导读
AIGC的飞速发展离不开生成模型、深度学习以及多模态学习等领域研究的不断累积,其中生成模型的原理与算法发展是不可或缺的一部分,如:生成对抗网络 GAN 及其一系列变体、变分自编码器 VAE 及其一系列变体、自回归模型 AR、流模型 FLOW ,以及近年大火的扩散模型(Diffusion Model)等。扩散模型的早期思路可以追溯到2015年前后。2020年,经典的 Denoising Diffusion Probabilistic Models(DDPM)横空出世,后续迎来了很多基于扩散模型的变体,如DALLE-2(OpenAI)、Imagen(Google)和当前完全开源的Stable Diffusion。
此次,智源社区邀请到2023智源大会生成模型论坛的论坛主席李崇轩,介绍了他对于扩散模型以及生成式AI未来发展的展望。现阶段他的工作重点集中在如何在算法和理论层面做出更好的扩散模型,以及如何用好扩散模型。而他的长远理想,是通过生成模型,去模拟一个小小的「现实世界」。

李崇轩
李崇轩,中国人民大学高瓴人工智能学院准聘助理教授,博士生导师。研究方向为深度概率机器学习。他的代表性工作有:一致性理论下最优的半监督GAN 方法 Triple-GAN;扩散概率模型在最大似然意义下的最优反向方差估计Analytic-DPM。李崇轩获机器学习领域重要国际会议 ICLR 2022年杰出论文奖,2021年吴文俊人工智能自然科学奖一等奖,2019年中国计算机学会优秀博士论文。李崇轩入选2022年北京市科技新星计划,2019年中国博士后创新人才支持计划,主持国家自然科学基金面上项目。个人主页:https://zhenxuan00.github.io/
▲ 李崇轩是本次智源大会生成模型论坛的主席,生成模型论坛将邀请到斯坦福大学计算机系副教授Stefano Ermon、斯坦福大学助理教授吴佳俊、UCLA助理教授周博磊、浙江大学教授赵洲等做报告分享,敬请期待。扫描下方二维码,免费报名2023智源大会。

访谈&整理:李梦佳
生成式AI,前景与展望
Q1:在您看来,过去一年里,生成式AI最重要的进展有哪些?
GPT 系列为代表的自回归大语言模型,以及 ChatGPT 等对话系统等下游应用是最重要的进展;其次,以扩散模型为代表的文到图的生成,特别是开源模型Stable Diffusion的出现及其在图像可控编辑、三维场景生成的应用,也是重要的突破性进展。
一方面,这些模型对包括NLP、CV在内的学术界有很大冲击,大模型能够把我们之前为了推动学术发展抽象出来的特定任务做得很好,那么我们接下来该怎么走?回答好这个问题会给这些领域带来新的机遇。
除了互联网等计算机相关产业,这些模型也对传统行业有关键的影响。语言模型和文到图生成这两方面的进展都有广阔的落地前景。语言模型不必多说,各行各业都离不开文档总结、翻译之类的文字工作。文到图生成对于设计、建筑或是艺术等一系列相关产业也有相当大的影响。比如三维效果图的自动生成,在设计、建筑等行业里有很大的应用前景。
总结来说,GPT 系列和 diffusion 等跨模态的视觉生成对于学术界和人们的生活都有非常重大的影响。
Q2:diffusion model 出现之后,AIGC 产业才迎来了井喷式的发展。扩散模型相对于GAN以及VAE,主要优势在于?
我认为,扩散模型虽然很重要,但不是 AIGC井喷式发展的唯一决定性因素。其他主要因素还有算力的发展,大规模数据的采集,网络结构的发展,以及OpenAI发布的 CLIP、DALL E、 GPT系列突出的效果。一个生成式的AI,再配上 transformer 的结构,有足够的能量去容纳、“吃”很大体量的数据,有非常好的表现。整体上,这条路被领域内所广泛认可,所以才会有井喷式的这种发展。
扩散模型相比于GAN和VAE,有很大的优势。首先,训练方面比起GAN要稳定很多。效果方面,扩散模型通过迭代生成的图像、视频的质量与GAN和VAE相比有比较大的优势。所以在AIGC这条路上,大家会把扩散模型作为文到图或相关视觉应用算法上的首选。
Q3:DPM和DDPM这两篇论文的关系是?
DPM 通过特殊设计的变分推断过程,原理上把比较难的一步生成任务拆分成了多个彼此差不多的简单任务,这是DPM的共性。DDPM也延续了这个思路,但在子任务形式上做了变换,子任务是去噪,而不是DPM中的均值预测。这个变换有助于稳定神经网络的优化,又借鉴了一些其他的生成模型在网络结构设计的进展。因此,DDPM真正做到比其他所有方法都work,吸引了大量关注。

如果选一篇开创性文章的话,是DPM,还是DDPM?
我个人认为:不分先后地说,应该有三个工作都很重要。第一个工作就是DPM,第一作者是Jascha Sohl-Dickstein。第二个工作是DDPM,第一作者是Jonathan Ho。第三位是宋飏,他是DDPM所借鉴网络架构的生成模型的提出者,以及DDPM连续化版本SDE的提出者,同时也是ICLR 2021的杰出论文奖,他们三位对领域都做出了非常重要的贡献。
Q4:扩散模型现在存在哪些局限性?如果去挖掘子方向,有哪些问题仍然亟待解决?
首先是采样速度和训练速度比较慢,需要的计算资源大,我们之前做过一些加速采样的方法,可能之后也会继续做。
直觉上,之所以扩散模型比GAN和VAE好,就在于它把从噪声到图像的这种映射转换成很多分阶段的不同层次的去噪任务。这就天然地决定了,扩散模型结果好的同时生成速度慢。现在还没有定论,扩散模型是否能做到在较少的步数下,比GAN和VAE好,甚至和很多步的结果是一样的,我觉得这是扩散模型最主要的问题之一。
第二个问题,就不仅仅是扩散模型自己的问题了,而是生成式模型或生成式 AI 的一些通病。
首先,评测,即如何快速判断一个生成式AI的结果好不好,是否符合预期。这是一个非常大的公开问题,有很多阶段性的进展去做各种各样的评测,比如说用高考题或一些比较难的试题去评测GPT,都会有很大的积极意义。
第二,生成模型的可控性,即生成的内容能否去和用户对齐,是否会生成有害言论或图片,好不好用等。这在 diffusion 里面有一些进展,比如最近的ControlNet,但仍有很多不足。可控性和很多问题相关,比如有益的AI,无偏的AI等社会学问题,以及鲁棒性相关的问题;再比如如何对生成图像进行局部修改,产生可控的交互形式,这是长期来看,整个生成模型领域,不只是扩散模型要解决的问题。
Q5:LAION创始人表示,相比于图像中涉及的偏见问题,他更关心让数据“获得自由”,如何看待训练数据集涉及的安全及伦理问题?
在不同阶段大家关心的问题不一样。在LAION创始人看来,还没有到安全大过发展的时候。他觉得,应该让很多做研究的人能够去接触到高质量的数据,去推进这个领域的发展,探究从数据中能获得什么,这是有益的发展。另一方面,肯定会涉及版权或者偏见,如果数据收集的不好,甚至包含有危害的数据,可能训出来的模型也会有害。看个人权衡,在他看来,推动发展是最重要的。
我个人认为,不应该忽略安全的问题,但是也不应该因为安全的问题去阻断数据的自由。所以如何在中间取得权衡很重要,我认为,既然是公开数据,可以让数据的来源方去选择去掉自己的数据,其他的人也可以选择给LAION贡献数据,尽可能地减少版权上的争议。
涉及安全和偏见问题,需要相关维护数据集的团队去进行数据清洗,这方面也有很多机器学习方面的一些进展,涉及纠偏或对抗式的鲁棒性安全学习等技术。
专攻深度生成模型基础理论与算法,坚持源于兴趣
Q6:从求学和科研经历的角度,为什么当时选择扩散模型这个方向,它为什么重要?
我本科是在清华大学交叉信息研究院,保研直博到了清华计算机系,之后在张钹和朱军教授组里做博士生,中间去荷兰阿姆斯大学Max Welling组交换了一年。19 年又在组里做了两年的博士后,21 年加入了人大高瓴。
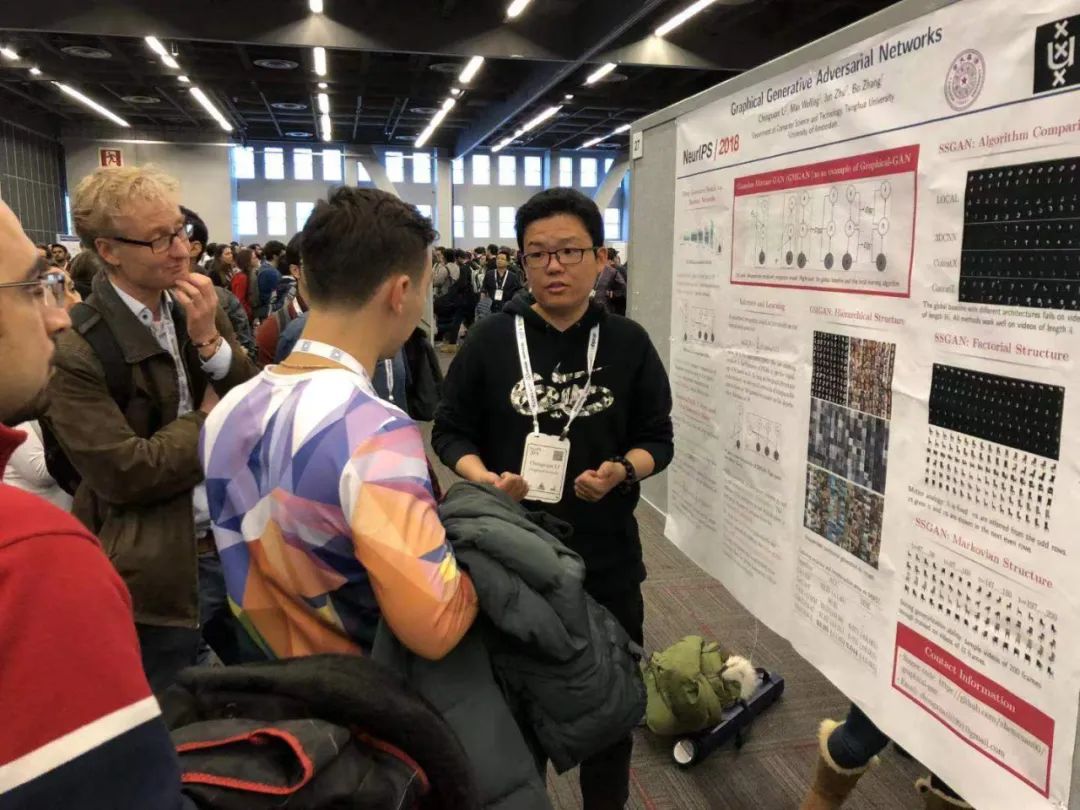 李崇轩在NeurIPS 2018现场(左二,Max Welling)
李崇轩在NeurIPS 2018现场(左二,Max Welling)
选择深度生成模型这个方向, 是因为14年(我大四)ICML在北京召开,朱老师邀请Diederik P Kingma,他是Max Welling的一个学生(VAE的第一作者)到组里做报告。他讲到VAE,当时的模型可以生成手写数字,我觉得很有意思。朱老师当时主要做贝叶斯,和生成模型的联系很紧密,同时深度生成模型又和deep learning相结合,他觉得这是一个很好的方向。
我从14年开始做深度生成模型,随着领域的发展做VAE、GAN等等。19年我开始对能量函数模型,特别是隐变量能量函数模型感兴趣。然后做了一段时间发现有一种学习算法叫做评分匹配很适合学习能量函数模型。这个方法当时宋飏(此前朱老师本科生)他们做得很好,我们经常会有一些交流。
21年初,扩散模型开始和能量函数里面的评分匹配建立联系,这是DDPM的一个贡献。建立起联系后宋飏就转到了扩散概率模型,SDE的那篇paper拿了ICLR杰出论文奖,他回组里做了相关的报告。
在和宋飏交流过程中,我认识到这确实是一个非常好的方向。有几个学生也对这个领域非常感兴趣,当时认识到它的采样速度确实是一个最大的瓶颈,这里面有机会可以做出好的工作。于是通过前期在能量函数模型和VAE等方面的积累,我们选择了扩散概率模型这个方向。
重要性方面,宋飏的工作在当时已经展现了非常好的潜力,在两个重要指标,生成效果和概率密度估计的准确度上,取得了很好的结果,比所有的GAN、VAE等自回归模型在图像生成上都好很多,同时还有能力去做非常高维的 1024* 1024 的彩图。正好当时它又存在采样速度的局限,我觉得我们可以找准这个方向去解决。
Q7:朱军老师所在的领域贝叶斯与生成模型是如何结合的?
二者联系非常紧密。扩散模型完全可以理解为对一个层次化隐变量模型的变分推断和近似最大似然估计,这些基础的思想和技术都是从传统的贝叶斯、概率图模型流传下来。
在深度生成模型中,去建模随机变量之间关系的时候,引入了深度神经网络,给学习和推断造成了新的困难和挑战。所以说要基于神经网络再去做一些近似推断的改进,但是基本原理都是相通的。
Q8:您最新的研究阶段性成果有哪些?
我最近的工作主要集中在扩散模型。
首先是怎样做更好的扩散模型,比如22年的ICLR杰出论文,在加速采样算法理论上有所创新,采样的方差最优解可以去做加速,后面还有一些更快的加速方法DPM-Solver(NeurIPS 2022 Oral)基于Stable Diffusion生成512*512的大图,只需要15步左右,目前部署于非常多的开源扩散大模型。
另外一方面,我们也训练了一个跨模态的扩散大模型UniDiffuser,这也是和朱军老师合作的工作。主要的点在于我可以做一个文图通用的diffusion model,不需要额外的训练时间和推断时间,只是需要一点点额外的参数,就可以处理很多文到图、图到文的跨模态任务。此外,我们也提出了基于transformer的扩散模型新架构,使用结果非常好。这些工作分别被 CPVR 2023和ICML2023接收。
 UniDiffuser效果图(论文地址:https://arxiv.org/pdf/2303.06555.pdf)
UniDiffuser效果图(论文地址:https://arxiv.org/pdf/2303.06555.pdf)
另一方面,怎样更好地去用扩散模型,特别是可控生成。包括一些基于能量函数的指引方法,在图到图的翻译,小分子药物合成上都有些好的效果。以及一些文到视频、文到3D场景的生成都会涉猎。这些工作发表于 NeurIPS 2022和ICLR 2023等。
总结起来,我目前阶段的工作重点在于如何做更好的扩散概率模型,以及怎么更好地去用扩散概率模型。
Q9:未来会持续深耕哪些方向?如何做更好的diffusion model 和怎么用?
短期规划,基本上围绕着生成模型去继续探索,包括泛化理论,训练算法,视觉的应用或其他的包括科学问题上面的应用都会做。长远规划,我的个人理想,是可以通过学习一个非常好的生成模型,去模拟一个小小的现实世界。大概可以想象,你定义好,有多少人或者物体,有什么样的场景,用文本输入,同时给一些随机性,让他们在其中交互,在宏观上、视觉上去模拟一个这样的小世界。最好可以用自己提的理论和算法,自己训练的模型来完成这件事情。
类似 Minecraft?
有一点区别是我希望得到的场景是非常逼真的,视觉上你感觉不到和外部世界上有什么区别。它就像真的人拍摄的视频一样。

Q10:加速采样算法的话,是为了让生成得更快?这些算法已经用在一些模型当中了?
相当于在保证生成质量不变的情况下,能够用更快的时间去做这种图像的生成,这个时间实际上是用户等待的时间。
DALLE-2使用了我们ICLR的一个工作,其论文中曾明确提出diffusion prior里面用到我们的核心采样技术。我们后续更快的方法DPM-Solver用在了Stable Diffusion 的官方、HuggingFace Diffuser的官方,以及Stable Diffusion WebUI 的官方。(印象中)可能是 Stable Diffusion 的官方,曾采用我们的加速方法,从8秒出图,到现在 3 秒多不到 4 秒出图。
Stable Diffusion 官方直接用到了贵组的算法?
据我所知是的。
加速方法上,有两种技术路线。一种是从数学角度在采样中做一些调整(我们之前的主要工作)来实现加速计算,过程中不涉及再训练其他的模型。另一套思路是,用蒸馏的方法去额外训练一个更快的模型,相当于这个采样更快的模型,它的学习目标就是为了很少的几步去拟合原来扩散模型很多步的结果。在大模型里训练这个知识蒸馏过程可能会有一些代价,并且大模型本身目前也迭代的比较快。所以开源的项目当中基本使用我们的方法。
Q11:您博士期间曾经获得过 CCF 优博。还曾荣获 ICLR 杰出论文奖,吴文俊人工智能自然科学奖一等奖,吴文俊人工智能优秀青年奖。您认为想要做出优秀的科研成果,需要哪些要素?
我很幸运能够加入到张老师、朱老师的团队,也遇到了很多学生,这是整个团队的成果,很荣幸做了一些贡献。我个人没有特别去想过,一定要做到特别优秀或一定要拿奖。我更多的是做一些自己比较感兴趣,比较重要的工作。
我最开始选择生成模型也是源于最初的兴趣,当时Kingma给我们展示了,如何控制手写字体的形态。比如我写了一个 9 字,模型可以自动提取我写字的特征,去写012345678,写出来和我自己写的感觉完全一样。这个效果,激发了我强烈的兴趣。14年左右,我明确了生成模型是我想要去做的方向。
后来我一直坚持在做生成模型,主要做基础算法,和一些少量的视觉应用。在 diffusion model 方面,我们组确实接触这个方向的前沿比较早,没想到该领域受到大量的关注,因此我也收获了很多认可,这是很幸运的。
所以我个人觉得总结来看,感兴趣,能够坚持下来,这是最重要的。去选择一个非常喜欢、感兴趣的方向,去长期坚持,再加上好的老师指导,好的学生或合作者,产出扎实的工作。当然最后,眼光和运气也至关重要,可能刚好你做的东西大家还比较关注,就会有一些意外之喜。
初入领域的时候没有想到现在AIGC会爆火?
记得在15年清华组织的一次研讨会上,展示关于手写数字的早期demo,一个产业界的人问我,这东西有什么用?我当时随便拍脑袋说,如果生成地好,未来有很多方向。比如现在大家用淘宝,可能你把自己的人体参数传进去,你可以直接生成穿上衣服的样子,这样在家点点鼠标就可以试穿成千上万件的衣服,选你最喜欢的。
这是多年以前的设想,而今早已实现。平面模特的工作也受到了一些挑战。进展很快,超出了我的预期。
AIGC大爆发,计算资源对于所有单位相对不足
Q12:AIGC(生成式AI)还有哪些潜在的落地场景?
生成式AI的场景十分广泛。比如图像方面,游戏中的3D建模,电影、动漫产业,经典小说配图,等等,不一而足。设计行业,包括平面设计、广告设计,电商等等,以及城市规划、建筑业,但凡涉及到视觉元素的领域都是可以落地的场景。AIGC也包含文字生成和多模态生成,但凡涉及到文字材料加工、润色,都很有前景。
Q13:企业和高校在AIGC研发和应用方面会有哪些?优势和劣势。
企业和高校之间的比较是一个长久的话题。AI或者说,计算机整体都和产业界联系非常紧密,各种各样的人在企业和高校之间流动,这个很正常。企业的优势是很明显的,特别在大模型这个背景下,它在算力上、数据上,工程能力上都有很大的优势。
劣势的话,分为大企业还是初创公司,初创公司资金压力会大一些。大企业,内部的协调,包括跟整个公司过去的业务线是不是有冲突,存在考量。
高校方面,我个人觉得就是最大的优势还是相对比较自由的探索。有很多高度不确定的工作,企业很难去做,可能还是要高校去做。劣势上,除了很少数的组之外,其他的组都会面临着计算资源不足。比如说训大模型,很多高校里的组是做不了,不过在使用大模型,或者一些早期的模型算法探索上可以去尝试。
Q14:计算资源是决定性的吗?对于一些学生来讲,如果计算资源不够,应该去做哪些尝试?
看方向。哪怕是做小的应用,有充足的计算资源也不会有坏处。计算资源肯定是越多越好,可以平行快速地迭代很多想法。
即使是企业也存在计算资源不足的情况。在训练大模型上,哪怕是OpenAI,也会希望有更多的卡,这是毫无疑问的。所以说计算资源在所有人面前都是相对不足的。
在给定你现有的计算资源的情况下,可能就得有所取舍了。比如我可能没有那么多卡,就不能去训练生成模型,可能只能去用它或者做一些推断方向的工作。或者做小样本、小规模数据上的适配和迁移等,就不需要太多的卡。
在企业中也需要去权衡,在何处发力。是选择并行训练很多小的任务,积累经验,还是all in所有的卡去训练一个大的模型。计算资源的问题是普遍存在的,只能靠经验去克服。
除了方法或结果,年轻研究者可以多关心实现的细节。很多现在机器学习的会议,都要求把计算资源明确地列在论文里,这种情况下可以关注这个方向上的文章普遍需要多少资源,再决定是不是投入。
Q15:AIGC催生了很多新的工种,如何培养生成式AI相关人才?需要具备哪些素养?
生成式AI的人才培养,和一般的AI人才培养绝大部分是相通的。首先,专业技能培养,基本的编程和数学,包括代数、微积分、概率统计等等。其次包括人工智能相关的核心技术,人工智能基础、机器学习、深度学习,乃至对应领域的基础知识。技能培养是基础。
第二,最主要的要去积极地拥抱变化。
AI的高速发展,半年不关注可能就会落伍。我觉得,最主要的是要有比较好的心态,快速学习的能力,能够很快地去了解或者深入掌握前沿的东西。
Q16:在今年的生成模型论坛上,想探讨哪些核心话题?
今年的生成模型论坛有邀请到斯坦福大学计算机系副教授Stefano Ermon,他将介绍生成模型基础理论与方法的进展;斯坦福大学助理教授吴佳俊,他在3D视觉生成上有非常多优秀的工作;UCLA助理教授周博磊,将会介绍可控生成方面的最新进展;国内青年学者代表浙江大学教授赵洲(他是多模态生成、语音合成方面的青年专家)等,将带来相关方向的精彩报告。论坛将聚焦大家最关心的进展,如何看待生成式AI未来的发展,包括数据的偏性和安全性在内亟待解决的问题。
Q17:对今年智源大会的寄语?
希望智源大会能够圆满成功。以本次大会为契机,国内外专家共同展望生成式AI的未来。碰撞学术的火花,希望各界的老师、朋友们能够有所收获,共同进步。
推荐阅读
MIT教授Tegmark:GPT-4敲响警钟,百年后人类何去何从丨智源大会嘉宾风采
40岁高中老师开源的数据集LAION,改变了生成式AI的未来丨智源大会嘉宾风采