【NodeRed】常用节点记录(loop、PostgreSQL、子流程、日志)
- 前言
- loop
- PostgreSQL
- number of rows per message
- sql 几种写法
- SQL query template
- Dynamic SQL queries
- Parameterized queries
- 子流程
- 状态节点怎么用?
- 日志
前言
在看了公司nodeRed 系统的设计,对涉及到的以下节点使用比较陌生,为了方便后续自己在编写过程中流畅性,对这些节点进行研究和示例编写消化,并在此进行记录,方便后续查阅。
- loop (测试使用)、
- PostgreSQL(测试几种sql、number of rows per message)、
- 子流程(测试status)、
- 日志(测试输出了什么)
loop
loop 在官方的介绍是:
Repeats a task in the loop specified times or by a condition or by an iterable enumeration (Array, Typed Array, Object, Map, Set, String).
简单的说,就是一个for。为了方便进一步了解它的使用,直接导入官方示例 Fixed number of loops,在这个基础上展开二次编写与测试。
经过测试,它的第一个输出就是for的最后一次,第二个输出则是整个迭代过程。2个输出都存在2个字典 :payload 和 loop ,这个在帮助文档有解释。其中,2个输出的payload 具体输出什么内容,可以在loop 节点 enumeration 选项 进行设置(或者fixed count 选项进行设置)。
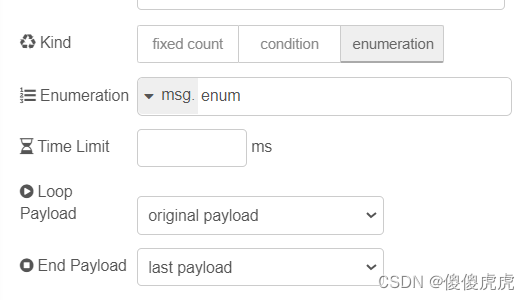
fixed count 选项中设置解释如下:
- Pass Count 表示 迭代次数;
- Initial Value 表示起始值设定(注意,设定的不是for索引,索引依旧是从0开始);
- Step Value 表示起始值设定的步长

这个其实就是
int value=1;
for(int i=0;i<10;i++){value +=2;
}
PostgreSQL
number of rows per message
在帮助文档有这么一句话:An exception is if the Split results option is enabled and the Number of rows per message is set to 1, then msg.payload is not an array but the single-row response. 翻译过来就是:例外情况是,如果启用了“拆分结果”选项,并且每条消息的行数设置为1,则msg.payload不是数组,而是单行响应。
最初看Number of rows per message 字面意思,就是用来控制输出sql 语句数量的,在进行了尝试后,再看这句话发现根本不是这个意思,大错特错,咋理解能力这么差。它是用来控制输出数据的,但前提必须是,Split results in multiple messages勾选,否则不起作用。
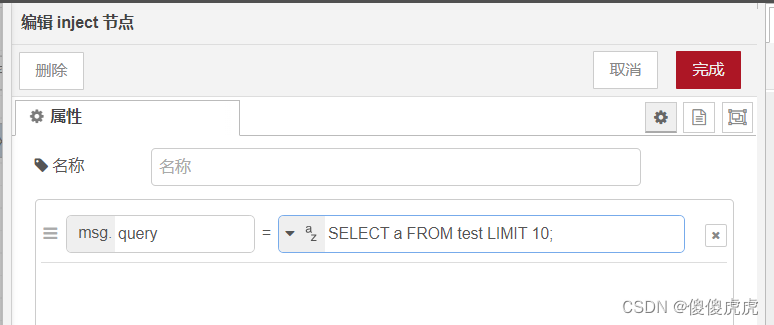
通过编写一句简单的sql 语句SELECT a FROM test LIMIT 10;,
- 在不勾选Split results in multiple messages的情况下,最后msg.payload输出是一个10个元素的数组
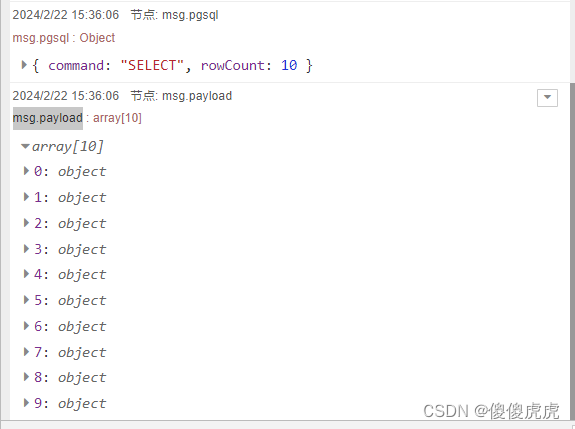
- 在勾选Split results in multiple messages,设置Number of rows per message为6的情况下,最后msg.payload输出是一个6个元素的数组,但要注意,勾选了Split results in multiple messages,msg.pgsql 就没有输出结果了。
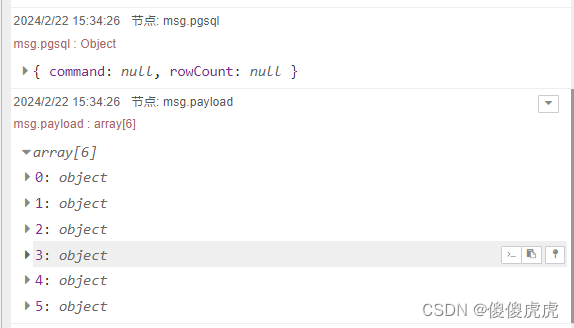
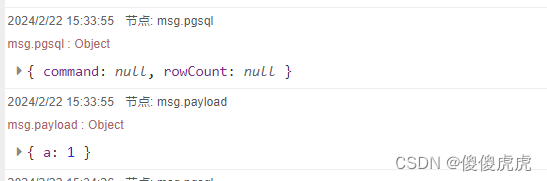
再回到关于帮助文档那句话的理解,其实是,在勾选Split results in multiple messages时,当设置Number of rows per message为1,此时输出就只有1个元素,但不是数组,而是字典。
sql 几种写法
SQL query template
- 变量为整型,不用双引号
SELECT a FROM test LIMIT {{{ msg.id }}};
- msg.id 作为变量传值
- 变量为字符串
SELECT id, employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id
FROM public.testseq
WHERE id='{{{ msg.id }}}';
- msg.id 作为变量传值,得用引号
Dynamic SQL queries
以msg.query形式注入,里面写sql 语句,然后再pg模块中不用写Query。
Parameterized queries
变量在函数中 以数组形式有序传到msg.params,然后通过$1 、$2 、… 去获取
//函数模块中写
msg.params = [ 12,11 ];
return msg;
//pg 模块中sql 编写
SELECT id, employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id
FROM public.testseq
where employee_id= $1 and manager_id =$2;
nodeRed 模块这样的配置对应的sql 就是
SELECT id, employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id
FROM public.testseq
where employee_id= 12 and manager_id =11;
子流程
子流程的创建跟流程创建类似,只是多了输入和输出选项,这个网上资源很多,可以参考大神博文Node-Red 学习笔记2-通过创建子流程来实现模块复用,而我主要记录的是,是针对其中状态节点的使用,经过了各种测试,目前依旧还未发现它的使用,网上对它的介绍,也只是记录实例的状态,没有再进一步的使用说明。所以,这个状态节点到底是什么,怎么用?
状态节点怎么用?
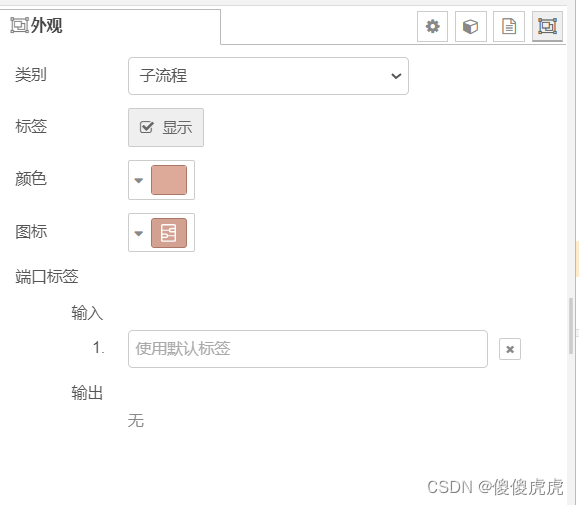
经过大神的讲解,该节点主要用于显示实例状态,如果设置了,会将对应的payload 输出到子流程下

就是下面的good,这个是因为子流程中payload 设值为good,可以根据需要定义。类似qdebug 的节点状态 自动显示。
日志
除了debug 节点,想实现输出日志并保存功能的节点是没有的,因此日志节点需要创建子流程并保存。日志功能的子流程创建如下:

主要包括 定义输出txt 文件名 + 写入信息 2部分,为了方便区分,可以左上角点击 编辑属性,在外观选项中,自定义类别、颜色、图标等。