Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
大数据 - Spark系列《八》- 闭包引用-CSDN博客
大数据 - Spark系列《九》- 广播变量-CSDN博客
大数据 - Spark系列《十》- rdd缓存详解-CSDN博客
大数据 - Spark系列《十一》- Spark累加器详解-CSDN博客
大数据 - Spark系列《十二》- 名词术语理解-CSDN博客
目录
13.1. 构造并初始化SparkContext
13.2 创建RDD构建DAG
13.3 触发行动算子
13.4 切分Stage,生成Task和TaskSet
13.5 提交stage-Stage的创建过程
🥙finalStage(ResultStage)
🥙父stage(ShuffleMapStage)
13.6 在Executor中执行Task
🥙ResultTask
🥙ShuffleMapTask
13.7 job执行全流程关键步骤总结
13.1. 构造并初始化SparkContext
用户主类的 main 方法中首先初始化 SparkContext,这会创建 DagScheduler 和 TaskScheduler,并为与 Executor 通信创建后端。
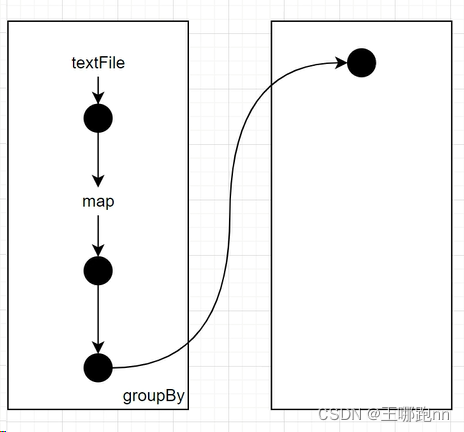
13.2 创建RDD构建DAG
-
原始的RDD通过一系列的转换形成有向无环图(DAG),根据RDD之间的依赖关系划分成不同的 Stage。
-
窄依赖的RDD操作在同一个Stage中进行计算,而宽依赖需要等待父Stage处理完成后才能开始计算。
13.3 触发行动算子
-
用户代码中的行动算子触发了 Spark 作业的执行。
-
SparkContext 的
runJob()方法被调用,开始调度作业。
13.4 切分Stage,生成Task和TaskSet

-
DAGScheduler根据作业的RDD依赖关系切分Stage,生成不同的Stage对象。
-
每个Stage对象中最关键的属性是最后一个RDD,将来生成的Task将使用此RDD的迭代器执行整个迭代器链。
13.5 提交stage-Stage的创建过程
1. 首先,DAGScheduler会将上一步(划分stage)得到finalStage,拿去提交task
2. 提交逻辑会检查当前要提交的stage是否还有未提交的父stage,如果有,就得先提交父stage!
🥙finalStage(ResultStage)
🥙父stage(ShuffleMapStage)

13.6 在Executor中执行Task
Executor收到Task对象并反序列化后,会将Task包装成一个TaskRunner类以便放入线程池执行;
🥙ResultTask
🥙ShuffleMapTask

而线程执行时,调用的就是Task的runTask方法,而runTask方法中,拿到这个task的rdd的迭代器,然后将迭代器传入一个ShuffleWriter.write(records)!
而shuffleWriter.write方法中,就是开始“迭代”这个迭代器

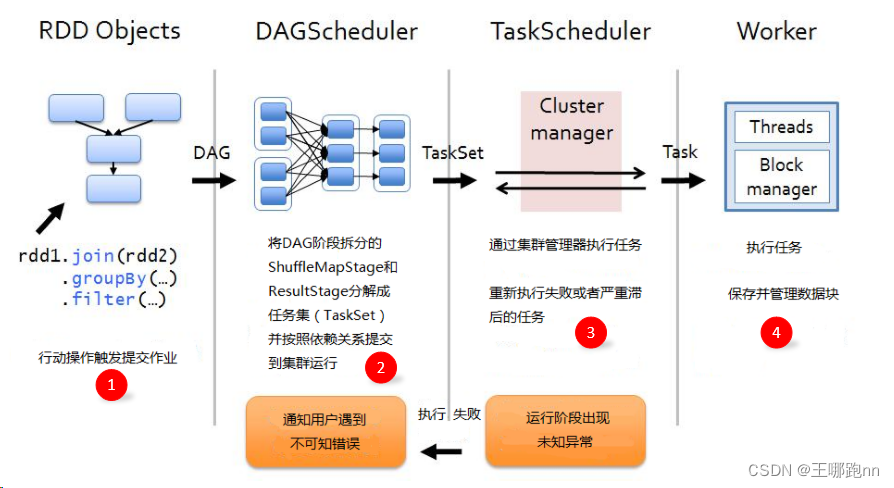
13.7 job执行全流程关键步骤总结
-
spark任务是通过行动算子触发执行的 ,在每个行动算子中都有sc.runjob方法 ;
foreach()行动算子-> sc.runJob() // 在SparkContext中执行作业-> dagScheduler.runJob() // DAG调度器执行作业
dagScheduler的runJob()—> submitJob()// 提交作业dagScheduler的submitJob()-> eventProcessLoop.post(JobSubmitted) // 发送作业提交事件 DAGSchedulerEventProcessLoop收到消息->doOnReceive()
DAGSchedulerEventProcessLoop的doOnReceive()-> dagScheduler.handleJobSubmitted DagScheduler的handleJobSubmitted方法-> finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite) // 根据finalRDD创建finalStage-> submitStage(finalStage) // 递归提交,永远是先从前面的stage开始提交submitStage()-> submitMissingTasks(stage, jobId.get)
submitMissingTasks方法-> 把stage的finalRDD信息序列化后广播给每个executor-> 根据要提交的stage的类型,以及需要计算的分区个数,生成相应类型相应个数的Task对象-> taskScheduler.submitTasks(new TaskSet(tasks.toArray,stage.id,job.id...))
TaskSchedulerImpl.submitTasks-> 将task对象序列化,发给executor-> task发给executor,也是有调度策略的:FIFOExecutor收到task对象,就反序列化
并将反序列化出来的task对象封装到一个TaskRunner对象中
然后把这个TaskRunner对象放入线程池执行
TaskRunner的run方法,就是调task对象的runTask方法
task对象的runTask方法就要看是哪种task了(shuffleMapTask,resultTask)
shuffleMapTask的runTask方法中,调ShuffleWriter.write(finalRDD.iterator)
ShuffleWriter.write(iterator)具体实现,要看是哪一种ShuffleWriter实现类while(iterator.hasNext)kv = iterator.next// 不同实现类的不同之处就在后续将kv放到哪里去缓存,以及缓存满了以后怎么溢出





![[HackMyVM]Quick 2](https://img-blog.csdnimg.cn/direct/c64b2edd06bb4045b64f0a577999b0ae.png)