奇怪的轨道。毕竟,如果智能助手不能理解你的需求,或者给你的答案太离谱,它有什么用?
在这篇文章中,我们将深入探讨如何评估我们的人工智能系统。
一、开发阶段
在开发阶段,必须按照典型的机器学习模型评估流程进行思考。在标准的AI/ML设置中,我们通常使用几个数据集,如开发、训练和测试集,并使用定量指标来衡量模型的有效性。然而,评估大型语言模型(LLM)非常有挑战,传统的定量指标很难捕捉LLM的输出质量,因为这些模型擅长生成多样化和创造性的语言。因此,很难有一套全面的标签来进行有效的评估。
在学术界,研究人员可能会使用MMLU等基准和分数来对LLM进行排名,并可能聘请人类专家来评估LLM输出的质量。然而,这些方法并不能无缝地过渡到生产环境,因为生产环境的开发速度很快,实际应用需要立即取得结果。这不仅仅关乎LLM的性能,现实世界的需求需要考虑整个过程,包括数据检索、Prompt合成和LLM。为每一次新的系统迭代或当文档或域发生变化时,制定一个人工策划的基准是不切实际的。此外,该行业的快速开发速度无法承受人类测试人员在部署前评估每个更新的漫长等待。因此,调整学术界的评估策略,以适应快速、注重成果的生产环境,是一个相当大的挑战。
因此,如果您遇到这种情况,您可能会考虑让LLM提供的伪分数。这个分数可以反映自动化评估指标和人类判断的组合,这种混合方法旨在弥合人类评估者的细微理解与机器评估的可扩展、系统分析之间的差距。
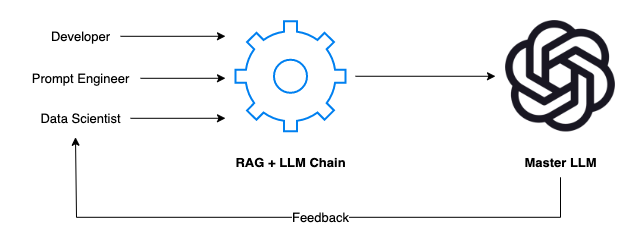
例如,如果您的团队正在开发一个内部LLM,该LLM是针对您的特定领域和数据进行训练的,那么该过程通常需要开发人员、Prompt工程师和数据科学家的合作。每个成员都发挥着关键作用:
开发人员就是架构师。他们构建了应用程序的框架,确保RAG+LLM链无缝集成,并且可以毫不费力地在不同的场景中进行切换。
Prompt工程师是创造性的。他们设计了模拟真实世界用户交互的场景和提示。他们思考“如果”,并推动系统处理广泛的主题和问题。
数据科学家是战略家。他们分析响应,深入研究数据,并运用他们的统计专业知识来评估人工智能的性能是否符合标准。
这里的反馈回路是必不可少的。当我们的人工智能响应提示时,团队会仔细检查每一个输出。人工智能理解这个问题了吗?回复是否准确且相关?语言能更流畅些吗?然后将此反馈反馈回系统以进行改进。
下面使用像OpenAI的GPT-4这样的主LLM作为评估自研LLM的基准,以下是具体的操作步骤:
生成相关数据集:首先创建一个反映用户领域细微差别的数据集。该数据集可以由专家策划,也可以在GPT-4的帮助下进行合成来节省时间,确保其符合您的黄金标准。
定义指标:利用LLM的优势来定义指标。可以选择一些开源工具进行评估,比如Langchain和其他一些库(如ragas[1])。评价指标,如可信度、上下文回忆、上下文精度、答案相似性等。
自动化评估流程:为了跟上快速的开发周期,建立一个自动化的流程。这将在每次更新或更改后,根据预定义的指标一致地评估应用程序的性能。通过自动化流程,您可以确保您的评估不仅是彻底的,而且是高效的迭代,从而实现快速的优化和细化。
例如,在下面的演示中,我将向您展示如何使用OpenAI的GPT-4在简单的文档检索对话任务中自动评估各种开源LLM。
首先,我们使用OpenAI GPT-4创建从文档派生的合成数据集,如下所示:
import osimport jsonimport pandas as pdfrom dataclasses import dataclassfrom langchain.chat_models import ChatOpenAIfrom langchain.chains import LLMChainfrom langchain.prompts import PromptTemplatefrom langchain.document_loaders import PyPDFLoaderfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.output_parsers import JsonOutputToolsParser, PydanticOutputParserfrom langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplateQA_DATASET_GENERATION_PROMPT = PromptTemplate.from_template("You are an expert on generate question-and-answer dataset based on a given context. You are given a context. ""Your task is to generate a question and answer based on the context. The generated question should be able to"" to answer by leverage the given context. And the generated question-and-answer pair must be grammatically ""and semantically correct. Your response must be in a json format with 2 keys: question, answer. For example,""\n\n""Context: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower.""\n\n""Response: {{""\n"" \"question\": \"Where is France and what is it’s capital?\",""\n"" \"answer\": \"France is in Western Europe and it’s capital is Paris.\"""\n""}}""\n\n""Context: The University of California, Berkeley is a public land-grant research university in Berkeley, California. Established in 1868 as the state's first land-grant university, it was the first campus of the University of California system and a founding member of the Association of American Universities.""\n\n""Response: {{""\n"" \"question\": \"When was the University of California, Berkeley established?\",""\n"" \"answer\": \"The University of California, Berkeley was established in 1868.\"""\n""}}""\n\n""Now your task is to generate a question-and-answer dataset based on the following context:""\n\n""Context: {context}""\n\n""Response: ",)OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")if OPENAI_API_KEY is None:raise ValueError("OPENAI_API_KEY is not set")llm = ChatOpenAI(model="gpt-4-1106-preview",api_key=OPENAI_API_KEY,temperature=0.7,response_format={"type": "json_object"},)chain = LLMChain(prompt=QA_DATASET_GENERATION_PROMPT,llm=llm)file_loader = PyPDFLoader("./data/cidr_lakehouse.pdf")text_splitter = CharacterTextSplitter(chunk_size=1000)chunks = text_splitter.split_documents(file_loader.load())questions, answers = [], []for chunk in chunks:for _ in range(2):response = chain.invoke({"context": chunk})obj = json.loads(response["text"])questions.append(obj["question"])answers.append(obj["answer"])df = pd.DataFrame({"question": questions,"answer": answers})df.to_csv("./data/cidr_lakehouse_qa.csv", index=False)
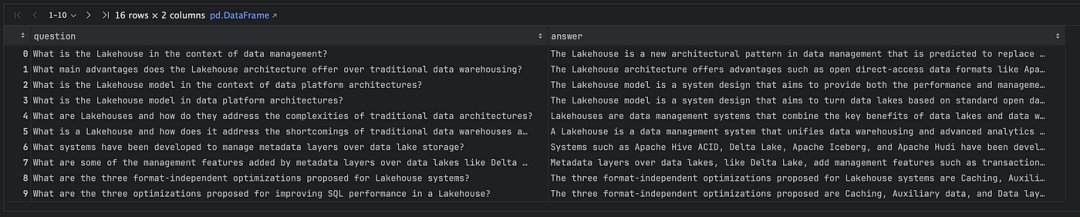
在运行上述代码后,我们获得了一个CSV文件作为结果。此文件包含与我们输入的文档相关的成对问题和答案,如下所示:
然后,我们使用Langchain构建简单的DocumentRetrievalQA链,并通过Ollama[2]可以在本地运行几个开源LLM(可以在这里[3]找到一些教程)。
from tqdm import tqdmfrom langchain.chains import RetrievalQAfrom langchain.chat_models import ChatOllamafrom langchain.vectorstores import FAISSfrom langchain.embeddings import HuggingFaceEmbeddingsvector_store = FAISS.from_documents(chunks, HuggingFaceEmbeddings())retriever = vector_store.as_retriever()def test_local_retrieval_qa(model: str):chain = RetrievalQA.from_llm(llm=ChatOllama(model=model),retriever=retriever,)predictions = []for it, row in tqdm(df.iterrows(), total=len(df)):resp = chain.invoke({"query": row["question"]})predictions.append(resp["result"])df[f"{model}_result"] = predictionstest_local_retrieval_qa("mistral")test_local_retrieval_qa("llama2")test_local_retrieval_qa("zephyr")test_local_retrieval_qa("orca-mini")test_local_retrieval_qa("phi")df.to_csv("./data/cidr_lakehouse_qa_retrieval_prediction.csv", index=False)
总之,上面的代码建立了一个简单的文档检索链。我们使用几个模型来执行这个链,如Mistral、Llama2、Zephyr、Orca-mini和Phi。因此,我们在现有的DataFrame中添加了五个额外的列,以存储每个LLM模型的预测结果。

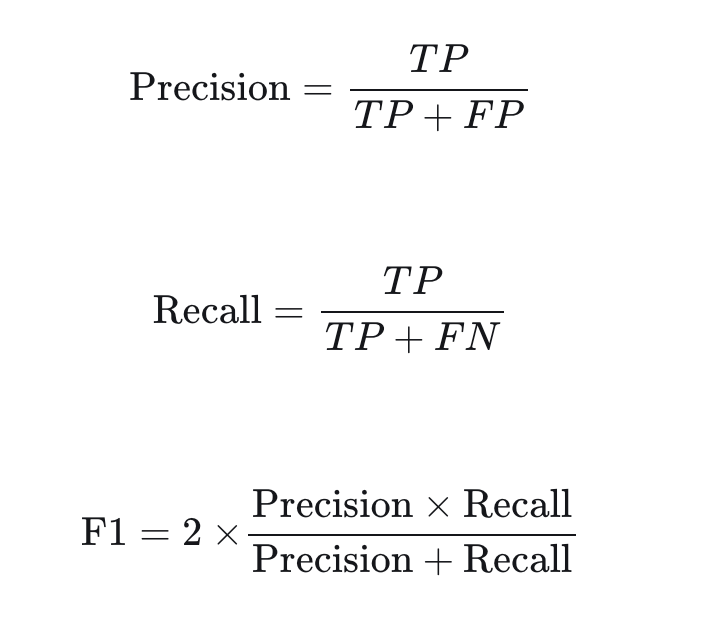
现在,让我们使用OpenAI的GPT-4来定义一个主链,以评估预测结果。评估指标采用一个在传统的AI/ML问题中很常见的评估指标,类似F1分数。为了实现这一点,我们将定义一些概念,如真阳性(TP)、假阳性(FP)和假阴性(FN),定义如下:
TP:在答案和ground truth都正确的事实。
FP:答案中有陈述,但在ground truth中没有。
FN:在ground truth中找到了相关陈述,但在回答中遗漏了。
有了这些定义,我们可以使用以下公式计算精度、召回率和F1分数:
import osimport numpy as npimport pandas as pdfrom tqdm import tqdmfrom langchain.chains import LLMChainfrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import PromptTemplateOPENAI_API_KEY = os.getenv("OPENAI_API_KEY")if OPENAI_API_KEY is None:raise ValueError("OPENAI_API_KEY is not set")CORRECTNESS_PROMPT = PromptTemplate.from_template("""Extract following from given question and ground truth. Your response must be in a json format with 3 keys and does not need to be in any specific order:- statements that are present in both the answer and the ground truth- statements present in the answer but not found in the ground truth- relevant statements found in the ground truth but omitted in the answerPlease be concise and do not include any unnecessary information. You should classify the statements as claims, facts, or opinions with semantic matching, no need exact word-by-word matching.Question:What powers the sun and what is its primary function?Answer: The sun is powered by nuclear fission, similar to nuclear reactors on Earth, and its primary function is to provide light to the solar system.Ground truth: The sun is actually powered by nuclear fusion, not fission. In its core, hydrogen atoms fuse to form helium, releasing a tremendous amount of energy. This energy is what lights up the sun and provides heat and light, essential for life on Earth. The sun's light also plays a critical role in Earth's climate system and helps to drive the weather and ocean currents.Extracted statements:[{{"statements that are present in both the answer and the ground truth": ["The sun's primary function is to provide light"],"statements present in the answer but not found in the ground truth": ["The sun is powered by nuclear fission", "similar to nuclear reactors on Earth"],"relevant statements found in the ground truth but omitted in the answer": ["The sun is powered by nuclear fusion, not fission", "In its core, hydrogen atoms fuse to form helium, releasing a tremendous amount of energy", "This energy provides heat and light, essential for life on Earth", "The sun's light plays a critical role in Earth's climate system", "The sun helps to drive the weather and ocean currents"]}}]Question: What is the boiling point of water?Answer: The boiling point of water is 100 degrees Celsius at sea level.Ground truth: The boiling point of water is 100 degrees Celsius (212 degrees Fahrenheit) at sea level, but it can change with altitude.Extracted statements:[{{"statements that are present in both the answer and the ground truth": ["The boiling point of water is 100 degrees Celsius at sea level"],"statements present in the answer but not found in the ground truth": [],"relevant statements found in the ground truth but omitted in the answer": ["The boiling point can change with altitude", "The boiling point of water is 212 degrees Fahrenheit at sea level"]}}]Question: {question}Answer: {answer}Ground truth: {ground_truth}Extracted statements:""",)judy_llm = ChatOpenAI(model="gpt-4-1106-preview",api_key=OPENAI_API_KEY,temperature=0.0,response_format={"type": "json_object"},)judy_chain = LLMChain(prompt=CORRECTNESS_PROMPT,llm=judy_llm)def evaluate_correctness(column_name: str):chain = LLMChain(prompt=CORRECTNESS_PROMPT,llm=ChatOpenAI(model="gpt-4-1106-preview",api_key=OPENAI_API_KEY,temperature=0.0,response_format={"type": "json_object"},))key_map = {"TP": "statements that are present in both the answer and the ground truth","FP": "statements present in the answer but not found in the ground truth","FN": "relevant statements found in the ground truth but omitted in the answer", # noqa: E501}TP, FP, FN = [], [], []for it, row in tqdm(df.iterrows(), total=len(df)):resp = chain.invoke({"question": row["question"],"answer": row[column_name],"ground_truth": row["answer"]})obj = json.loads(resp["text"])TP.append(len(obj[key_map["TP"]]))FP.append(len(obj[key_map["FP"]]))FN.append(len(obj[key_map["FN"]]))# convert to numpy arrayTP = np.array(TP)FP = np.array(FP)FN = np.array(FN)df[f"{column_name}_recall"] = TP / (TP + FN)df[f"{column_name}_precision"] = TP / (TP + FP)df[f"{column_name}_correctness"] = 2 * df[f"{column_name}_recall"] * df[f"{column_name}_precision"] / (df[f"{column_name}_recall"] + df[f"{column_name}_precision"])evaluate_correctness("mistral_result")evaluate_correctness("llama2_result")evaluate_correctness("zephyr_result")evaluate_correctness("orca-mini_result")evaluate_correctness("phi_result")print("|====Model====|=== Recall ===|== Precision ==|== Correctness ==|")print(f"|mistral | {df['mistral_result_recall'].mean():.4f} | {df['mistral_result_precision'].mean():.4f} | {df['mistral_result_correctness'].mean():.4f} |")print(f"|llama2 | {df['llama2_result_recall'].mean():.4f} | {df['llama2_result_precision'].mean():.4f} | {df['llama2_result_correctness'].mean():.4f} |")print(f"|zephyr | {df['zephyr_result_recall'].mean():.4f} | {df['zephyr_result_precision'].mean():.4f} | {df['zephyr_result_correctness'].mean():.4f} |")print(f"|orca-mini | {df['orca-mini_result_recall'].mean():.4f} | {df['orca-mini_result_precision'].mean():.4f} | {df['orca-mini_result_correctness'].mean():.4f} |")print(f"|phi | {df['phi_result_recall'].mean():.4f} | {df['phi_result_precision'].mean():.4f} | {df['phi_result_correctness'].mean():.4f} |")print("|==============================================================|")df.to_csv("./data/cidr_lakehouse_qa_retrieval_prediction_correctness.csv", index=False)
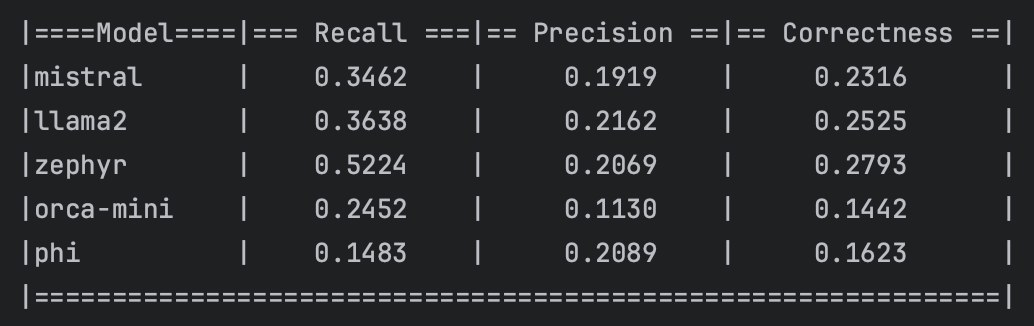
现在我们有了几个模型的简单基准,这可以被视为每个模型处理文档检索任务的初步指标。它们是理解哪些模型更善于从给定语料库中检索准确和相关信息的基线。你可以在这里[4]找到源代码。
二、人类在流程中进行反馈
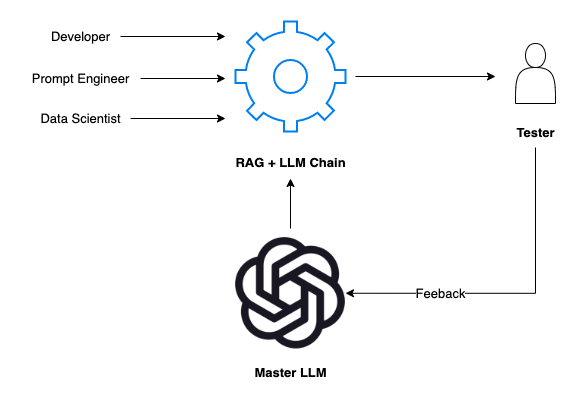
当涉及到通过人类在流程中反馈调整我们的人工智能时,人类测试人员和主LLM之间的协同作用至关重要。这种关系不仅仅是为了收集反馈,而是为了创建一个能够适应人类输入并从中学习的响应式人工智能系统。
2.1 互动过程
测试人员的输入:测试人员参与RAG+LLM链,从人类的角度评估其输出。它们提供人工智能反应的相关性、准确性和自然度等方面的反馈。
对主LLM的反馈:人类测试人员的反馈直接传达给Master LLM。与标准模型不同,主LLM旨在理解和解释此反馈,以完善其后续输出。
主LLM提示调整:有了这个反馈,主LLM会调整我们开发LLM的提示。这个过程类似于导师指导学生。主LLM修改开发LLM对提示的解释和反应方式,确保了更有效和情境感知的反应机制。
2.2 主LLM的双重作用
主LLM既是内部开发LLM的基准,也是反馈循环中的积极参与者。它评估反馈,调整提示或模型参数,并从人类互动中“学习”。
2.3 实时自适应的好处
这一过程具有变革性。它允许人工智能实时适应,使其更加敏捷,并与人类语言和思维过程的复杂性保持一致。这样的实时适应确保了人工智能的学习曲线是陡峭和连续的。
2.4 改进的周期
通过这种互动、反馈和适应的循环,我们的人工智能不仅仅是一种工具;它成为一个学习实体,能够通过与人类测试人员的每次交互进行改进。这种人在流程中的反馈模型确保了我们的人工智能不会停滞,而是进化成一个更高效、更直观的助手。
总之,“人在回路反馈”不仅仅是收集人类的见解,而是创建一个动态的、适应性强的人工智能,可以微调其行为,更好地为用户服务。这种迭代过程确保了我们的RAG+LLM应用程序保持在最前沿,不仅提供了答案,而且提供了上下文感知的、微妙的响应,反映了对用户需求的真正理解。
可以在视频[5]中观看ClearML如何使用这一概念来增强Promptimizer。
三、运营阶段
过渡到运营阶段就像从彩排到开幕之夜。在这里,我们的RAG+LLM应用程序不再是假设实体;他们成为真实用户日常工作流程的积极参与者。这个阶段是对开发阶段所有准备和微调工作的试金石。
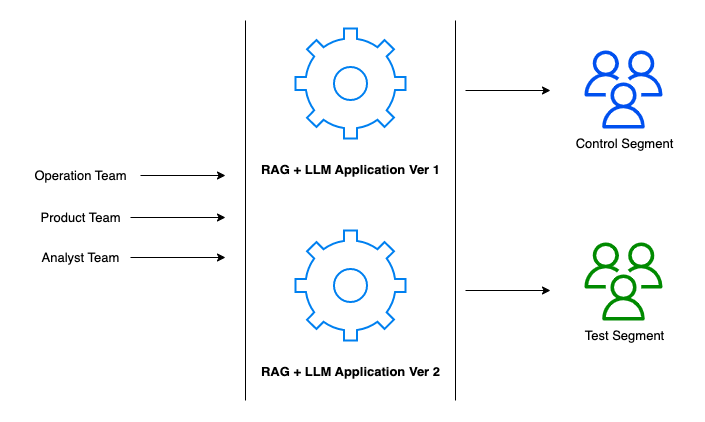
在这个阶段,我们的团队——运营、产品和分析师——协调部署和管理应用程序,确保我们构建的一切不仅能正常运行,而且能在实时环境中蓬勃发展。在这里,我们可以考虑实施A/B测试策略,以可控的方式衡量应用程序的有效性。
A/B测试框架:我们将用户群分为两个部分——控制部分和测试部分,前者继续使用已建立的应用程序版本(版本1),后者尝试版本2中的新功能(实际上,您也可以同时运行多个A/B测试)。这使我们能够收集有关用户体验、功能接受度和整体性能的比较数据。
运营推出:运营团队的任务是顺利推出这两个版本,确保基础设施稳健,任何版本转换对用户来说都是无缝的。
产品进化:产品团队密切关注用户反馈的脉搏,努力迭代产品。该团队确保新功能与用户需求和整体产品愿景相一致。
分析见解:分析师团队严格检查从A/B测试中收集的数据。他们的见解对于确定新版本是否优于旧版本以及是否准备好进行更广泛的发布至关重要。
性能指标:对关键性能指标(KPI)进行监控,以衡量每个版本的成功与否。其中包括用户参与度指标、满意度得分和应用程序输出的准确性。
运营阶段是动态的,由连续的反馈循环提供信息,不仅可以改进应用程序,还可以提高用户的参与度和满意度。这是一个以监控、分析、迭代为特征的阶段,最重要的是,从实时数据中学习。
四、结论
总之,检索增强生成(RAG)和大型语言模型(LLM)的集成标志着人工智能的重大进步,将深度数据检索与复杂的文本生成相结合。然而,我们需要一种适当有效的评估方法和迭代开发策略。开发阶段强调定制人工智能评估,并通过人在流程中的反馈增强评估,确保这些系统具有同理心,并适应现实世界的场景。这种方法突显了人工智能从单纯的工具向协作伙伴的演变。运营阶段在真实世界的场景中测试这些应用程序,使用A/B测试和连续反馈循环等策略来确保有效性和基于用户交互的持续发展。
参考文献:
[1] https://github.com/explodinggradients/ragas
[2] https://github.com/jmorganca/ollama
[3] https://blog.duy-huynh.com/build-your-own-rag-and-run-them-locally/
[4] https://github.com/vndee/dev-notebooks/blob/main/Langchain_Evaluation_With_Dataset.ipynb
[5] https://www.youtube.com/watch?v=gR__vhOVvy4
[6] https://medium.com/@vndee.huynh/how-to-effectively-evaluate-your-rag-llm-applications-2139e2d2c7a4