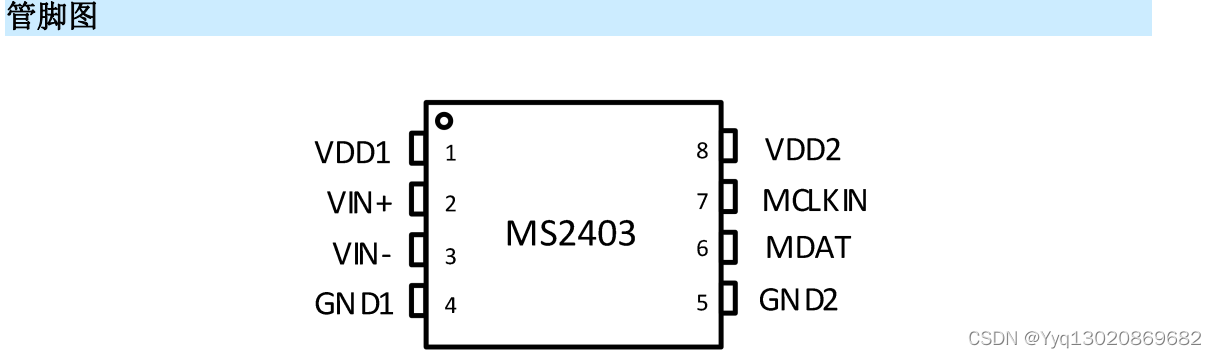
Spring 的三级缓存机制
Spring 的三级缓存机制是解决循环依赖的关键。
Spring 框架为了解决循环依赖问题,设计了一套三级缓存机制。这三级缓存分别是:
- 一级缓存 singletonObjects:这是最常规的缓存,用于存放完全初始化好的 bean。如果某个 bean 已经在这个缓存中,则直接返回这个 bean 的实例。
- 二级缓存 earlySingletonObjects:这个缓存用于存放早期暴露出来的 bean,也就是那些已经创建但尚未完成初始化(如属性填充和初始化方法调用)的 bean。这样做的目的是为了在 bean 的创建过程中就能提前暴露出来,以便于解决循环依赖的问题。
- 三级缓存 singletonFactories:这个缓存存放的是 bean 的工厂对象,这些工厂对象负责生成 bean 的实例。当一个 bean 被创建时,它的工厂对象会被放入这个缓存中。
通过这三级缓存,Spring 能够在 bean 的创建过程中就解决循环依赖的问题。具体来说,当 AOP 代理对象需要引用其他 bean 时,可以通过提前暴露的二级缓存来获取尚未完全初始化的 bean,从而打破循环依赖的僵局。
以下是一个简单的例子来说明这个过程:
假设有两个 bean,A 和 B,它们相互依赖。当 Spring 容器开始创建 bean A 时,它会首先检查一级缓存中是否已经有了 bean A 的实例。如果没有,它会创建一个 bean A 的实例,并将其工厂对象放入三级缓存中。然后,bean A 的创建过程会因为需要注入 bean B 而被挂起,Spring 会转而去创建 bean B。
在创建 bean B 的过程中,同样会检查一级缓存中是否已经有了 bean B 的实例。由于还没有创建,Spring 会将 bean B 的半成品(即尚未完成初始化的实例)放入二级缓存中,并继续创建过程。这时,bean B 也需要依赖 bean A,但由于 bean A 的工厂对象已经在三级缓存中,Spring 可以直接从三级缓存中获取到 bean A 的工厂对象,并通过它来创建 bean A 的实例。
这样,即使两个 beans 相互依赖,Spring 也能够通过三级缓存机制成功地创建它们,解决了循环依赖的问题。

参考文章——Spring中的“三级缓存”
参考文章——Spring面试题之循环依赖与三级缓存
为什么 Spring 只有二级缓存不行
Spring只有二级缓存确实无法完全解决循环依赖问题,尤其是在涉及到AOP代理时。
二级缓存earlySingletonObjects用于存储半成品的Bean实例,即那些已经被实例化但尚未完成初始化(如属性填充和方法调用)的Bean。这个缓存允许Spring在Bean的创建过程中就能提前暴露出来,以便于解决循环依赖的问题。然而,如果只有二级缓存,当涉及到AOP代理时,问题就来了。
AOP代理的生成是在Bean的初始化阶段完成的,这意味着在Bean的所有属性都被设置之后。如果一个Bean需要被代理,那么在代理之前,Spring会尽量从缓存中获取到原始的Bean实例,以避免在代理过程中出现循环引用的问题。但是,如果只有二级缓存,那么在Bean初始化之前,我们无法从缓存中获取到代理对象,因为二级缓存中存储的是尚未初始化的Bean实例,而不是代理对象。
举个例子,假设有两个Bean,A和B,它们相互依赖,并且A需要被AOP代理。在Spring的创建过程中,首先会创建A的实例并将其放入二级缓存中。然后,当尝试创建B并注入A时,会发现A还没有完成初始化,因此无法生成A的代理对象。这样就会导致循环依赖的问题无法被解决。
而三级缓存中的singletonFactories存储的是Bean的工厂对象,可以在Bean初始化之前就生成代理对象,并将其放入一级缓存singletonObjects中。这样,即使Bean之间存在循环依赖,Spring也能够通过三级缓存机制成功地创建它们,解决了循环依赖的问题。
总的来说,三级缓存机制是Spring为了在保持设计原则的同时,解决循环依赖和AOP代理的问题而设计的。二级缓存虽然可以解决部分循环依赖的问题,但在面对AOP代理时就显得力不从心了。因此,Spring需要三级缓存来确保在复杂情况下依然能够正常工作。
让我们通过一个具体的例子来理解为什么仅有二级缓存无法解决涉及AOP代理的循环依赖问题。
假设我们有两个Bean,ServiceA和ServiceB,它们相互依赖,并且ServiceA需要被AOP代理(例如,为了实现事务管理)。
-
创建ServiceA实例:Spring首先尝试创建
ServiceA的实例。在实例化过程中,ServiceA尚未完成初始化(例如,还未填充属性,未调用初始化方法等),但它的半成品实例被放入了二级缓存earlySingletonObjects。 -
创建ServiceB实例:接着,Spring尝试创建
ServiceB的实例,并试图注入ServiceA。由于ServiceA的完整初始化尚未完成,因此无法生成其AOP代理。 -
AOP代理问题:在Spring中,AOP代理是在Bean的初始化阶段完成的,这意味着所有的属性填充和方法调用之后。如果
ServiceA需要被代理,那么在代理之前,Spring会尝试从缓存中获取到原始的ServiceA实例,以避免在代理过程中出现循环引用的问题。但是,如果只有二级缓存,那么在ServiceA初始化之前,我们无法从缓存中获取到代理对象,因为二级缓存中存储的是尚未初始化的ServiceA实例,而不是代理对象。 -
循环依赖:由于
ServiceB需要注入ServiceA,而ServiceA又需要被AOP代理,这就形成了一个循环依赖。如果没有三级缓存,Spring就无法在ServiceA完全初始化之前创建一个代理实例来解决这个循环依赖。
现在,让我们看看三级缓存是如何解决这个问题的:
-
三级缓存singletonFactories:在创建
ServiceA的过程中,它的工厂对象会被放入三级缓存singletonFactories。这个工厂对象负责生成ServiceA的实例。 -
解决循环依赖:当创建
ServiceB并尝试注入ServiceA时,Spring会检查三级缓存中是否存在ServiceA的工厂对象。如果存在,Spring使用该工厂对象来创建ServiceA的代理实例,并将其放入一级缓存singletonObjects中。这样,即使ServiceA和ServiceB相互依赖,Spring也能够通过三级缓存机制成功地创建它们,解决了循环依赖的问题。
总结来说,二级缓存能够解决一些循环依赖问题,但在涉及AOP代理的情况下,它无法提供一个尚未初始化的Bean的代理实例。三级缓存通过引入工厂对象来提前创建代理实例,从而解决了这个问题。
创建ServiceB实例:接着,Spring 尝试创建 ServiceB 的实例,并试图注入 ServiceA。由于 ServiceA 的完整初始化尚未完成,因此无法生成其 AOP 代理。 这里为什么要生成 ServiceA 的 AOP 代理,是不是 ServiceB 要注入的是 ServiceA 的代理对象
是的,ServiceB要注入的是ServiceA的代理对象。在Spring中,如果一个Bean被AOP代理,那么其他Bean注入的是这个Bean的代理对象,而不是原始的Bean实例。这样做的目的是为了让代理对象能够拦截对原始Bean方法的调用,以便在调用前后执行额外的操作,如日志记录、事务管理等。
在创建ServiceB实例时,如果需要注入ServiceA,而ServiceA尚未完成初始化,就无法生成其AOP代理。这是因为AOP代理是在Bean的初始化阶段完成的,这意味着所有的属性填充和方法调用之后。如果ServiceA需要被代理,那么在代理之前,Spring会尝试从缓存中获取到原始的ServiceA实例,以避免在代理过程中出现循环引用的问题。
因此,生成ServiceA的AOP代理是为了确保在Bean的初始化阶段能够生成代理对象,并将其注入到其他Bean中,从而实现横切关注点的模块化。这样,开发人员可以专注于核心业务逻辑的开发,而不必关心那些横切关注点的实现细节。
三级缓存singletonFactories 既可以创建代理bean也可以创建非代理bean
是的,三级缓存singletonFactories可以用于创建代理bean和非代理bean。
在Spring中,singletonFactories是一个Map类型的缓存,它存储了Bean的工厂对象。这些工厂对象负责生成Bean的实例。当需要创建一个Bean时,Spring会首先检查一级缓存singletonObjects中是否已经存在该Bean的实例。如果不存在,则继续检查二级缓存earlySingletonObjects中是否存在半成品的Bean实例。如果仍然不存在,Spring会从三级缓存singletonFactories中获取到对应Bean的工厂对象,并使用该工厂对象来创建Bean的实例。
对于非代理Bean,singletonFactories中的工厂对象直接创建Bean的实例并将其放入一级缓存singletonObjects中。而对于需要被AOP代理的Bean,singletonFactories中的工厂对象会先创建一个原始的Bean实例,然后通过AOP代理来生成代理对象,并将代理对象放入一级缓存singletonObjects中。
因此,三级缓存singletonFactories既可以创建代理bean,也可以创建非代理bean,根据具体的需求和配置来决定是否需要进行AOP代理。