📙 作者简介 :RO-BERRY
📗 学习方向:致力于C、C++、数据结构、TCP/IP、数据库等等一系列知识
📒 日后方向 : 偏向于CPP开发以及大数据方向,欢迎各位关注,谢谢各位的支持

目录
- 1.进程优先级
- 2.Linux下的进程优先级
- 调整优先级
- 3.进程切换
- 3.1进程特性
- 3.2寄存器
- 3.3 进程切换的过程
- 4 命令行参数
- 5.利用main函数参数实现简易计算器
- 6.环境变量
- 6.1 基本概念
- 6.2 环境变量的分类
- 6.3 查看环境变量
1.进程优先级
进程优先级就是进程要访问某种资源,进程进行通过一定的方式(排队),确认享受资源的先后顺序
CPU资源分配的先后顺序,就是值进程的优先权(priority)
优先权高的进程有优先执行的权力。
配置进程优先权对多任务环境的Linux很有用,可以改善系统性能。还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体的性能。
为什么要有优先级?
因为CPU资源有限,一台普通的电脑上CPU是4~8个,而要执行的进程少说也要20个以上,所以要让重要的进程优先执行,保证利益的最大化。
2.Linux下的进程优先级
在Linux或unix系统中,用
ps -al指令则会类似输出以下几个内容:

UID:代表执行者的身份,用户标识符PID:代表这个进程的代号PPID:代表这个进程是由那个进程发展衍生而来的,亦即父进程的代号PRI:代表这个进程可被执行的优先级,其值越小越早被执行NI:代表这个进程的nice值
PRI 和 NI
- PRI(priority),即进程的优先级,就是程序被CPU执行的先后顺序,此值越小进程的优先级越高
每个普通进程的PRI默认值为80- NI(nice),表示进程可被执行的优先级的修正数值
- nice值默认基本都是0
- PRI值越小越快被执行,加入nice值后,将会使得PRI变为:
PRI = 80 + nice- 当nice为负数时,该进程的优先级将会变小,即期优先级会变高,则其越快被执行
- 调整优先级,在Linux下,就是调整进程的nice值
- nice其取值范围是
-20~19,一共40个级别(一般不会去改nice值,一直使用默认值)
nice值之所以有范围,为了防止优先级被调整过度,时每次先使用CPU都是同一批进程,其它进程没办法更好的调度执行,所以过渡器 不允许过度调整nice值
调度器主要功能:较均衡的让每个进程都可以使用CPU推进代码,而不能使一个或几个进程产生偏差
所以,优先级对于我们来说并不是很重要,我们一般写代码也几乎不回去调整优先级
注意
进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。
可将nice理解为是进程优先级的修正数据
关于优先级PRI着重强调
Linux默认优先级是80
Linux的优先级是可以修改的,Linux的优先级的范围(60,99]
Linux优先级本质是数字,数字越小,优先级越高
调整优先级
调整方法非常多,可以使用代码去调整,也可以用指令去调,这里我们讲一下使用top去调整进程的优先级
写一个简单程序
myprocess.c
1 #include<stdio.h>2 #include<unistd.h>3 #include<stdlib.h>4 int main()5 {6 while(1)7 {8 printf("I am process, pid: %d\n",getpid()); 9 sleep(1);10 }11 }
makefile
myprocess:myprocess.cgcc -o $@ $^ #-std=c99
.PHONY:clean
clean:rm -f myprocess
使用make指令生成可执行文件myprocess,之后按照下面的步骤做
- 执行该文件
- 使用ps -la查看对应进程的PID
- 使用top指令打开top
- 进入top后,按“r”
- 输入进程PID,回车
- 输入需要调整的nice值,回车
- 按q退出top
- 使用ps -la查看对应进程的PID

- 使用top指令打开top
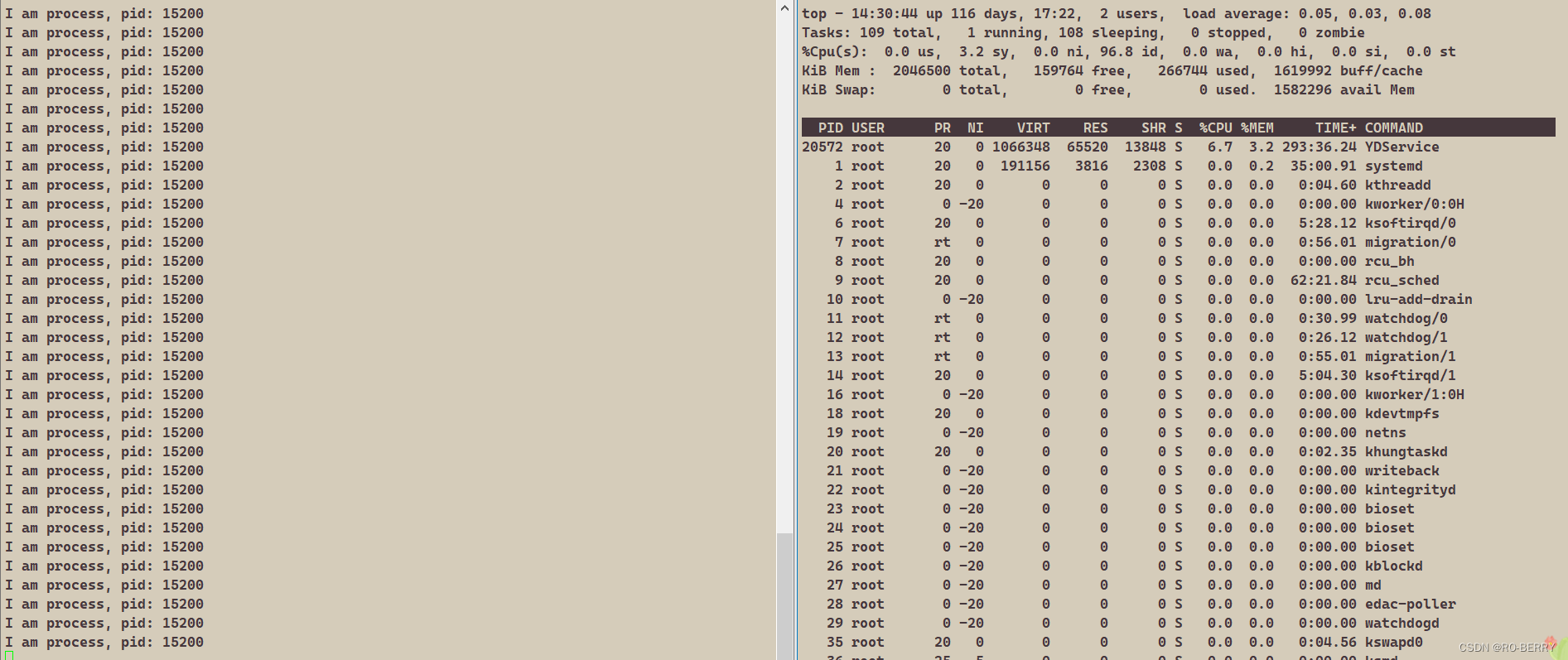
- 进入top后,按“r”
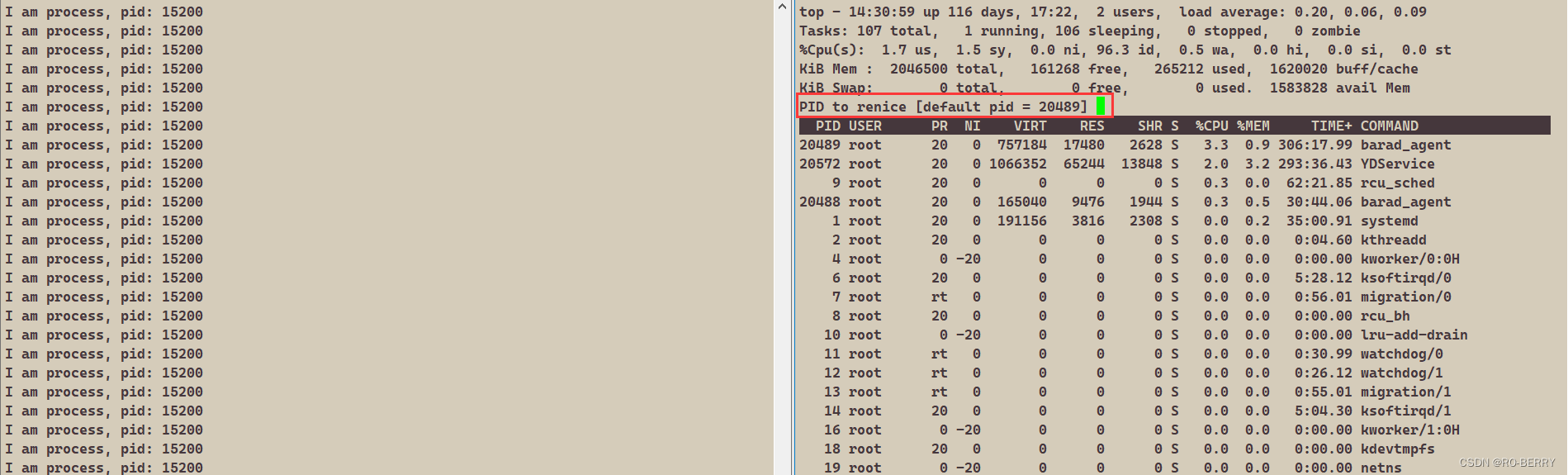
- 输入进程PID,回车
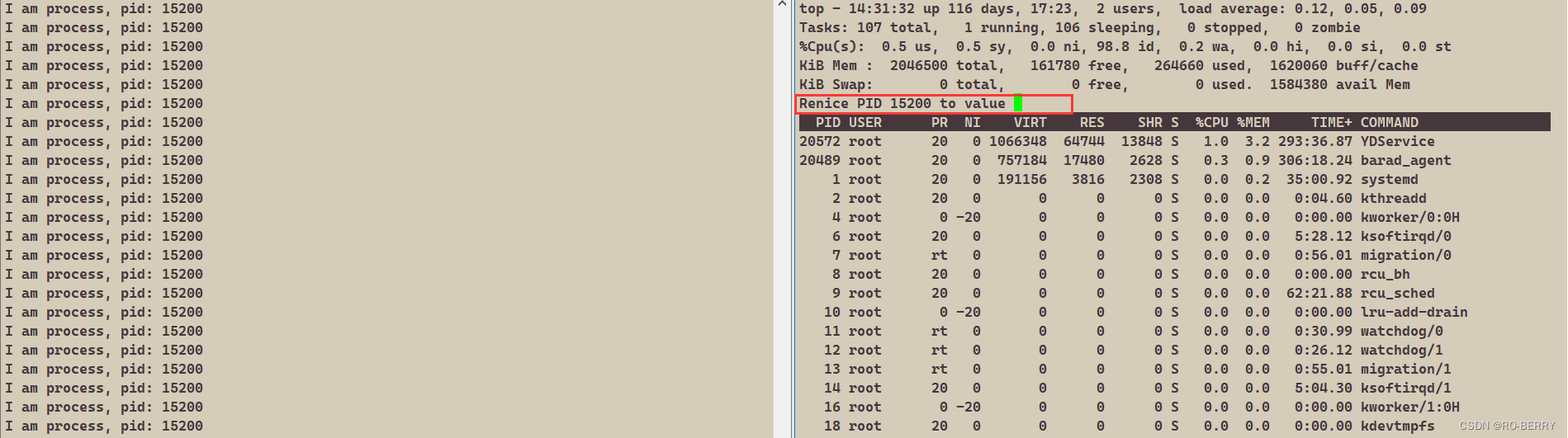
- 输入需要调整的nice值,输入10回车,然后按q退出top再次使用ps -la查看对应进程的PID

PRI变为90,并且NI变为10
注意:
如果调整的nice值过大,那调整的值默认为19
如果调整的nice值过小,那调整值默认为-20
每次修改调整值,最终的PRI都是80加上nice值
Linux为什么调整优先级是有一个范围的?
进程饥饿问题
如果不加限制,那么将自己的进程优先级调整的非常高,别人的优先级调整的非常低,每个人都会想把自己的程序优先级调到最高,优先级较高的进程,会优先得到资源,但是后续还有源源不断的进程产生,常规进程就会很难享受到CPU资源,就会导致进程饥饿问题
3.进程切换
3.1进程特性
- 竞争性:系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了搞小完成任务,更合理竞争相关资源,便具有了优先级。
- 独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰
- 并行:多个进程在多个CPU下分别、同时进行运行,这称之为并行。
- 并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
3.2寄存器
一个CPU里面存在很多的寄存器寄存器,寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果以及一些CPU运行需要的信息。
寄存器主要分为:通用寄存器、标志寄存器、指令寄存器、段寄存器、控制寄存器、调试寄存器、描述符寄存器、任务寄存器、MSR寄存器
通用寄存器
eax: 通常用来执行加法,函数调用的返回值一般也放在这里面
ebx: 数据存取
ecx: 通常用来作为计数器,比如for循环
edx: 读写I/O端口时,edx用来存放端口号
esp: 栈顶指针,指向栈的顶部
ebp: 栈底指针,指向栈的底部,通常用ebp+偏移量的形式来定位函数存放在栈中的局部变量
esi: 字符串操作时,用于存放数据源的地址
edi: 字符串操作时,用于存放目的地址的,和esi两个经常搭配一起使用,执行字符串的复制等操作
标志寄存器
标志寄存器,里面有众多标记位,记录了CPU执行指令过程中的一系列状态,这些标志大都由CPU自动设置和修改:
- CF 进位标志
- PF 奇偶标志
- ZF 零标志
- SF 符号标志
- OF 补码溢出标志
- TF 跟踪标志
- IF 中断标志
- …
指令寄存器
eip: 指令寄存器可以说是CPU中最最重要的寄存器了,它指向了下一条要执行的指令所存放的地址,CPU的工作其实就是不断取出它指向的指令,然后执行这条指令,同时指令寄存器继续指向下面一条指令,如此不断重复,这就是CPU工作的基本日常。
段寄存器
段寄存器与CPU的内存寻址技术紧密相关。
控制寄存器
控制寄存器是CPU中一组相当重要的寄存器,我们知道eflags寄存器记录了当前运行线程的一系列关键信息。那CPU运行过程中自身的一些关键信息保存在哪里呢?答案是控制寄存器!
调试寄存器
在x86/x64CPU内部,还有一组用于支持软件调试的寄存器。
描述符寄存器
所谓描述符,其实就是一个数据结构,用来记录一些信息,‘描述’一个东西。把很多个描述符排列在一起,组成一个表,就成了描述符表。再使用一个寄存器来指向这个表,这个寄存器就是描述符寄存器。
任务寄存器
CPU内部设置了一个专用的寄存器——任务寄存器TR,它指向当前运行的任务
MSR寄存器
从80486之后的x86架构CPU,内部增加了一组新的寄存器,统称为MSR寄存器,中文直译是模型特定寄存器,意思是这些寄存器不像上面列出的寄存器是固定的,这些寄存器可能随着不同的版本有所变化。这些寄存器主要用来支持一些新的功能。
3.3 进程切换的过程
- 计算机调度某个进程时,CPU 会把这个进程的 PCB 地址加载到某个寄存器,也就是说,CPU内有寄存器可以只找到进程的PCB地址。
- CPU里有一个 eip 寄存器(PC指针),指向当前执行指令的下一条指令的地址。
- 当进程在运行的时候,一定会产生非常多的临时数据,这些临时数据只属于当前进程,这些临时数据会放在CPU的寄存器中。CPU内部的所有的临时数据我们称做为硬件上下文。
- 进程在调度的时候占有CPU,但是却不是一直占有到进程结束,进程都有自己的时间片,有了时间片就可以实现高效率调度,因为时间片的存在,进程会出现没有被执行完就被拿下去的情况。
- 当进程被换下去的时候,进程的运行信息会被存在操作系统里面,以便下次CPU重新调度时进程能够正常运行,这叫做进程的上下文保护。
- 在进程第二次被CPU调度的时候,首先要做的第一件事情就是读取操作系统中进程运行的相关数据,这叫做进程的上下文恢复,然后进程就会继续上次没执行完的任务开始运行。
注意:
CPU内的寄存器只有一套,区分寄存器以及寄存器的内容,这两个是不一样的,我们运行进程使用这一套寄存器并且产生临时数据,当进程离开的时候,这些临时数据一并带走存入操作系统,当次进程再次运行的时候,数据重新拿出来。
但是寄存器内部保存的数据可以有多套,虽然寄存器数据放在了一个共享的CPU设备里,但是所有的数据,其实都是被进程私有的!进程和进程之间使用同一个CPU以及寄存器,但是其中的数据不是共享的。
4 命令行参数
请你回想一下写C语言代码的时候,我们的主函数main函数带参数吗?我们一般写main函数里面不带参数也就是void参数对吧?
其实main函数默认是带参数的函数
#include<stdio.h>
int main(int argc,char *argv[])
{return 0
}
我们这样直接运行代码是能跑的
这里的char *argv就是一个指针数组,int argc则代表了这个指针数组里有多少个成员
这里面存的是什么呢?
我们来试着打印一下
#include<stdio.h>
int main(int argc,char *argv[])
{for(int i=0;i < argc; i++){printf("argv[%d]:%s\n",i,argv[i]);}return 0;
}
运行结果

其演变过程如下:
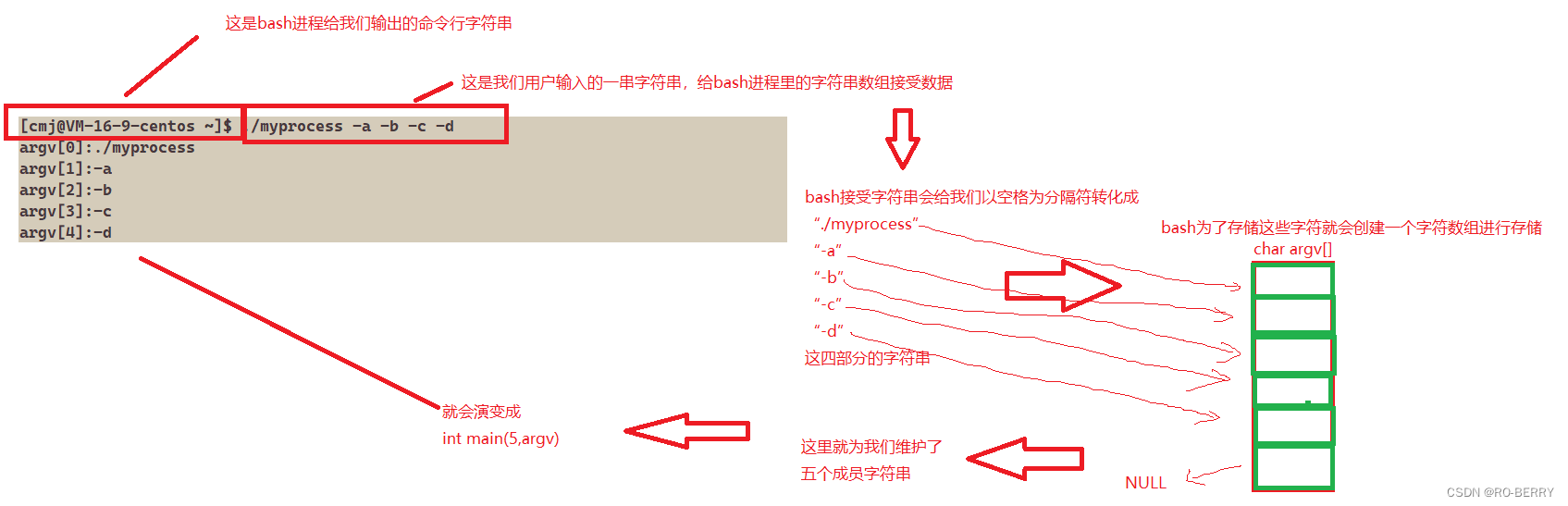
这就是我们bash维护的命令行参数表
那到底为什么要这样做呢?
请看下面的例子:
#include<stdio.h>
#include<string.h>//要实现三种不同的功能
// ./myprocess -3
int main(int argc,char *argv[])
{if(argc != 2){printf("Usage:\n\t%s -number[1-3]\n",argv[0]);return 1;}if(strcmp("-1",argv[1]) == 0){printf("function 1\n");}else if(strcmp("-2",argv[1]) == 0){printf("function 2\n");}else if(strcmp("-3",argv[1]) == 0){printf("function 3\n");}else{printf("unKnow!\n");}return 0;
}运行结果

通过这个代码片段我们已经实现了简单的功能:
我们可以通过不同的选项,让我们的同一个程序执行它内部不同的功能
我们这样使用程序,有没有觉得眼熟呢?
我们使用的这些Linux指令不也是这样使用的吗?
我们指令后面的这些选项让我们可以实现指令的不同的功能
所以指令后面的这些选项的本质是我们的命令行参数!!!!
命令行参数是我们Linux选项指令的基础
5.利用main函数参数实现简易计算器
既然main函数参数可以读到命令行
中输入的字符串,所以可以用代码实现
一个简易的计算器,代码如下:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
int main(int argc,char* argv[])
{ if(argc!=4) { printf("%s OP[add|sub|mul|div] d1 d2\n",argv[0]); return 1; } int x=atoi(argv[2]); int y=atoi(argv[3]); if(strcmp(argv[1],"add")==0) printf("%d + %d = %d\n",x,y,x+y); else if(strcmp(argv[1],"sub")==0) printf("%d - %d = %d\n",x,y,x-y); else if(strcmp(argv[1],"mul")==0) printf("%d * %d = %d\n",x,y,x*y); else if(strcmp(argv[1],"div")==0) printf("%d / %d = %d\n",x,y,x/y); else printf("输入操作符错误"); return 0;
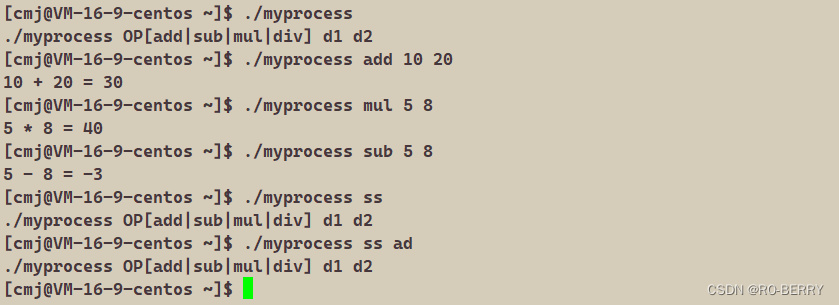
} 使用方法:
- 用户必须先输入可执行程序:a.out
- 第二个字符串输入加减乘除其中一个
- 第三,第四个字符串输入操作数
- 若其中有一个环节输入错误会报提醒
6.环境变量
6.1 基本概念
环境变量一般是指在操作系统中用来指定操作系统运行环境的一些参数。
如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但 是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找;
环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性。
程序(操作系统命令和应用程序)的执行都需要运行环境,这个环境是由多个环境变量组成的。
6.2 环境变量的分类
按生效的范围分类
系统环境变量:公共的,对全部的用户都生效。
用户环境变量:用户私有的、自定义的个性化设置,只对该用户生效。
按生存周期分类
永久环境变量:在环境变量脚本文件中配置,用户每次登录时会自动执行这些脚本,相当于永久生效。
临时环境变量:使用时在Shell中临时定义,退出Shell后失效。
6.3 查看环境变量
我们来先思考一个问题
为什么我们myprocess可执行文件前面需要加上./Linux指令在使用的时候不需要在前面加上./
这是因为我们系统在执行myprocess文件的时候是去查找了,但是没找到,所以我们在前面加上./或者绝对路径就可以运行了,所以我们想执行一个程序系统需要先找到
这不得不引出一个概念: 环境变量
保存程序的默认搜索路径的环境变量
叫做: PATH
在运行程序时,系统会去PATH中
找当前可执行程序在不在这些路径中
如果在就直接执行程序,不在就报错
使用指令查看PATH
echo $PATH

这个路径是以无数个子路径组成,路径之间以冒号进行分隔
系统在这些路径下都找不到你的程序就会报错
所以只能通过./告诉系统我们在这个路径下查找
所以要想我们的指令像系统指令一样运行
我们可以将自己写的程序的路径加入
到环境变量PATH中!
注意:我们进行拷贝需要root的权限,普通用户使用指令需要sudo
使用指令:
sudo cp myprocess /usr/bin/
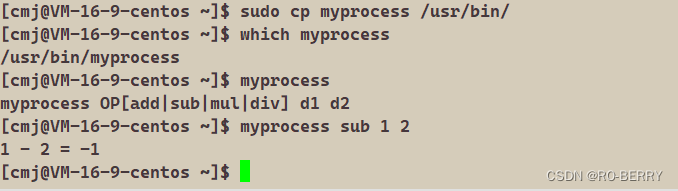
我们刚刚是拷贝数据到默认路径下实现我们的程序可以像系统指令一样运行起来
那我们可不可以把我们的工作目录也加入到默认搜索路径下面呢?那我们就不用每一次都要一个一个程序去加入默认路径了
使用指令: PATH = $PATH:要添加的路径

请注意,当你将你的路径添加后
下次重启时又会恢复为默认路径
所以想一劳永逸的话可以将你自己
的可执行程序放入默认的路径中!
查看所有环境变量
使用指令
env
可以看到这里很多,看的眼花缭乱,我们并不需要每一个都认识,我们简单认识几个:
- 1.环境变量PWD
为什么我们可以使用pwd查看当前目录呢?
这是因为存在pwd环境变量,当你访问目录这个环境变量会自动更新
- 2.环境变量USER
为什么我们使用
whoami指令就会打出当前用户的用户名呢?
这是因为我们的环境变量USER,它记录了我们登入Linux的用户的用户名信息
- 3.环境变量HOME
为什么我们使用
cd ~就可以访问我们的家目录呢?
这是因为我们有环境变量HOME,他记录着我们当前用户的家目录
学习之路还很漫长,如果我的文章对你有所帮助的话,不妨关注加三连给我一个支持,感谢各位IT大佬