本文将带你通过查看 Elasticsearch 源码来了解磁盘使用阈值在达到每个阶段的处理情况。
跳转文章末尾获取答案

环境
本文使用 Macos 系统测试,512M 的磁盘,目前剩余空间还有 60G 左右,所以按照 Elasticsearch 的设定,ES 中分片应该是无法分配的。
- MacOS 14.1.1
- Elasticsearch 8.1 源码启动
启动的源码已经上传 GitHub:https://github.com/zuiyu-main/elasticsearch

一、场景复现
1.1、启动 Elasticsearch
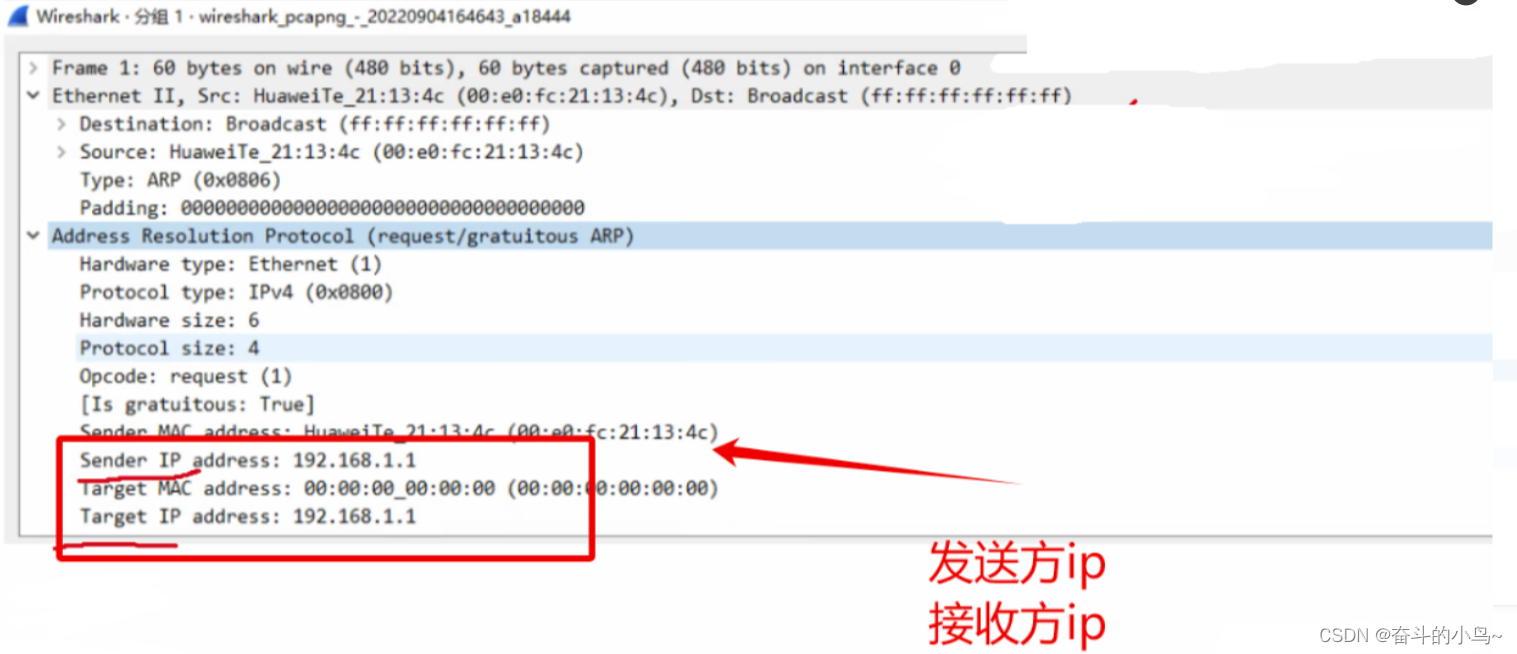
打印日志中出现如下提示:已经超过95%的洪水水位设置,当前节点的全部索引都将是只读状态。
[2024-02-28T21:55:08,682][WARN ][o.e.c.r.a.DiskThresholdMonitor] [node-1] flood stage disk watermark [95%] exceeded on [t5hKtM6PT3amCCT7xzqgMg][node-1][/cxt/codework/github/elasticsearch/8.1/home/data] free: 15gb[3.2%], all indices on this node will be marked read-only
1.2、当前节点索引状态
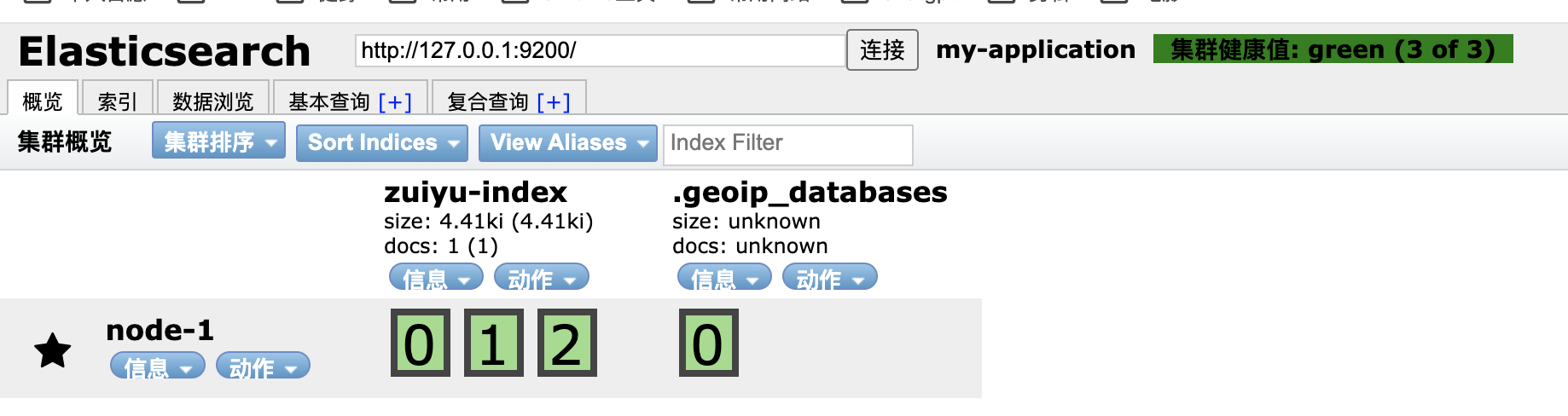
可以看到,当前 Elasticsearch 集群是单节点,且只有一个普通索引与一个geo的索引。
1.3、发送创建索引请求
发送 http 请求,创建一篇文档,如果当前索引不存在时自动创建索引。
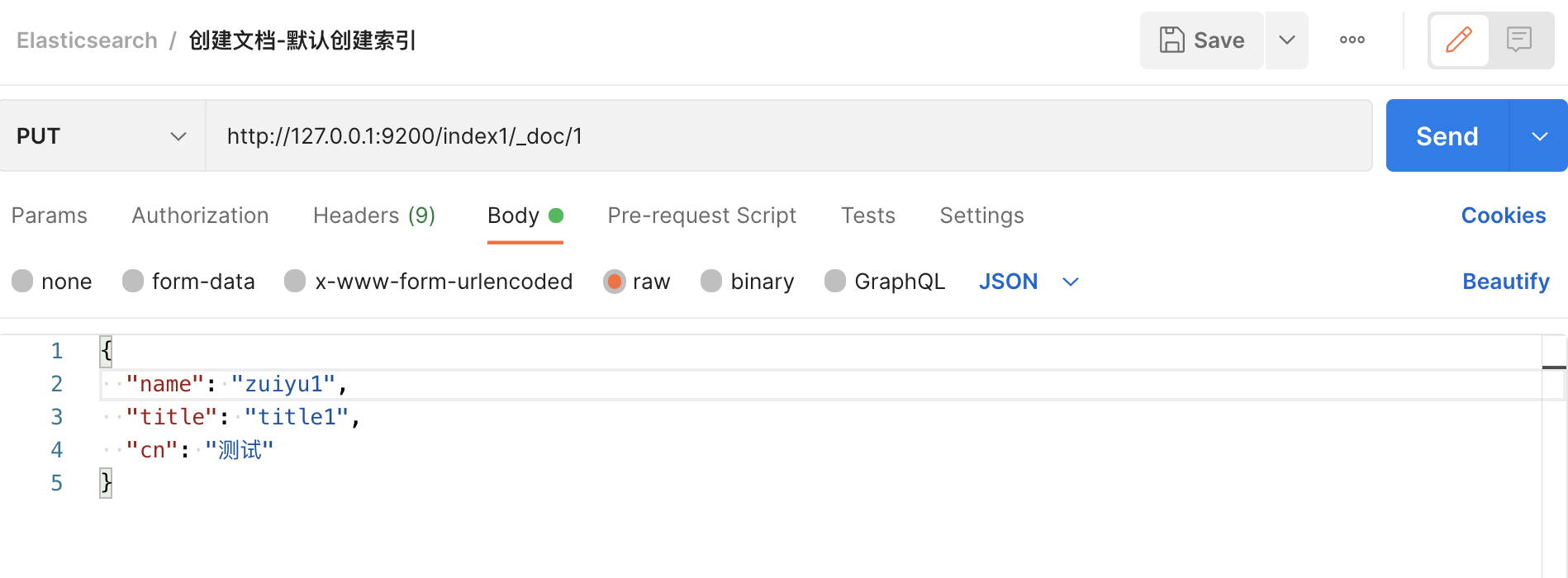
http://127.0.0.1:9200/index1/_doc/1{"name": "zuiyu1","title": "title1","cn": "测试"
}
1.4、查看日志输出
提示集群健康状态从黄色变为红色,磁盘已经超过洪水水位 95%。
[2024-02-28T22:01:55,921][INFO ][o.e.c.r.a.AllocationService] [node-1] current.health="RED" message="Cluster health status changed from [YELLOW] to [RED] (reason: [auto-create])." previous.health="YELLOW" reason="auto-create"
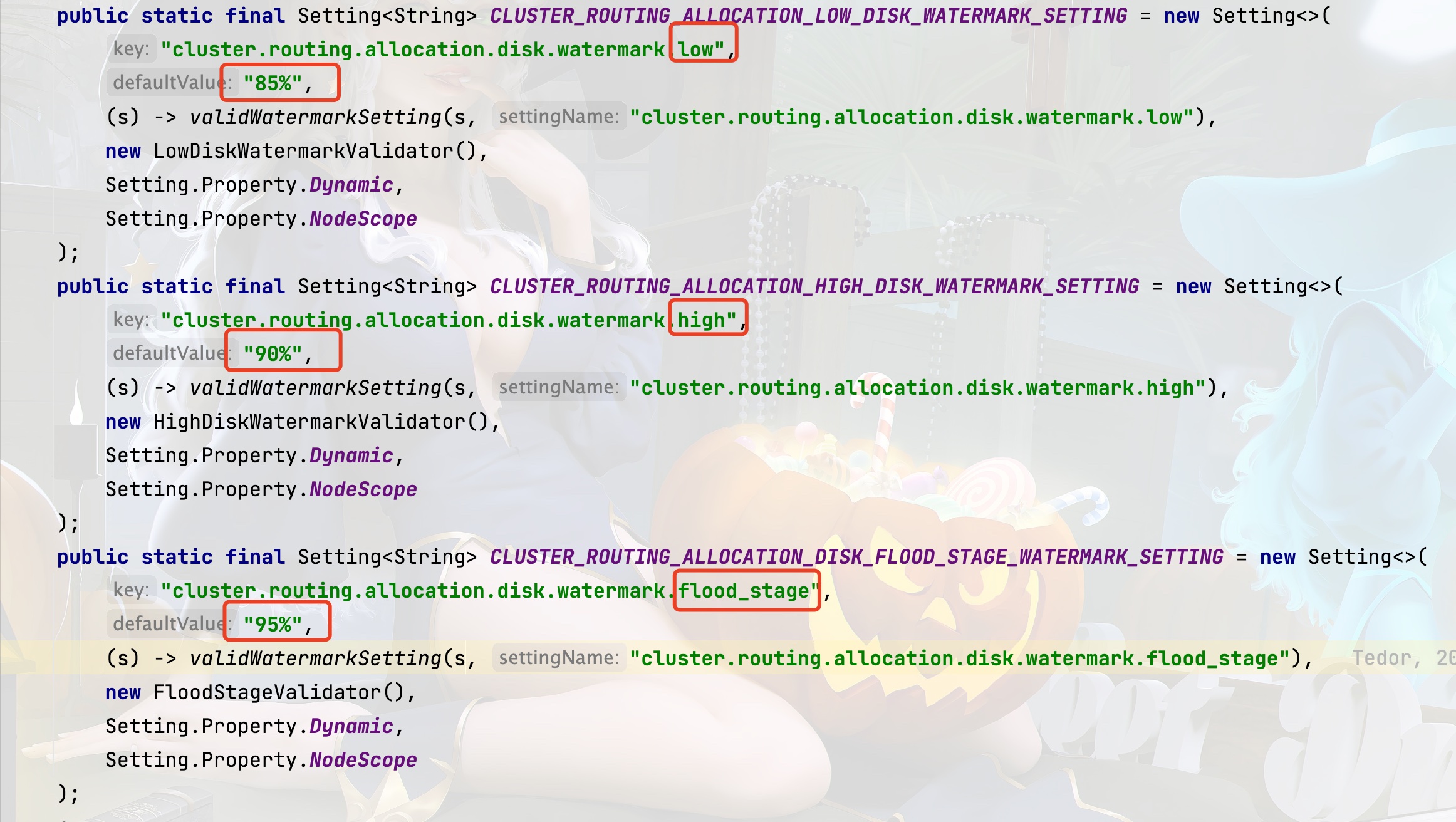
[2024-02-28T22:02:08,996][WARN ][o.e.c.r.a.DiskThresholdMonitor] [node-1] flood stage disk watermark [95%] exceeded on [t5hKtM6PT3amCCT7xzqgMg][node-1][/cxt/codework/github/elasticsearch/8.1/home/data] free: 14.9gb[3.2%], all indices on this node will be marked read-only源码中关于水位相关的三个参数默认值见下图。
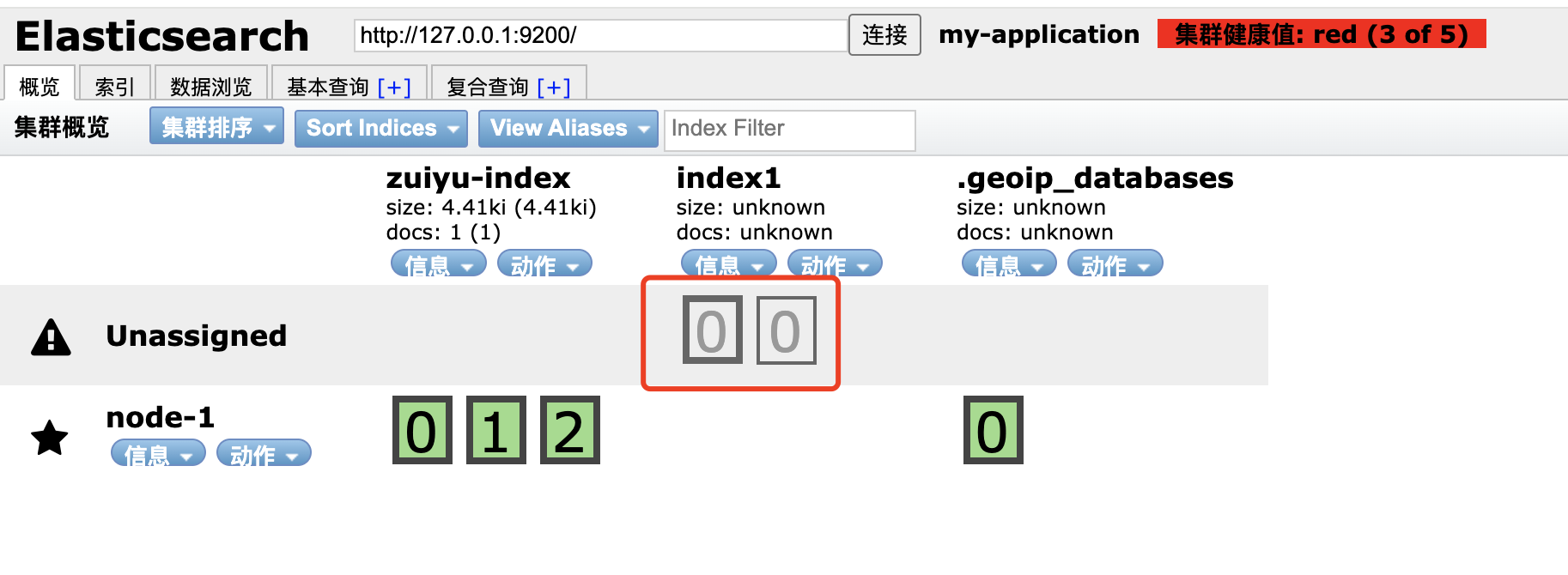
1.5、查看索引分片状态
通过查看当前集群索引状态,可以看出,我们刚刚新增的索引 index1 分片是没有进行分配的。
到了这,还记得我们的问题吗,就是说 Elasticsearch 是怎么判定的磁盘超出设定的阈值的呢?既然复现了我们的场景,下面就让我们一起去源码中查找答案吧。
二、源码中获取答案
2.1、定位代码位置
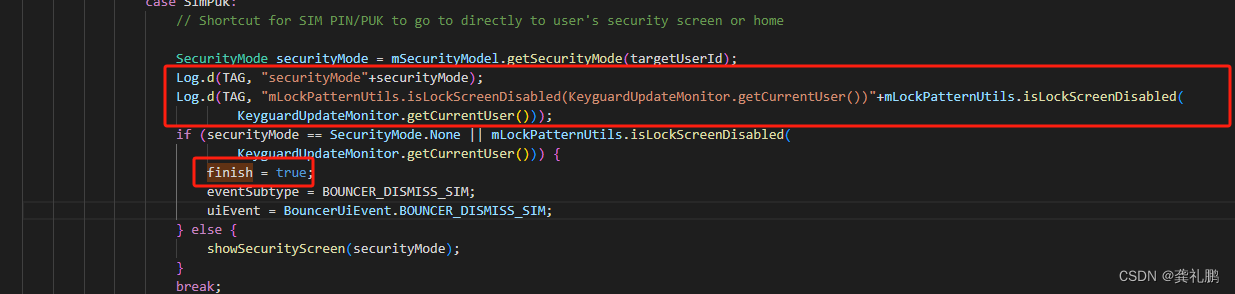
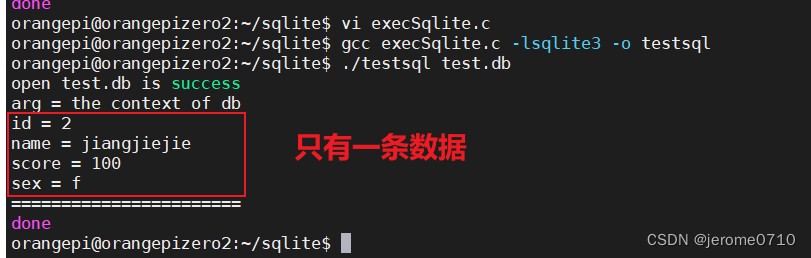
首先我们还是根据打印的日志,定位到输出这行日志的类,也就是DiskThresholdMonitor,然后根据打印日志中的关键字flood stage disk watermark,可以看到,当前类中出现了两次,根据日志打印的其他信息不难发现,对于此处就是205行。
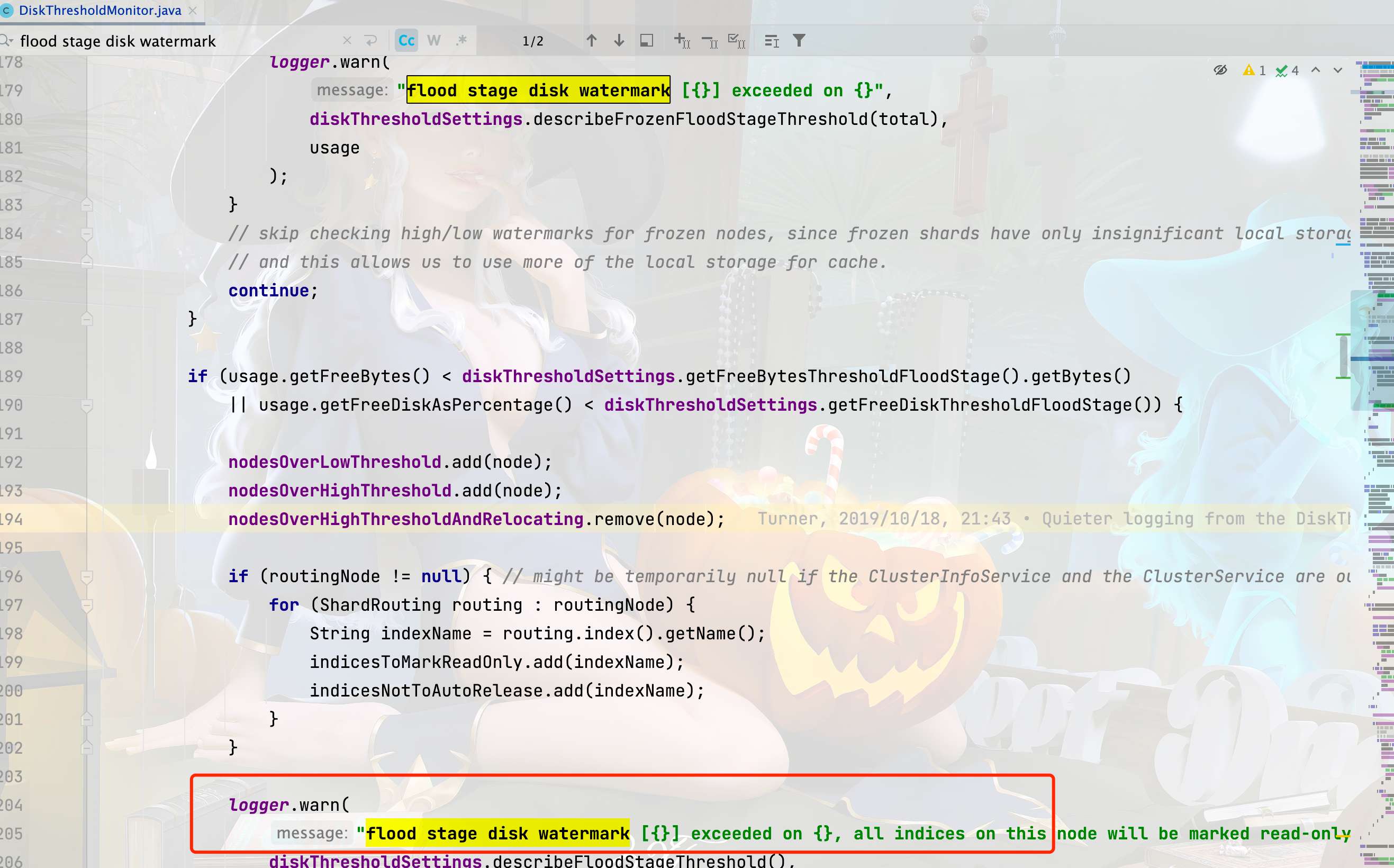
2.2、跟踪代码获取值
顺着这句代码往上走,看到 189 行有个 if 判断,相信就是这了,我的感觉来了,没想到这个找起来这么简单。
下面我们逐个参数进行分析。
usage.getFreeBytes()
进入 getFreeBytes 这个方法,在本类搜索 freeBytes ,找到 set 此参数的位置或者构造函数给值的位置
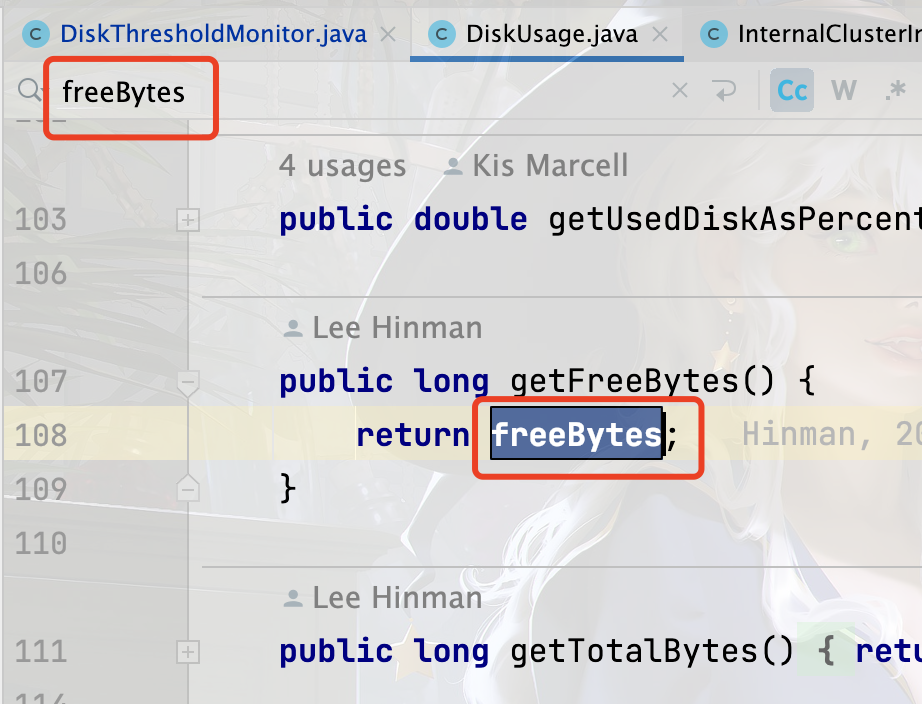
往上看到是在 39 行的 DiskUsage 方法中设定的值,那么我们在 37 行方法的开头打一个断点,重启之后,进入断点之后的值如下。

然后在看左下角的 debugger 处,此处就是我们的调用栈。
是的你没猜错,通过这个位置你就可以知道是哪个方法调用的这,我们点一下fillDiskUsagePerNode。
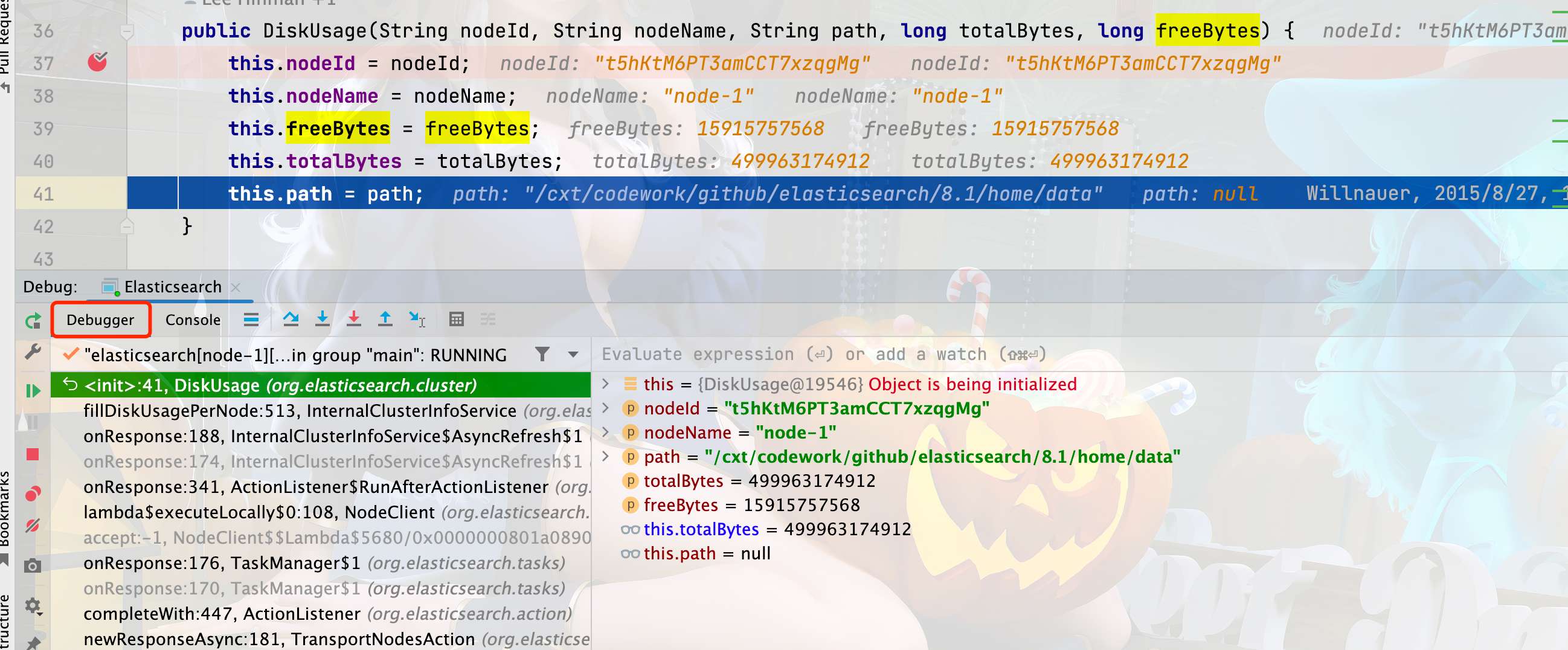
就进入了 InternalClusterInfoService 的 fillDiskUsagePerNode 处,从这基本就可以看出来 usage.getFreeBytes()就是获取了当前磁盘的可用空间。
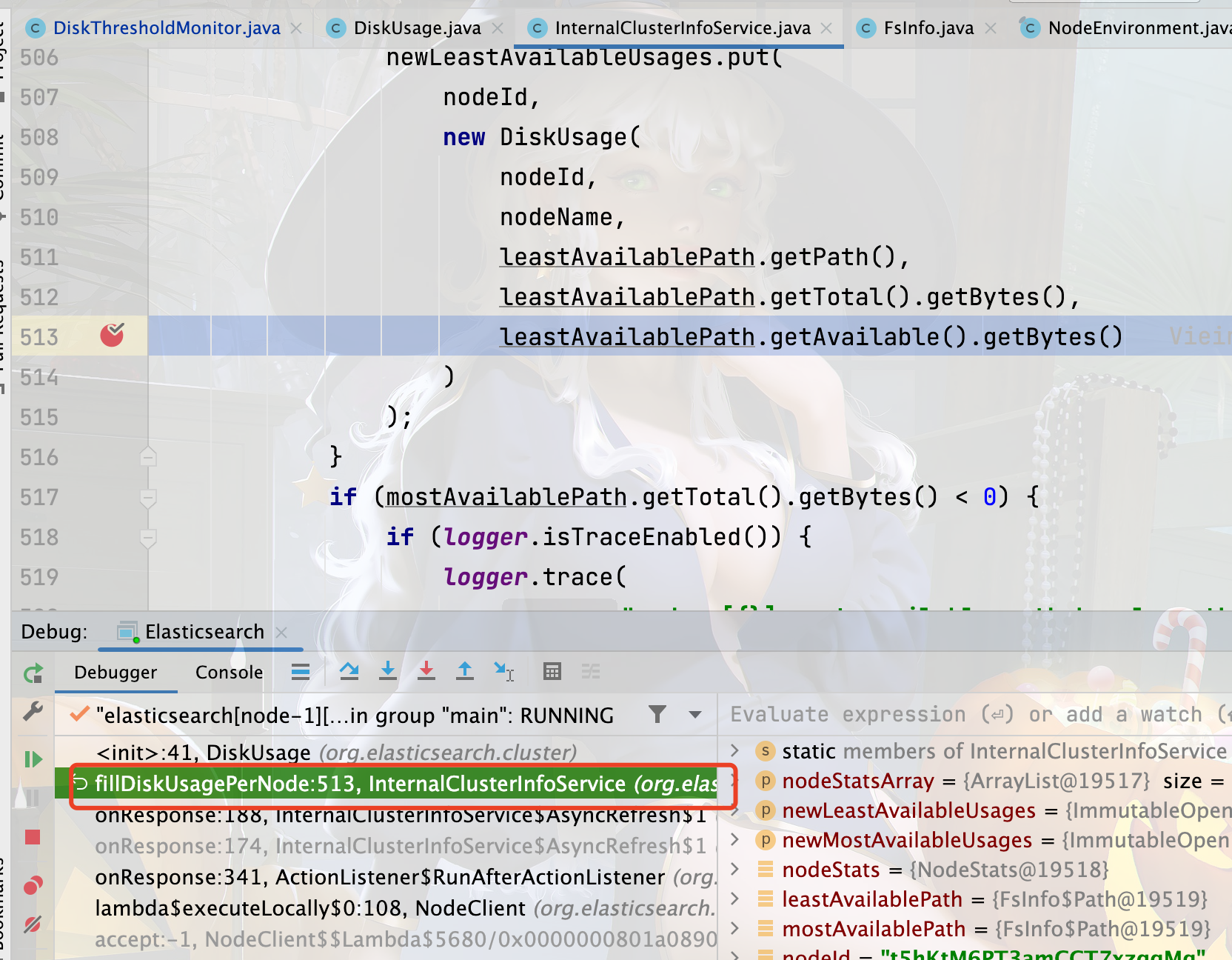
顺着代码往上走,就可以找到在哪里给leastAvailablePath赋值的地方了,感兴趣的可以按照此方法找一下。
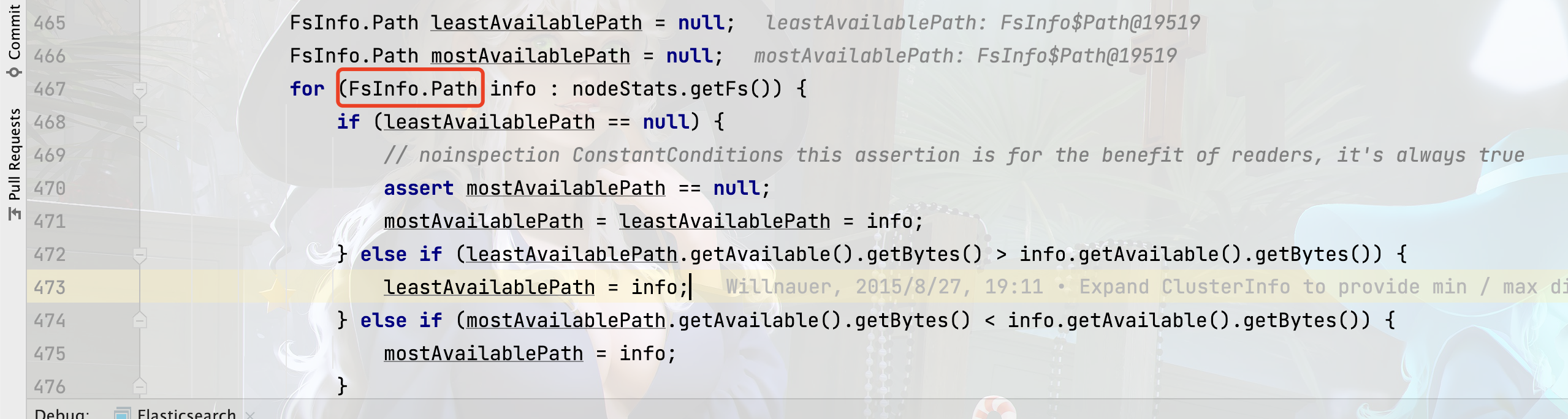
按照上面该方法,继续查询剩下三个参数的值。
diskThresholdSettings.getFreeBytesThresholdFloodStage().getBytes()
获取当前系统磁盘可用空间洪水水位阈值。
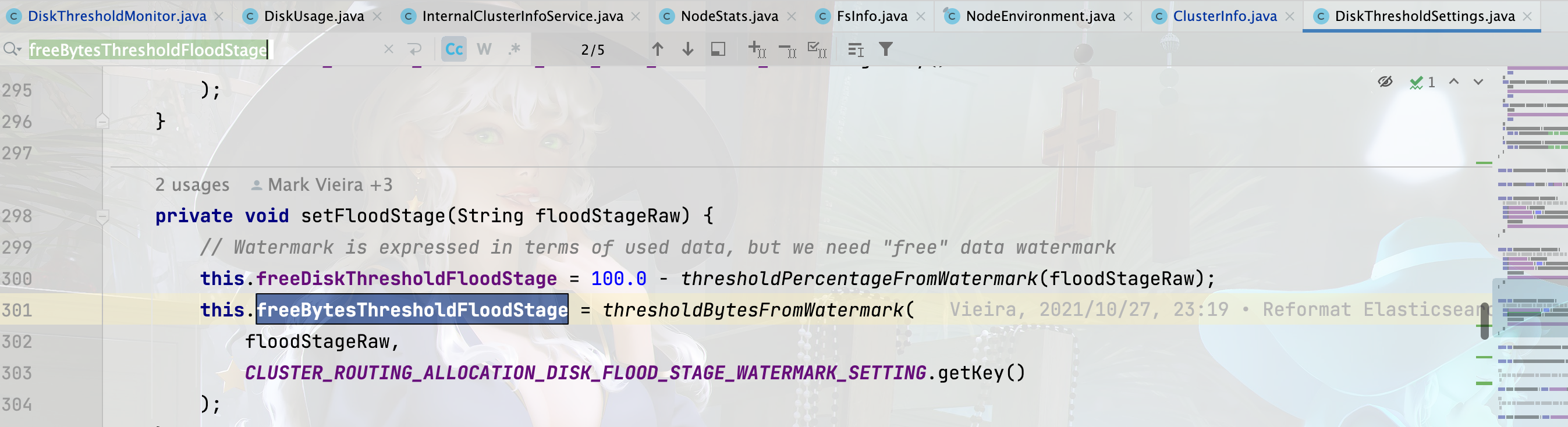
usage.getFreeDiskAsPercentage()
获取磁盘可用空间占用总磁盘空间的百分比。
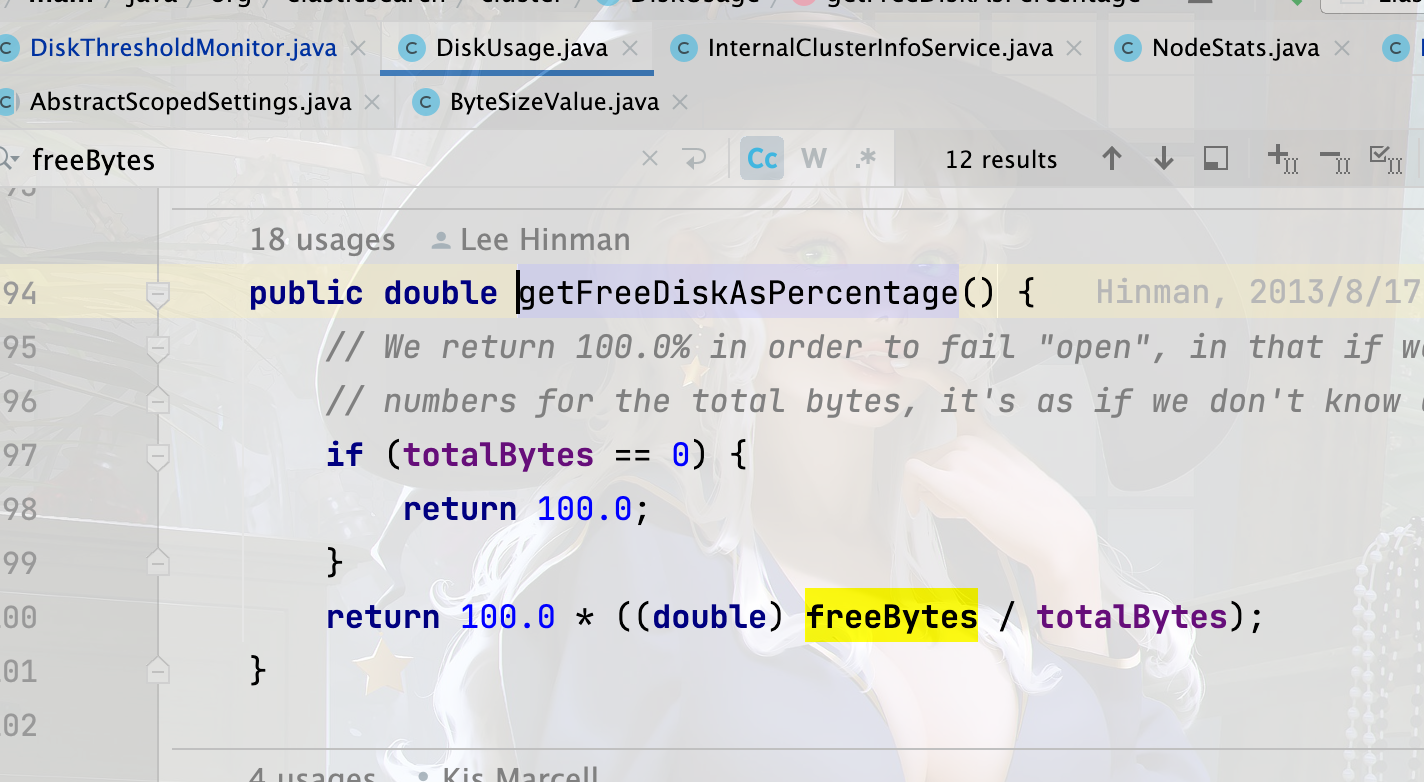
diskThresholdSettings.getFreeDiskThresholdFloodStage()
根据洪水阈值百分比阈值设置,获取当前磁盘可用空间占用总磁盘空间的百分比。

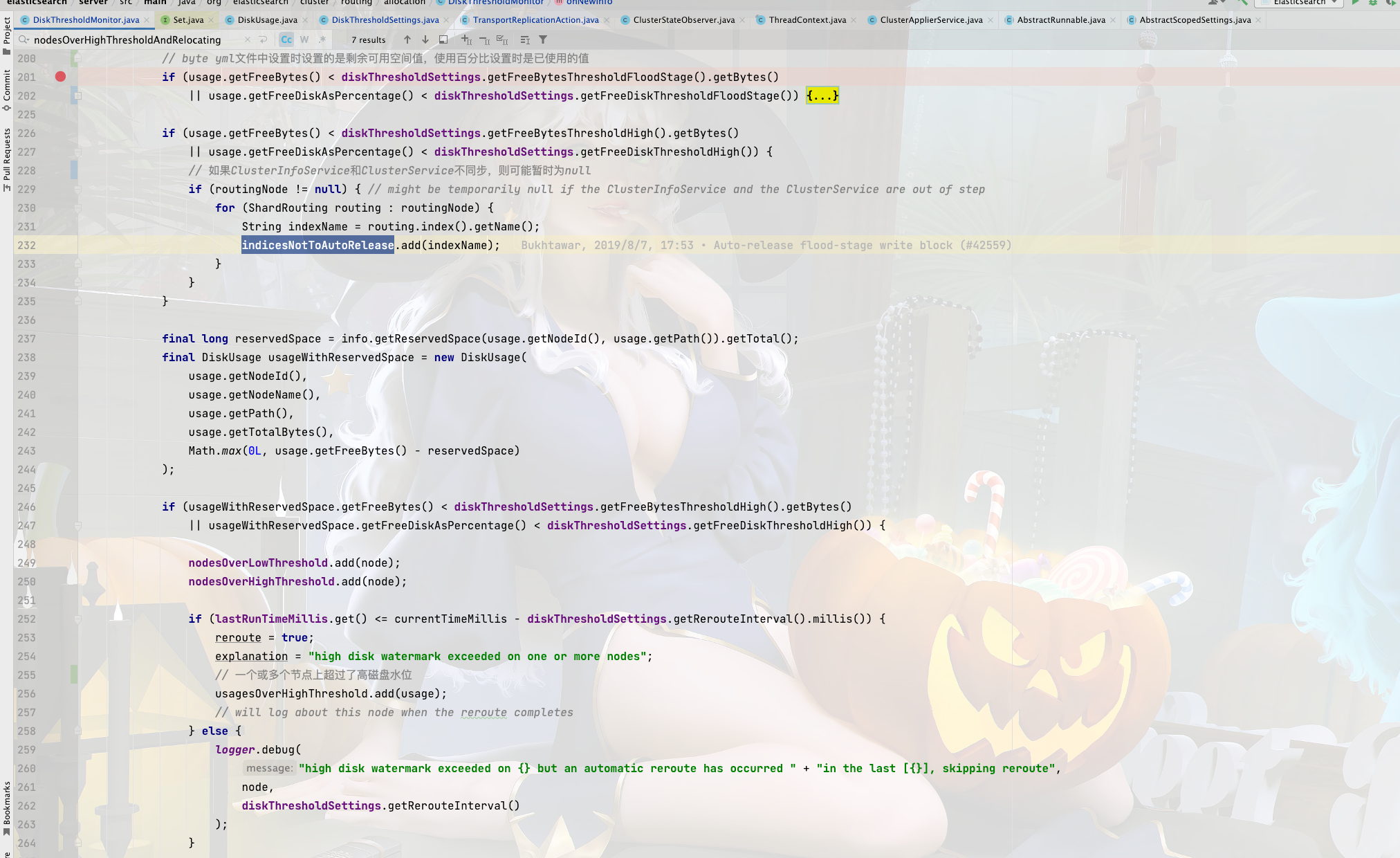
2.3、逻辑判断
其实上面的代码很简单就是一个 if-else ,所以我们很轻松的就看到了判断逻辑:
当磁盘可用空间 小于 设定的可用磁盘空间洪水水位阈值时(byte)或者磁盘可用空间占用总磁盘的百分比 小于 设定的可用空间占用总磁盘的百分比(double)阈值。
对于百分比不了解的看下图。
可用空间百分比 = 100 - 洪水水位阈值设定的百分比(已用空间占用百分比)

需要注意的是:我们可以看到
if判断是两个或条件,支持byte与double两种形式,但是yml文件中指定值时需要固定一种格式,都是百分比形式或者都是byte形式。byte是可用磁盘空间,double是已用磁盘空间。
cluster.routing.allocation.disk.watermark.low: 400g
cluster.routing.allocation.disk.watermark.high: 350g
cluster.routing.allocation.disk.watermark.flood_stage: 10g// 两种配置形式固定一种cluster.routing.allocation.disk.watermark.low: 85%
cluster.routing.allocation.disk.watermark.high: 90%
cluster.routing.allocation.disk.watermark.flood_stage: 95%
对于另外的两个参数
cluster.routing.allocation.disk.watermark.high与cluster.routing.allocation.disk.watermark.low,也可以按照上述方式查找。
下面我们就一起来看看 Elasticsearch 对这些值做了判断之后究竟做了什么
?
源码图中的注释来源于翻译,未修正,仅供参考
low

默认 85%,也就是说 Elasticsearch 不会将分片分配给超过 85% 的节点。
该设置对新创建的索引主分片不生效,只会影响副本分片的分配。
high
默认 90%,Elasticsearch 会将磁盘使用率高于 90% 的节点上的分片重新分配。
不管之前分片是否分配过,该设置会影响所有分片的分配。
flood
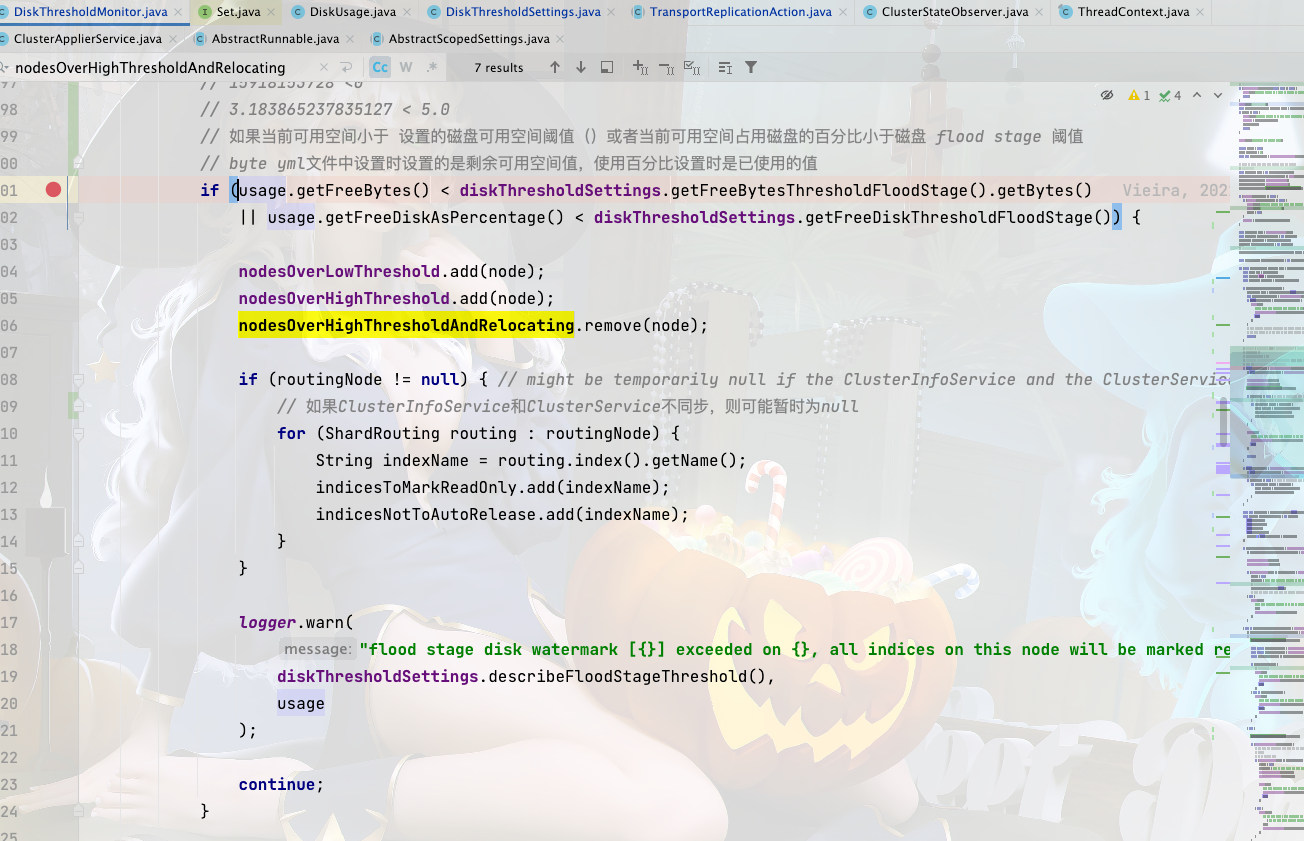
默认 95%,Elasticsearch 会将磁盘使用率超过 95%节点上的分片设置为只读索引。
防止磁盘空间耗尽最后的手段。当磁盘低于
high水位时,索引块自动释放。
官网中是这样说的。

三、总结
通过上面的实验,我们知道了当磁盘水位达到low阈值时,对于新创建的索引主分片不影响,副本分片受影响;当磁盘水位达到high时,会影响所有分片的分配;当磁盘水位达到flood时,会将所有的索引设置为只读。
对于上面的分片未分配的可以查看历史文章
索引分片未分配解决
Reroute Api 使用
索引分片分配策略
对于 Elasticsearch 中怎么设置索引为只读的?如何取消主分片、副本分片分配的?
感觉写的还可以欢迎点个关注,后面为你揭秘。
如果写的有误,欢迎指出,你的建议就是大家前进的动力。
四、参考链接
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cluster.html#disk-based-shard-allocation
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cluster.html