Module:给所有的神经网络提供一个基本的骨架,所有神经网络都需要继承Module,并定义_ _ init _ _方法、 forward() 方法 在_ _ init _ _方法中定义,卷积层的具体变换,在forward() 方法中定义,神经网络的前向传播具体是什么样的 官方代码样例如下: import torch.nn as nn
import torch.nn.functional as Fclass Model( nn.Module) :def __init__( self) :super( ) .__init__( ) self.conv1 = nn.Conv2d( 1 , 20 , 5 ) self.conv2 = nn.Conv2d( 20 , 20 , 5 ) def forward( self, x) :x = F.relu( self.conv1( x)) return F.relu( self.conv2( x))
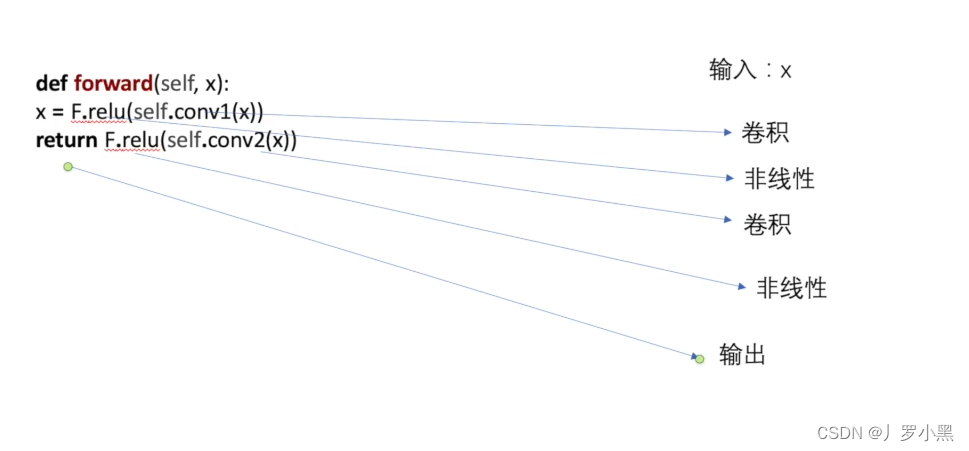
表明输入 x 经过一个卷积层A,一个非线性层a,一个卷积层B,一个非线性层b,最后输出,如下图: 简单模型代码如下: from torch import nn
import torch
class Tudui( nn.Module) :def __init__( self) : super( ) .__init__( ) def forward( self, input) : output = input + 1 return output tudui = Tudui( )
x = torch.tensor( 1.0 )
print( tudui( x))
* 注意:可以在调试模式中,选择单步执行代码,一步一步执行更清晰
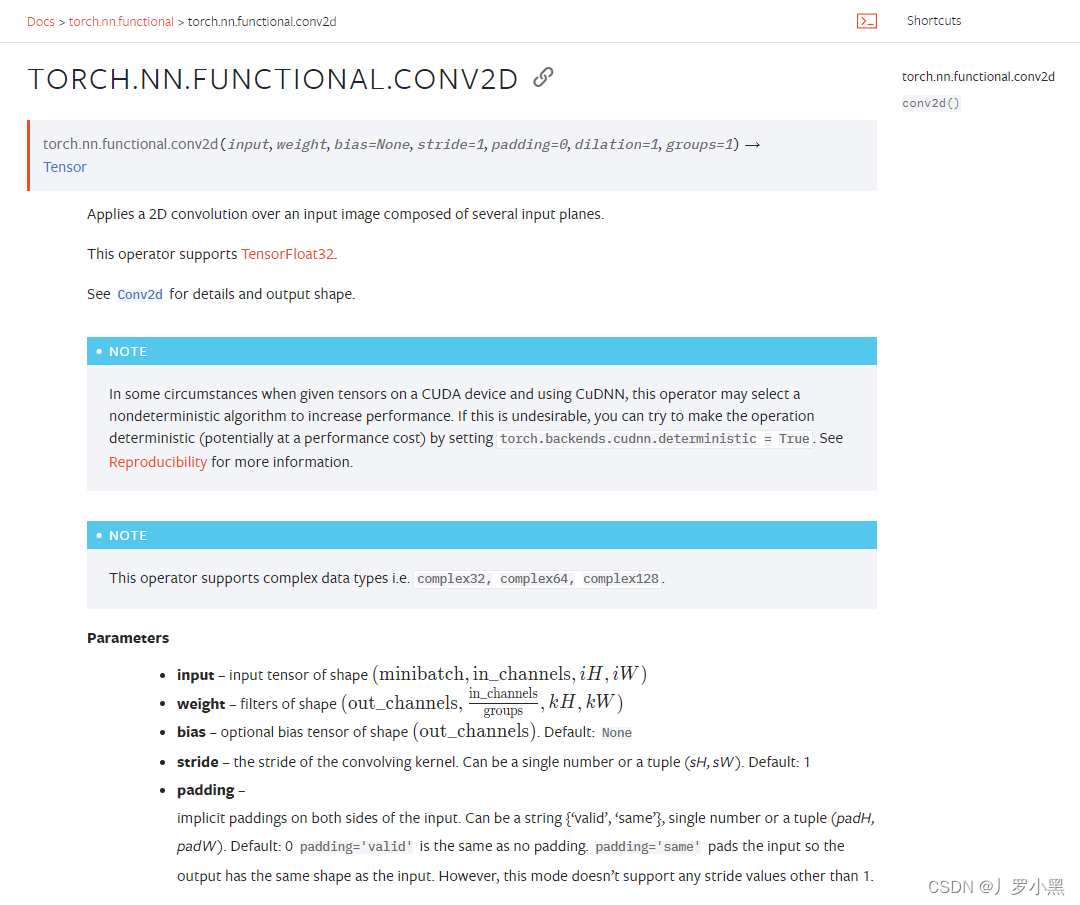
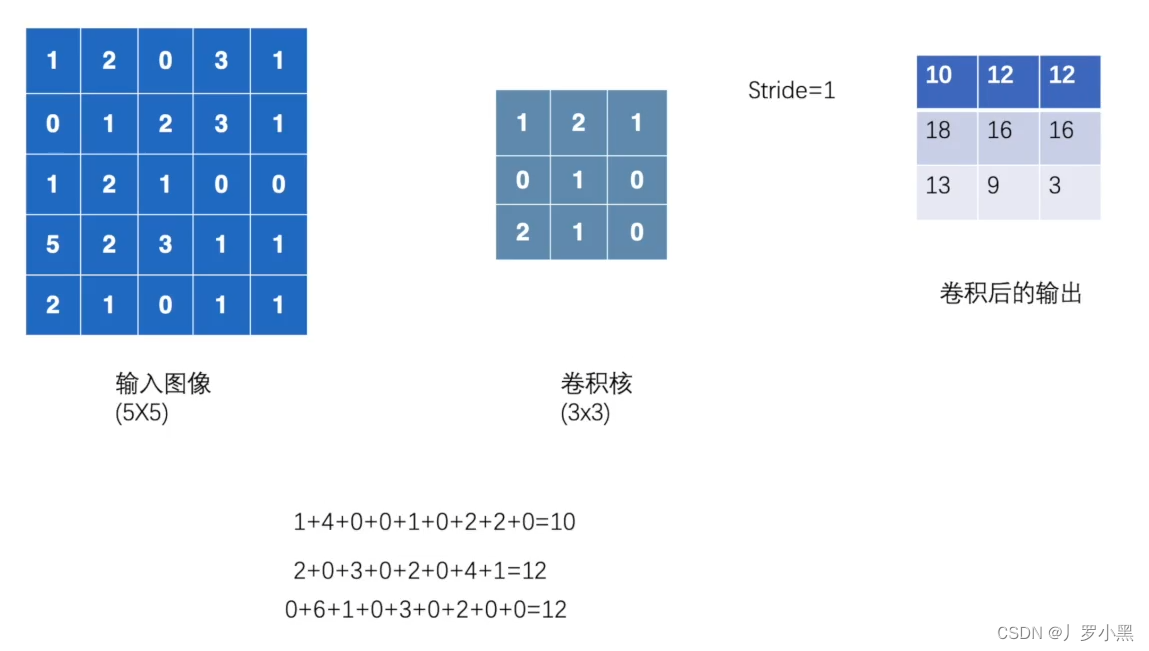
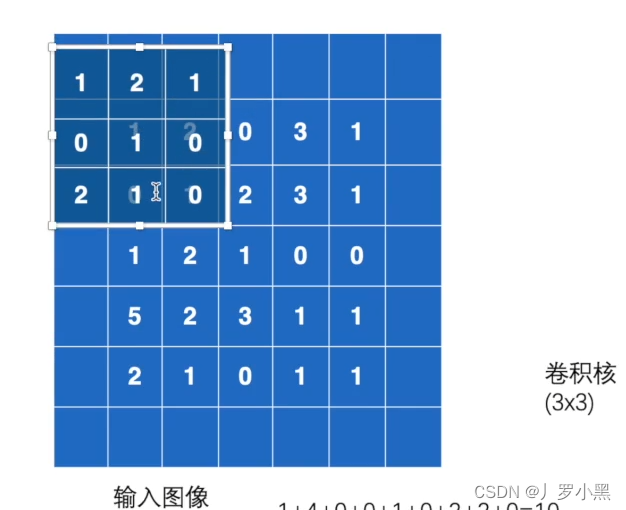
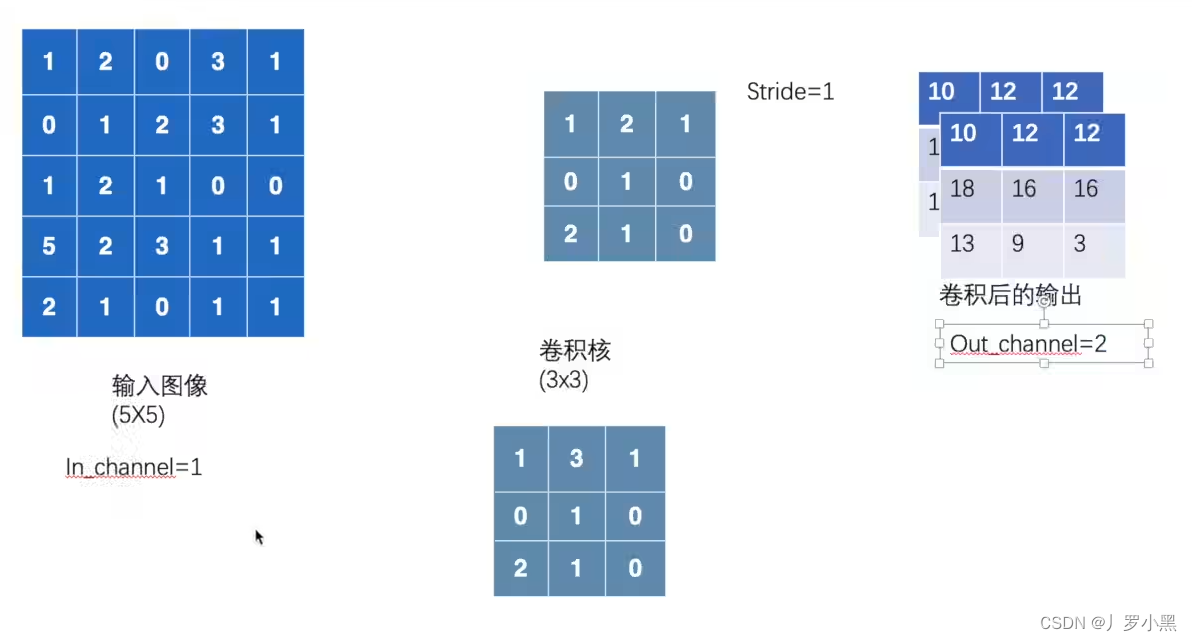
2D卷积操作:卷积核在输入图像上不断移动,并把对应位相乘再求和,最后得到输出结果,以下是参数设置: input:输入张量的维数要是四维,batch表示一次输入多少张图像,channel表示通道数,RGB图像的通道数为3,灰度图像(一层二维张量)的通道数为1,H为高度,W为宽度 weight:卷积核,维数也要是四维,out_channel表示(输出通道数)卷积核的数量,in_channel表示输入图像的通道数,一般groups为1,H为高度,W为宽度 stride:卷积核每次移动的步长(为整数或者长度为2的元组),如果是整数,表示在水平和垂直方向上使用相同的步长。如果是元组,分别表示在水平和垂直方向上的步长。默认为1。 padding:控制在输入张量的边界周围添加的零填充的数量(为整数或长度为2的元组),如果是整数,表示在水平和垂直方向上使用相同的填充数量。如果是元组,分别表示在水平和垂直方向上的填充数量。默认为0 例如,将一张灰度图经过2D卷积操作得到输出的代码,如下: import torch
input = torch.tensor( [ [ 1,2 ,0,3,1] ,[ 0,1 ,2,3,1] ,[ 1,2 ,1,0,0] ,[ 5,2 ,3,1,1] ,[ 2,1 ,0,1,1] ] )
kernel = torch.tensor( [ [ 1,2 ,1] ,[ 0,1 ,0] ,[ 2,1 ,0] ] )
print( input.shape)
print( kernel.shape)
input = torch.reshape( input, [ 1,1 ,5,5] )
kernel = torch.reshape( kernel, [ 1,1 ,3,3] ) print( input.shape)
print( kernel.shape) output = torch.nn.functional.conv2d( input, kernel, stride = 1 )
print( output)
可视化图如下: padding设置为1的可视化图如下:
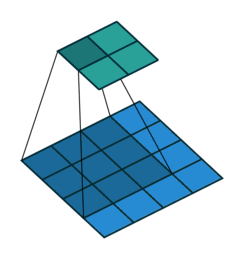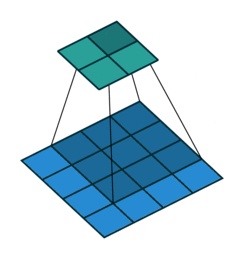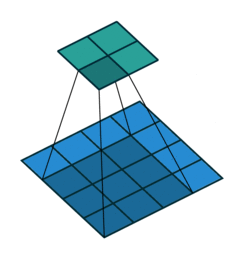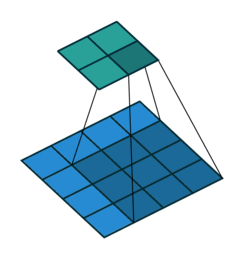
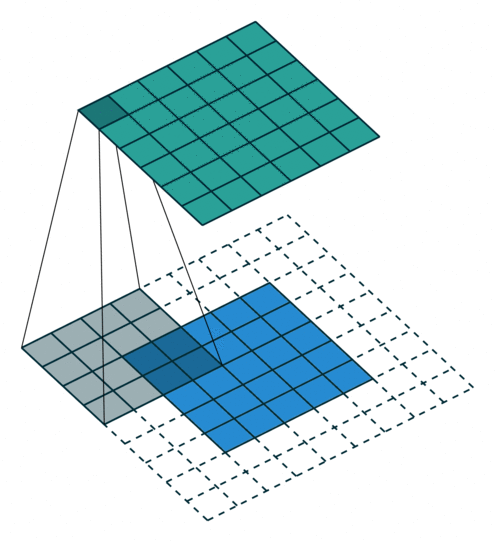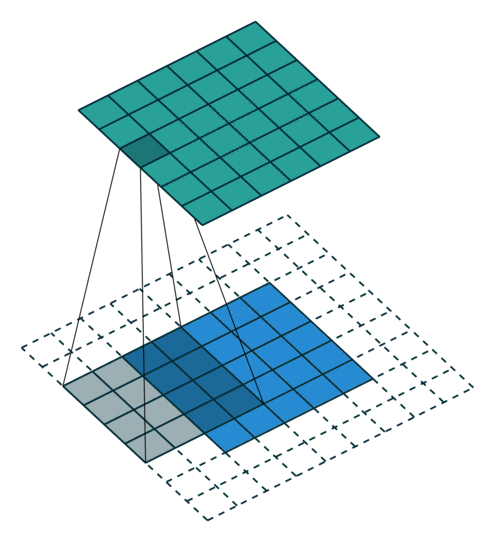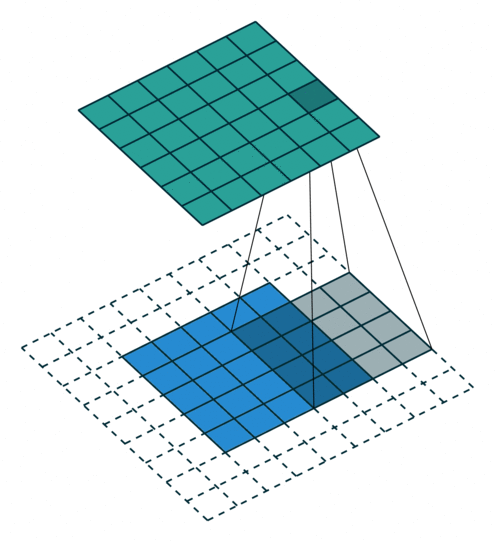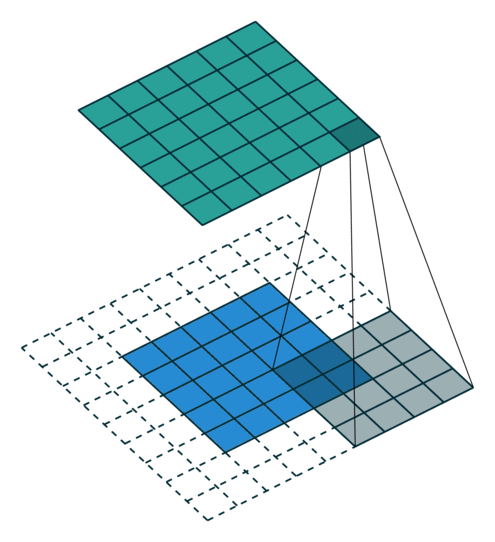
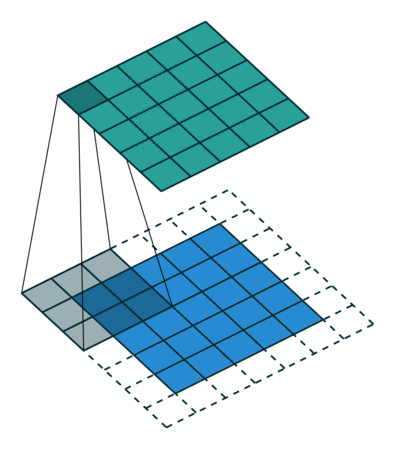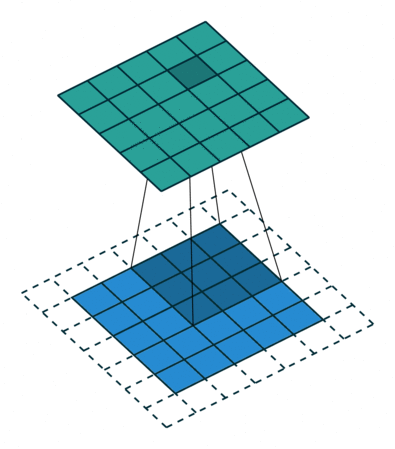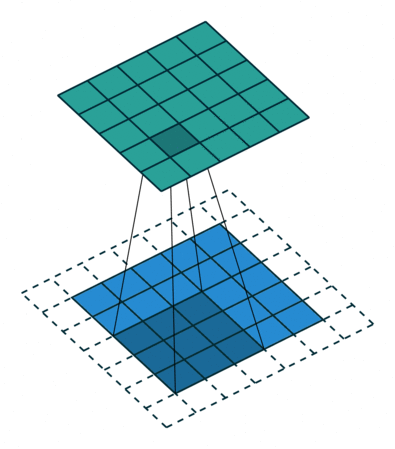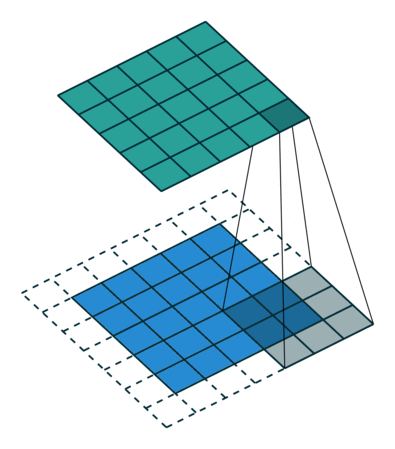
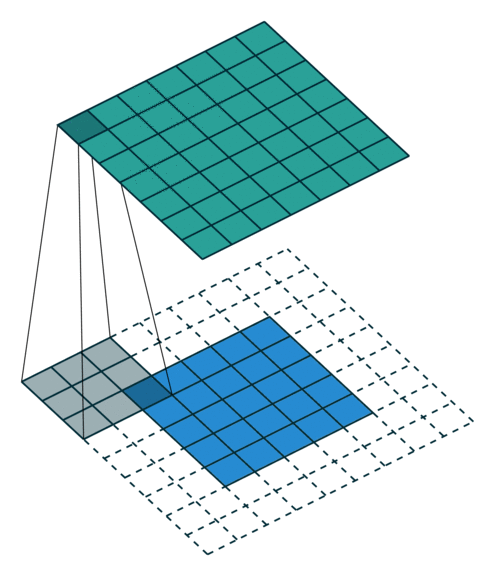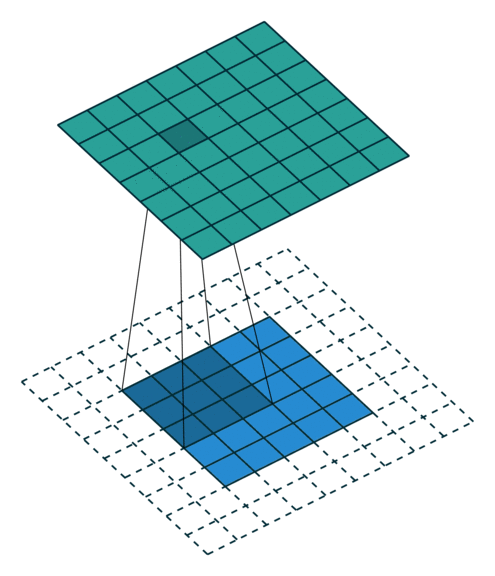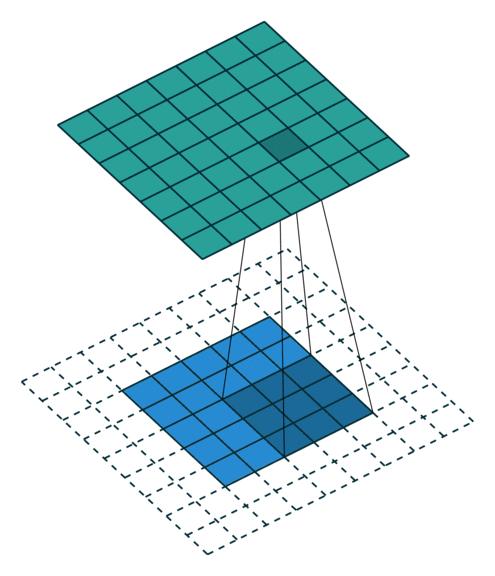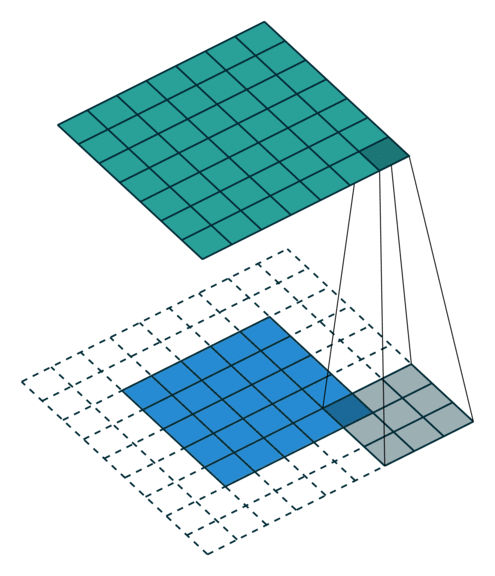
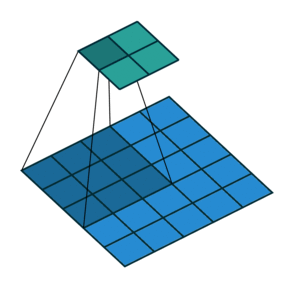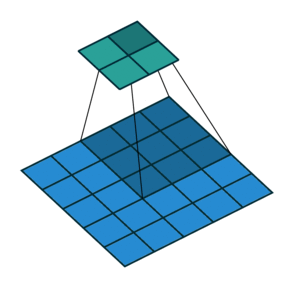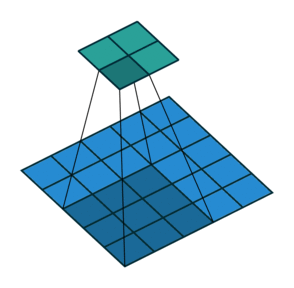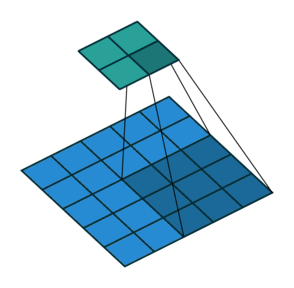
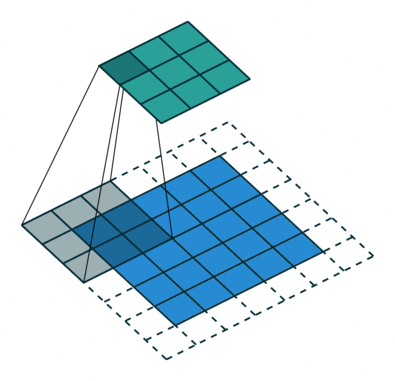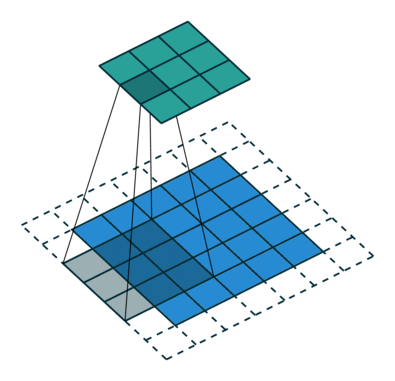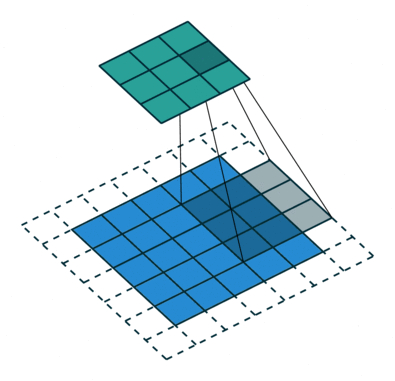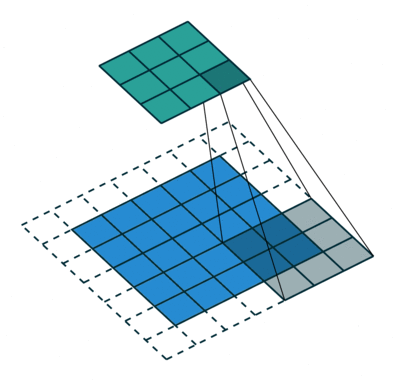
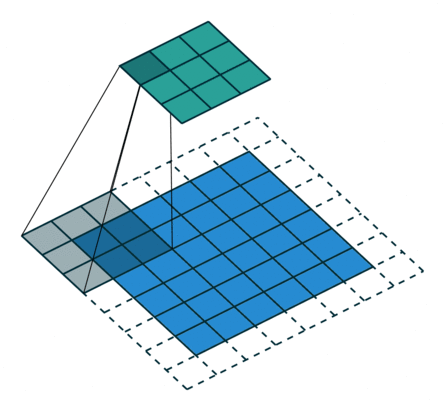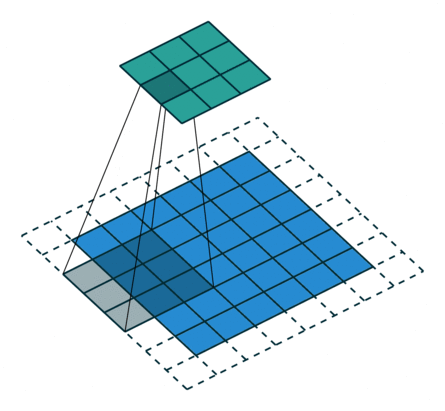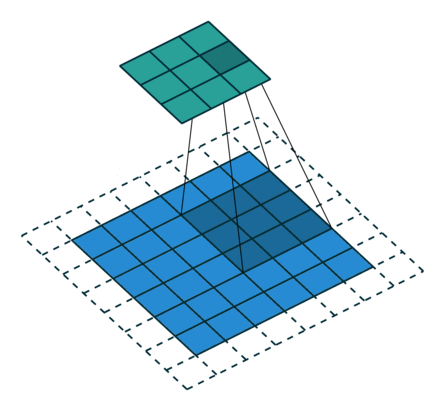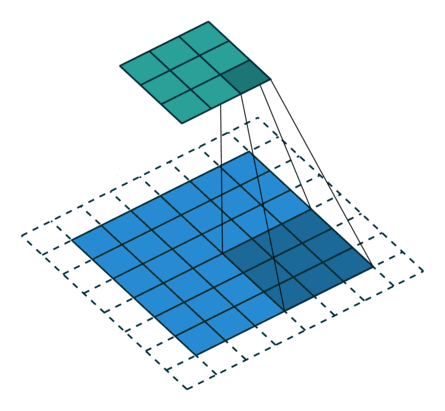
2D卷积层,通常我们直接使用卷积层即可,上一节仅供了解,以下是参数设置: in_channels:输入通道数,RGB图像为3,灰度图像为1,一层二维张量为1 out_channels:输出通道数,即卷积核的个数 kernel_size:卷积核的高宽(整数或元组),整数时表示高宽都为该整数,元组时表示分别在水平和垂直方向上的长度。我们只需要设置卷积核的高宽,而卷积核内部的具体参数不需要我们指定,它是在神经网络的训练中不断地对分布进行采样,同时进行不断调整 stride:卷积核每次移动的步长(整数或元组),整数时表示在水平和垂直方向上使用相同的步长。元组时分别表示在水平和垂直方向上的步长。默认为1。 padding:控制在输入张量的边界周围添加的零填充的数量(为整数或元组),如果是整数,表示在水平和垂直方向上使用相同的填充数量。如果是元组,分别表示在水平和垂直方向上的填充数量。默认为0 padding_mode:控制以什么样的模式进行填充,默认为 zeros 零填充 dilation:卷积核内部元素之间的距离,空洞卷积 groups:默认为1 bias:给输出加一个偏置,默认为True 以下是2D卷积层的可视化图像,青色的为输出图像,蓝色为输入图像,深蓝色为卷积核: No padding,No strides Aribitrary padding,No strides
Half padding,No strides Full padding,No strides
No padding,strides Padding,strides Padding,strides(odd)
当out_channel 为2时,卷积核也为2个,会先拿第一个卷积核与输入图像进行卷积,得到第一个输出,然后会拿第二个卷积核与输入图像进行卷积,得到第二个输出,这两个卷积核内部的具体参数可能会不同,最后把这两个输出叠加起来得到最终的输出,以下是可视化图像: 构建一个包含一层简单2D卷积层的神经网络模型,代码如下: import torch
import torch.nn as nn
import torchvisiontest_dataset = torchvision.datasets.CIFAR10( root= 'Dataset' , train = False, download = True, transform = torchvision.transforms.ToTensor( ))
test_loader = torch.utils.data.DataLoader( test_dataset, batch_size = 64 , shuffle = False, num_workers = 0 ) class Tudui( nn.Module) :def __init__( self) : super( ) .__init__( ) self.conv1 = nn.Conv2d( 3 , 6 , 3 , 1 , 0 ) def forward( self, x) : x = self.conv1( x) return xtudui = Tudui( ) print( tudui)
for data in test_loader:imgs, targets = dataoutputs = tudui( imgs) print( imgs.shape) print( outputs.shape)
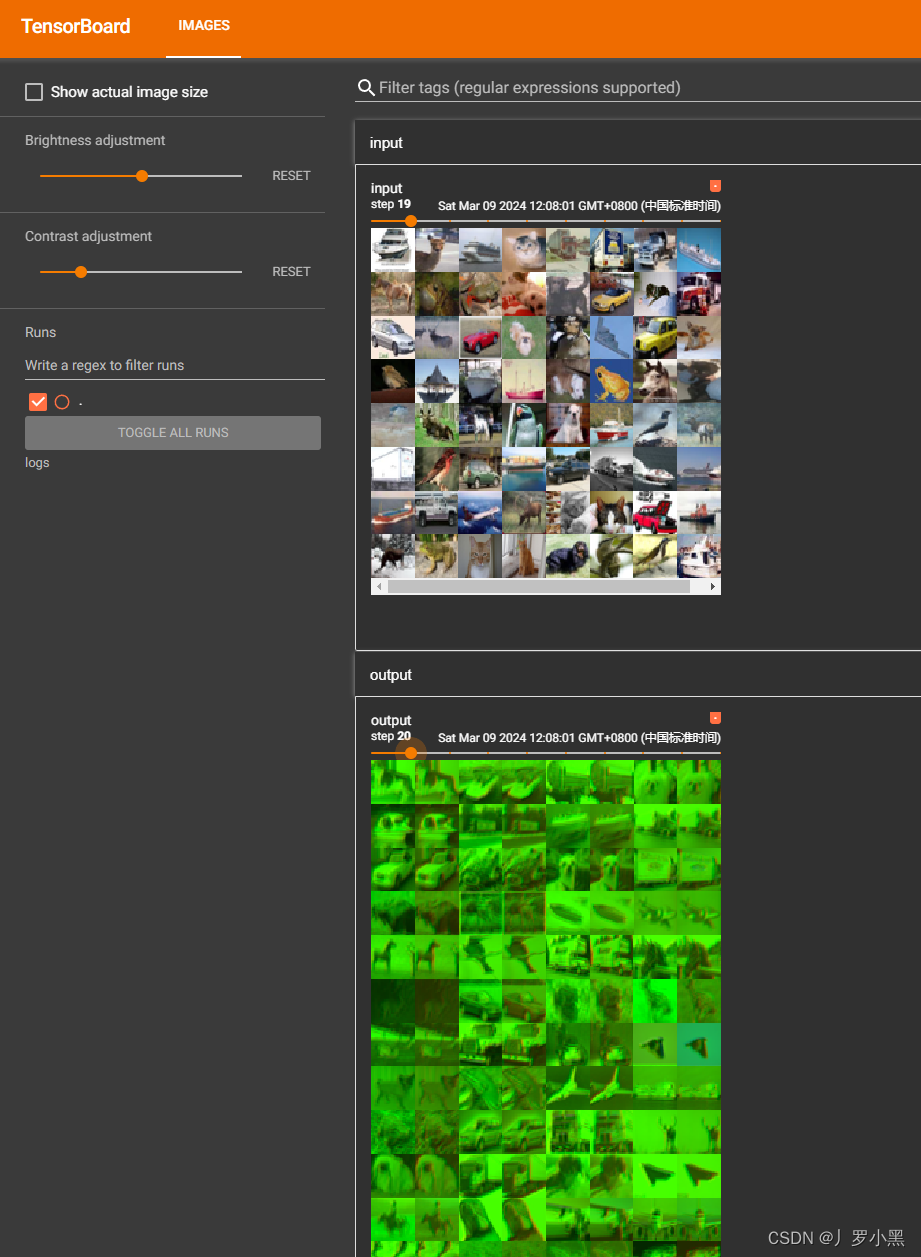
可以通过tensorboard来展示输入图像和输出图像,代码如下: 注意: 由于outputs的channel为6,而add_images函数要求channel为3,所以需要对outputs进行处理 把torch.Size([64, 6, 30, 30]) -> torch.Size([xx, 3, 30, 30]) 把6个通道变成3个通道,多出来的部分就打包放入batch_size中 如果不知道变换后的batch_size是多少,可以写-1,PyTorch会自动计算 import torch
import torch.nn as nn
import torchvision
from torch.utils.tensorboard import SummaryWritertest_dataset = torchvision.datasets.CIFAR10( root= 'Dataset' , train = False, download = True, transform = torchvision.transforms.ToTensor( ))
test_loader = torch.utils.data.DataLoader( test_dataset, batch_size = 64 , shuffle = False, num_workers = 0 ) class Tudui( nn.Module) :def __init__( self) : super( ) .__init__( ) self.conv1 = nn.Conv2d( 3 , 6 , 3 , 1 , 0 ) def forward( self, x) : x = self.conv1( x) return xtudui = Tudui( ) writer = SummaryWriter( "logs" )
step = 0
for data in test_loader:imgs, targets = dataoutputs = tudui( imgs) writer.add_images( "input" , imgs, step) outputs = torch.reshape( outputs, ( -1, 3 , 30 , 30 )) writer.add_images( "output" , outputs, step) step += 1 writer.close( )
结果如下: 注意:如果别人论文里没有写stride、padding具体为多少,那么我们可以根据以下式子进行推导: N:batch_size C:channel H:高 W:宽