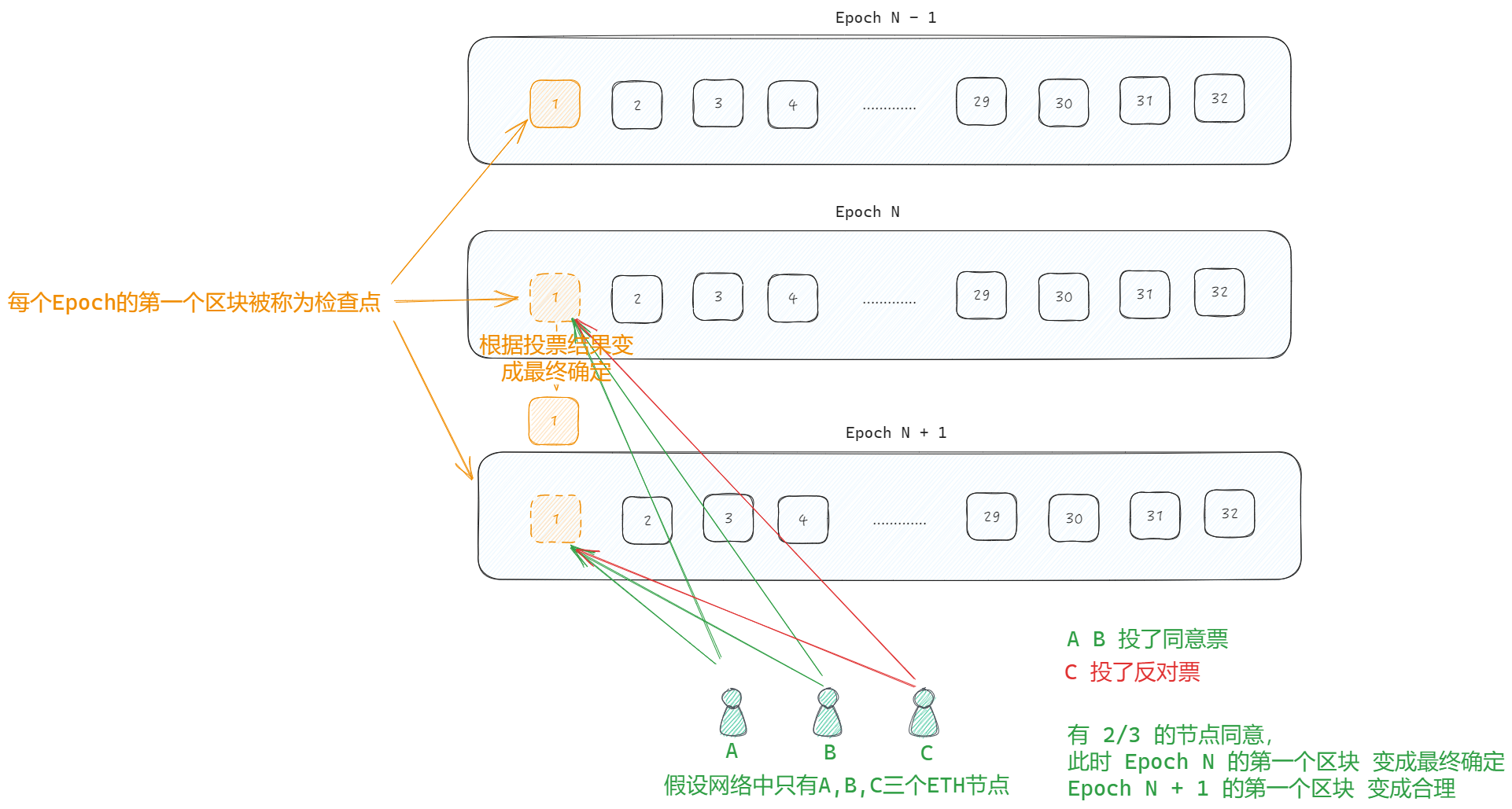
零.实现目标
爬取视频网站视频
视频网站你们随意,在这里我选择飞某速(狗头保命)。
例如,作者上半年看过的“铃芽之旅”,突然想看了,但是在正版网站看要VIP,在盗版网站看又太卡了,没办法,那只好祭出我们的白嫖大法了(狗头保命)
一.准备工作
1.打开网址
我们先用谷歌浏览器,找到我们的铃芽之旅的网址:
铃芽之旅 百度云网盘_在线播放-70看看
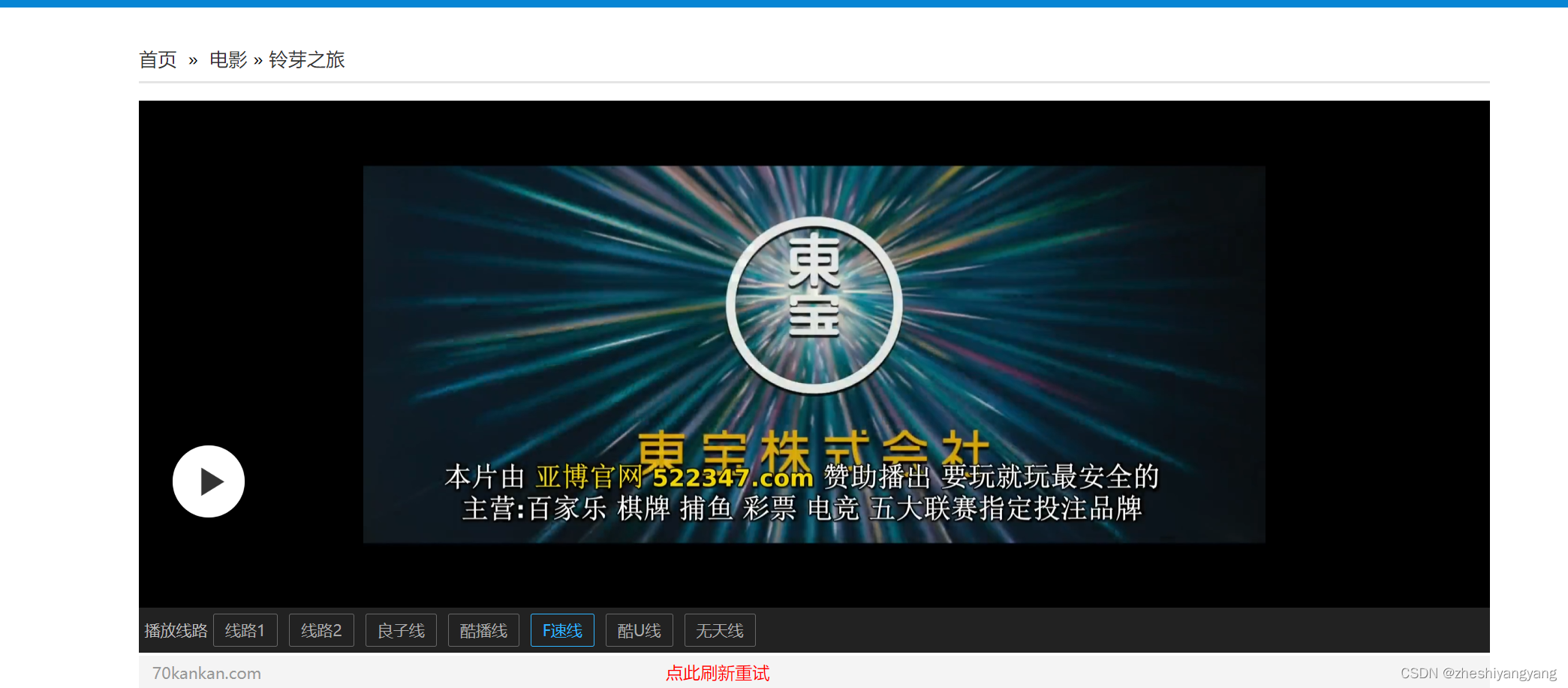
进入之后,是介个样子的:
2.寻找视频文件
右键页面空白处,找到我们的检查,进入开发者工具,点击Network(网络)。
(不过这个网址有点针对我们,右键不了,我们使用"shift + ctrl + i"快捷键打开)

点击我们的Fetch/XHR

可以看到有.m3u8后缀文件也有.ts文件,小伙伴可能会说,这都是啥啊我也看不懂,不要急我们先来科普一下:
2.1什么是TS文件
TS(Transport Stream,传输流)是一种封装的格式,它的全称为MPEG2-TS。MPEG2-TS是一种标准数据容器格式,传输与存储音视频、节目与系统信息协议数据,主要应用于数字广播系统,譬如DVB、ATSC与IPTV
2.2什么是.m3u8文件
.m3u8文件一般与.ts文件同时出现,主要记录.ts文件的索引,即某一个.ts文件对应视频中的某一段时间,而所有的.ts文件合并在一起就是一整个视频啦。
我们观察两个.m3u8文件,进入它们的预览,查看谁的格式是对的,如下图所示:

这种格式就代表是准确的.m3u8文件。
此时,我们已经找到了需要的.m3u8文件,我们开始分析这个m3u8文件。
2.3分析.m3u8文件
首先我们要先查看文件的URL,我们查看它的请求头可以发现,并不需要我们修改什么,我们只需要赋值一整串即为我们需要的URL。

接下来,我们需要查看我们在后续爬虫中需要构造的headers,也就是请求头:

通过分析查看,上述的所有请求头并不需要人为修改,并且在爬取过程中也不会动态变化。
为此,我们只需要将这些全部复制下来并构造成请求头即可。
三.构造爬取.m3u8文件代码
3.1获取.m3u8文件内容
通过第二步的分析,我们知道了URL和请求头,那还等什么,直接开始写代码吧!
import requests
import osdef get_ts_txt():#4请求URLurl = "https://s8.fsvod1.com/20230703/J6BHjLy3/1500kb/hls/index.m3u8"#请求头headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"}#创建get请求对象reponse = requests.get(url=url,headers=headers)#获取get请求对象的返回值get_txt = reponse.textprint(get_txt)if __name__ == "__main__":get_ts_txt()值得注意的是,我们在headers构造中,并没有用全在第二步寻找到的请求头元素,这是因为在一般情况下我们只使用“User-Agent”来反爬就能成功了,如果不成功,我们再加上嘛,又不浪费时间。
效果图:

可以看到内容极其杂乱,并且不利于后面的使用,为此我们需要分析并提取出有效信息,也就是.ts信息。
3.2提取.m3u8中有效信息
仔细看可以发现,每个.ts文件之后跟着一个“,”,为此我们可以使用正则表达式,来匹配出.ts文件名。
使用:“\b\w+\.ts\b”,即可匹配出对应的.ts文件。
为此,我们可以改下代码为如下格式:
import requests
import os
import redef get_ts_txt():#4请求URLurl = "https://s8.fsvod1.com/20230703/J6BHjLy3/1500kb/hls/index.m3u8"#请求头headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"}reponse = requests.get(url=url,headers=headers)get_txt = reponse.text#正则匹配出.ts后缀数据ts_files = re.findall(r"\b\w+\.ts\b",get_txt)#将.ts数据写入到文件中中with open("get_ts.txt","w") as file:for i in ts_files:i = i + "\n"file.write(i)print("获取ts文件成功.")return ts_filesif __name__ == "__main__":print(get_ts_txt())同时,我们还将对应的.ts文件名保存到一个.txt文件中,方便查看。
效果:


至此,我们已经成功获取所有.ts视频文件名了,接下来只需要构建对应的爬取代码下载即可啦~
四.构造爬取.ts文件代码
4.1分析.ts文件
我们在开发者工具中随便打开一个.ts文件(你也可以打开多个查看不同点),找到URL部分,例如我打开的这个:
![]()
通过打开多个.ts文件查看,可以发现所有的.ts文件的URL只有后缀是不同的,而后缀恰恰是这个.ts文件的名字,为此我们就可以构造爬取代码了。
4.2构造爬取.ts代码
在爬取.ts之前,我们先创建一个文件夹用来存放:
def create_filedir():path = os.getcwd() + "/爬取数据"if os.path.exists(path):print("\\爬取视频文件夹已存在,本次不创建.")else:os.mkdir(path)print("创建\\爬取文件夹成功.")通过这串代码可以轻松创建一个文件夹。
接下来,我们来构造爬取.ts代码:
def down_video(item):#对item进行解包,提取出ts文件和ts文件索引index,ts = item[0],item[1]#拼接文件序号if 0 <= index <=9:index = "000" + str(index)elif 10 <= index <= 99:index = "00" + str(index)elif 100 <= index <= 999:index = "0" + str(index)else:index = str(index)#爬取视频URLURL = "https://s8.fsvod1.com/20230703/J6BHjLy3/1500kb/hls/"#请求头headers = {"authority":"s8.fsvod1.com","method":"GET","path":f"/20221207/10692_4308abda/2000k/hls/{ts}","scheme":"https","Accept":r"*/*","Accept-Encoding":"gzip,deflate,br,zstd","Accept-Language":"zh-CN,zh;q=0.9","Origin":"https://test3.gqyy8.com:4438","Sec-Ch-Ua":'"Chromium";v="122","Not(A:Brand";v="24","Google Chrome";v="122"',"Sec-Ch-Ua-Mobile":"?0","Sec-Ch-Ua-Platform":"Windows","Sec-Fetch-Dest":"empty","Sec-Fetch-Mode":"cors","Sec-Fetch-Site":"cross-site","User-Agent":"Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/122.0.0.0Safari/537.36"}#拼接视频urlURL = URL + "/" + tstry:r = requests.get(url=URL,headers=headers,timeout=10)with open(f"{os.getcwd()}/爬取数据/" + index + ".ts", "wb") as file:file.write(r.content)except Exception as e:if not file_flag:fil_list.append([int(index),ts])print(index,"写入失败,原因",e,sep="->")returnprint(index,"写入成功.",sep="->")因为.ts文件是乱码且无序的,为此我们需要人为的给.ts文件按照下载的顺序进行重命名。
效果图:


在本次文章中,我们初步完成了怎么爬取一个.ts文件,下一章我们讲解怎么一次性爬取所有的.ts文件。
好了,我们先讲到这里,后面请期待:“爬虫实战第三例【三】【下】”
地址是:Python爬虫实战第三例【三】(下)-CSDN博客