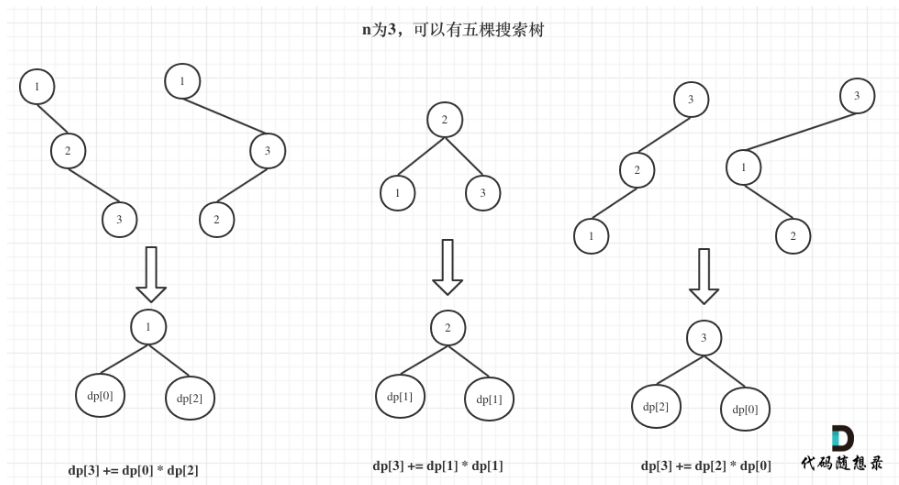
7、接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
提示:
n == height.length1 <= n <= 2 * 1040 <= height[i] <= 105
思路解答:
- 使用左右双指针分别指向数组的两端,同时维护左右两端的最大高度。
- 在移动指针的过程中,根据当前的左右最大高度来计算当前位置能接的雨水量,并移动指针。
- 不断更新左右两端的最大高度,直到两个指针相遇。
def trap(self, height: list[int]) -> int:if not height:return 0n = len(height)left, right = 0, n - 1left_max, right_max = height[left], height[right]water = 0while left < right:left_max = max(left_max, height[left])right_max = max(right_max, height[right])if left_max < right_max:water += left_max - height[left]left += 1else:water += right_max - height[right]right -= 1return water
8、无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
提示:
-
0 <= s.length <= 5 * 104 -
s由英文字母、数字、符号和空格组成
思路解答:
补充:
滑动窗口是一种经典的算法技巧,通常用于解决数组或字符串的子数组或子串问题。它通过维护一个窗口(通常是一个子数组或子串),在遍历过程中动态调整窗口的起始位置和结束位置,以便在满足特定条件的情况下找到所需的结果。
对于此题:
- 定义一个窗口,初始时起始位置和结束位置都指向字符串的开头,同时定义一个哈希表
char_index_map用于记录每个字符最近出现的位置。 - 遍历字符串,不断移动结束位置
end,并根据当前字符是否在窗口内已经出现过来更新起始位置start。 - 如果当前字符已经在窗口内出现过,需要更新
start指针的位置为重复字符的下一个位置。 - 在每次遍历时,更新字符的最新位置,并计算当前窗口的长度(即
end - start + 1),并更新最大长度。 - 最终返回最长不含重复字符的子串长度。
通过滑动窗口算法,我们可以在一次遍历过程中找到最长的不含重复字符的子串长度,并且时间复杂度为 O(n),其中 n 是字符串的长度。这种方法在处理子串问题时非常高效,适用于需要动态调整窗口范围的场景。
def lengthOfLongestSubstring(self, s: str) -> int:n = len(s)if n == 0:return 0char_index_map = {} # 用于记录字符的索引位置max_length = 0start = 0for end,num in enumerate(s):if num in char_index_map:# 如果当前字符在窗口内已经出现过,更新起始位置start = max(start, char_index_map[num] + 1)# 更新当前字符的最新位置char_index_map[num] = endmax_length = max(max_length, end - start + 1)return max_length
9、找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
提示:
-
1 <= s.length, p.length <= 3 * 104 -
s和p仅包含小写字母
思路解答:
- 创建两个字典
p_count和window,分别用于记录 p 中字符的计数和当前窗口中字符的计数。 - 初始化指针
left和right,分别表示窗口的左右边界,初始时两者都指向字符串 s 的起始位置。 - 不断移动右指针
right,直到窗口包含了 p 中所有字符,此时开始移动左指针left来缩小窗口。 - 在移动窗口的过程中,根据窗口内字符的计数情况来更新结果。
- 最终返回所有符合条件的子串的起始索引。
def findAnagrams(self, s: str, p: str) -> list[int]:result = []#统计p中的字符个数p_count = collections.defaultdict(int)#记录窗口中的字符个数window = collections.defaultdict(int)required = len(p)left, right = 0, 0for char in p:p_count[char] += 1#移动窗口右边界while right < len(s):char = s[right]if char in p_count:window[char] += 1if window[char] <= p_count[char]:required -= 1while required == 0:if right - left + 1 == len(p):result.append(left)left_char = s[left]if left_char in p_count:window[left_char] -= 1if window[left_char] < p_count[left_char]:required += 1left += 1right += 1return result