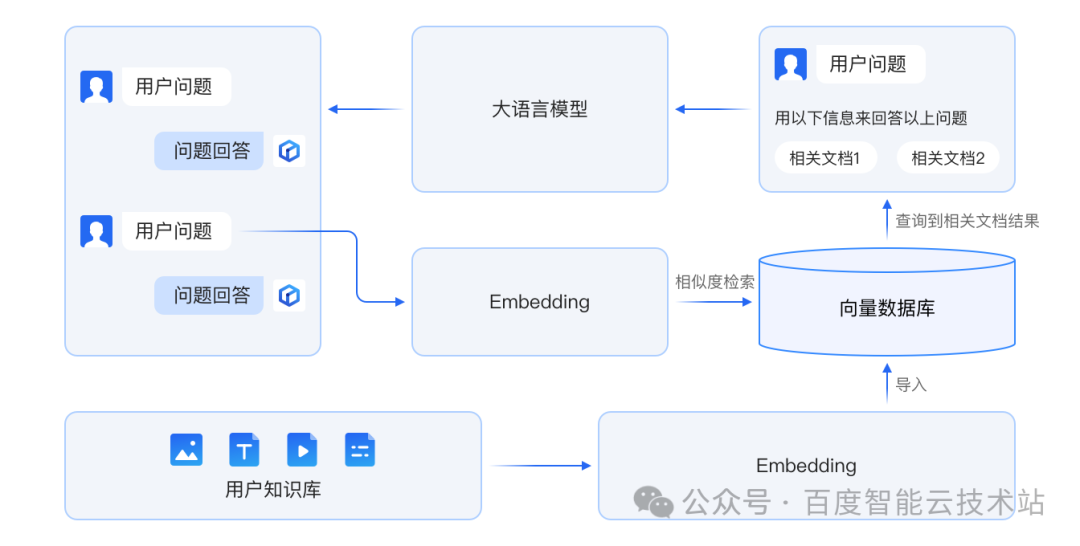
ElasticSearch简介
Elasticsearch 是一个分布式的、开源的搜索分析引擎,支持各种数据类型,包括文本、数字、地理、结构化、非结构化。
Lucene与ElasticSearch
Apache Lucene是一款高性能的、可扩展的信息检索(IR)工具库,是由Java语言开发的成熟、自由开源的搜索类库,基于Apache协议授权。Lucene只是一个软件类库,如果要发挥Lucene的功能,还需要开发一个调用Lucene类库的应用程序。
ElasticSearch在底层利用Lucene完成其索引功能,因此其许多基本概念源于Lucene。ElasticSearch封装了许多lucene底层功能,提供了分布式的服务、简单易用的restful API接口和许多语言的客户端。
倒排索引
Lucene中对文档检索基于倒排索引实现,并将它发挥到了极致。
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
例如:
| id | 句子 |
|---|---|
| 1 | I like apples |
| 2 | I dislike apples |
| 3 | I dislike apples too |
如果要用单词作为索引,而句子的位置作为被索引的元素,那么索引就发生了倒置:
| id | 单词索引 |
|---|---|
| I | {1,2,3} |
| like | {1} |
| apples | {1,2,3} |
| dislike | {2,3} |
| too | {3} |
如果要检索I dislike apples这句话,那么就可以这么计算 : {1,2,3} ^ {2,3} ^ {1,2,3} (^是交集)
核心概念
-
索引(Index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
-
类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
-
文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
-
映射(Mapping)
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。另外,ES还提供了额外功能,例如将域中的内容按需排序。事实上,ES也能自动根据其值确定域的类型。
-
**节点(Node) **
一个es实例即为一个节点,也是集群的一部分,它存储你的数据,并参与集群的索引和搜索。和集群一样,节点也是通过唯一的名字去区分,默认名字是一个随机的UUID,当服务器启动的时候就会设置到节点。你也可以自定义节点的名称。名称对管理员来说十分重要,它可以帮助你辨认出集群中的各个服务器和哪个节点相对应。
-
分片(Shard)和副本(Replica)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。 -
集群(Cluster)
集群是一个或多个节点(服务器)的集合,它们联合起来保存所有的数据(索引以分片为单位分散到多个节点上保存)并且可以在所有的节点上进行索引和搜索操作。集群通过一个唯一的名字区分,默认的名字是“elasticsearch”。这个名字十分重要,因为一个节点仅仅可以属于一个集群,并根据集群名称加入集群。
与关系型数据库核心概念对比
| Elasticsearch | 关系型数据库(如Mysql) |
|---|---|
| 索引Index | 数据库Database |
| 类型Type(8.x版本已废弃) | 表Table |
| 文档Document | 数据行Row |
| 字段Field | 数据列Column |
| 映射Mapping | 约束Schema |
数据类型
Elasticsearch 8.x中已经完全删除了数据类型,创建映射时也不再支持使用type字段指定数据类型,不然会报错"index" is not a valid parameter. Allowed parameters are "create", "error_trace"
这里就不继续介绍数据类型了
安装和启动
Windows
1.去官网Download Elasticsearch | Elastic下载windows版本压缩包,然后解压;
2.修改config目录下的elasticsearch.yml文件,将截图中的两个配置项true改为false,不然会报错[WARN ][o.e.h.n.Netty4HttpServerTransport] [BF-202205061541] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/[0:0:0:0:0:0:0:1]:9200, remoteAddress=/[0:0:0:0:0:0:0:1]:62134}
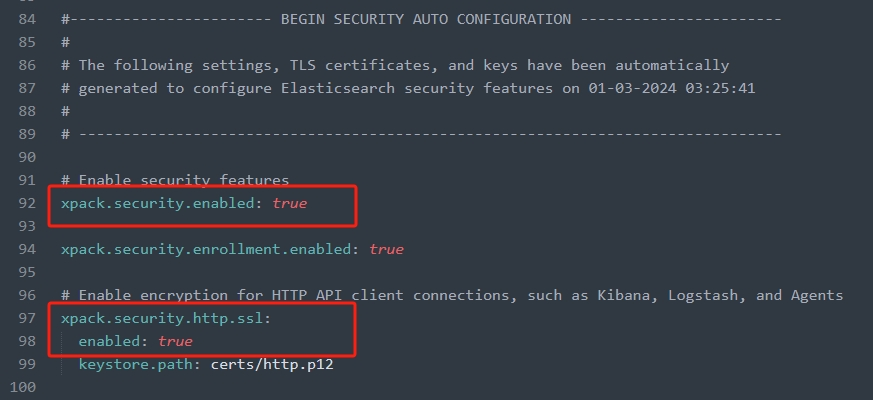
3.双击bin/elasticsearch.bat脚本启动服务
4.打开浏览器访问http://localhost:9200/,输出下面的json信息表示启动成功
{"name": "BF-202205061541","cluster_name": "elasticsearch","cluster_uuid": "0JlZuKgbSWa3DGX44DnxgQ","version": {"number": "8.12.2","build_flavor": "default","build_type": "zip","build_hash": "48a287ab9497e852de30327444b0809e55d46466","build_date": "2024-02-19T10:04:32.774273190Z","build_snapshot": false,"lucene_version": "9.9.2","minimum_wire_compatibility_version": "7.17.0","minimum_index_compatibility_version": "7.0.0"},"tagline": "You Know, for Search"
}
Docker
-
拉取镜像
docker pull elasticsearch:8.12.2 # 版本号自己选择 -
创建并启动容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -d elasticsearch:8.12.2 -
设置密码
docker exec -it elasticsearch # 进入docker cd /usr/share/elasticsearch/bin # 进入elasticsearch目录 ./elasticsearch-setup-passwords interactive #要同时设置内置6个账户的密码 -
访问elasticsearch
浏览器打开
https://192.168.204.128:9200即可访问,需要输入上面设置的账号和密码,注意这里是要https访问
安装分词器
elasticsearch有默认的分词器,但是对中文不太友好,我们可以单独安装适用于中文的分词器ik;根据你的es版本再Releases · infinilabs/analysis-ik (github.com)下载对应的压缩包,然后解压到es目录下的plugins/ik目录,然后重启es服务即可
插件
es-client(推荐)
elasticsearch的浏览插件,项目主页 | es-client (esion.xyz),提供各个浏览器插件,在插件市场都能搜得到,界面美观
elasticsearch-head
elasticsearch-head是一种便捷查询操作elasticsearch库的可视化工具,具备集群管理、增删查改等功能,用于监控 Elasticsearch 状态的客户端插件,包括数据可视化、执行增删改查操作等,有npm、docker和浏览器扩展版本(仅Chrome浏览器),按照下面文档选择自己喜欢的方式安装即可
mobz/elasticsearch-head: A web front end for an elastic search cluster (github.com)
php调用
由于实际开发中项目都是使用php框架开发,所以以下分别用ThinkPHP5和Laravel框架实现
ThinkPHP框架
- 安装扩展
composer require elasticsearch/elasticsearch
composer dump-autoload
-
索引和文档的增删改查
<?phpnamespace app\index\controller;use Elasticsearch\ClientBuilder;class Elasticsearch {// 客户端protected $client = null;//索引名称protected $indexName = 'test';public function __construct(){try {$this->client = ClientBuilder::create()->setHosts(['127.0.0.1:9200'])->build();} catch (\Exception $e) {die($e->getMessage());}}/*** 创建索引* @desc 相当于mysql的数据库,索引只需要创建一次*/public function createIndex(){$params = ['index' => $this->indexName, // 索引名称'body' => ['settings' => ['number_of_shards' => 5, //分片数量:一个索引库将拆分成多片分别存储不同的结点,默认5个'number_of_replicas' => 0 //为每个分片分配的副本数,replica shard是primary shard的副本,负责容错,以及承担读请求负载,如果服务器只有一台,只能设置为0,不然会报错创建超时failed to process cluster event (create-index [test], cause [api]) within 30s],//创建文档映射,就是文档存储在ES中的数据结构,这里以商城商品搜索为例,建立商品的映射'mappings' => ['properties' => ['goods_id' => [ //商品id'type' => 'keyword','index' => 'true',],'goods_name' => [ //商品名称'type' => 'text', //数据类型为text,支持分词;类型为keyword,不支持分词,只能精确索引;8.x以上版本不再支持string等类型'index' => 'true', //字段可以被索引,也就是能用来当做查询条件来查询,只能填写true和false'analyzer' => 'ik_max_word', //索引分词器,用于字符串类型,这里使用中文分词器ik,用默认分词器可以省略'search_analyzer' => 'ik_smart'//搜索分词器,用于搜索关键词的分词器],'goods_desc' => [ //商品描述'type' => 'keyword','index' => 'false', //字段不可以被索引,不能用来当做查询条件来查询],'stock' => [ //商品库存'type' => 'keyword','index' => 'true',],'created_at' => [ //创建时间'type' => 'keyword','index' => 'true',],'status' => [ //上架状态'type' => 'keyword','index' => 'true',],]]]];try {return $this->client->indices()->create($params);} catch (\Exception $e) {return $e->getMessage();}}/*** 删除索引*/public function deleteIndex(){$params = ['index' => $this->indexName, // 索引名称];try {return $this->client->indices()->delete($params);} catch (\Exception $e) {return $e->getMessage();}}/*** 查看映射*/public function getMapping(){$params = ['index' => $this->indexName, // 索引名称];try {return $this->client->indices()->getMapping($params);} catch (\Exception $e) {return $e->getMessage();}}/*** 新增文档*/public function addDoc(){$params = ['index' => $this->indexName, // 索引名称'id' => 1, //文档id,可省略,默认生成随机id'body' => ['goods_id' => 1, //商品id'goods_name' => '爆款煎饼(传统双蛋煎饼+肉松+优质火腿片+配菜+薄脆)', //商品名称'goods_desc' => '煎饼果子', //商品描述'stock' => 100, //库存'created_at' => '2019-06-01 00:00:00', //创建时间'status' => 1, //上架状态]];try {return json_encode($this->client->index($params));} catch (\Exception $e) {return $e->getMessage();}}/*** 获取文档*/public function getDoc(){$params = ['index' => $this->indexName, // 索引名称'id' => 1, //文档id];try {return json_encode($this->client->get($params));} catch (\Exception $e) {return $e->getMessage();}}/*** 更新文档*/public function updateDoc(){$params = ['index' => $this->indexName, // 索引名称'id' => 1, //文档id'body' => ['doc' => ['goods_name' => '爆款煎饼(传统双蛋煎饼+肉松+优质火腿片+配菜+薄脆)', //更新商品名称]]];try {return json_encode($this->client->update($params));} catch (\Exception $e) {return $e->getMessage();}}/*** 删除文档*/public function deleteDoc(){$params = ['index' => $this->indexName, // 索引名称'id' => 1, //文档id];try {return json_encode($this->client->delete($params));} catch (\Exception $e) {return $e->getMessage();}}/*** 查询文档** 查询条件* must(且):数组里面的条件都要满足,该条数据才被选择,所有的条件为且的关系* must_not(或,然后取反):数组里面的条件满足其中一个,该条数据则不被选择* should(或):数组里面的条件满足其中一个,该条数据被选择*/public function searchDoc(){$keywords = '火腿煎饼'; // 查询关键词$params = ['index' => $this->indexName, // 索引名称'body' => ['query' => ['bool' => ['should' => [ //should:模糊查询(or);must:精确查询(and);must_not:or取反;'match' => ['goods_name' => $keywords], //match:匹配字段;range:范围查询]],],'sort' => ['stock' => ['order' => 'desc']], // 排序'from' => 0, // 分页起始位置'size' => 10 // 分页记录数量]];try {return json_encode($this->client->search($params),JSON_UNESCAPED_UNICODE);} catch (\Exception $e) {return $e->getMessage();}}//testpublic function test(){ // $res = 123; // $res = $this->deleteIndex(); // $res = $this->createIndex(); // $res = $this->getMapping(); // $res = $this->addDoc(); // $res = $this->getDoc(); // $res = $this->updateDoc(); // $res = $this->deleteDoc();$res = $this->searchDoc();var_dump($res);} }
Laravel框架
方式一
参考上面的ThinkPHP框架调用
方式二
Laravel框架除了能像tp框架一样自己写es的功能,它还有专门的es扩展包,并且支持在model中使用es及导入数据
-
安装扩展包
composer require elasticsearch/elasticsearch composer require tamayo/laravel-scout-elastic composer require laravel/scout -
发布配置
php artisan vendor:publish --provider="Laravel\Scout\ScoutServiceProvider" -
修改配置
修改
config/scout.php文件的配置,将驱动'driver' => env('SCOUT_DRIVER', 'algolia')改为'driver' => env('SCOUT_DRIVER', 'elastic')然后最文件增加elasticsearch配置
/* |-------------------------------------------------------------------------- | Elasticsearch Configuration |-------------------------------------------------------------------------- | | Here you may configure your Elasticsearch settings. | */ 'elasticsearch' => ['index' => env('ELASTICSEARCH_INDEX', 'laravel'), //laravel就是索引的名字,可以根据你的需求随便起'hosts' => [env('ELASTICSEARCH_HOST', 'http://127.0.0.1:9200'),],],当然,你可以在
.env环境配置文件中覆盖配置ELASTICSEARCH_HOST=127.0.0.1:9200 -
使用es
public function handle(){$host = config('scout.elasticsearch.hosts');$index = config('scout.elasticsearch.index');$client = ClientBuilder::create()->setHosts($host)->build();if ($client->indices()->exists(['index' => $index])) {$this->warn("Index {$index} exists, deleting...");$client->indices()->delete(['index' => $index]);}$this->info("Creating index: {$index}");return $client->indices()->create(['index' => $index,'body' => ['settings' => ['number_of_shards' => 1,'number_of_replicas' => 0],'mappings' => ['_source' => ['enabled' => true],'properties' => ['id' => ['type' => 'long'],'title' => ['type' => 'text','analyzer' => 'ik_max_word','search_analyzer' => 'ik_smart'],'subtitle' => ['type' => 'text','analyzer' => 'ik_max_word','search_analyzer' => 'ik_smart'],'content' => ['type' => 'text','analyzer' => 'ik_max_word','search_analyzer' => 'ik_smart']],]]]); } -
Model中使用
参考官方文档Scout 全文搜索 | 官方扩展包 |《Laravel 6 中文文档 6.x》| Laravel China 社区 (learnku.com)








![[Redis]——Spring整合Redis(SpringDataRedis)](https://img-blog.csdnimg.cn/direct/a4298eca7d26480a89d703e329b3d3b8.png)