flink watermark 生成机制与总结
- watermark 介绍
- watermark生成方式
- watermark 的生成值算法策略
- watermark策略设置代码
- watermark源码分析
- watermark源码调用流程debug(重要)
- 测试思路
- 迟到时间处理
- FlinkSql 中的watermark
- 引出问题与源码分析
watermark 介绍
本质上watermark是flink为了处理eventTime窗口计算提出的一种机制,本质上也是一种时间戳,由flink souce或者自定义的watermark生成器按照需求定期或者按条件生成一种系统event,与普通数据流event一样流转到对应的下游operations,接收到watermark数据的operator以此不断调整自己管理的window event time clock。
首先,eventTime计算意味着flink必须有一个地方用于抽取每条消息中自带的时间戳,所以TimestampAssigner的实现类都要具体实现
long (T element, long previousElementTimestamp);方法用来抽取当前元素的eventTime,这个eventTime会用来决定元素落到下游的哪个或者哪几个window中进行计算。
其次,在数据进入window前,需要有一个Watermarker生成当前的event time对应的水位线,flink支持两种后置的Watermarker:Periodic和Punctuated,一种是定期产生watermark(即使没有消息产生),一种是在满足特定情况的前提下触发。两种Watermark分别需要实现接口为
Watermark getCurrentWatermark()和Watermark checkAndGetNextWatermark(T lastElement, long extractedTimestamp);
如果一个下游算子实例消费者多个上游算子实例,则选择上游最小的watermark作为自己的watermark发往下游,这也是为什么要对齐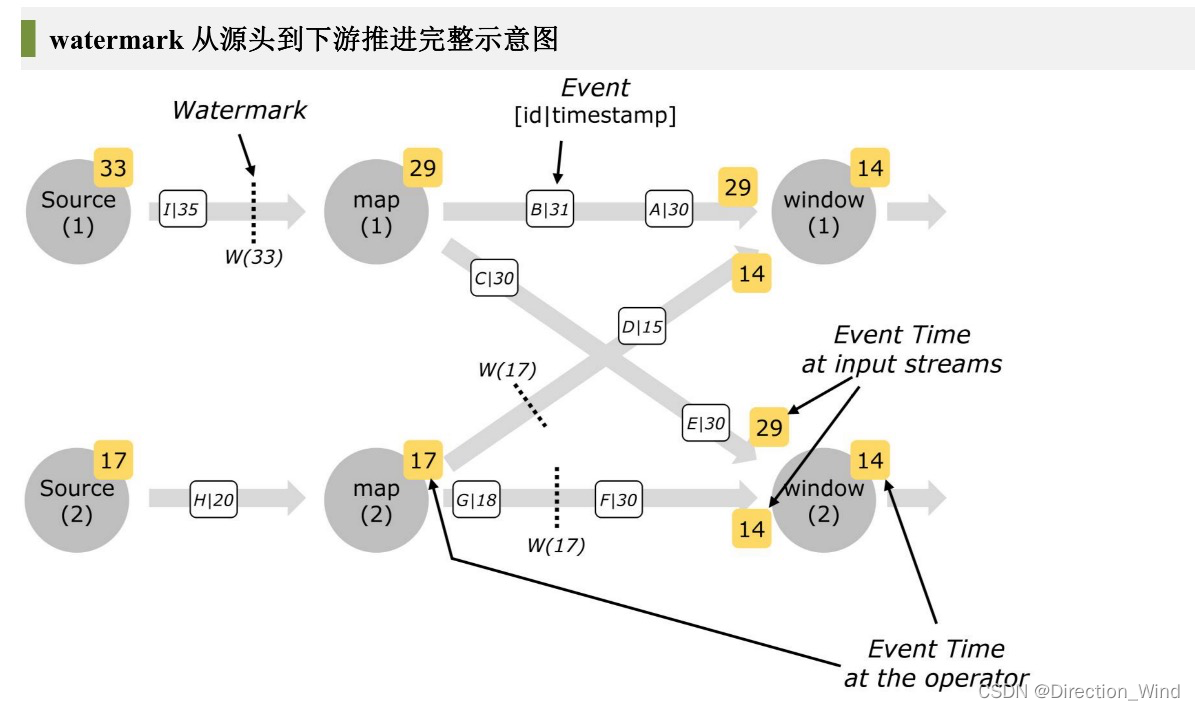
另外
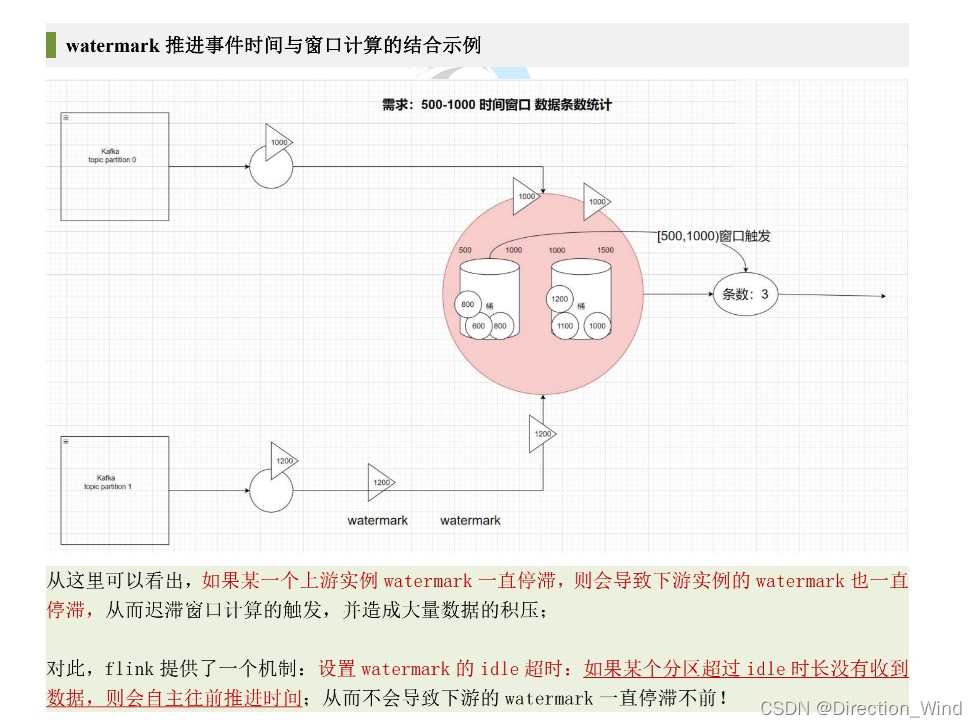
watermark生成方式
在 Flink 中,数据处理中需要通过调⽤ DataStream 中的 assignTimestampsAndWatermarks ⽅法来分配时间和⽔印,该⽅法可以传⼊两种参数,⼀个是 AssignerWithPeriodicWatermarks(周期性生成watermark),另⼀个是 AssignerWithPunctuatedWatermarks(已过期,按指定标记性事件生成 watermark),通常建议在数据源(source)之后就进⾏⽣成⽔印,或者做些简单操作⽐如 filter/map/flatMap 之 后再⽣成⽔印,越早⽣成⽔印的效果会更好,也可以直接在数据源头就做⽣成⽔印。
-
With Periodic Watermarks(常用):周期性(一定时间间隔或者达到一定的记录条数)生成watermark
- 需要实现AssignerWithPeriodicWatermarks接口
- 默认周期是200ms,可通过env.getConfig.setAutoWatermarkInterval进行修改
- 实际生产环境用得多,但必须结合时间或者累计条数两个维度,否则在极端情况下会有很大的延时
-
With Punctuated Watermarks(不常用):在满足自定义条件时生成watermark,每一个元素都有机会判断是否生成一个watermark。
- 需要实现AssignerWithPunctuatedWatermarks接口
- 在TPS很高的生产环境下会产生大量的 Watermark,可能在一定程度上对下游算子造成一定的压力,只有在实时性很高的场景才会选择这种方式来进行生成水印
- 新版 Flink 源码中已经标记为 @Deprecated
watermark 的生成值算法策略
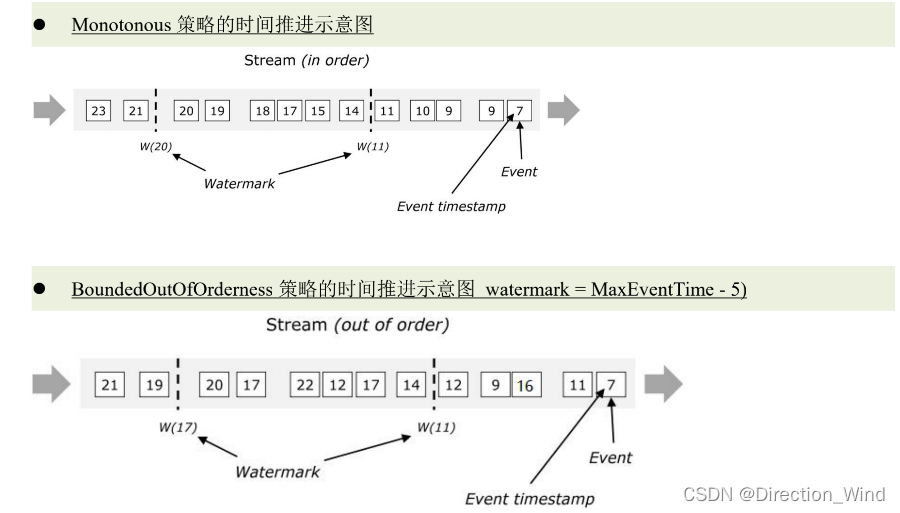
- 紧跟最大事件时间的 watermark 生成策略(完全不容忍乱序)
WatermarkStrategy.forMonotonousTimestamps(); - 允许乱序的 watermark 生成策略(最大事件时间-容错时间)
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10)); // 根据实际数据的最大乱序情况来设置 - 自定义 watermark 生成策略
WatermarkStrategy.forGenerator(new WatermarkGenerator(){ … } );
watermark策略设置代码
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.time.Duration;public class sinkFunction {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> stream = env.socketTextStream("local", 9999);stream.assignTimestampsAndWatermarks(WatermarkStrategy.noWatermarks()); //禁用时间时间的推进机制stream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps()); //紧跟最大时间时间stream.assignTimestampsAndWatermarks(WatermarkStrategy.forGenerator()); //自定义watermark生成算法stream.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(10)).withTimestampAssigner(new SerializableTimestampAssigner<String>() {@Overridepublic long extractTimestamp(String s, long l) {return Long.parseLong(s.split(",")[0]);}}));}
}watermark源码分析
背景代码: source.map(s->bean).assignWatermarkAndTimestamps( ).process().print();
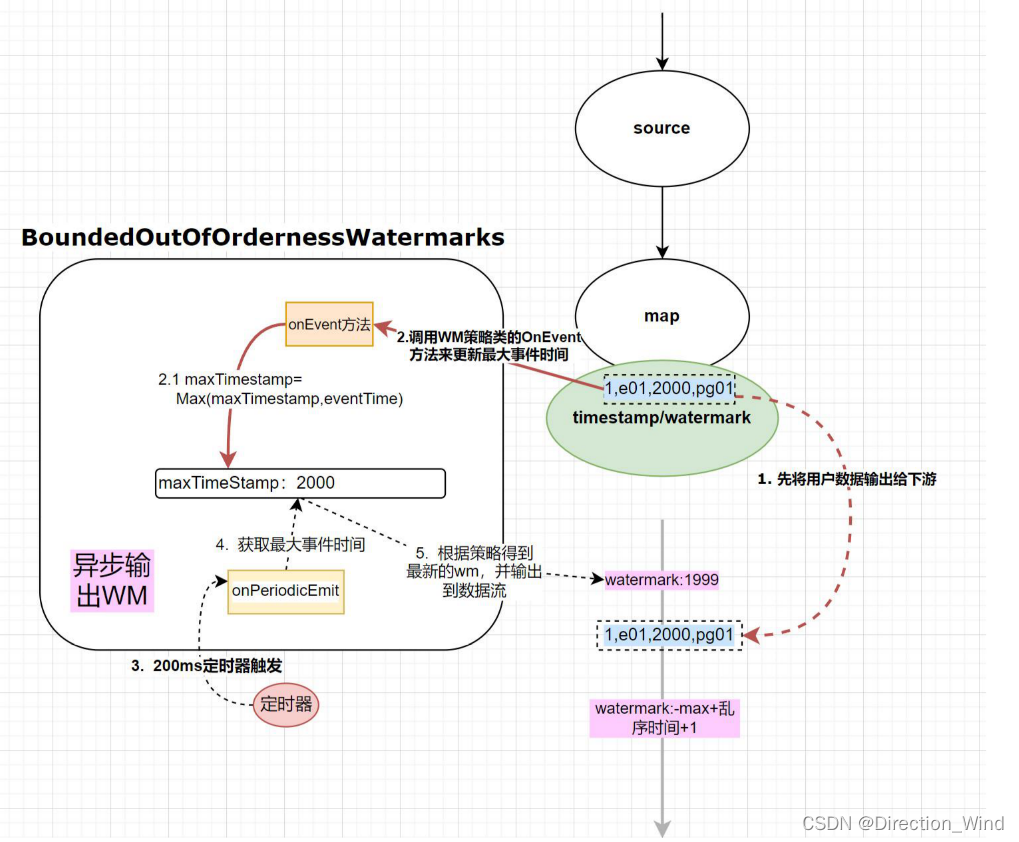
watermark源码调用流程debug(重要)
想要知道代码是如何调用的,我们通过debug的方式来查看数据调用:
我们测试的代码是这样的:
package Launcher;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.time.Duration;
//nc -lk 9999
public class sinkFunction {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> stream = env.socketTextStream("localhost", 9999);
// stream.assignTimestampsAndWatermarks(WatermarkStrategy.noWatermarks()); //禁用时间时间的推进机制
// stream.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps()); //紧跟最大时间时间
// stream.assignTimestampsAndWatermarks(WatermarkStrategy.forGenerator()); //自定义watermark生成算法stream.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(10)).withTimestampAssigner(new SerializableTimestampAssigner<String>() {@Overridepublic long extractTimestamp(String s, long l) {return Long.parseLong(s.split(",")[0]);}}));stream.print();env.execute();}
}
代码很简单,什么都没有,就一个设置watermark
我们先打了两个断点在源码的BoundedOutOfOrdernessWatermarks.class中:
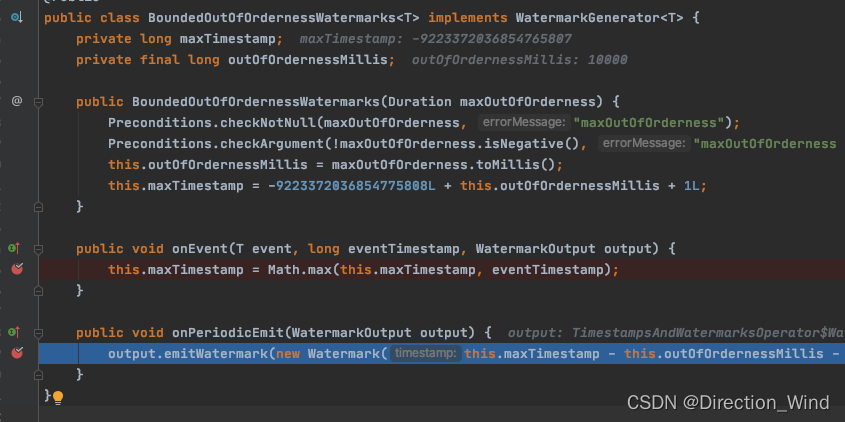
然后开启nc窗口:

当我们debug后,没有任何输入就会在output.emitWatermark(new Watermark(this.maxTimestamp - this.outOfOrdernessMillis - 1L));处 断点停止,因为这个函数是有定时器触发的,只要程序跑起来,每200ms就会触发一次:
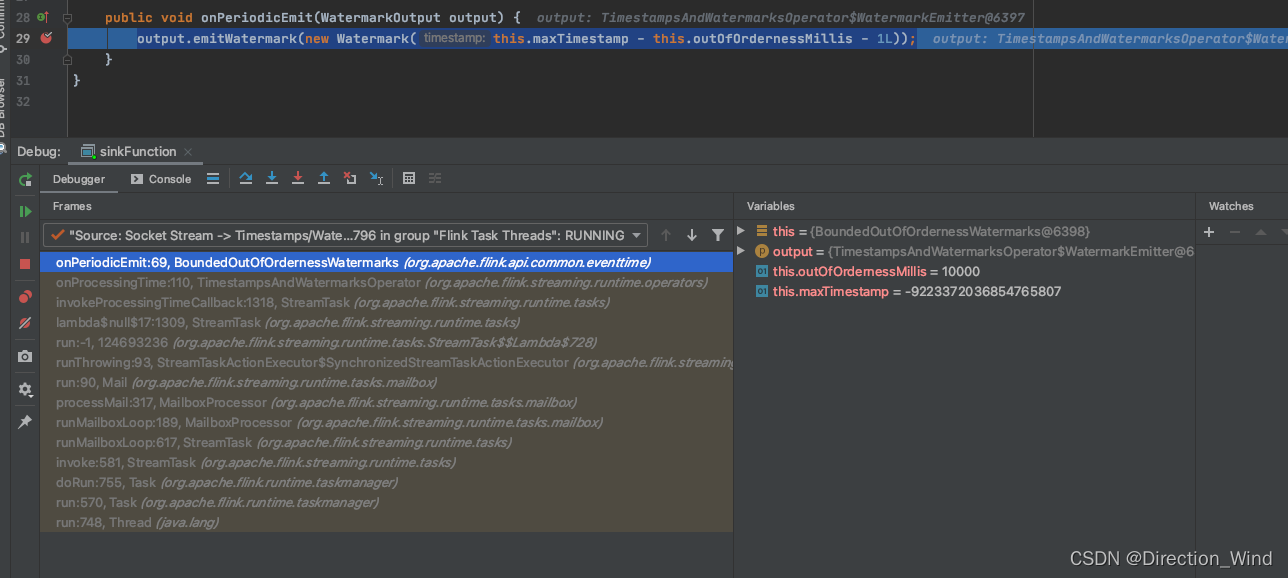
这个两百是怎么来的呢?点这里可以看到:
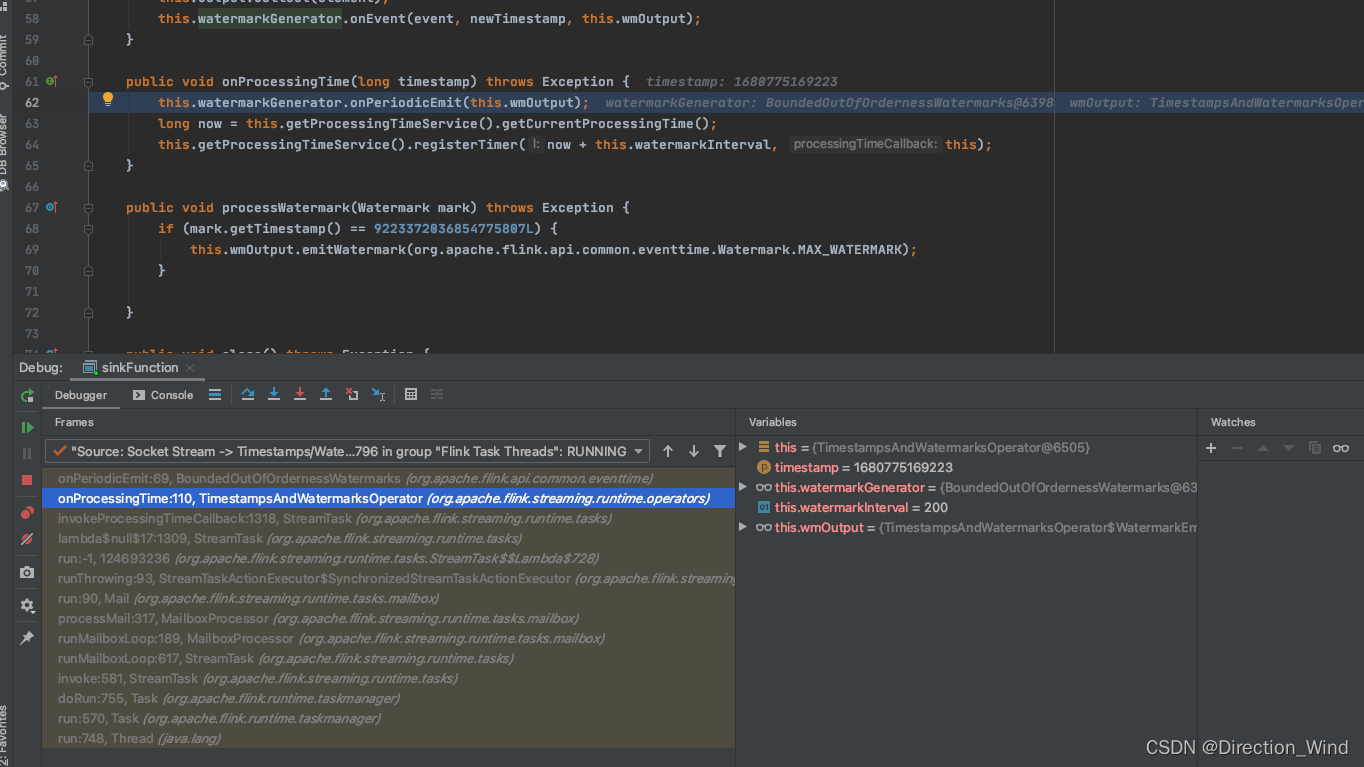
这是task类封装的,一个底层算子类TimestampsAndWatermarksOperator,看这个类的open方法中的这里:
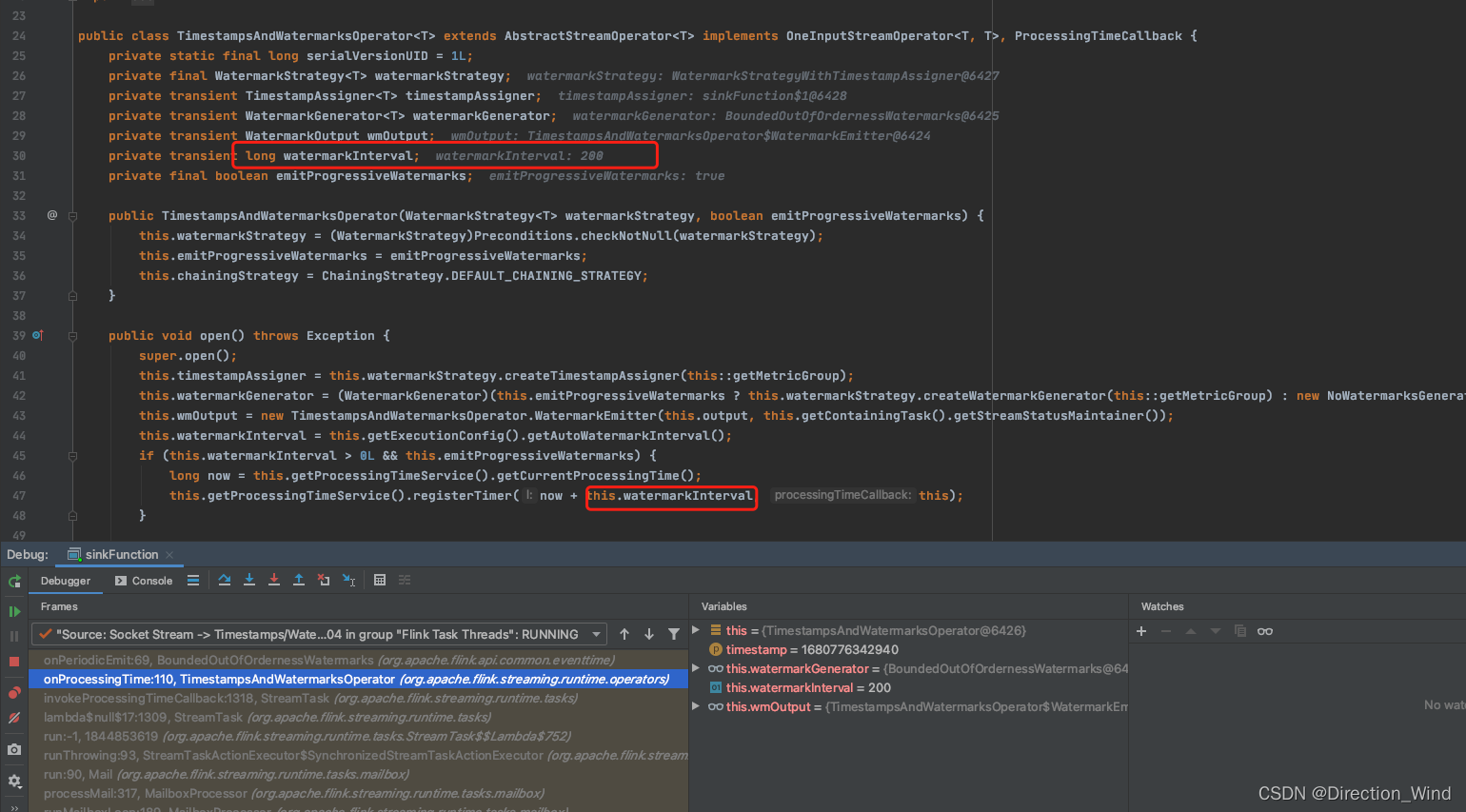
这里注册了一个计时器,时间是当前时间加watermarkInterval 后触发,这个watermarkInterval 就是200ms。
 而触发方法,这里在调用了watermarkGenerator.onPeriodicEmit,并且有重新注册了一个200ms后的定时,实现了 每隔200ms触发一次的效果。
而触发方法,这里在调用了watermarkGenerator.onPeriodicEmit,并且有重新注册了一个200ms后的定时,实现了 每隔200ms触发一次的效果。
如果想修改源码,看一些效果,可以完全按照源码的包名,类名,写一个一模一样的java类,类加载器会优先加载自己写的代码,而不会去加载引入的源码中代码。
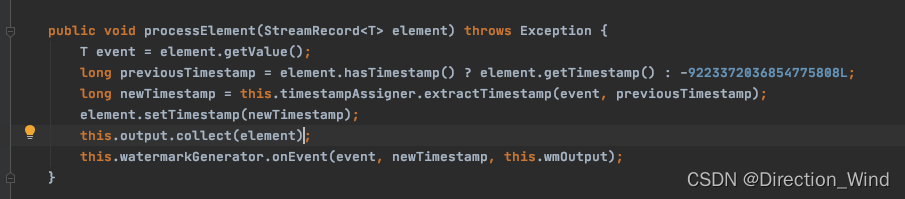
这里可以看到,数据来了,他是先数据 collect,后触发水印的onevent方法,也就是后更新watermark值。
测试思路
构造两条单并行度流,合并成一个单并行度流,来 watermark,及重点观察“接收多个上游分区”的 算子的 watermark 推进规律;
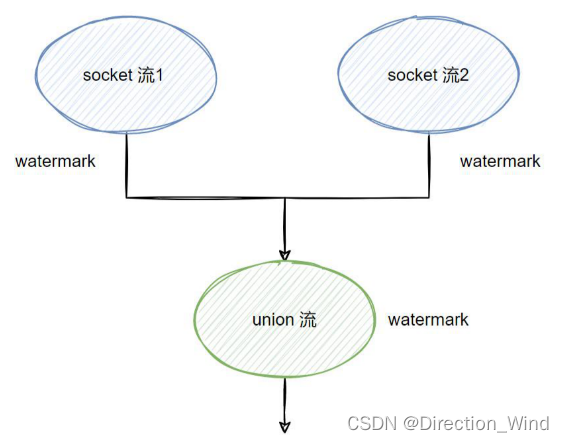
/*** 作者:深海 "deep as the sea"* 日期:2022/4/10* 联系方式:qq:657270652 wx:doitedu2018* 网站:多易教育 www.51doit.cn* 描述:watermark 推进测试观察**/
public class WatermarkTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 构造一个无乱序延迟的 watermark 生成策略WatermarkStrategy<String> stringWatermarkStrategy = WatermarkStrategy.<String>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<String>() {@Overridepublic long extractTimestamp(String element, long recordTimestamp) {return Long.parseLong(element.split(",")[1]);}});// 构造单并行度流 1DataStreamSource<String> source1 = env.socketTextStream("localhost", 9988);SingleOutputStreamOperator<String> s1 = source1.assignTimestampsAndWatermarks(stringWatermarkStrategy);// 构造单并行度流 2DataStreamSource<String> source2 = env.socketTextStream("localhost", 9999);SingleOutputStreamOperator<String> s2 = source2.assignTimestampsAndWatermarks(stringWatermarkStrategy);// 两条单并行度流,合并到一条单并行度流DataStream<String> s = s1.union(s2);// 打印 watermark 信息,观察 watermark 推进情况s.process(new ProcessFunction<String, String>() {@Overridepublic void processElement(String value, Context ctx, Collector<String> out) throws Exception {// 获取当前的 watermark(注意:此处所谓当前 watermark 是指处理当前数据前的 watermark)long currentWatermark = ctx.timerService().currentWatermark();Long timestamp = ctx.timestamp();System.out.println("s" + " : " + timestamp + " : " + currentWatermark + " => " + value);out.collect(value);}}).print();env.execute();}
}测试结果
在 9988 端口输入数据: a,1000
在 9999 端口输入数据: b,1000 b,4000 b,5000
输出结果:
s: 1000 : -9223372036854775808 => a,1000
s: 1000 : -9223372036854775808 => b,1000
s: 4000 : 999 => b,4000
s: 5000 : 999 => b,5000
迟到时间处理
- 直接丢弃:将迟到事件视为错误消息并丢弃(flink默认处理方式)。
- Side Output机制:可以将迟到事件单独放入一个数据流分支,这会作为 window 计算结果的副产品,以便用户获取并对其进行特殊处理。
- Allowed Lateness机制:允许用户设置一个允许的最大迟到时长。Flink 会再窗口关闭后一直保存窗口的状态直至超过允许迟到时长,这期间的迟到事件不会被丢弃,而是默认会触发窗口重新计算。因为保存窗口状态需要额外内存,并且如果窗口计算使用了 ProcessWindowFunction API 还可能使得每个迟到事件触发一次窗口的全量计算,代价比较大,所以允许迟到时长不宜设得太长,迟到事件也不宜过多,否则应该考虑降低水位线提高的速度或者调整算法。
FlinkSql 中的watermark
在创建表的 DDL 中定义
事件时间属性可以用 WATERMARK 语句在 CREATE TABLE DDL 中进行定义。WATERMARK 语句在一个已有字段上定义一个 Watermark 生成表达式,同时标记这个已有字段为时间属性字段。
CREATE TABLE user_actions (
user_name STRING,data STRING,
user_action_time TIMESTAMP(3),-- 声明 user_action_time 是事件时间属性,并且用 延迟 5 秒的策略来生成 watermark
WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
...
);SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);如果源中的时间戳数据表示为一个 epoch time,通常是一个长值,例如 1618989564564,建议将事件时间属性定义为 TIMESTAMP_LTZ 列
CREATE TABLE user_actions (
user_name STRING,data STRING,
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),-- declare time_ltz as event time attribute and use 5 seconds delayed watermark strategy
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (
...
);SELECT TUMBLE_START(time_ltz, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(time_ltz, INTERVAL '10' MINUTE);
引出问题与源码分析
我们这里来引出一个问题,不能排除有同学就是想用ProcessTime。
那么问题来了,EventTime 情况的watermark 很好理解,
可是ProcessTime的watermark到底做了什么,也不需要用它来过滤数据,本来就没有用数据内的时间,根本就不知道数据的顺序,更谈不上乱序了,那ProcessTime起了什么用呢?
我们首先来看下env.setStreamTimeCharacteristic() 这个方法
/*** Sets the time characteristic for all streams create from this environment, e.g., processing* time, event time, or ingestion time.** <p>If you set the characteristic to IngestionTime of EventTime this will set a default* watermark update interval of 200 ms. If this is not applicable for your application* you should change it using {@link ExecutionConfig#setAutoWatermarkInterval(long)}.** @param characteristic The time characteristic.*/@PublicEvolvingpublic void setStreamTimeCharacteristic(TimeCharacteristic characteristic) {this.timeCharacteristic = Preconditions.checkNotNull(characteristic);if (characteristic == TimeCharacteristic.ProcessingTime) {getConfig().setAutoWatermarkInterval(0);} else {getConfig().setAutoWatermarkInterval(200);}}
这个方法设置用户使用的是eventtime还是processtime
由源码可以看到 ,如果设置的是ProcessingTime ,会把autoWatermarkInterval这个属性值设为0,如果是EventTime,会设置为 200,我们追踪这个值发现,用户自定义的watermark类,需要注册在assignTimestampsAndWatermarks中,而在assignTimestampsAndWatermarks类中能够找到TimestampsAndPeriodicWatermarksOperator,
TimestampsAndPeriodicWatermarksOperator的open方法中有autoWatermarkInterval这个属性值。
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(AssignerWithPeriodicWatermarks<T> timestampAndWatermarkAssigner) {// match parallelism to input, otherwise dop=1 sources could lead to some strange// behaviour: the watermark will creep along very slowly because the elements// from the source go to each extraction operator round robin.final int inputParallelism = getTransformation().getParallelism();final AssignerWithPeriodicWatermarks<T> cleanedAssigner = clean(timestampAndWatermarkAssigner);TimestampsAndPeriodicWatermarksOperator<T> operator =new TimestampsAndPeriodicWatermarksOperator<>(cleanedAssigner);return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);}@Overridepublic void open() throws Exception {super.open();currentWatermark = Long.MIN_VALUE;watermarkInterval = getExecutionConfig().getAutoWatermarkInterval();if (watermarkInterval > 0) {long now = getProcessingTimeService().getCurrentProcessingTime();getProcessingTimeService().registerTimer(now + watermarkInterval, this);}}
我们来看这个open的初始方法,这个open是TimestampsAndPeriodicWatermarksOperator的初始方法,其实也是assignTimestampsAndWatermarks启动的条件,这个open给定了watermark的初始值。
这里初始化了两个值,
- 一个是其实的watermark的初始值,最小的long值,-9223372036854775808
- 另一个是初始的 watermark的间隔 如果是 EventTime就是当前时间加200ms,如果是ProcessTime就是当前时间。
再来看下面的定时任务
@Overridepublic void onProcessingTime(long timestamp) throws Exception {// register next timerWatermark newWatermark = userFunction.getCurrentWatermark();if (newWatermark != null && newWatermark.getTimestamp() > currentWatermark) {currentWatermark = newWatermark.getTimestamp();// emit watermarkoutput.emitWatermark(newWatermark);}long now = getProcessingTimeService().getCurrentProcessingTime();getProcessingTimeService().registerTimer(now + watermarkInterval, this);}
再来看下我们自定义注册的watermark方法
@Overridepublic Watermark getCurrentWatermark() {// return the watermark as current highest timestamp minus the out-of-orderness boundreturn new Watermark(currentMaxTimestamp - maxOutOfOrderness);}
autoWatermarkInterval为0的话 super.open() 不会被调用
这里面now,就是System.currentTimeMillis(); 所以如果时间间隔不为0,那么下一次调用的时间就是 当前时间 + 方法运行的时间 + 时间间隔,由于方法运行的时间约等于0ms,所以基本就是每个时间间隔(默认200ms),运行一次获取wakermark的方法。
所以如果是ProcessingTime,那么默认时间间隔是0,所以matermarks时间就是一直-9223372036854775808,所以就一直不会过滤时间。
所以想要启动ProcessingTime 来做 时间戳 ,就一定要设置
env.getConfig().setAutoWatermarkInterval(200);









![[更新]ARCGIS之土地耕地占补平衡、进出平衡系统报备坐标txt格式批量导出工具(定制开发版)](https://img-blog.csdnimg.cn/direct/456dc85e991d42f685c026ca693dde49.png)