数据模型 DataModel
指标 Metric
metric 包含 metric name 和 metric label
格式:
<metric name>{<label name>=<label value>, ...}
例如:服务器 HTTP 接口 /messages 的总请求数
api_http_requests_total{method="POST", handler="/messages"}
Metric Names
- 命名规范:[a-zA-Z_:][a-zA-Z0-9_:]*
Metric Labels
- 命名规范:[a-zA-Z_][a-zA-Z0-9_]*
- 双下划线 __ 是系统预留的
样本 Samples
样本包含一个 float64 类型数据和一个毫秒级时间戳
指标分类 Metric Types
计数器 Counter
用来表示只增不减的指标。
例如:http 接口请求数
# HELP prometheus_http_requests_total Counter of HTTP requests.
# TYPE prometheus_http_requests_total counter
prometheus_http_requests_total{code="200",handler="/-/ready"} 1
prometheus_http_requests_total{code="200",handler="/api/v1/label/:name/values"} 1
prometheus_http_requests_total{code="200",handler="/api/v1/query"} 1
prometheus_http_requests_total{code="200",handler="/favicon.ico"} 7
prometheus_http_requests_total{code="200",handler="/graph"} 1
prometheus_http_requests_total{code="200",handler="/metrics"} 15
prometheus_http_requests_total{code="200",handler="/static/*filepath"} 3
prometheus_http_requests_total{code="302",handler="/"} 1
仪表 Gauge
仪表通常用于测量值,如温度或当前内存使用情况,也可用于上下变化的“计数”,如并发请求的数量。
例如:堆内存块申请的量
# HELP go_memstats_heap_objects Number of allocated objects.
# TYPE go_memstats_heap_objects gauge
go_memstats_heap_objects 210915
Histogram
Histogram 对观察结果(通常是请求持续时间或响应大小)进行采样,并在可配置的桶中对其进行计数。它还提供了所有观测值的总和。
在大多数情况下人们一般倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 Web 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10 ms 之间的请求数有多少,而 10~20 ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
例如:
# HELP prometheus_tsdb_compaction_chunk_range_seconds Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range_seconds histogram
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="100"} 0
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="400"} 0
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1600"} 0
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6400"} 0
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="25600"} 0
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="102400"} 0
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="409600"} 32
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1.6384e+06"} 56
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6.5536e+06"} 7989
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="2.62144e+07"} 7989
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="+Inf"} 7989
prometheus_tsdb_compaction_chunk_range_seconds_sum 1.5042587366e+10
prometheus_tsdb_compaction_chunk_range_seconds_count 7989
Summary
Histogram 在客户端仅是简单的桶划分和分桶计数,分位数计算由 Prometheus Server 基于样本数据进行估算,因而其结果未必准确,甚至不合理的 bucket 划分会导致较大的误差。
Summary 是一种类似于 Histogram 的指标类型,但它在客户端于一段时间内(默认为 10 分钟)的每个采样点进行统计,计算并存储了分位数数值,Server 端直接抓取相应值即可。
对于每个指标,Summary 以指标名称 为前缀,生成如下几个指标序列:
- _sum :统计所有样本值之和
- _count :统计所有样本总数
- {quantile=“x”} :统计样本值的分位数分布情况,分位数范围:0 ≤ x ≤ 1
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 2.6563e-05
go_gc_duration_seconds{quantile="0.25"} 2.8106e-05
go_gc_duration_seconds{quantile="0.5"} 3.0472e-05
go_gc_duration_seconds{quantile="0.75"} 3.3599e-05
go_gc_duration_seconds{quantile="1"} 4.4264e-05
go_gc_duration_seconds_sum 0.000422106
go_gc_duration_seconds_count 13
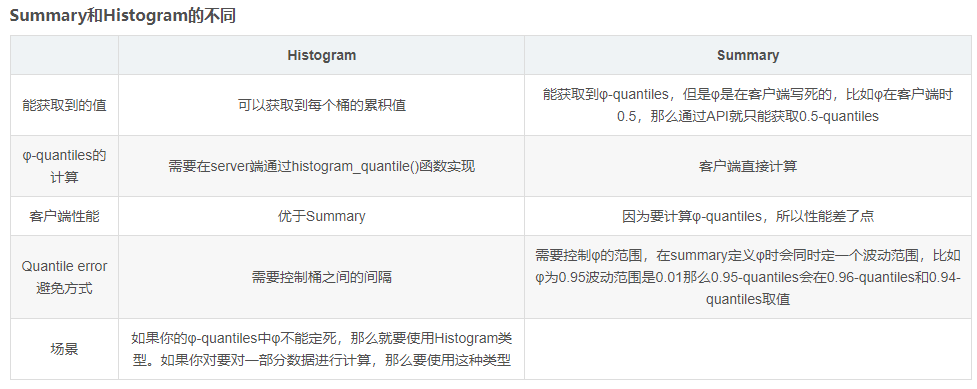
histogram 和 summary 的异同
它们都包含了 _sum 和 _count 指标,Histogram 需要通过 _bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
- https://blog.csdn.net/u014686399/article/details/103068655
Job and Instances
通常一个 instance 对应一个进程,一个 job 包含多个采集。
For example, an API server job with four replicated instances:
- job: api-server
- instance 1: 1.2.3.4:5670
- instance 2: 1.2.3.4:5671
- instance 3: 5.6.7.8:5670
- instance 4: 5.6.7.8:5671