特别说明:参考官方开源的yolov9代码、瑞芯微官方文档、地平线的官方文档,如有侵权告知删,谢谢。
模型和完整仿真测试代码,放在github上参考链接 模型和代码。
之前写过yolov8检测、分割、关键点模型的部署的多篇博文,yolov8还没玩溜,这不yolov9又来了。yolov9刚出来两三天,有朋友就问:yolov9都出来好几天了,怎么没有见到你写一篇部署博客呢。其实yolov9出来两三天,说实话还是通过朋友告知才知道的。一直想抽时间把yolov9部署给盘一下,奈何一拖就又是好几天,这两天抽时间终于把这个yolov9给盘完了。
1 模型和训练
训练代码参考官方开源的yolov9训练代码,考虑到有些板端对SiLU的支持有限,本示例训练前把激活函数SiLU替换成了ReLU,训练使用的模型配置文件是yolov9.yaml,输入分辨率640x640。用 from thop import profile 统计的模型计算量和参数 Flops: 120081612800.0(120G),Params: 55388336.0(55M)
2 导出 yolov9 onnx
导出onnx时需要修改两个地方。
特别说明:只在导出onnx时修改,训练时无需修改,修改以下代码后运行会报错,但是可以生成onnx文件,无需关注报错。
第一个处:增加以下代码(红色框能新增):
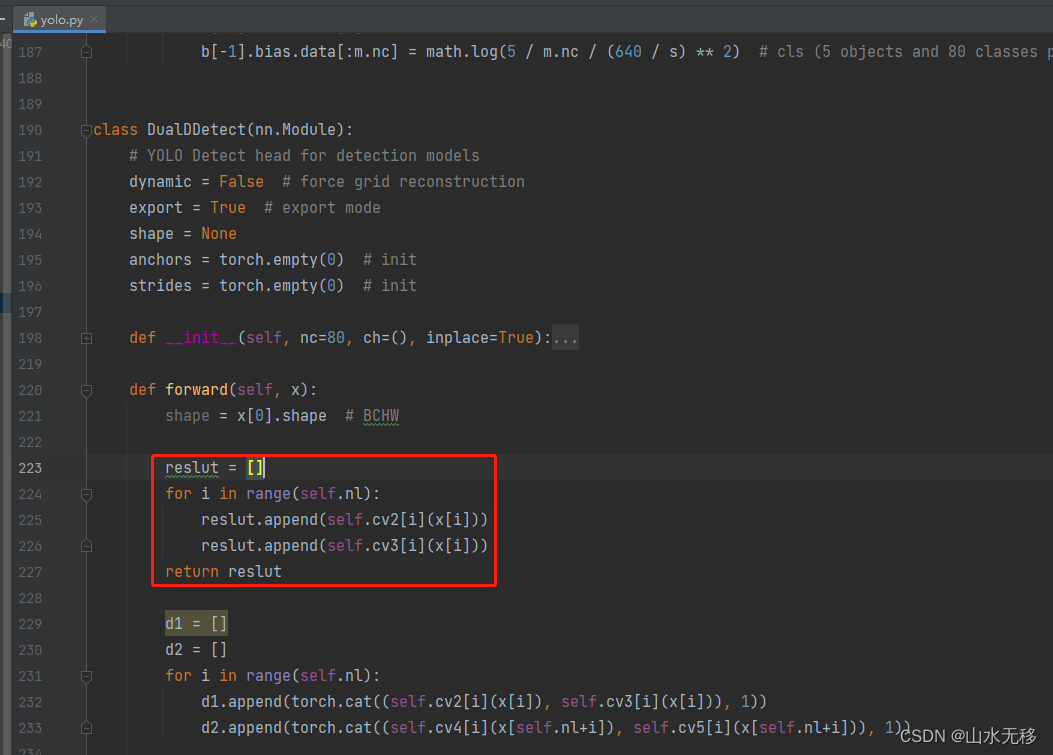
reslut = []for i in range(self.nl):reslut.append(self.cv2[i](x[i]))reslut.append(self.cv3[i](x[i]))return reslut
第二处修改:增加以下代码(红色框能新增)
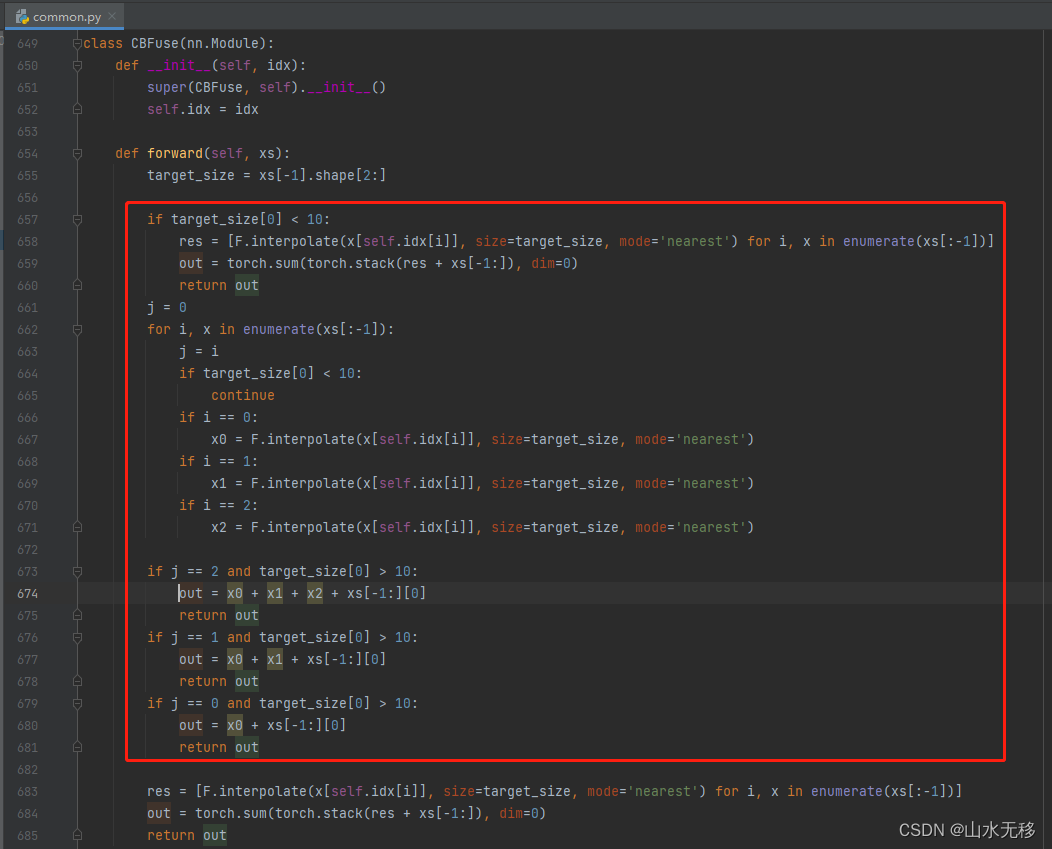
class CBFuse(nn.Module):def __init__(self, idx):super(CBFuse, self).__init__()self.idx = idxdef forward(self, xs):target_size = xs[-1].shape[2:]if target_size[0] < 10:res = [F.interpolate(x[self.idx[i]], size=target_size, mode='nearest') for i, x in enumerate(xs[:-1])]out = torch.sum(torch.stack(res + xs[-1:]), dim=0)return outj = 0for i, x in enumerate(xs[:-1]):j = iif target_size[0] < 10:continueif i == 0:x0 = F.interpolate(x[self.idx[i]], size=target_size, mode='nearest')if i == 1:x1 = F.interpolate(x[self.idx[i]], size=target_size, mode='nearest')if i == 2:x2 = F.interpolate(x[self.idx[i]], size=target_size, mode='nearest')if j == 2 and target_size[0] > 10:out = x0 + x1 + x2 + xs[-1:][0]return outif j == 1 and target_size[0] > 10:out = x0 + x1 + xs[-1:][0]return outif j == 0 and target_size[0] > 10:out = x0 + xs[-1:][0]return outres = [F.interpolate(x[self.idx[i]], size=target_size, mode='nearest') for i, x in enumerate(xs[:-1])]out = torch.sum(torch.stack(res + xs[-1:]), dim=0)return out
最后:增加保存onnx文件代码
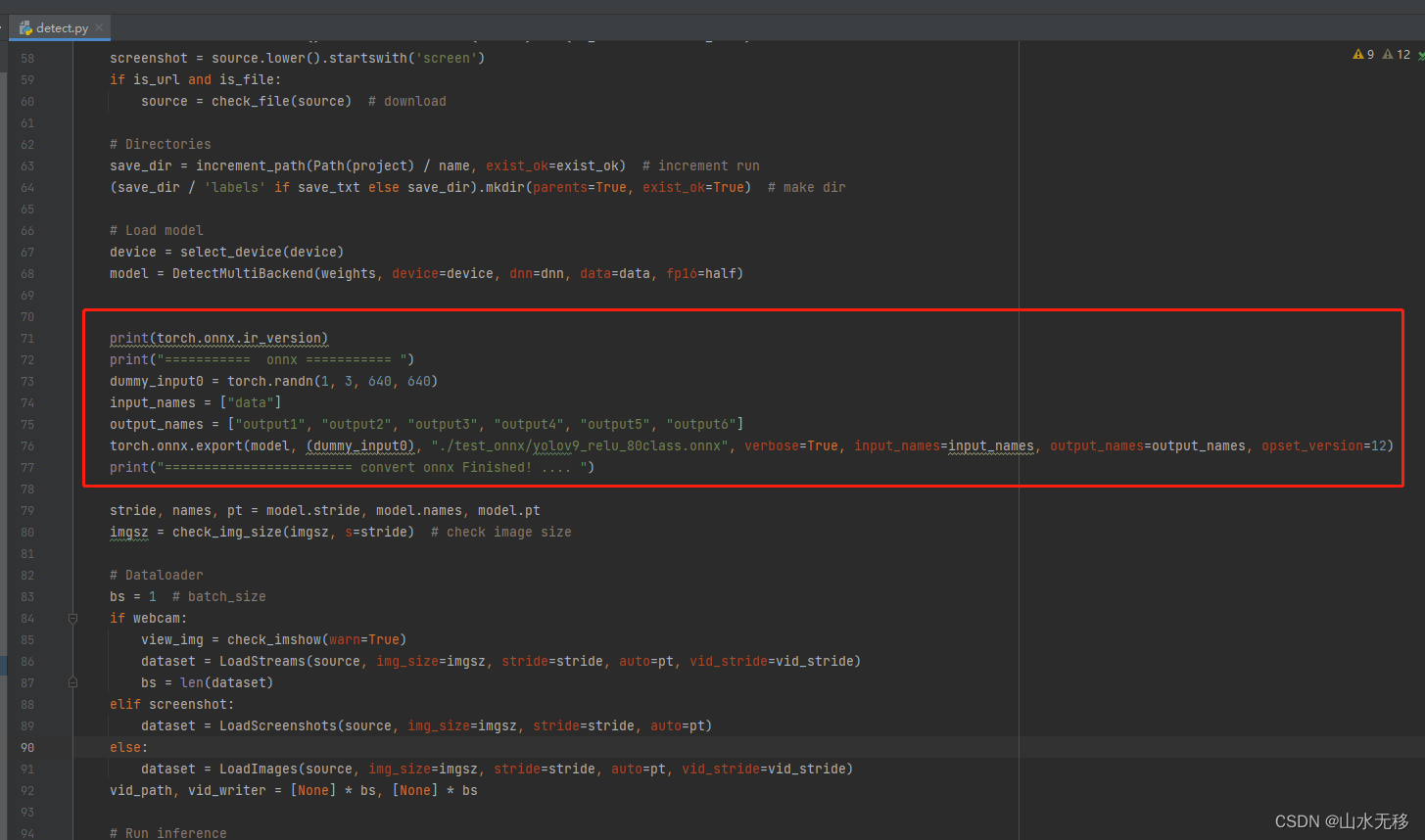
print(torch.onnx.ir_version)print("=========== onnx =========== ")dummy_input0 = torch.randn(1, 3, 640, 640)input_names = ["data"]output_names = ["output1", "output2", "output3", "output4", "output5", "output6"]torch.onnx.export(model, (dummy_input0), "./test_onnx/yolov9_relu_80class.onnx", verbose=True, input_names=input_names, output_names=output_names, opset_version=12)print("======================== convert onnx Finished! .... ")
3 yolov9 测试效果
pytorhc测试效果

onnx测试效果(确保修改CBFuse后导出的onnx测试结果和pytorch是一致的)

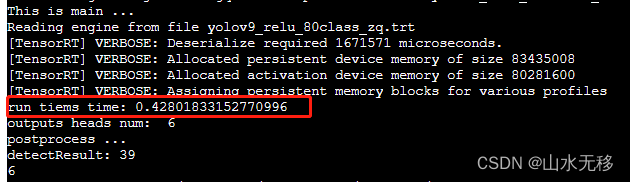
4 tensorRT 时耗
模型训练使用的配置文件是yolov9.yaml,输入分辨率是640x640,转trt使用的fp16_mode,显卡Tesla V100,cuda_11.0。
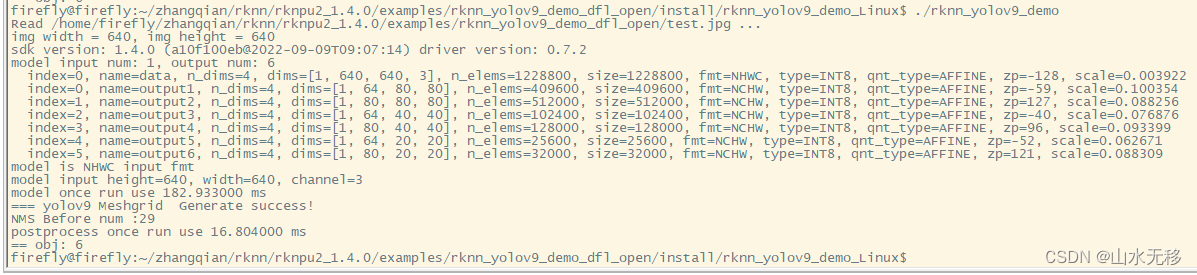
5 rknn 板端C++部署
模型训练使用的配置文件是yolov9.yaml,输入分辨率是640x640,芯片rk3588.
把在rk3588板子上测试的模特推理时耗,和用C++代码写的后处理时耗,都给贴出来供大家参考。【rk3588的C++代码参考链接】。
![[Flutter]设置应用包名、名称、版本号、最低支持版本、Icon、启动页以及环境判断、平台判断和打包](https://img-blog.csdnimg.cn/direct/7949861475f24fb49d880e1737da4f66.png)