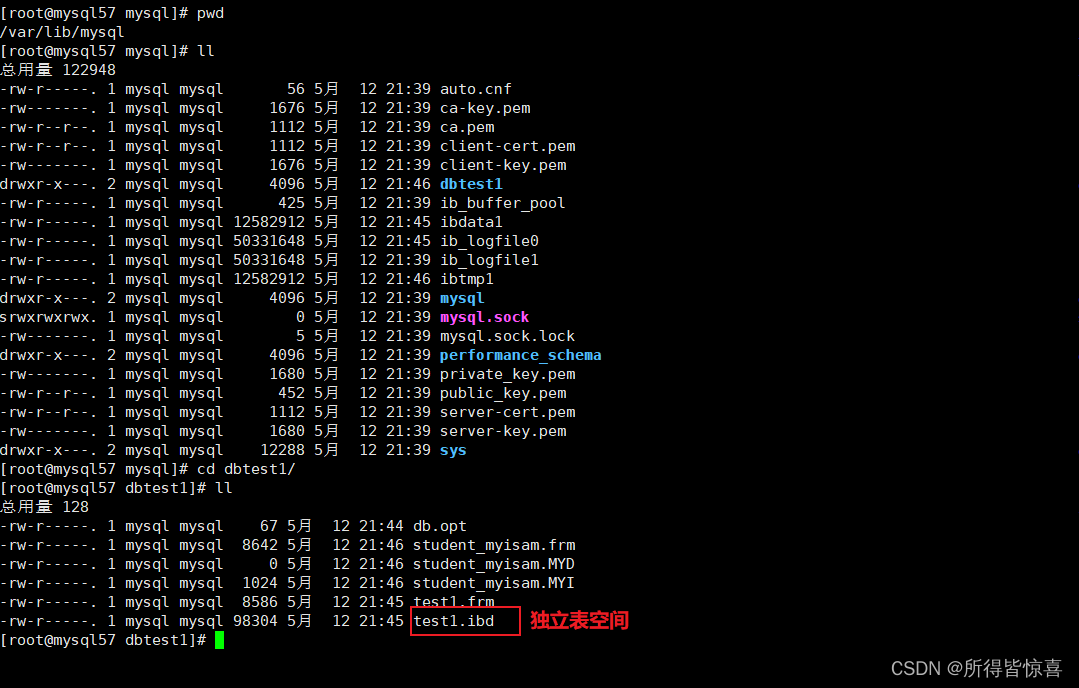
binwalk 查看图片,发现有 rar 文件,提取后如上图所示(flag.txt为已经解压后出来的)其中这个 rar 需要用 archpr爆破一下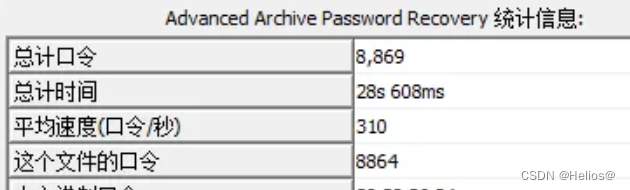
打开后一个 flag.txt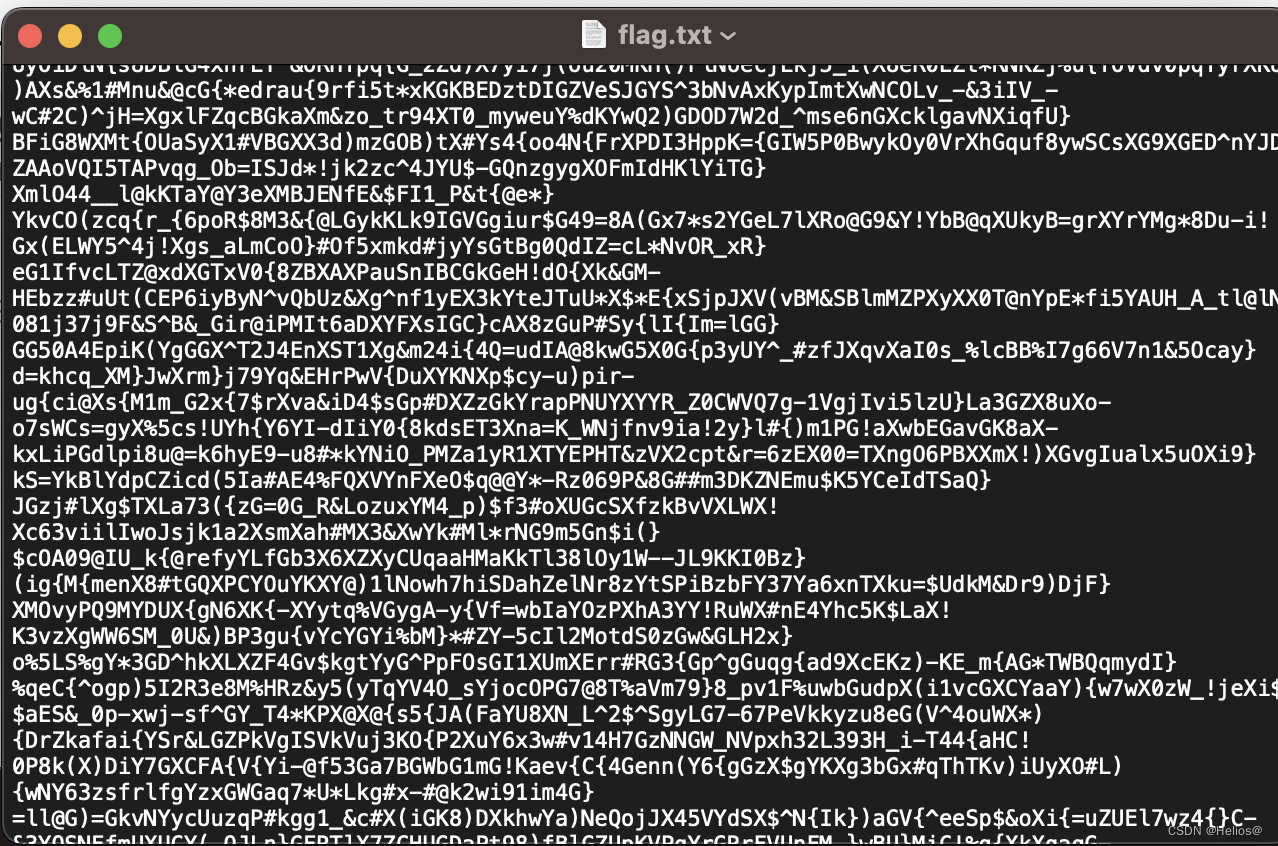
一堆杂乱无章的字符,需要用到 python 脚本进行词频统计,我们采用两种输出法,见下图:
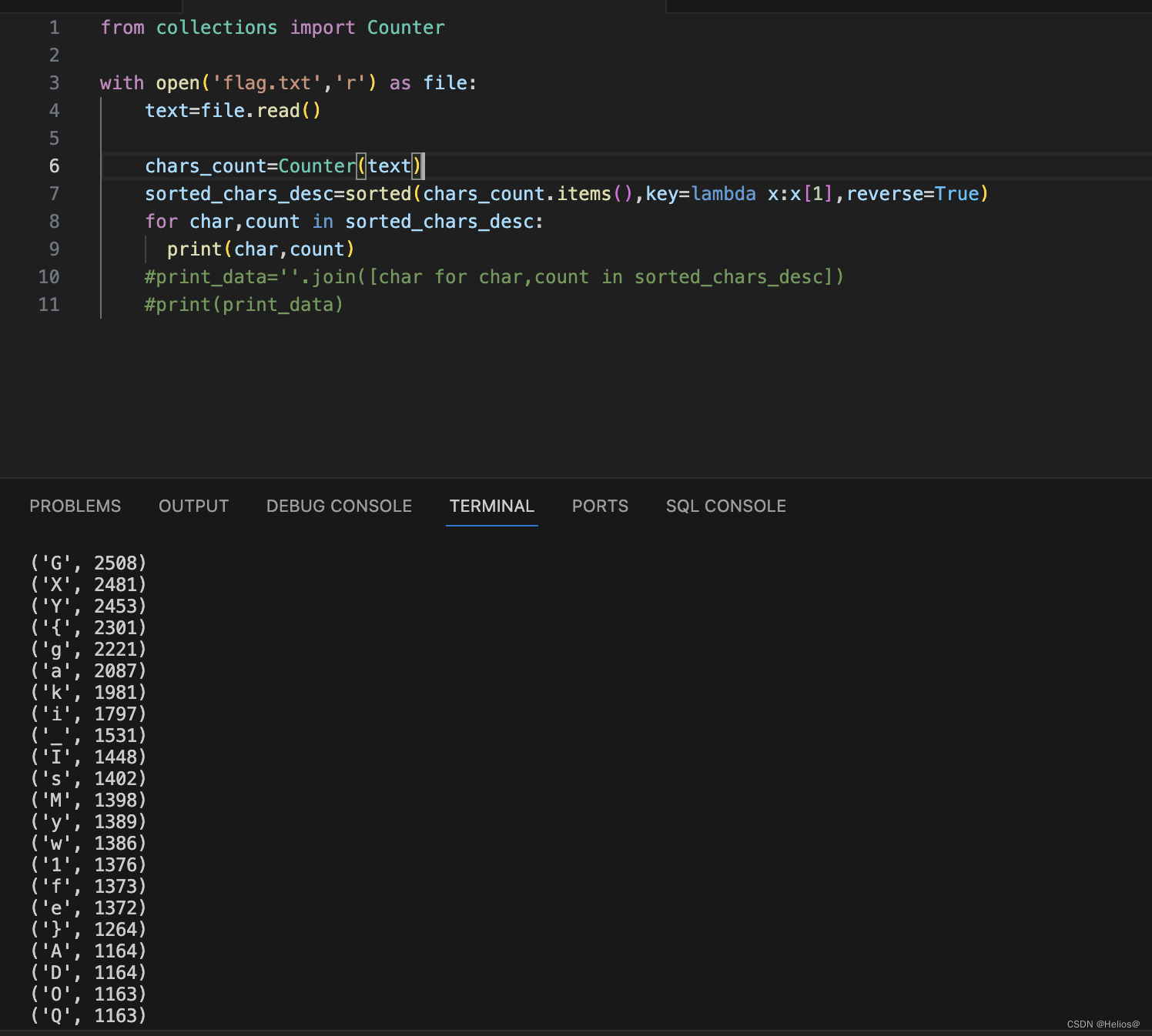
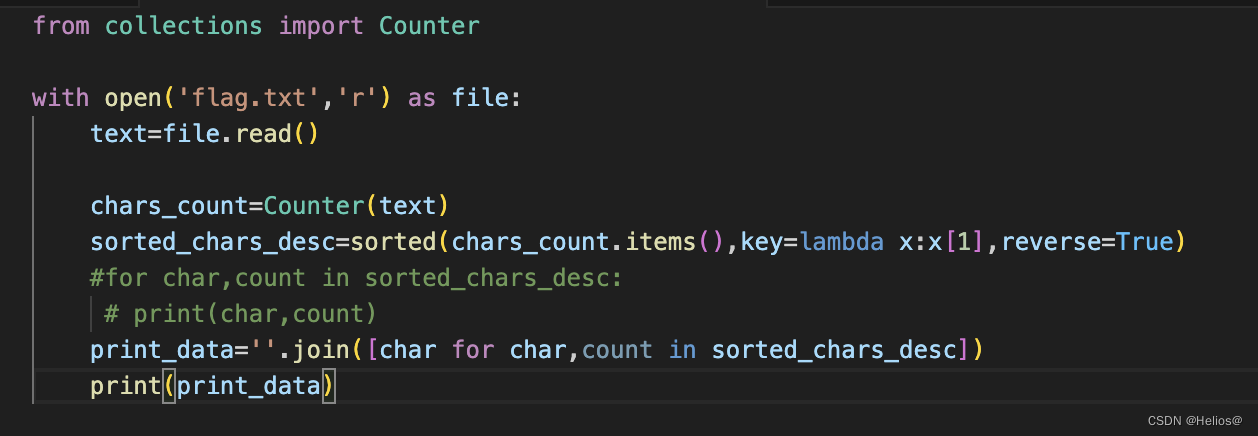
![]()
最后我们来详细分析一下这段代码
# 导入 Counter 类,用于统计字符频率
from collections import Counter# 打开文件 'flag.txt' 以读取模式
with open('flag.txt', 'r') as file:# 读取文件内容text = file.read()# 使用 Counter 统计字符频率chars_count = Counter(text)# 对字符频率进行降序排序,得到一个包含元组的列表sorted_chars_desc = sorted(chars_count.items(), key=lambda x: x[1], reverse=True)# 遍历排序后的字符频率列表,输出字符和对应的次数for char, count in sorted_chars_desc:print(char, count)# 使用列表推导式将字符按照出现次数降序连接成一个字符串print_data = ''.join([char for char, count in sorted_chars_desc])# 输出按照字符出现次数降序排列的字符串print(print_data)
1.collections 模块中的 Counter 类是 Python 中用于计数可哈希对象(例如列表中的元素,字符串中的字符)出现次数的工具
2.chars_count=Count(text)的目的是使用 Counter 类统计字符串text中每个字符的出现次数,并将结果存储在 chars_count 变量中。举例来看,若text = "abracadabra",通过使用 Counter 类的构造函数,将字符串 text 传递给它,创建了一个 Counter 对象 chars_count。这个对象是一个字典,其中每个键是字符串中的一个字符,而对应的值是该字符在字符串中出现的次数。对于字符串 "abracadabra",chars_count 可能的值是 Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})。这表示字符 'a' 出现了5次,字符 'b' 出现了2次,以此类推。
3.chars_count.items() 返回一个包含 Counter 对象中所有键值对的视图。例如,如果 chars_count 是 Counter({'a': 3, 'b': 2, 'c': 1}),那么 chars_count.items() 返回的视图可能是 dict_items([('a', 3), ('b', 2), ('c', 1)])。每个键值对表示一个字符和它在字符串中出现的次数。sorted() 函数用于对可迭代对象进行排序。在这里,我们对 chars_count.items() 返回的键值对进行排序。参数 key=lambda x: x[1] 表示排序的关键是元组的第二个元素,即出现的次数。reverse=True 表示降序排序。
4.使用一个 for 循环遍历了 sorted_chars_desc 列表中的每个元组(每个元组都代表一个字符及其出现次数),然后在每次迭代中打印字符和对应的出现次数。
5.print_data一行,使用列表推导式和 join 方法将排序后的字符按照出现次数降序连接成一个字符串。列表推导式 [char for char, count in sorted_chars_desc] 从每个元组中取出字符,构成一个新的列表。''.join(...) 将这个列表中的字符连接成一个字符串,'' 中的空字符串表示连接时不使用分隔符。