上一遍内容
接下来我们都使用navicat软件来操作数据了。
1.新建数据库
先创建我门自己的一个数据库

鼠标右键点击bendi那个绿色海豚的图标,然后选择新建数据库。

数据库名按自己喜好的填,不要写中文,
在 MySQL 8.0 中,最优的字符集和排序规则是 UTF-8 和 utf8mb4_unicode_ci。这种字符集和排序规则可以支持大多数语言,并且能够保证在排序和比较时的正确性。
不同的数据库版本是不一样的
在这里我先讲几个常用的排序规则
- utf8mb4_0900_ai_ci 不区分大小写
- utf8mb4_unicode_ci 不能完全支持组合的记号。
- utf8mb4_general_ci 校对规则仅部分支持Unicode校对规则算法,一些字符还是不能支持;
| 排序规则 | 说明 |
|---|---|
| utf8_bin | 字符串每个字符用二进制数据编译存储。区分大小写,可以存储二进制内容。 |
| utf8_general_ci | 校对速度快,但准确度稍差。 |
| utf8_unicode_ci | 精准度高,但校对速度稍慢。 |
utf8mb4_unicode_ci比较准确,utf8mb4_general_ci速度比较快。通常情况下,新建数据库时一般选用 utf8mb4_general_ci 就足够了!
常用的命名规则:_ci结尾表示大小写不敏感(case insensitive),_cs表示大小写敏感(case sensitive),_bin表示二进制的比较(大小写敏感)。

创建完以后就出出现这个数据库,里面是没有表的,等着我们去创建。
2.用命令创建数据库
刚刚我们用界面操作创建数据库,现在我们要用命令了,
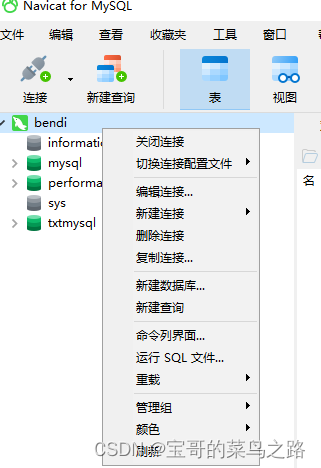
右键点小海豚,命令列界面。

在新建之前,我们先输入之前学习的show databases;的命令

跟左边显示的一模一样,没有问题。
创建数据库我这里有两个方法
第一种:create database 数据库名;
第二种:create database if not exists 数据库名 default character set 字符集;
第三种:CREATE DATABASE 数据库名 DEFAULT CHARACTER SET 字符集 DEFAULT COLLATE 排序规则;
在这里讲一下字符集的意思:
| 字符集 | 说明 |
|---|---|
| utf8 | 表示一个字符需要使用1~4个字节。字符集表示一个字符所用的最大字节长度,在某些方面会影响系统的存储和性能。 |
| utf8mb3 | 阉割过的utf8字符集,只使用1~3个字节表示字符。 |
| utf8mb4 | 正宗的utf字符集,使用1~4个字节表示字符。 |
在utf8mb4下,英文占1个字符,中文3个,特殊符号4个。
为了数据库有更好的兼容性,用mb4,但是会浪费点空间。
采用第一种方法:
采用第二种方法:

如果左边数据库没有显示出来,右键点击小海豚,刷新一下就出来了。
3.删除数据库语句
可以鼠标右键点击删除
命令1:DROP DATABASE txt1;
命令2:DROP DATABASE IF NOT EXISTS txt1;
IF NOT EXISTS为可选项,它的作用是判断即将新建的数据库名是否存在,若不存在则直接创建该数据库,若以存在同名的数据库则不创建任何数据库。如果在新建数据库时没有指定IF NOT EXISTS,那么新建的数据库与连接中的数据库重名将会出现错误提示。同样删除数据库的时候也是一样。

txt1就是你要删除的数据库名字,更换成你想删除的数据库名即可。
4.修改数据库
让我们来修改数据库的字符集和排序规则,先让我们看看它原本是什么的
字符集是utf8mb4,排序是utf8mb4_0900_ai_ci,让我们来修改成字符集为gbk,排序规则为gbk_chinese_ci。
命令:ALTER DATABASE txt1 CHARACTER SET gbk COLLATE gbk_chinese_ci;

我们可以看到它的字符集和排序规则都已经发生了改变,如果出现OK没变化的,记得刷新一下数据库。

![[机器视觉]halcon十二 条码识别、字符识别之二维码识别](https://img-blog.csdnimg.cn/direct/746d84b2ec2b4f1cbe1de889ab3223cc.png)