SparkUnit
Function:用于获取Spark Session
package com.example.unitlimport org.apache.spark.sql.SparkSessionobject SparkUnit {def getLocal(appName: String): SparkSession = {SparkSession.builder().appName(appName).master("local[*]").getOrCreate()}def getLocal(appName: String, supportHive: Boolean): SparkSession = {if (supportHive) getLocal(appName,"local[*]",true)else getLocal(appName)}def getLocal(appName:String,master:String,supportHive:Boolean): SparkSession = {if (supportHive) SparkSession.builder().appName(appName).master(master).enableHiveSupport().getOrCreate()else SparkSession.builder().appName(appName).master(master).getOrCreate()}def stopSs(ss:SparkSession): Unit ={if (ss != null) {ss.stop()}}
}log4j.properties
Function:设置控制台输出级别
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
KTV
Function:读取kudu,写入hive。Kudu_To_Hive,简称KTV
package com.example.daoimport com.example.unitl.SparkUnit
import org.apache.spark.sql.SparkSessionobject KTV {def getKuduTableDataFrame(ss: SparkSession): Unit = {// 读取kudu// 获取tb对象val kuduTb = ss.read.format("org.apache.kudu.spark.kudu").option("kudu.master", "10.168.1.12:7051").option("kudu.table", "impala::realtimedcs.bakup_db") // Tips:注意指定库.load()// create viewkuduTb.createTempView("v1")val kudu_unit1_df = ss.sql("""|SELECT * FROM `sources_tb1`|WHERE `splittime` = "2021-07-11"|""".stripMargin)// printkudu_unit1_df.printSchema()kudu_unit1_df.show()// load of memorykudu_unit1_df.createOrReplaceTempView("v2")}def insertHive(ss: SparkSession): Unit = {// create tabless.sql("""|USE `bakup_db`|""".stripMargin)ss.sql("""| CREATE TABLE IF NOT EXISTS `bak_tb1`(| `id` int,| `packtimestr` string,| `dcs_name` string,| `dcs_type` string,| `dcs_value` string,| `dcs_as` string,| `dcs_as2` string)| PARTITIONED BY (| `splittime` string)|""".stripMargin)println("创建表成功!")// create viewss.sql("""|INSERT INTO `bakup_db`|SELECT * FROM bak_tb1|""".stripMargin)println("保存成功!")}def main(args: Array[String]): Unit = {//get ssval ss = SparkUnit.getLocal("KTV", true)// 做动态分区, 所以要先设定partition参数// default是false, 需要额外下指令打开这个开关ss.sqlContext.setConf("hive.exec.dynamic.partition;","true");ss.sqlContext.setConf("hive.exec.dynamic.partition.mode","nonstrict");// 调用方法getKuduTableDataFrame(ss)insertHive(ss)// 关闭连接SparkUnit.stopSs(ss)}
}
运行:
运行时请将hive的配置文件 hive-site.xml文件,复制到项目resource下。
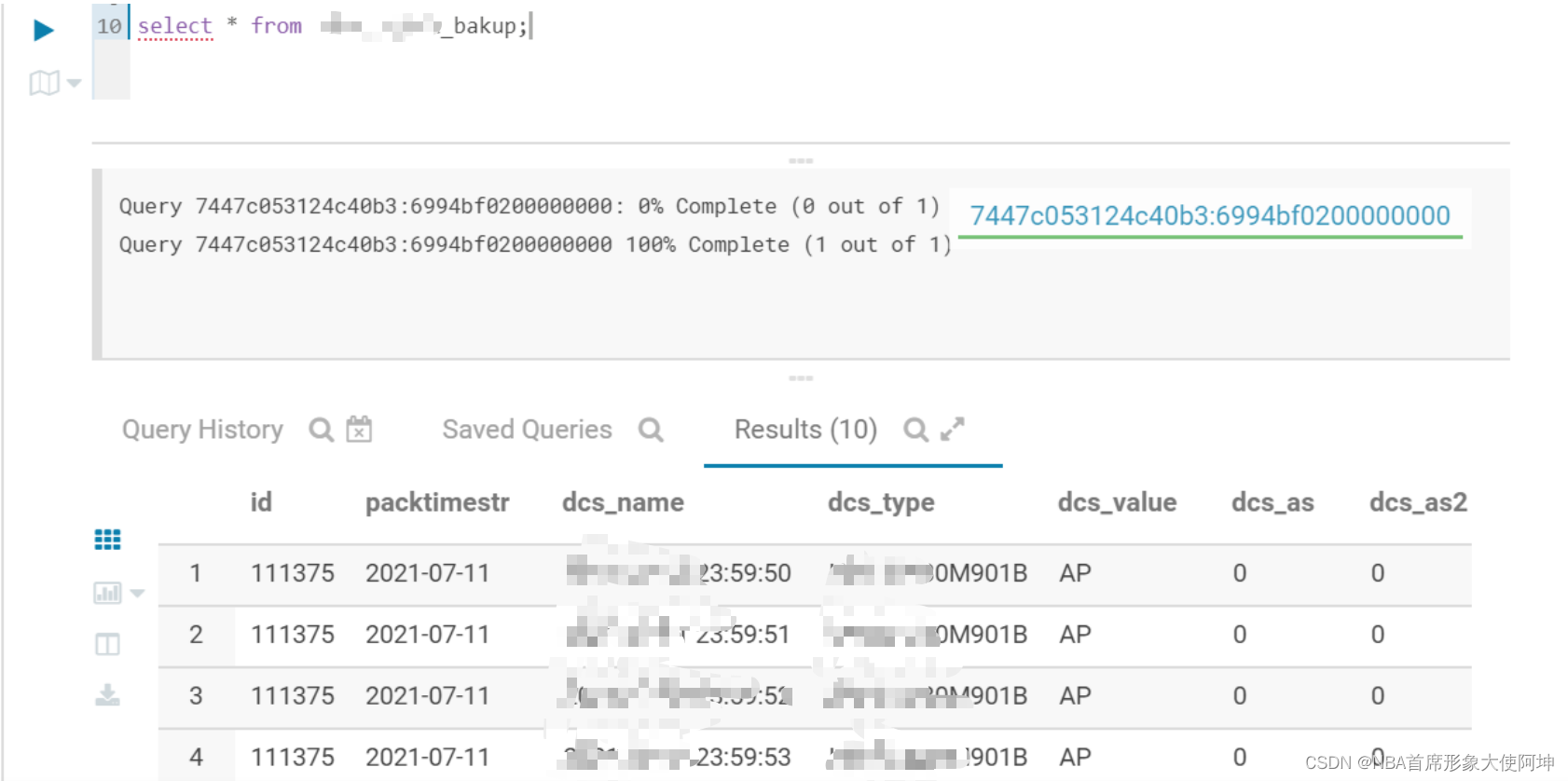
hue查看写入的数据: