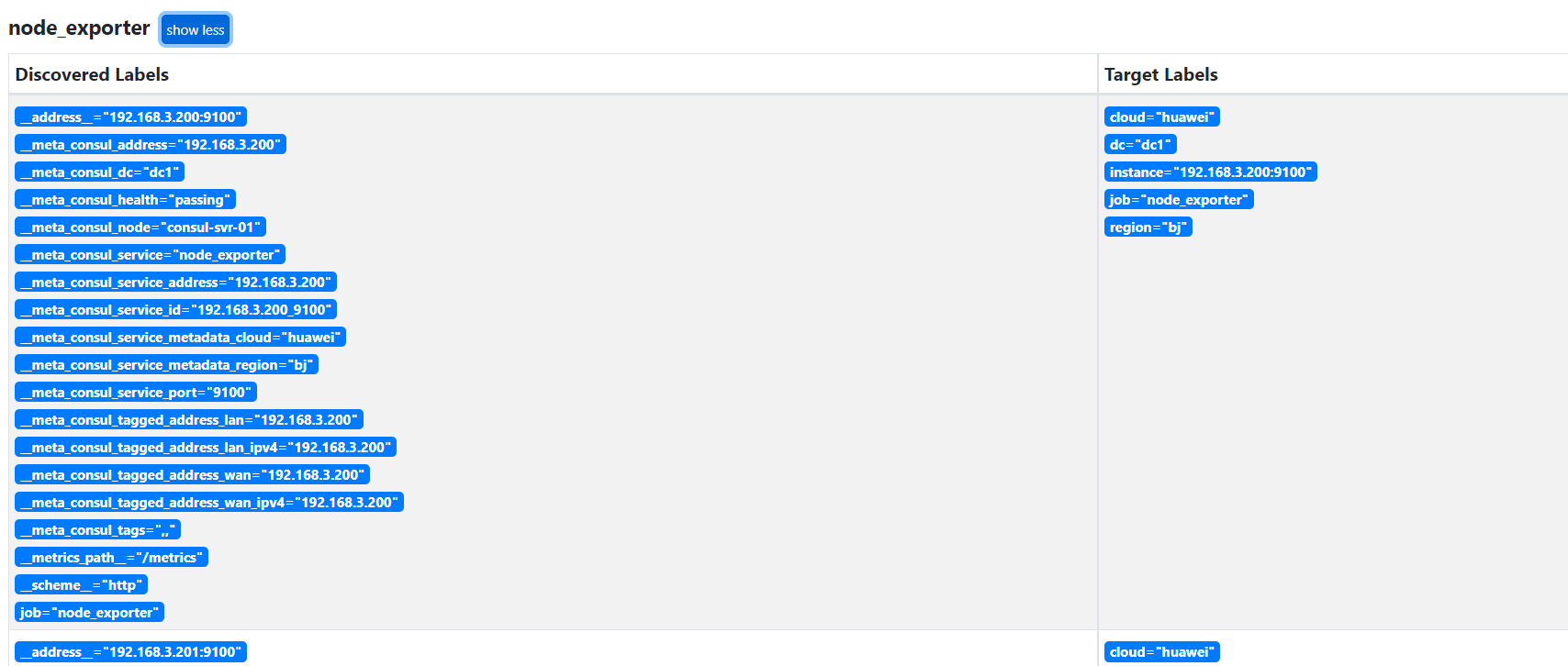
文章目录
- 1.问题
- 2.求解
- 3.直观理解
- 4.例子
- 5.总结
1.问题
给定一个闭凸函数 g ( u ) = ∥ u ∥ 1 g(\mathbf{u}) = \|\mathbf{u}\|_1 g(u)=∥u∥1(即 l 1 l_1 l1 范数),近端映射的定义为:
prox t ( ∥ ⋅ ∥ 1 ) ( x ) = arg min u { ∥ u ∥ 1 + 1 2 t ∥ u − x ∥ 2 } . \text{prox}_t(\|\cdot\|_1)(\mathbf{x}) = \arg\min_{\mathbf{u}} \left\{ \|\mathbf{u}\|_1 + \frac{1}{2t} \|\mathbf{u} - \mathbf{x}\|^2 \right\}. proxt(∥⋅∥1)(x)=argumin{∥u∥1+2t1∥u−x∥2}.
我们的目标是找到一个点 u \mathbf{u} u,使得上述表达式达到最小值。
为了简化分析,我们可以将优化问题分量化,即对每个分量 x i x_i xi 单独考虑。优化问题可以被分解为:
min u i { ∣ u i ∣ + 1 2 t ( u i − x i ) 2 } . \min_{u_i} \left\{ |u_i| + \frac{1}{2t} (u_i - x_i)^2 \right\}. uimin{∣ui∣+2t1(ui−xi)2}.
2.求解
我们将对不同的情况进行讨论,根据 u i u_i ui 的符号,我们可以将绝对值函数 ∣ u i ∣ |u_i| ∣ui∣ 分解为不同的形式:
-
当 u i > 0 u_i > 0 ui>0 时, ∣ u i ∣ = u i |u_i| = u_i ∣ui∣=ui,优化问题变为:
min u i > 0 { u i + 1 2 t ( u i − x i ) 2 } . \min_{u_i > 0} \left\{ u_i + \frac{1}{2t} (u_i - x_i)^2 \right\}. ui>0min{ui+2t1(ui−xi)2}.
-
当 u i < 0 u_i < 0 ui<0 时, ∣ u i ∣ = − u i |u_i| = -u_i ∣ui∣=−ui,优化问题变为:
min u i < 0 { − u i + 1 2 t ( u i − x i ) 2 } . \min_{u_i < 0} \left\{ -u_i + \frac{1}{2t} (u_i - x_i)^2 \right\}. ui<0min{−ui+2t1(ui−xi)2}.
-
当 u i = 0 u_i = 0 ui=0时,表达式的值为 1 2 t x i 2 \frac{1}{2t} x_i^2 2t1xi2。
我们可以通过对这些情况下的函数求导来找到最优值。
当 u i > 0 u_i > 0 ui>0时:
d d u i ( u i + 1 2 t ( u i − x i ) 2 ) = 1 + 1 t ( u i − x i ) . \frac{d}{du_i} \left( u_i + \frac{1}{2t} (u_i - x_i)^2 \right) = 1 + \frac{1}{t} (u_i - x_i). duid(ui+2t1(ui−xi)2)=1+t1(ui−xi).
令导数等于 0,得到:
1 + 1 t ( u i − x i ) = 0 ⟹ u i = x i − t . 1 + \frac{1}{t} (u_i - x_i) = 0 \implies u_i = x_i - t. 1+t1(ui−xi)=0⟹ui=xi−t.
当 u i < 0 u_i < 0 ui<0 时:
d d u i ( − u i + 1 2 t ( u i − x i ) 2 ) = − 1 + 1 t ( u i − x i ) . \frac{d}{du_i} \left( -u_i + \frac{1}{2t} (u_i - x_i)^2 \right) = -1 + \frac{1}{t} (u_i - x_i). duid(−ui+2t1(ui−xi)2)=−1+t1(ui−xi).
令导数等于 0,得到:
− 1 + 1 t ( u i − x i ) = 0 ⟹ u i = x i + t . -1 + \frac{1}{t} (u_i - x_i) = 0 \implies u_i = x_i + t. −1+t1(ui−xi)=0⟹ui=xi+t.
根据上面的求导结果,我们需要结合以下条件来得到最优解:
- 当 x i > t x_i > t xi>t 时,最优解为 u i = x i − t u_i = x_i - t ui=xi−t;
- 当 x i < − t x_i < -t xi<−t时,最优解为 u i = x i + t u_i = x_i + t ui=xi+t;
- 当 ∣ x i ∣ ≤ t |x_i| \leq t ∣xi∣≤t 时,最优解为 u i = 0 u_i = 0 ui=0。
这三种情况可以统一写成软阈值函数的形式:
prox t ( ∥ ⋅ ∥ 1 ) ( x i ) = sign ( x i ) ⋅ max ( ∣ x i ∣ − t , 0 ) . \text{prox}_t(\|\cdot\|_1)(x_i) = \text{sign}(x_i) \cdot \max(|x_i| - t, 0). proxt(∥⋅∥1)(xi)=sign(xi)⋅max(∣xi∣−t,0).
3.直观理解
软阈值函数的作用是对每个分量进行“收缩”:
- 如果 x i x_i xi 的绝对值大于阈值 t t t,那么它被缩小 t t t 的量;
- 如果 x i x_i xi 的绝对值小于或等于 t t t,那么它被直接置为 0。
4.例子
假设 x = ( 3 , − 1 , 0.5 ) \mathbf{x} = (3, -1, 0.5) x=(3,−1,0.5) 且 t = 1 t = 1 t=1,那么通过近端映射计算得到:
- 对于 x 1 = 3 x_1 = 3 x1=3: prox 1 ( ∥ ⋅ ∥ 1 ) ( 3 ) = sign ( 3 ) ⋅ ( 3 − 1 ) = 2 \text{prox}_1(\|\cdot\|_1)(3) = \text{sign}(3) \cdot (3 - 1) = 2 prox1(∥⋅∥1)(3)=sign(3)⋅(3−1)=2。
- 对于 x 2 = − 1 x_2 = -1 x2=−1: prox 1 ( ∥ ⋅ ∥ 1 ) ( − 1 ) = sign ( − 1 ) ⋅ ( 1 − 1 ) = 0 \text{prox}_1(\|\cdot\|_1)(-1) = \text{sign}(-1) \cdot (1 - 1) = 0 prox1(∥⋅∥1)(−1)=sign(−1)⋅(1−1)=0。
- 对于 x 3 = 0.5 x_3 = 0.5 x3=0.5: prox 1 ( ∥ ⋅ ∥ 1 ) ( 0.5 ) = sign ( 0.5 ) ⋅ max ( 0.5 − 1 , 0 ) = 0 \text{prox}_1(\|\cdot\|_1)(0.5) = \text{sign}(0.5) \cdot \max(0.5 - 1, 0) = 0 prox1(∥⋅∥1)(0.5)=sign(0.5)⋅max(0.5−1,0)=0。
因此,近端映射的结果是 prox 1 ( ∥ ⋅ ∥ 1 ) ( x ) = ( 2 , 0 , 0 ) \text{prox}_1(\|\cdot\|_1)(\mathbf{x}) = (2, 0, 0) prox1(∥⋅∥1)(x)=(2,0,0)。
在这个例子中,我们可以看到,对于给定的输入 x = ( 3 , − 1 , 0.5 ) \mathbf{x} = (3, -1, 0.5) x=(3,−1,0.5),近端映射给出了唯一的输出 ( 2 , 0 , 0 ) (2, 0, 0) (2,0,0)。无论我们如何重复计算,给定相同的 x \mathbf{x} x 和参数 t t t,结果总是相同的。这就是所谓的单值映射,即每一个输入只对应一个唯一的输出。
5.总结
近端映射是从空间 E E E 到自身的单值映射,这意味着它对每个输入点 x \mathbf{x} x 总是返回唯一的、确定的输出点 u \mathbf{u} u。这种特性在优化问题中非常有用,因为它确保了算法在每一步都有明确的更新方向,不会产生多义性。