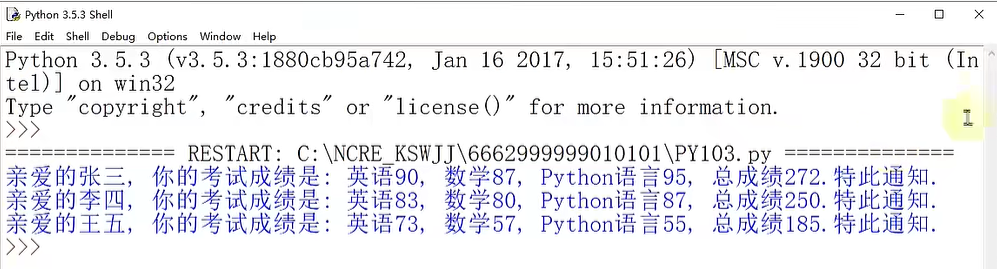
数据中心GPU集群组网技术是指将多个GPU设备连接在一起,形成一个高性能计算的集群系统。通过集群组网技术,可以实现多个GPU设备之间的协同计算,提供更大规模的计算能力,适用于需要大规模并行计算的应用场景。
常用的组网技术:
1.InfiniBand(简称IB):
InfiniBand是一种高性能计算和数据中心互连技术,具有低延迟和高带宽的特点。它支持点对点和多播通信模式,并提供高效的远程直接内存访问(RDMA)功能。InfiniBand通常用于大规模GPU集群的互连。
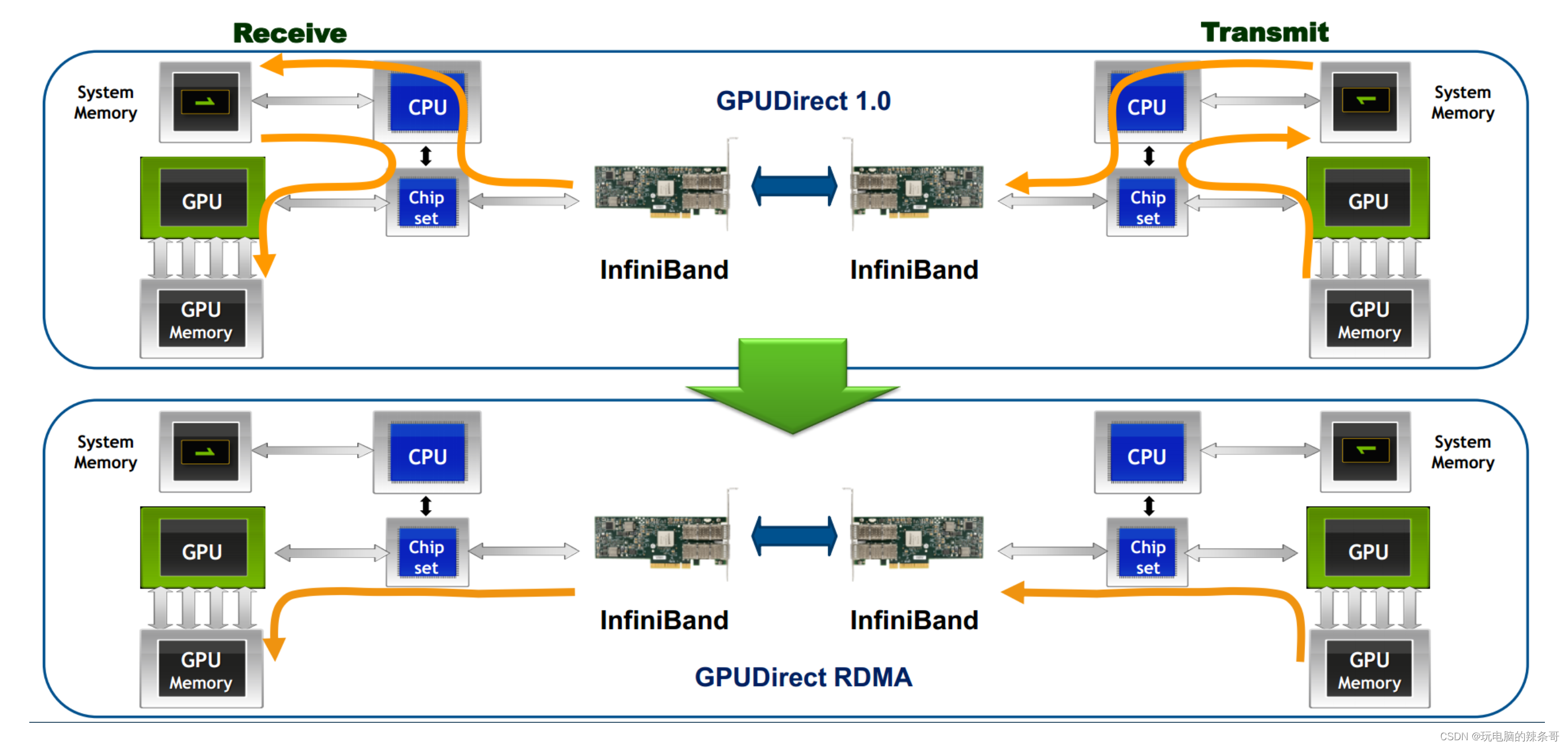
InfiniBand网络的一些特点和功能:
低延迟:InfiniBand网络通过在硬件和协议栈中采用一些优化技术,实现了非常低的传输延迟。这对于需要实时数据传输和低延迟响应的应用非常重要,如高性能计算、金融交易和实时数据分析等。高带宽:InfiniBand网络提供了非常高的数据传输带宽,通常以吉比特或每秒更高的速度进行通信。这使得它适用于大规模数据传输和并行计算任务,能够满足对大吞吐量的需求。RDMA支持:InfiniBand网络通过支持RDMA技术,实现了高效的远程内存访问。RDMA允许数据在主机之间直接传输,而无需通过CPU的干预。这种直接内存访问方式可以提供更低的处理延迟和更高的数据吞吐量。点对点和多播通信:InfiniBand网络支持点对点和多播通信模式。点对点通信意味着两个节点之间可以直接通信,而无需经过交换机或路由器。多播通信可以将数据同时传输到多个节点,适用于广播和集体通信操作。可扩展性:InfiniBand网络可以支持数千个节点的集群规模,并提供可扩展性的设计。它包括交换机、网关、适配器等设备,可以灵活地构建各种规模的网络拓扑。
InfiniBand网络通常用于构建高性能计算集群、大规模存储系统、高频交易平台等需要低延迟和高带宽的应用。它提供了一种高效的数据传输解决方案,并在科学研究、金融、能源等领域发挥重要作用。
目前,Nvidia是唯一一家提供高端IB交换机供HPC和AI GPU集群使用的供应商。例如,OpenAI在Microsoft Azure云中使用了10,000个Nvidia A100 GPU和IB交换网络来训练他们的GPT-3模型。而Meta最近构建了一个包含16K GPU的集群,该集群使用Nvidia A100 GPU服务器和Quantum-2 IB交换机(英伟达GTC 2021大会上发布全新的InfiniBand网络平台,具有25.6Tbps的交换容量和400Gbps端口)。这个集群被用于训练他们的生成式人工智能模型,包括LLaMA。值得注意的是,当连接10,000个以上的GPU时,服务器内部GPU之间的切换是通过服务器内的NVswitches完成的,而IB/以太网网络则负责将服务器连接在一起。

为了应对更大参数量的训练需求,超大规模云服务提供商正在寻求构建具有32K甚至64K GPU的GPU集群。在这种规模上,从经济角度来看,使用以太网网络可能更有意义。这是因为以太网已经在许多硅/系统和光模块供应商中形成了强大的生态系统,并且以开放标准为目标,实现了供应商之间的互操作性
2.Ethernet:
以太网是一种常见的网络技术,也可以用于GPU集群的组网。通过使用高速以太网(如10GbE、40GbE、100GbE),可以提供足够的带宽和低延迟,以满足GPU集群的需求。一些高性能计算网络技术,如RDMA over Converged Ethernet(RoCE)和Data Center Bridging(DCB),可以进一步提高以太网在GPU集群中的性能。
RDMA over Converged Ethernet (RoCE)
RoCE读音类似Ráo kì
是一种基于以太网的远程直接内存访问(RDMA)技术。它允许在以太网上实现高性能、低延迟的数据传输,同时保持以太网的通用性和可扩展性。
RoCE通过在以太网协议栈上引入RDMA功能,实现了RDMA在以太网上的使用。RDMA是一种数据传输方式,它允许数据在内存之间直接传输,而无需通过CPU进行数据拷贝和处理。这种直接内存访问方式可以提供低延迟、高带宽和高效能的数据传输。
RoCE技术的主要特点包括以下几点:
无损以太网:RoCE在以太网上实现了无损传输,即保证数据的可靠性和完整性。它通过使用带有流量控制和拥塞管理机制的数据包传输,确保数据在传输过程中不会丢失或损坏。
网络内部的一个丢包,这个端到端的通信的时延,没有损失,以前的网络,是可能会丢包,然后他这个时延,也有有各种的样的一个损失。0丢包低时延,高吞吐
基于标准以太网:RoCE技术基于标准以太网协议栈,不需要额外的硬件或专用网络设备。这使得RoCE可以在现有以太网基础设施上部署,无需进行大规模的网络改造。低延迟和高带宽:RoCE利用RDMA技术的特性,在以太网上实现了低延迟和高带宽的数据传输。它可以提供与传统InfiniBand类似的性能水平,适用于对延迟和带宽要求较高的应用场景。
RoCE通常用于数据中心和云计算环境中构建高性能计算和存储系统。它可以与现有的以太网设备和协议兼容,并提供低延迟、高带宽的数据传输能力。通过采用RoCE技术,可以在以太网上实现高效能的远程直接内存访问,提高数据传输效率和系统性能。
高端以太网交换机ASIC的主要供应商可以提供高达51.2Tbps的交换容量,配备800Gbps端口,其性能是Quantum-2((英伟达GTC 2021大会上发布全新的InfiniBand网络平台,具有25.6Tbps的交换容量和400Gbps端口))的两倍。这意味着,如果交换机的吞吐量翻倍,构建GPU网络所需的交换机数量可以减少一半。
以太网还能提供无丢包传输服务,通过优先流量控制(PFC)实现。PFC支持8个服务类别,每个类别都可以进行流量控制,其中一些类别可以指定为无丢包类别。在处理和通过交换机时,无丢包流量的优先级高于有丢包流量。在发生网络拥塞时,交换机或网卡可以通过流量控制来管理上游设备,而不是简单地丢弃数据包。
此外,以太网还支持RDMA(远程直接内存访问)通过RoCEv2(RDMA over Converged Ethernet)实现,其中RDMA帧被封装在IP/UDP内。当RoCEv2数据包到达GPU服务器中的网络适配器(NIC)时,NIC可以直接将RDMA数据传输到GPU的内存中,无需CPU介入。同时,可以部署如DCQCN等强大的端到端拥塞控制方案,以降低RDMA的端到端拥塞和丢包。
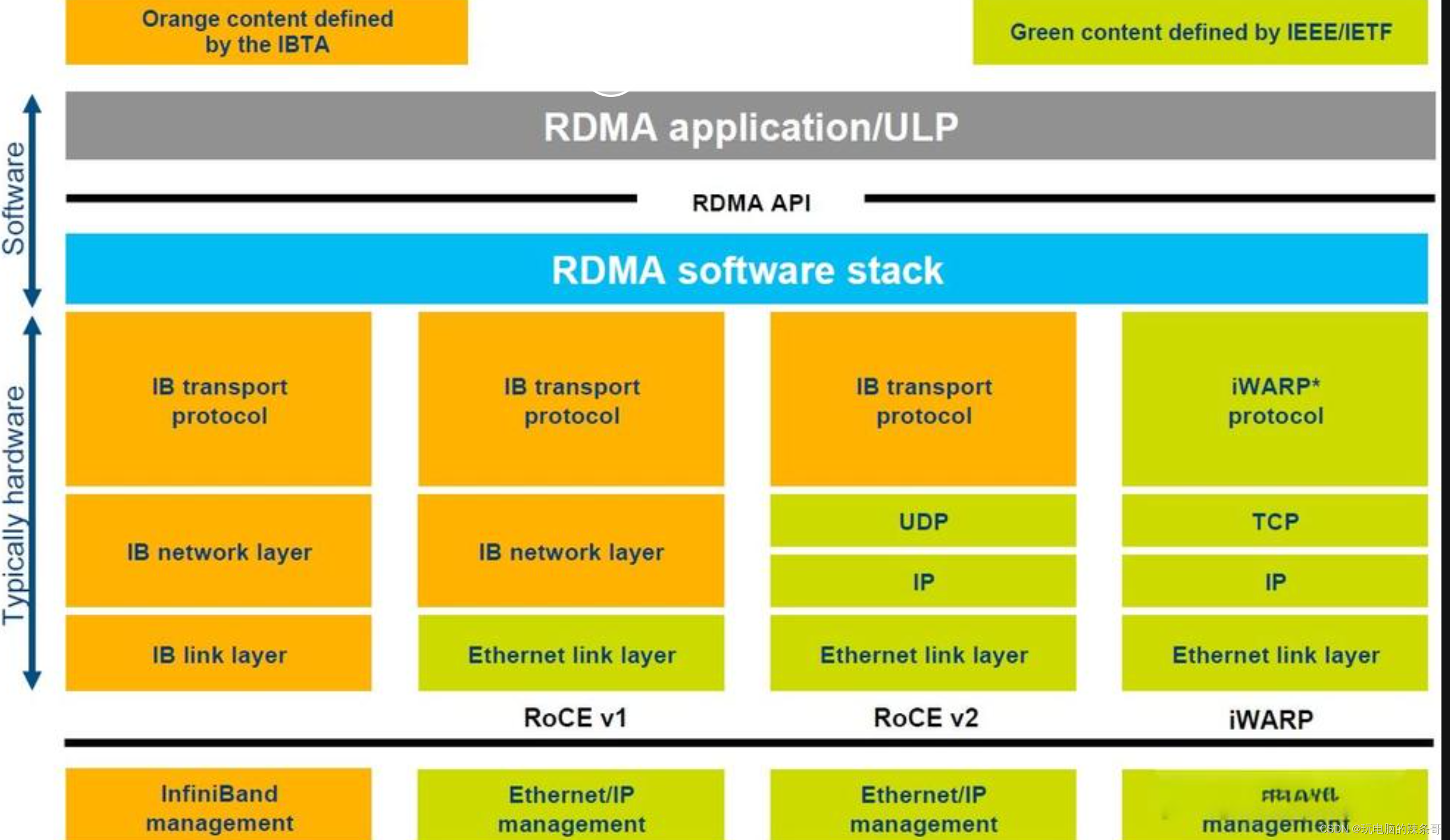
RDMA over Converged Ethernet (RoCE)和RoCEv2都是基于以太网的远程直接内存访问(RDMA)技术,用于在以太网上实现高性能、低延迟的数据传输。它们之间的主要区别在于以下几个方面:协议版本:RoCE和RoCEv2是不同的协议版本。RoCE是早期的协议版本,而RoCEv2是对RoCE协议进行改进和扩展后的新版本。IP支持:RoCE和RoCEv2在IP支持方面有所不同。RoCEv2可以在IP网络中运行,支持使用IPv4或IPv6地址进行通信。而RoCE则需要在以太网之上建立专用的InfiniBand子网,不直接使用IP。网络层:RoCE和RoCEv2在网络层的实现方式上有所区别。RoCE在以太网上直接封装InfiniBand的传输层协议(IBTA RDMA)进行数据传输。而RoCEv2使用UDP/IP封装RDMA数据,从而在IP网络上实现RDMA。扩展性:RoCEv2在扩展性方面有所改进。RoCEv2引入了更灵活的路由和多路径功能,可以支持更大规模的网络拓扑和部署。它还提供了更多的配置选项,如网址控制信息(GID)和服务级别(SL),以支持不同应用需求。需要注意的是,RoCE和RoCEv2虽然有一些区别,但它们的基本原理和目标都是实现在以太网上的高性能、低延迟的RDMA。具体选择使用哪个版本取决于具体应用的需求、网络环境和设备兼容性等因素。iWARP(Internet Wide Area RDMA Protocol)是一种基于以太网的远程直接内存访问(RDMA)协议。它允许在以太网上实现低延迟、高带宽的数据传输,提供了与传统的基于 InfiniBand 的 RDMA 相似的性能和效果。
iWARP 是通过在以太网上的 TCP/IP 协议栈上添加 RDMA 支持来实现的。它在以太网的传输层以上添加了 RDMA 协议,通过在数据传输过程中绕过操作系统内核的数据拷贝和处理,实现了零拷贝和低延迟的数据传输。这使得应用程序可以直接在远程主机的内存中读写数据,从而提供了高效的数据交换。
iWARP 提供了多种功能和特性,包括传输层卸载(TOE),数据完整性保护,流量控制,错误恢复等。它使用标准的以太网硬件和协议,无需专用的高速网络设备,因此更容易部署和使用。
iWARP 技术的优势在于它可以在现有的以太网基础设施上实现高性能和低延迟的数据传输。它被广泛应用于需要大数据量、低延迟、高吞吐量的应用场景,如数据中心、云计算、存储系统、高性能计算等领域。
iWARP和RoCE(RDMA over Converged Ethernet)都是基于以太网的远程直接内存访问(RDMA)协议,但它们在实现和特性上有一些区别:
技术实现:iWARP使用TCP/IP协议栈来实现RDMA,而RoCE使用UDP/IP协议栈。因此,iWARP利用TCP的可靠性和流量控制机制,而RoCE则利用UDP的低延迟和多播特性。软硬件支持:iWARP通常需要特定的网卡和驱动程序来实现,而RoCE可以在标准的以太网硬件上实现,但需要支持RDMA的网络适配器。性能和延迟:iWARP通常在吞吐量和延迟方面具有更好的性能。它使用了更复杂的协议堆栈和流量控制机制,可以提供更稳定和可预测的性能。RoCE则更加注重低延迟,可以实现更快的数据传输速度。部署和兼容性:由于iWARP使用TCP/IP协议栈,它可以与现有的以太网基础设施兼容,并且易于部署。RoCE需要支持RDMA的网络适配器,并且对交换机和路由器的支持有一定的要求。
选择使用iWARP还是RoCE取决于具体的应用需求和环境条件。如果你的应用需要更好的吞吐量和稳定性,或者正在使用现有的以太网基础设施,那么iWARP可能是一个更好的选择。如果你的应用对低延迟有更高的要求,并且有适当的硬件支持,那么RoCE可能更适合你的需求。
Data Center Bridging(DCB)
是一组标准和技术,旨在提供在数据中心网络中传输数据时的高可靠性、低延迟和带宽保证。
DCB 主要解决了在传统以太网网络中面临的一些挑战,包括数据传输的可靠性、带宽利用率和延迟控制等问题。DCB 引入了以下关键技术和标准:
Priority-based Flow Control(PFC):PFC 用于解决数据包丢失和拥塞的问题。它基于 IEEE 802.1Qbb 标准,允许交换机根据流的优先级进行流量控制,确保高优先级的流量不会被低优先级的流量阻塞。Enhanced Transmission Selection(ETS):ETS 用于提供带宽保证。它基于 IEEE 802.1Qaz 标准,允许网络管理员将可用带宽分配给不同的流量类别,并根据优先级和带宽需求进行流量管理。Data Center Bridging Exchange(DCBX):DCBX 是一种交换机和终端设备之间的协议,用于在连接建立时交换关于 DCB 支持和配置的信息。DCBX 可以确保网络中的所有设备都能够遵守相同的 DCB 配置,从而实现更好的互操作性和一致性。
DCB 技术通常用于数据中心网络中的存储交换机、以太网交换机、服务器和存储设备之间的连接。它可以为关键应用程序提供低延迟、高可靠性和带宽保证的网络环境,从而提高数据中心的性能和可靠性。
3.NVLink:
NVLink是NVIDIA开发的一种高速互连技术,专门用于连接多个GPU设备。它提供高带宽、低延迟的点对点连接,并支持共享内存和直接内存访问。NVLink通常用于构建NVIDIA GPU的集群系统,以实现更高的GPU计算性能和数据传输效率。
NVLink 交换系统
用于连接 GPU 服务器中的 8 个 GPU 的 NVLink 交换机也可以用于构建连接 GPU 服务器之间的交换网络。Nvidia 在 2022 年的 Hot Chips 大会上展示了使用 NVswitch 架构连接 32 个节点(或 256 个 GPU)的拓扑结构。由于 NVLink 是专门设计为连接 GPU 的高速点对点链路,所以它具有比传统网络更高的性能和更低的开销。
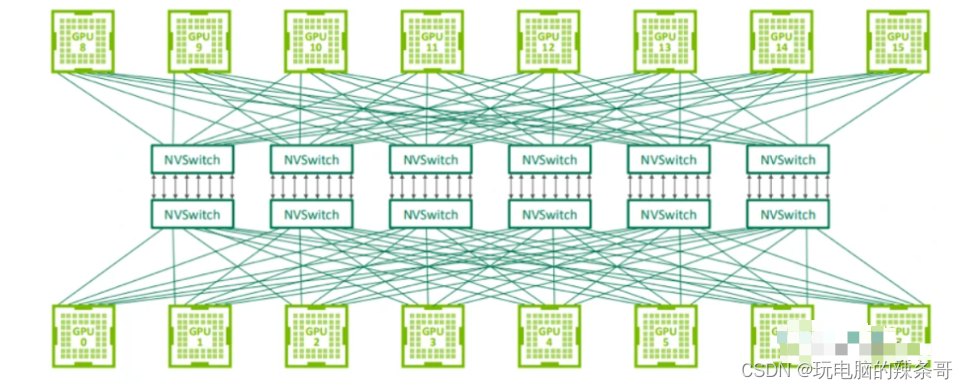
第三代 NVswitch 配备 64 个 NVLink 端口,提供高达 12.8Tbps 的交换容量,同时支持多播和网络内聚合功能。网络内聚合能够在 NVswitches 内部汇集所有工作 GPU 生成的梯度,并将更新后的梯度反馈给 GPU,以便进行下一次迭代。这一特点有助于减少训练迭代过程中 GPU 之间的数据传输量。
据 Nvidia 介绍,在训练 GPT-3 模型时,NVswitch 架构的速度是 InfiniBand 交换网络的 2 倍,展现出了令人瞩目的性能。然而,值得注意的是,这款交换机的带宽相较于高端交换机供应商提供的 51.2Tbps 交换机来说,要少 4 倍。
若尝试使用 NVswitches 构建包含超过 1000 个 GPU 的大规模系统,不仅成本上不可行,还可能受到协议本身的限制,从而无法支持更大规模的系统。此外,Nvidia 不单独销售 NVswitches,这意味着如果数据中心希望通过混合搭配不同供应商的 GPU 来扩展现有集群,他们将无法使用 NVswitches,因为其他供应商的 GPU 不支持这些接口。
4.PCIe:
PCI Express(PCIe)是一种常见的计算机总线技术,也可以用于GPU集群的组网。通过将多个GPU设备插入到主机上的不同PCIe插槽中,可以将它们连接在一起,并通过软件和驱动程序进行协同计算。然而,相比于其他高性能互连技术,PCIe的带宽和延迟较高,适合中小规模的GPU集群。
GPU集群组网技术的选择取决于具体的应用需求、预算和可用资源。不同的技术对网络拓扑、设备支持和软件兼容性等方面有不同的要求,因此在选择和部署GPU集群组网技术时,需要综合考虑各种因素,并结合具体需求做出决策。
5.DDC全调度网络
DDC(Distributed Data Center)全调度网络是一种用于数据中心互连的网络架构。它是基于全调度算法的网络设计,旨在提供高性能、低延迟的数据传输和资源调度能力。
在传统的数据中心网络架构中,通常采用分层结构,例如经典的三层结构(核心层、汇聚层和接入层)。这种分层结构可能导致数据传输的延迟较高和资源利用率较低的问题。
DDC全调度网络通过将网络交换机配置为全调度模式,即所有交换机都能直接通信,消除了分层结构带来的瓶颈和延迟。它采用集中式的全局调度算法,根据数据中心内的实时负载情况和通信需求,动态地分配网络资源和优化数据流。
DDC全调度网络的关键特点包括:
低延迟:由于所有交换机都能直接通信,DDC全调度网络可以减少数据传输的跳数和排队延迟,从而实现低延迟的数据传输。高带宽:DDC全调度网络提供高带宽的数据传输能力,可以满足大规模数据中心的高吞吐量需求。灵活性:DDC全调度网络具有灵活的资源调度能力,可以根据实际需求动态分配网络带宽和处理能力,实现资源的最优利用。可扩展性:DDC全调度网络设计为可扩展的结构,支持逐步扩展和添加更多的交换机和节点,以适应不断增长的数据中心规模。
DDC全调度网络是一种新型的数据中心网络架构,它通过全调度算法和直接通信的方式提供了高性能、低延迟的数据传输和资源调度能力。这种网络架构被广泛应用于大规模数据中心、云计算和超级计算等领域,以提升系统性能和应用效率。
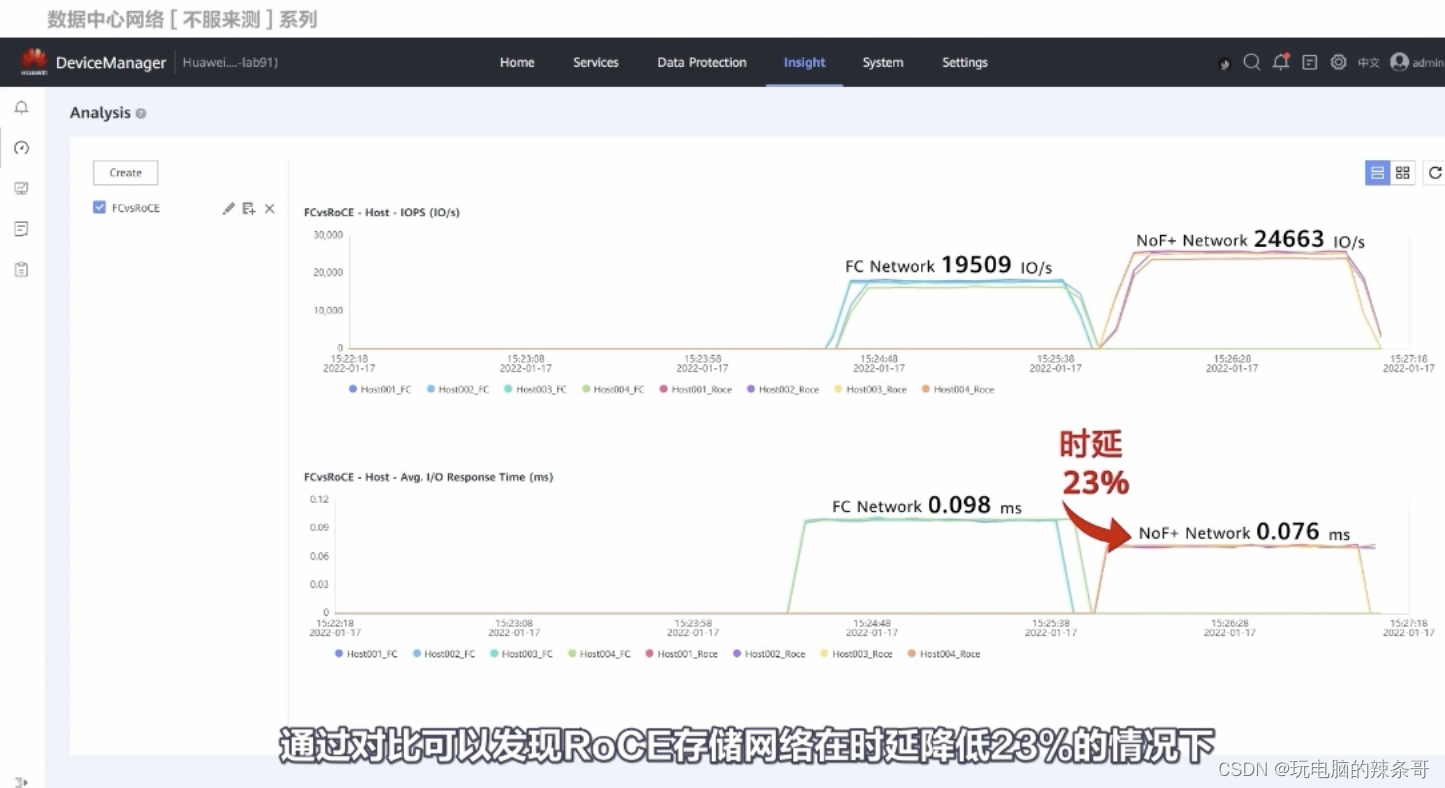
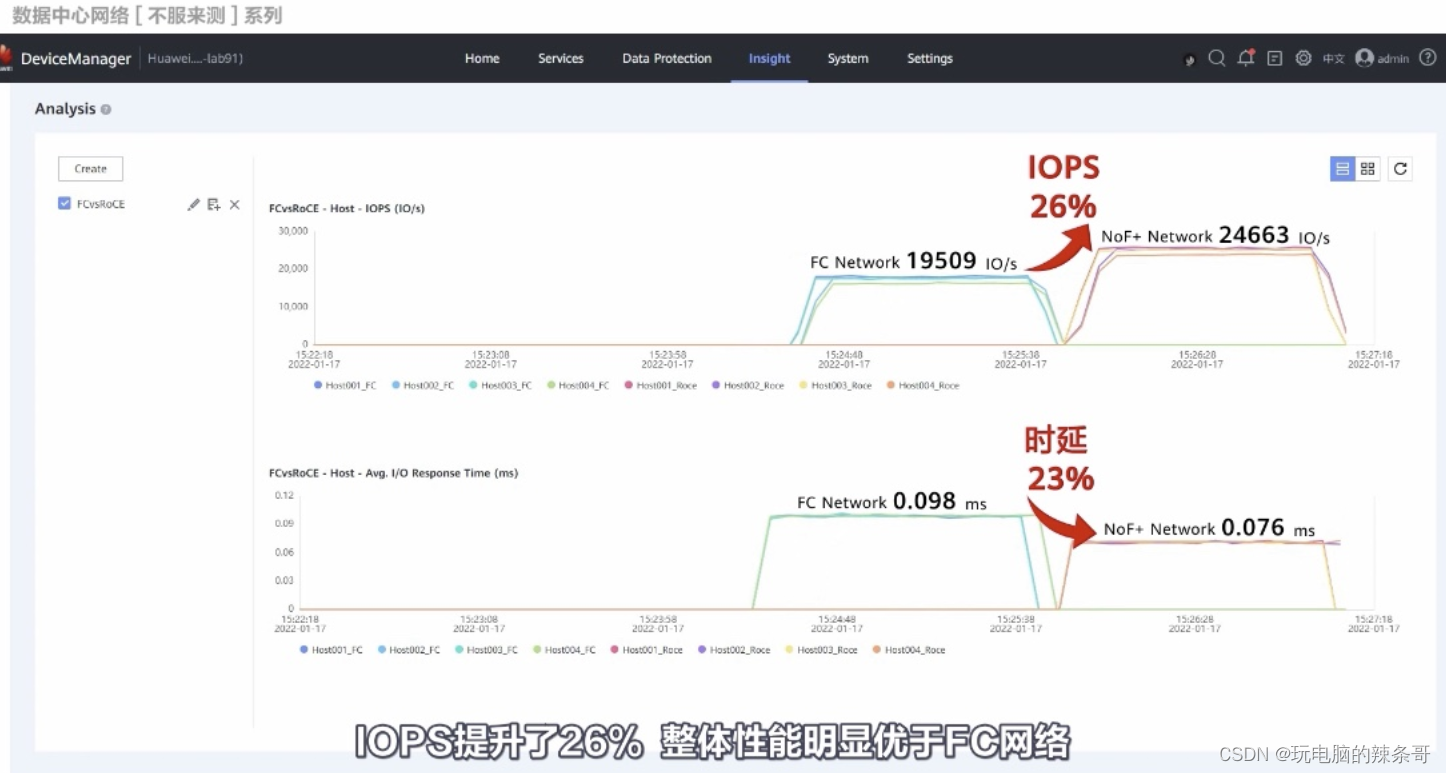
RoCE 和 FC测试对比
测试来自华为