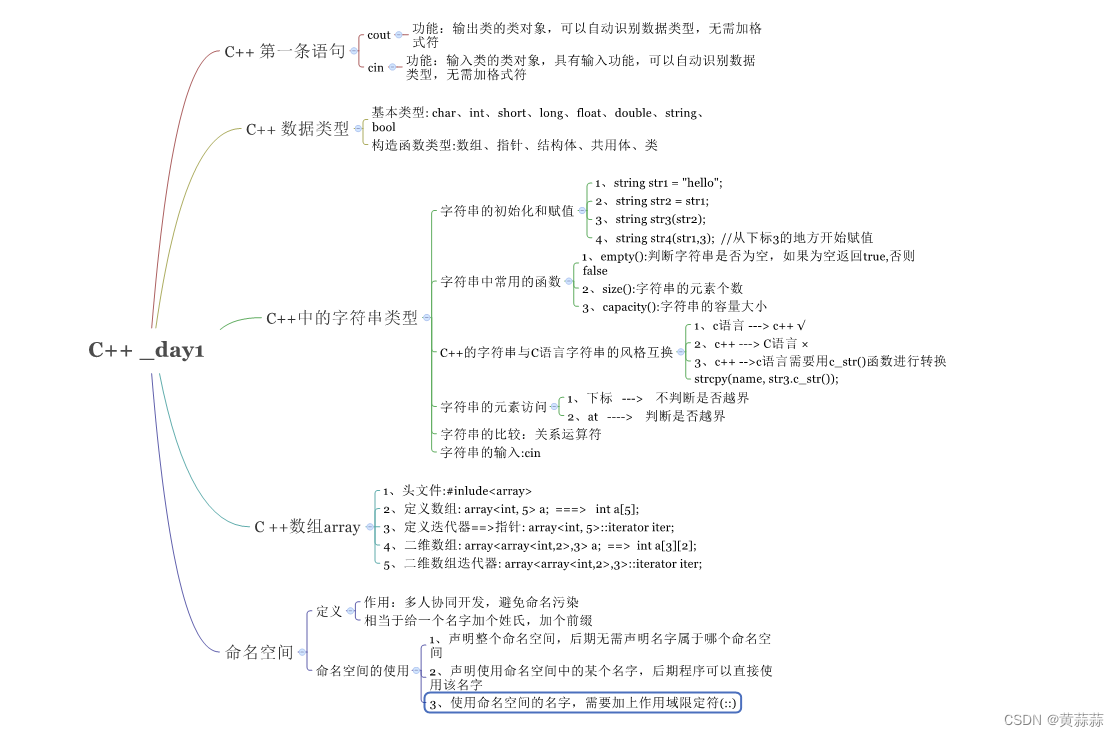
第二章 Linux 多进程开发
- 2.1 进程概述
- 2.2 进程状态转换
- 2.3 进程创建
- 2.4 exec 函数族
- 2.5 进程控制
网络编程系列文章:
第1章 Linux系统编程入门(上)
第1章 Linux系统编程入门(下)
第2章 Linux多进程开发(上)
第2章 Linux多进程开发(下)
第3章 Linux多线程开发
第4章 Linux网络编程
- 4.1 网络基础
- 4.2 socket 通信基础
- 4.3 TCP套接字通信
- 4.4 IO多路复用
- 4.5 UDP 通信
第5章 Web服务器
2.1 进程概述
(1)程序和进程
程序是包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程:
-
二进制格式标识:每个程序文件都包含用于描述可执行文件格式的元信息。内核利用此信息来解释文件中的其他信息。(
ELF 可执行连接格式) -
机器语言指令:对程序算法进行编码。
-
程序入口地址:标识程序开始执行时的起始指令位置。
-
数据:程序文件包含的变量初始值和程序使用的字面量值(比如字符串)。
-
符号表及重定位表:描述程序中函数和变量的位置及名称。这些表格有多重用途,其中包括调试和运行时的符号解析(动态链接)。
-
共享库和动态链接信息:程序文件所包含的一些字段,列出了程序运行时需要使用的共享库,以及加载共享库的动态连接器的路径名。
-
其他信息:程序文件还包含许多其他信息,用以描述如何创建进程。
-
进程是正在运行的程序的实例。是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
-
可以用一个程序来创建多个进程,进程是由内核定义的抽象实体,并为该实体分配用 以执行程序的各项系统资源。从内核的角度看,进程由用户内存空间和一系列内核数 据结构组成,其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程状态信息。记录在内核数据结构中的信息包括许多与进程相关的标识号( IDs )、虚拟内存表、打开文件的描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
(2)单道、多道程序设计
- 单道程序,即在计算机内存中只允许一个的程序运行。
- 多道程序设计技术 是在计算机内存中同时存放几道相互独立的程序,使它们在管理程序控制下,相互穿插运行,两个或两个以上程序在计算机系统中同处于开始到结束之间的状态 , 这些程序共享计算机系统资源。引入多道程序设计技术的根本目的是为了提高 CPU 的利用率。
- 对于一个单 CPU 系统来说,程序同时处于运行状态只是一种宏观上的概念,他们虽然都已经开始运行,但就微观而言,任意时刻, CPU 上运行的程序只有一个。
- 在多道程序设计模型中,多个进程轮流使用 CPU 。而当下常见 CPU 为 纳秒级, 1 秒可以执行大约 10 亿条指令。由于人眼的反应速度是毫秒级,所以看似同时在运行。
(3)时间片
- 时间片(
timeslice)又称为“量子 (quantum)” 或 “处理器片 (processor slice)是操作系统分配给每个正在运行的进程微观上的一段 CPU 时间。事实上,虽然一台计算机通常可能有多个 CPU ,但是同一个 CPU 永远不可能真正地同时运行多个任务。在只考虑一个 CPU 的情况下,这些进程“看起来像”同时运行的,实则是 轮番穿插地运行,由于时间片通常很短(在 Linux 上为 5ms-800ms ),用户不会感觉到。 - 时间片由操作系统内核的调度程序分配给每个进程。首先,内核会给每个进程分配相等的初始时间片,然后每个进程轮番地执行相应的时间,当所有进程都处于时间片耗尽的状态时,内核会重新为每个进程计算并分配时间片,如此往复。
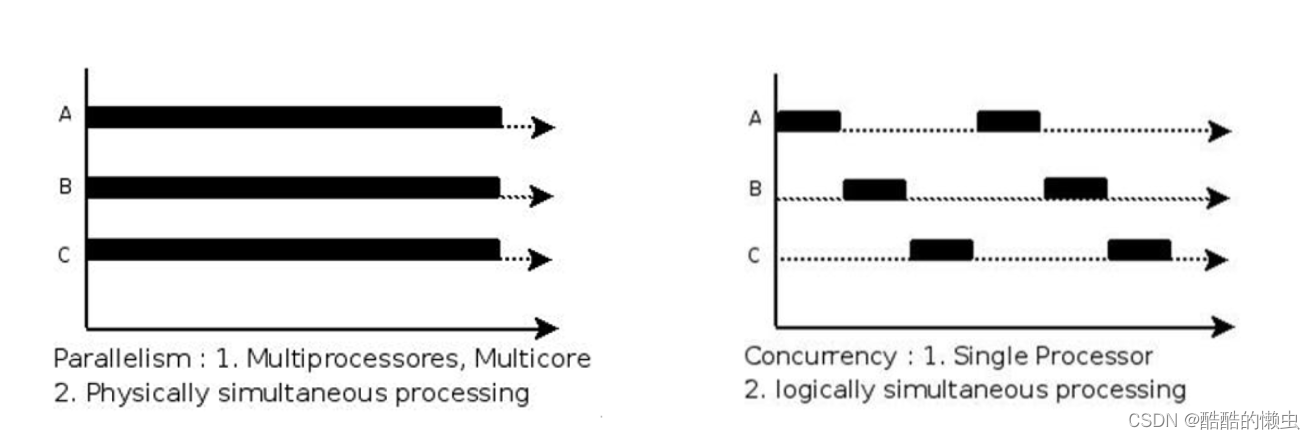
(4)并行和并发
- 并行 (
parallel):指在同一时刻,有多条指令在多个处理器上同时执行。 - 并发 (
concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
(5)进程控制块(PCB)
-
为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。内核为每个进程分配一个
PCB(Processing Control Block)进程控制块,维护进程相关的信息,Linux 内核的进程控制块是task_struct结构体。 -
在
/usr/src/linux-headers-xxx/include/linux/sched.h文件中可以查看struct task_struct结构体定义。其内部成员有很多,我们只需要掌握以下部分即可:-
进程 id :系统中每个进程有唯一的
id,用pid_t类型表示,其实就是一个非负整数 -
进程的状态:有就绪、运行、挂起、停止等状态
-
进程切换时需要保存和恢复的一些 CPU 寄存器
-
描述 虚拟地址空间 的信息
-
描述 控制终端 的信息
-
当前工作目录(
Current Working Directory) -
umask掩码 -
文件描述符表,包含很多指向
file结构体的指针 -
和信号相关的信息
-
用户 id和组 id -
会话(
Session)和进程组 -
进程可以使用的资源上限(
Resource Limit)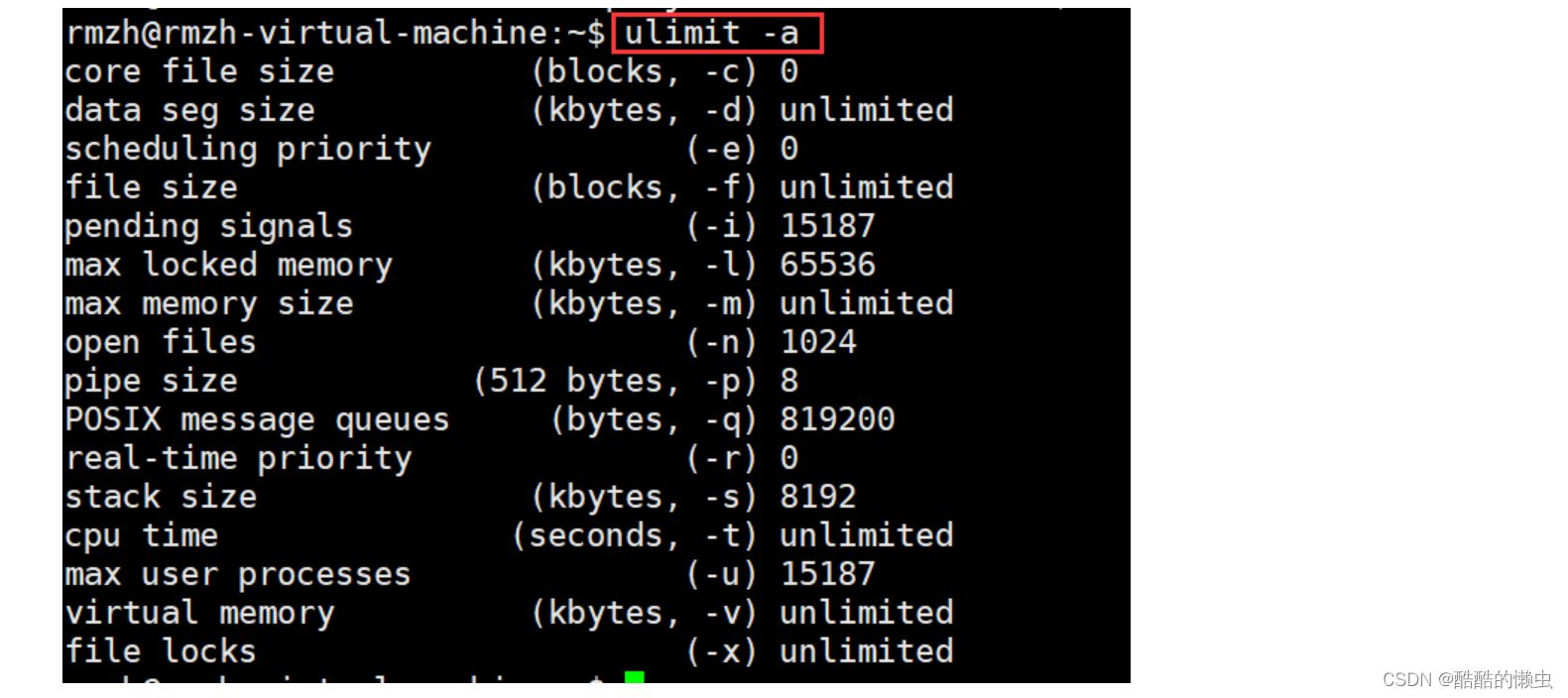
-
2.2 进程状态转换
(1)进程的状态
进程状态反映进程执行过程的变化。这些状态随着进程的执行和外界条件的变化而转换。在三态模型中,进程状态分为三个基本状态,即就绪态,运行态,阻塞态。在五态模型中,进程分为新建态、就绪态,运行态,阻塞态,终止态。
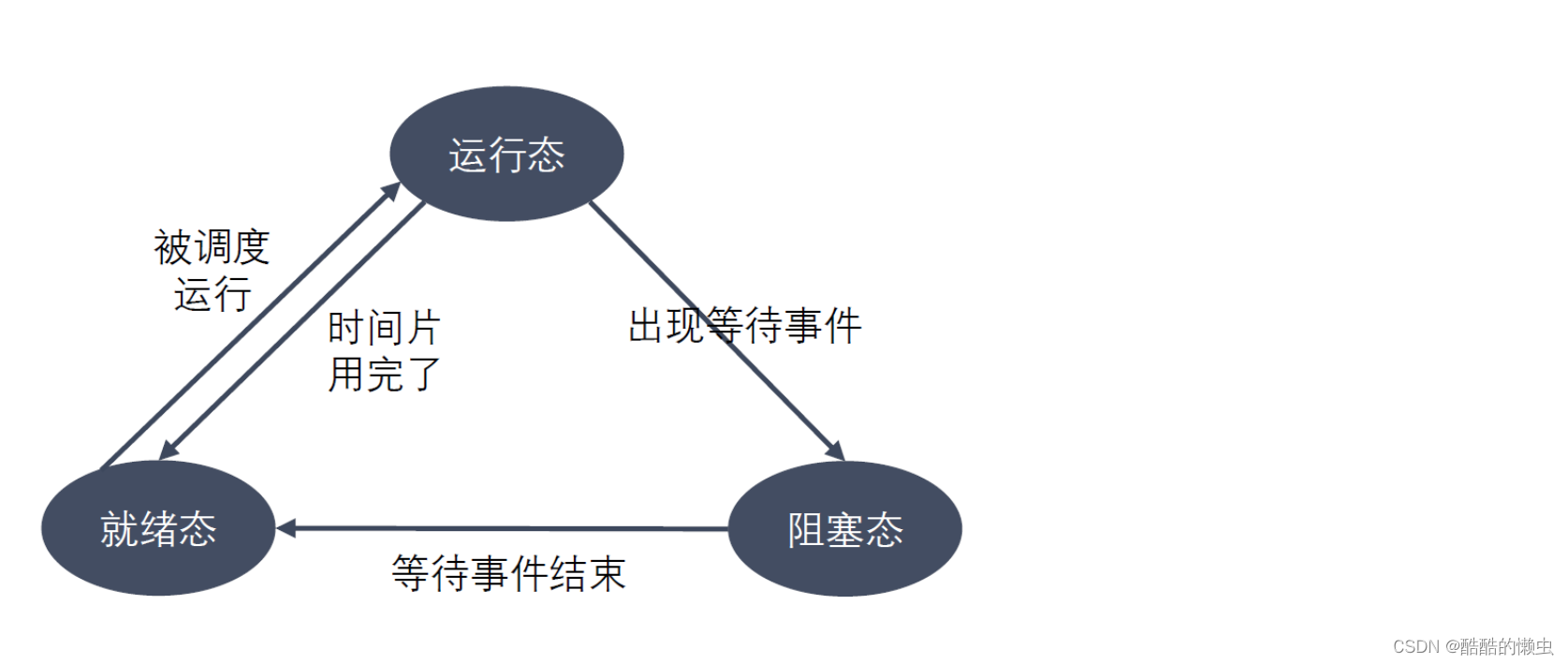
- 运行态:进程占有处理器正在运行
- 就绪态:进程具备运行条件,等待系统分配处理器以便运行。当进程已分配到除 CPU 以外的所有必要资源后,只要再获得 CPU ,便可立即执行。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为就绪队列
- 阻塞态:又称为等待 (
wite) 态或睡眠 (sleep) 态,指进程不具备运行条件,正在等待某个事件的完成
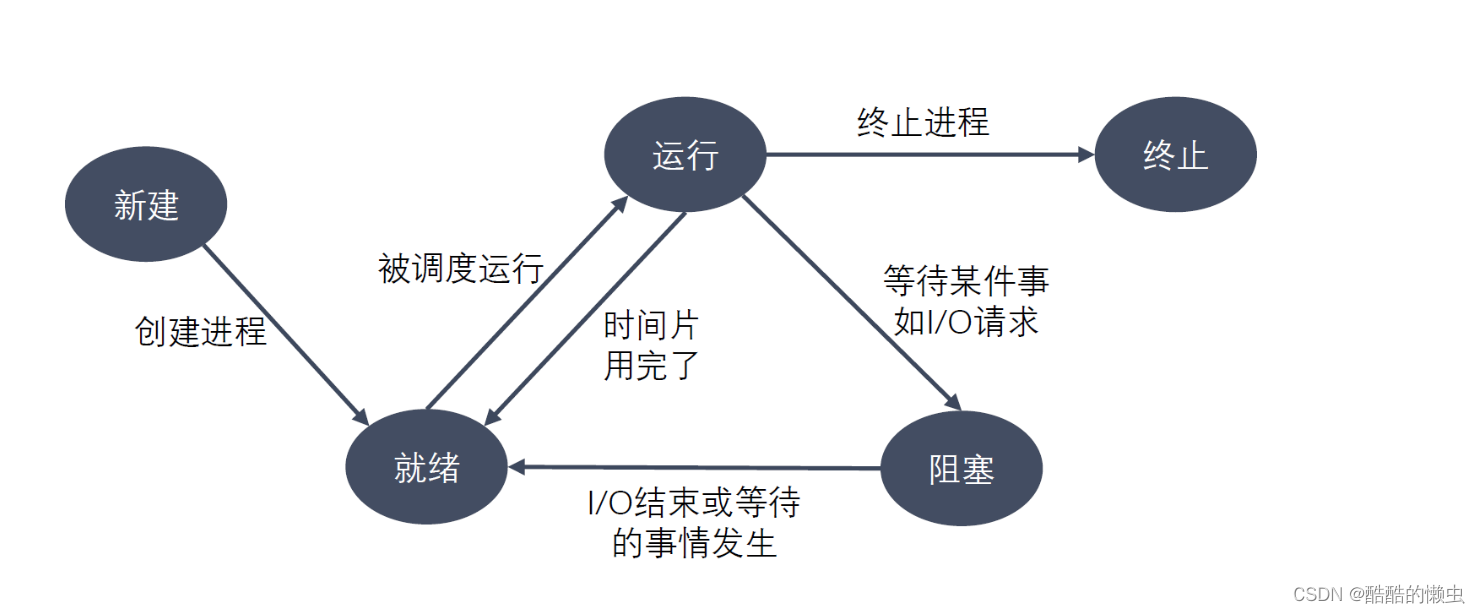
- 新建态:进程刚被创建时的状态,尚未进入就绪队列
- 终止态:进程完成任务到达正常结束点,或出现无法克服的错误而异常终止,或被操作系统及有终止权的进程所终止时所处的状态。进入终止态的进程以后不再执行,但依然保留在操作系统中等待善后。一旦其他进程完成了对终止态进程的信息抽取之后,操作系统将删除该进程。
(2)进程相关命令
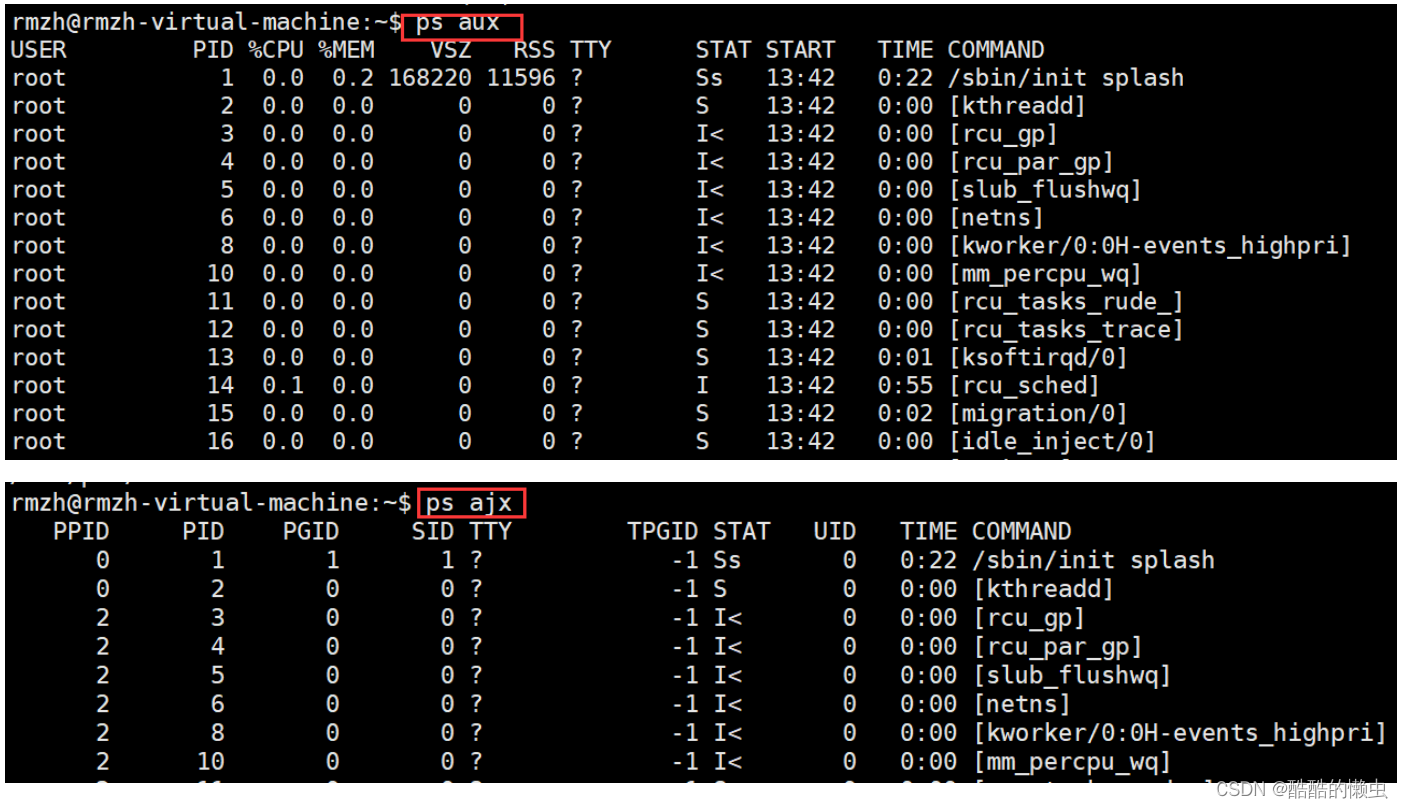
-
查看进程
ps aux / ajxa:显示终端上的所有进程,包括其他用户的进程u:显示进程的详细信息x:显示没有控制终端的进程j:列出与作业控制相关的信息
-
STAT(状态) 参数意义:
D不可中断Uninterruptible(usually IO)R正在运行,或在队列中的进程S(大写) 处于休眠状态T停止或被追踪Z僵尸进程W进入内存交换(从内核 2.6 开始无效)X死掉的进程<高优先级N低优先级s包含子进程+位于前台的进程组
-
实时显示进程动态
top可以在使用
top命令时加上-d来指定显示信息更新的时间间隔,在top命令执行后,可以按以下按键对显示的结果进行排序:-
M根据内存使用量排序 -
P根据 CPU 占有率排序 -
T根据进程运行时间长短排序 -
U根据用户名来筛选进程 -
K输入指定的 PID 杀死进程 -
杀死进程
kill [signal] pidkill -l列出所有信号
kill -SIGKILL进程 ID
kill -9进程 ID
killall name根据进程名杀死进程
-
(3) 进程号和相关函数
- 每个进程都由进程号来标识,其类型为
pid_t(非负整型),进程号的范围0~32767。进程号总是唯一的,但可以重用。当一个进程终止后,其进程号就可以再次使用。 - 任何进程(除
init进程)都是由另一个进程创建,该进程称为被创建进程的父进程,对应的进程号称为父进程号(PPID)。 - 进程组是一个或多个进程的集合。他们之间相互关联,进程组可以接收同一终端的各种信号,关联的进程有一个进程组号(
PGID)。默认情况下,当前的进程号会当做当前的进程组号。- 进程号和进程组相关函数:
pid_t getpid(void);
pid_t getppid(void);
pid_t getpgid(pid_t pid);
- 进程号和进程组相关函数:
2.3 进程创建
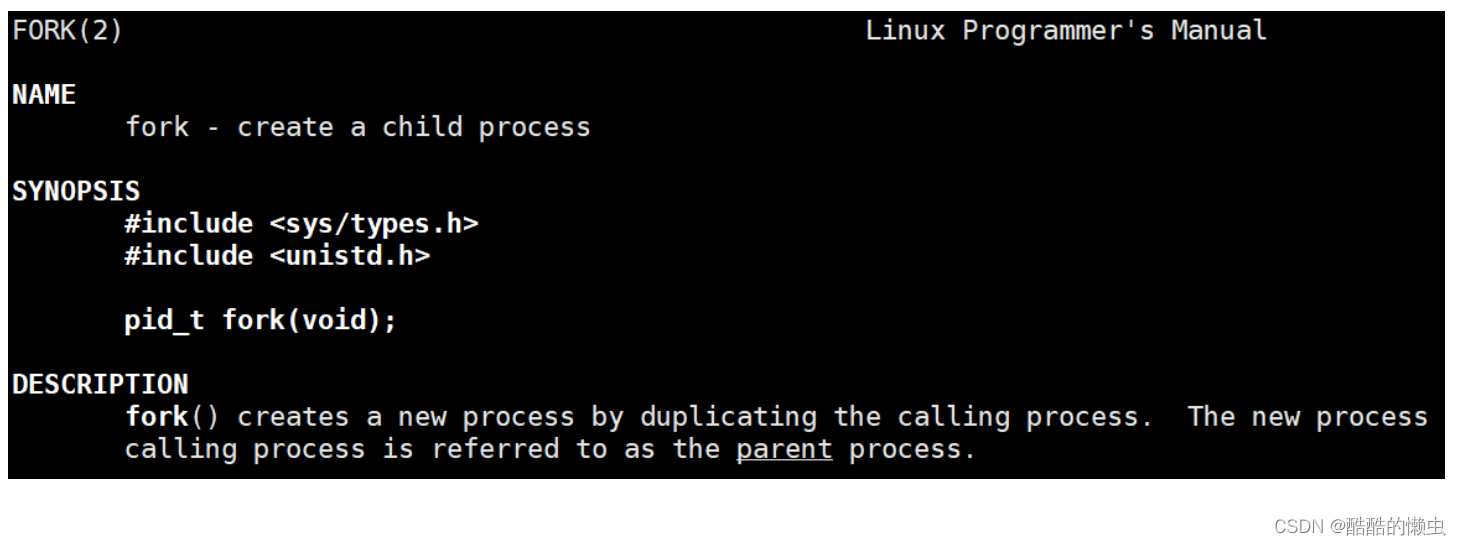
(1)进程创建
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型。
返回值:
- 成功:子进程中返回
0,父进程中返回子进程 ID - 失败:返回
-1
失败的两个主要原因:
- 当前系统的进程数已经达到了系统规定的上限,这时
errno的值被设置为EAGAIN - 系统内存不足,这时
errno的值被设置为ENOMEM
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
/*
pid_t fork(void);
函数的作用:用于创建子进程。返回值:fork()的返回值会返回两次。一次是在父进程中,一次是在子进程中。在父进程中返回创建的子进程的ID,在子进程中返回0如何区分父进程和子进程:通过fork的返回值。在父进程中返回-1,表示创建子进程失败,并且设置errno
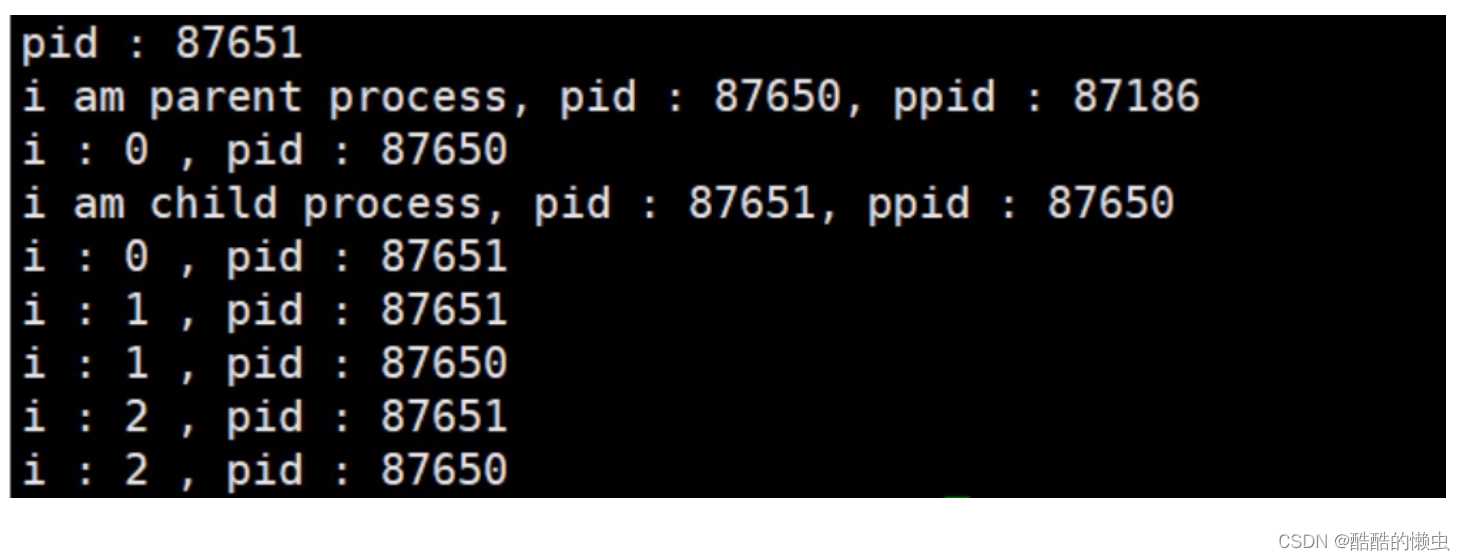
*/int main() {int num = 10;// 创建子进程pid_t pid = fork();// 判断是父进程还是子进程if(pid > 0) {printf("pid : %d\n", pid);// 如果大于0,返回的是创建的子进程的进程号,当前是父进程printf("i am parent process, pid : %d, ppid : %d\n", getpid(), getppid());printf("parent num : %d\n", num);num += 10;printf("parent num += 10 : %d\n", num);} else if(pid == 0) {// 当前是子进程printf("i am child process, pid : %d, ppid : %d\n", getpid(),getppid());printf("child num : %d\n", num);num += 100;printf("child num += 100 : %d\n", num);}// for循环for(int i = 0; i < 3; i++) {printf("i : %d , pid : %d\n", i , getpid());sleep(1);}return 0;
}
(2)父子进程虚拟地址空间
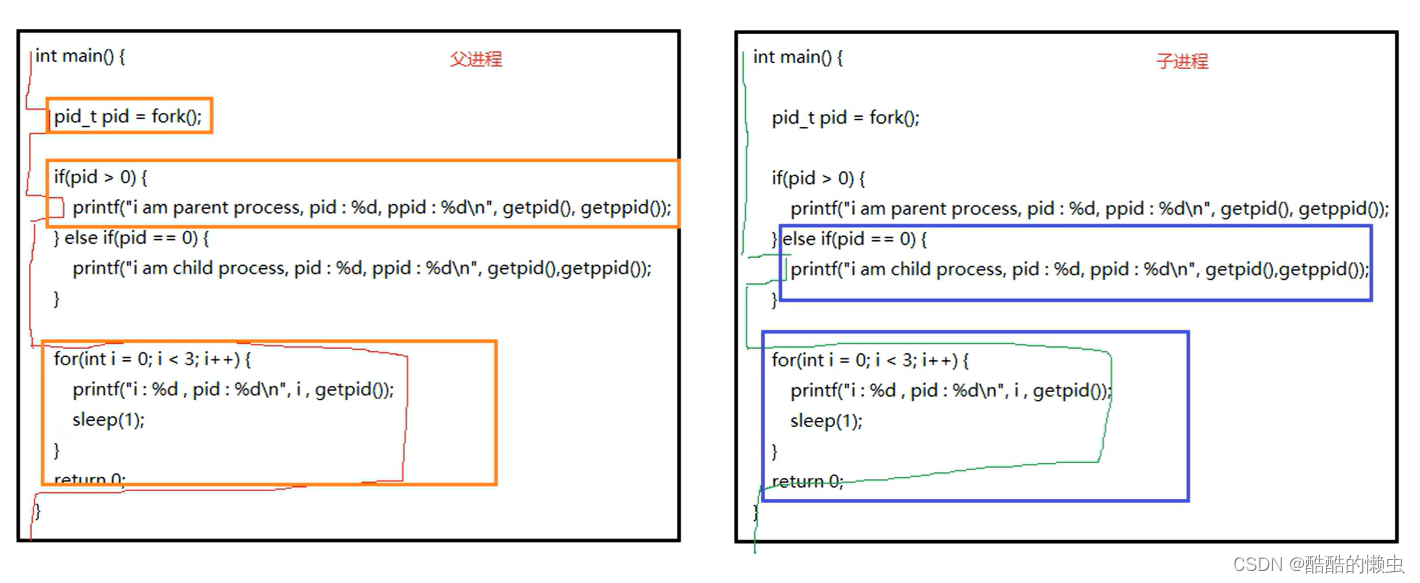
父子进程之间的关系:
区别:
fork()函数的返回值不同
父进程中: >0 返的子进程的ID
子进程中: =0- pcb中的一些数据
当前的进程的id:pid
当前的进程的父进程的id:ppid
信号集共同点:
某些状态下:子进程刚被创建出来,还没有执行任何的写数据的操作
- 用户区的数据相同
- 文件描述符表相同
父子进程对变量是不是共享的?
- 刚开始的时候,是一样的,共享的。如果修改了数据,不共享了。
- 读时共享(子进程被创建,两个进程没有做任何的写的操作),写时拷贝。
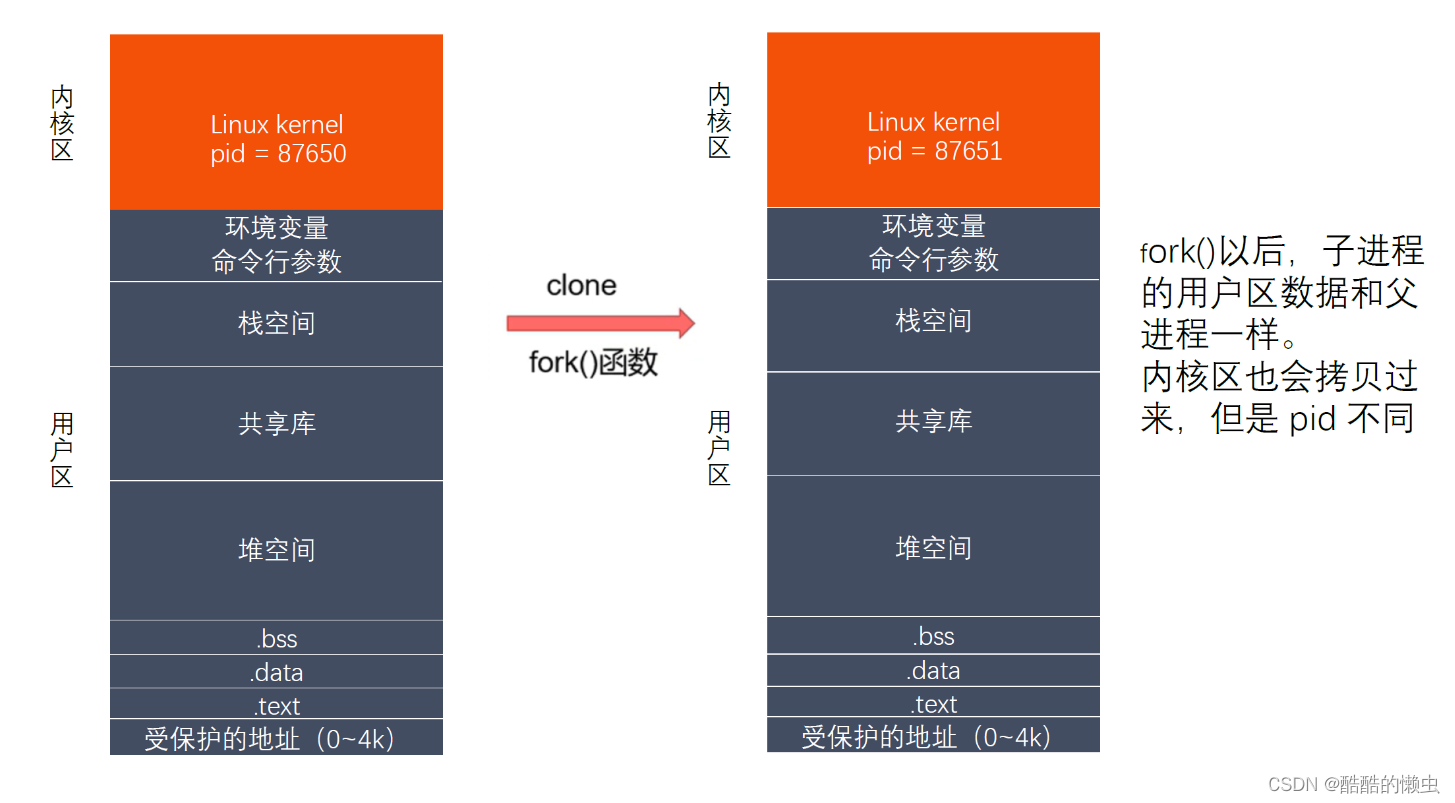
- 栈空间中的变量相同,但会不干扰。
实际上,更准确来说,Linux 的
fork()使用是通过写时拷贝 (copy- on-write) 实现。
写时拷贝是一种可以推迟甚至避免拷贝数据的技术。
内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。
只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。
也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。注意:
fork之后父子进程共享文件,
fork产生的子进程与父进程相同的文件文件描述符指向相同的文件表,引用计数增加,共享文件偏移指针。
(3)GDB 多进程调试
- 使用 GDB 调试的时候, GDB 默认只能跟踪一个进程,可以在
fork函数调用之前,通过指令设置 GDB 调试工具跟踪父进程或者是跟踪子进程,默认跟踪父进程。 - 设置调试父进程或者子进程:
set follow-fork-mode [parent (默认) | child] - 设置调试模式:
set detach-on-fork [on (默认) | off]- 默认为
on,表示调试当前进程的时候,其它的进程继续运行,如果为off,调试当前进程的时候,其它进程被 GDB 挂起。
- 默认为
- 查看调试的进程:
info inferiors - 切换当前调试的进程:
inferior id - 使进程脱离 GDB 调试:
detach inferiors id
2.4 exec 函数族
(1)exec 函数族介绍
-
函数族:功能相同或相似;类似C++ 中的函数重载。
-
exec 函数族的作用是根据指定的文件名 找到可执行文件,并用它来 取代 调用进程的内容(一般都是先fork出一个子进程,取代子进程 ),换句话说,就是在调用进程内部执行一个可执行文件。 -
exec函数族的函数执行成功后不会返回,因为调用进程的实体,包括 代码段,数据段 和 堆栈 等都已经被新的内容取代,只留下进程 ID 等一些表面上的信息仍保持原样,颇有些神似 “三十六计” 中的 “金蝉脱壳” 。看上去还是旧的躯壳,却已经注入了新的灵魂。只有调用失败了,它们才会返回-1,从原程序的调用点接着往下执行。
(2)exec 函数族
// 标准c库中的函数
int execl(const char *path, const char *arg, .../* (char *) NULL */);
int execlp(const char *file, const char *arg, ... /* (char *) NULL */);
int execle(const char *path, const char *arg, .../*, (char *) NULL, char *
const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);// Linux 中的函数
int execve(const char *filename, char *const argv[], char *const envp[]);
l(list) 参数地址列表,以空指针结尾v(vector) 存有各参数地址的指针数组的地址p(path) 按 PATH 环境变量指定的目录搜索可执行文件e(environment) 存有环境变量字符串地址的指针数组的地址
int execl(const char *path, const char *arg, ...);
-
参数:
path: 需要指定的执行的文件的路径或者名称a.out,/home/nowcoder/a.out推荐使用绝对路径
arg: 是执行可执行文件所需要的参数列表 (./a.outhelloworld)- 第一个参数一般没有什么作用,为了方便,一般写的是执行的程序的名称
- 从第二个参数开始往后,就是程序执行所需要的的参数列表。
- 参数最后需要以
NULL结束(哨兵)
-
返回值:
- 只有当调用失败,才会有返回值,返回
-1,并且设置errno - 如果调用成功,没有返回值。
例如:首先创建一个
hello.c#include <stdio.h>int main() { printf("hello, world\n");return 0; }#include <unistd.h> #include <stdio.h>int main() {// 创建一个子进程,在子进程中执行exec函数族中的函数pid_t pid = fork();if(pid > 0) {// 父进程printf("i am parent process, pid : %d\n",getpid());sleep(1);}else if(pid == 0) {// 子进程execl("hello","hello",NULL);// execl("/bin/ps", "ps", "aux", NULL);perror("execl");printf("i am child process, pid : %d\n", getpid());}for(int i = 0; i < 3; i++) {printf("i = %d, pid = %d\n", i, getpid());}return 0; }
- 只有当调用失败,才会有返回值,返回
int execlp (const char *file, const char *arg, ...);
-
会到 环境变量 中查找指定的可执行文件,如果找到了就执行,找不到就执行不成功。
-
参数:
file: 需要执行的可执行文件的文件名a.out,ps
arg: 是执行可执行文件所需要的参数列表 (./a.outhelloworld)- 第一个参数一般没有什么作用,为了方便,一般写的是执行的程序的名称
- 从第二个参数开始往后,就是程序执行所需要的的参数列表。
- 参数最后需要以
NULL结束(哨兵)
-
返回值:
- 只有当调用失败,才会有返回值,返回
-1,并且设置errno - 如果调用成功,没有返回值。
- 只有当调用失败,才会有返回值,返回
#include <unistd.h>
#include <stdio.h>int main() {// 创建一个子进程,在子进程中执行exec函数族中的函数pid_t pid = fork();if(pid > 0) {// 父进程printf("i am parent process, pid : %d\n",getpid());sleep(1);}else if(pid == 0) {// 子进程execlp("ps", "ps", "aux", NULL);printf("i am child process, pid : %d\n", getpid());}for(int i = 0; i < 3; i++) {printf("i = %d, pid = %d\n", i, getpid());}return 0;
}
其他的类似:
/*
int execv(const char *path, char *const argv[]);argv是需要的参数的一个字符串数组char * argv[] = {"ps", "aux", NULL};execv("/bin/ps", argv);int execve(const char *filename, char *const argv[], char *const envp[]);char * envp[] = {"/home/nowcoder", "/home/bbb", "/home/aaa"};*/
2.5 进程控制
(1)进程退出
#include <stdlib.h> // 标准c库,常用
void exit(int status);#include <unistd.h> // Linux 系统函数
void _exit(int status);
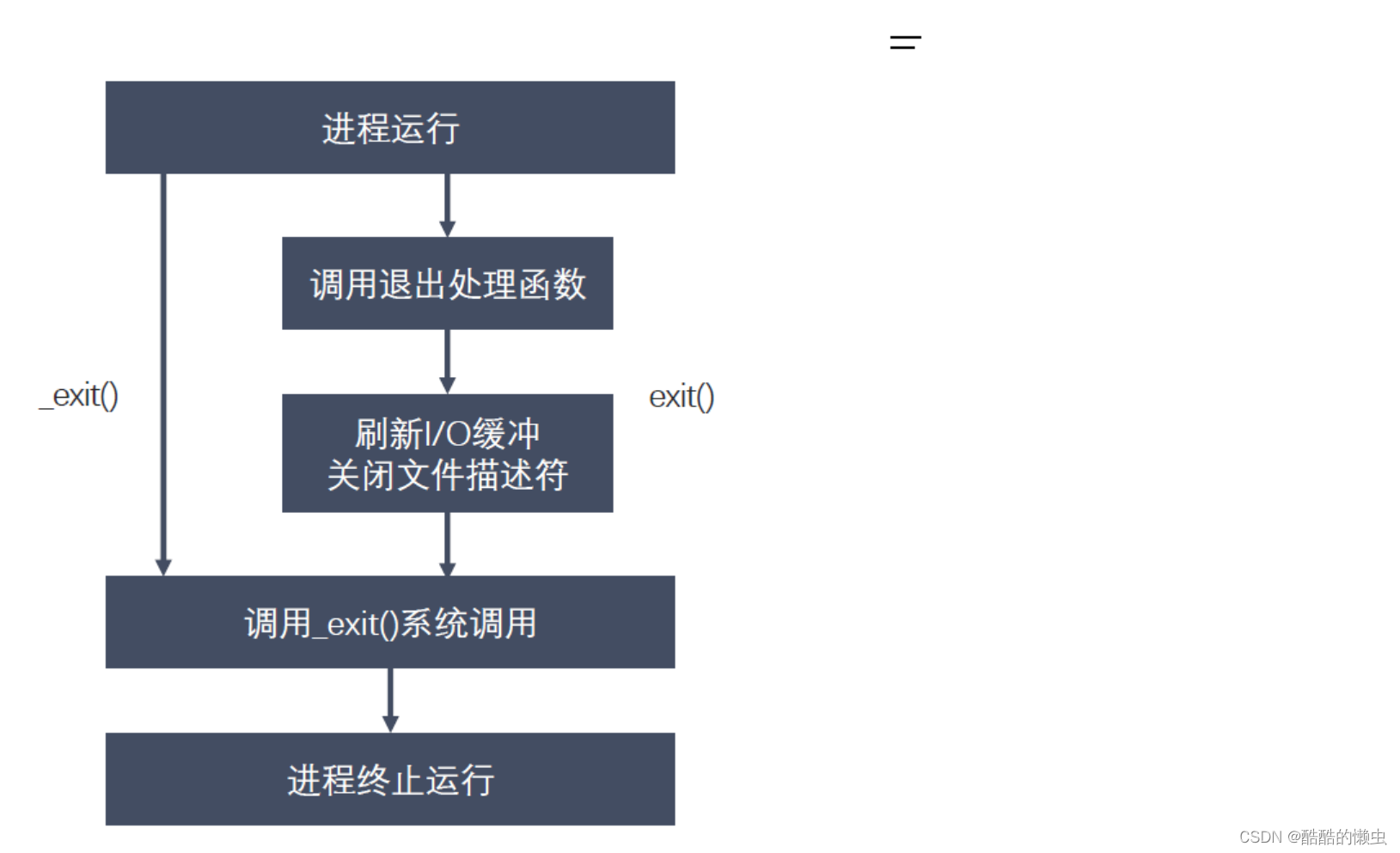
(2)孤儿进程
- 父进程运行结束,但子进程还在运行(未运行结束),这样的子进程就称为 孤儿进程 (
Orphan Process)(没爹了)。 - 每当出现一个孤儿进程的时候,内核就把孤儿进程的 父进程 设置为
init(ppid = 1),而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表 党和政府 出面处理它的一切善后工作。 - 因此孤儿进程并 不会有什么危害。
(3)僵尸进程
- 每个进程结束之后 , 都会释放自己地址空间中的 用户区数据,内核区 的
PCB没有办法自己释放掉,需要父进程去释放。 - 进程终止时,父进程尚未回收,子进程残留资源(
PCB)存放于内核中,变成僵尸 (Zombie)进程。(爹还在) - 僵尸进程不能被
kill -9杀死, - 这样就会导致一个问题,如果父进程不调用
wait()或waitpid()的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统 不能产生新的进程,此即为僵尸进程的危害,应当避免。
(4)进程回收
-
在每个进程退出的时候,内核释放该进程所有的资源、包括打开的文件、占用的内存 (都是用户区数据) 等。但是仍然为其保留一定的信息,这些信息主要主要指进程控制块 PCB(内核区) 的信息(包括进程号、退出状态、运行时间等)。
-
父进程可以通过调用
wait或waitpid得到它的 退出状态(int类型地址,传出参数) 同时 彻底清除掉这个进程。
-
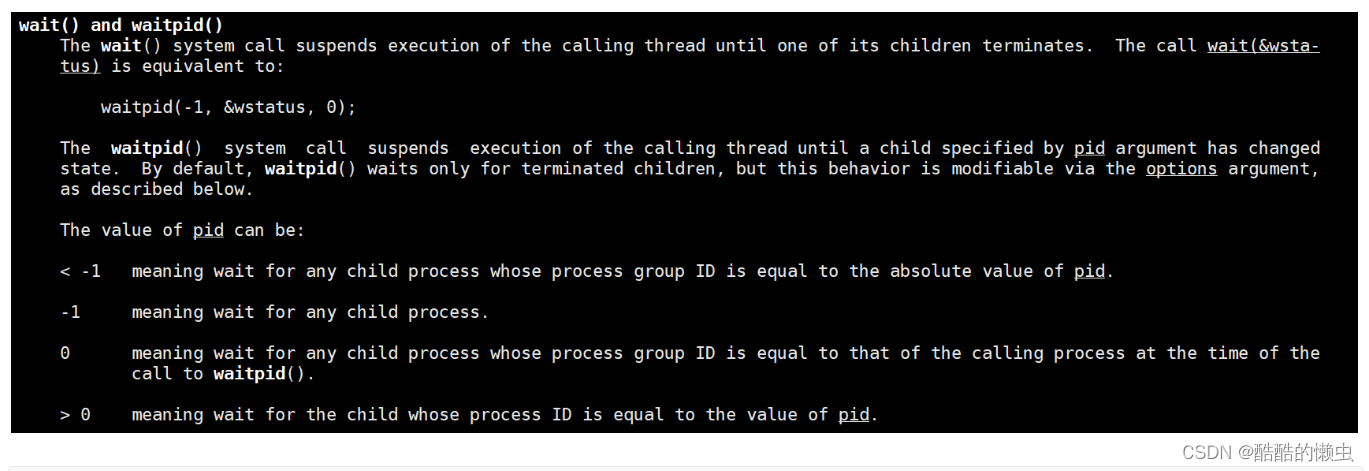
wait()和waitpid()函数的功能一样,区别在于,wait()函数会 阻塞,waitpid()可以设置 不阻塞,waitpid()还可以指定等待哪个子进程结束。 -
注意:一次
wait或waitpid调用 只能清理一个子进程,清理多个子进程应使用循环。
调用
wait函数的进程会被挂起(阻塞),直到它的 一个子进程退出 或者 收到一个不能被忽略的信号 时才被唤醒(相当于继续往下执行)
- 成功:返回被回收的
子进程的id- 失败:
-1(所有的子进程都结束,调用函数失败)如果没有子进程了,函数立刻返回,返回
-1;如果子进程都已经结束了,也会立即返回,返回-1.
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <unistd.h>
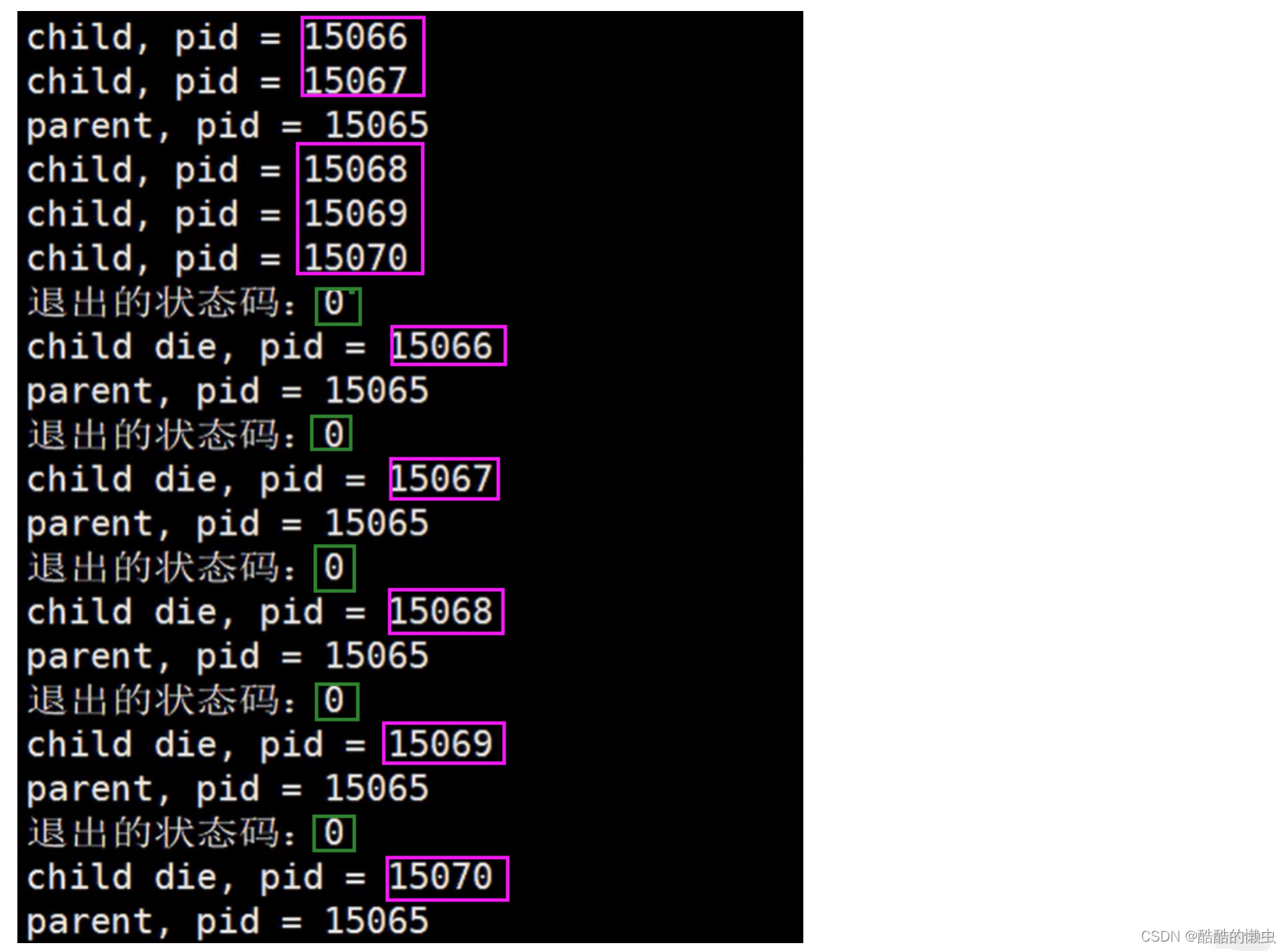
#include <stdlib.h>int main() {// 有一个父进程,创建5个子进程(兄弟)pid_t pid;// 创建5个子进程for(int i = 0; i < 5; i++) {pid = fork();if(pid == 0) { // 如果是子进程,则退出循环,不在产生孙子进程break;}}if(pid > 0) {// 父进程while(1) {printf("parent, pid = %d\n", getpid());// int ret = wait(NULL);int st;int ret = wait(&st); //阻塞if(ret == -1) {break;}if(WIFEXITED(st)) { // w if exited// 是不是正常退出printf("退出的状态码:%d\n", WEXITSTATUS(st));}if(WIFSIGNALED(st)) {// 是不是异常终止printf("被哪个信号干掉了:%d\n", WTERMSIG(st));}printf("child die, pid = %d\n", ret);sleep(1);}} else if (pid == 0){// 子进程while(1) {printf("child, pid = %d\n",getpid()); sleep(1); }exit(0); // 设置:退出的状态码为 0}return 0; // exit(0)
}
-
pid_t waitpid(pid_t pid, int *wstatus, int options);-
功能:回收 指定进程号 的 子进程,可以设置是否阻塞。
-
参数:
-
pid:
pid > 0: 某个子进程的pid
pid = 0: 回收 当前进程组的所有子进程
pid = -1: 回收 所有的子进程,相当于wait()(最常用)(有的子进程可能不在一个组,也要回收)
pid < -1: 某个进程组的组id的绝对值,回收 指定进程组 中的 子进程 -
options:设置阻塞或者非阻塞
0: 阻塞
WNOHANG: 非阻塞 -
返回值
*wstatus:> 0: 返回子进程的id
= 0:options=WNOHANG, 表示还有子进程活着
= -1:错误,或者没有子进程了
#include <sys/types.h> #include <sys/wait.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h>int main() {// 有一个父进程,创建5个子进程(兄弟)pid_t pid;// 创建5个子进程for(int i = 0; i < 5; i++) {pid = fork();if(pid == 0) {break;}}if(pid > 0) {// 父进程while(1) {printf("parent, pid = %d\n", getpid());sleep(1);int st;// int ret = waitpid(-1, &st, 0); // 阻塞,和wait相同int ret = waitpid(-1, &st, WNOHANG);//非阻塞if(ret == -1) {break;} else if(ret == 0) {// 说明还有子进程存在continue;} else if(ret > 0) {if(WIFEXITED(st)) {// 是不是正常退出printf("退出的状态码:%d\n", WEXITSTATUS(st));}if(WIFSIGNALED(st)) {// 是不是异常终止printf("被哪个信号干掉了:%d\n", WTERMSIG(st));}printf("child die, pid = %d\n", ret);}}} else if (pid == 0){// 子进程while(1) {printf("child, pid = %d\n",getpid()); sleep(1); }exit(0);}return 0; } -
-
(4)退出信息相关宏函数
-
WIFEXITED(status)非 0 ,进程正常退出 -
WEXITSTATUS(status)如果上宏为真,获取进程退出的状态(exit的参数) -
WIFSIGNALED(status)非 0 ,进程异常终止 -
WTERMSIG(status)如果上宏为真,获取使进程终止的信号编号 -
WIFSTOPPED(status)非 0 ,进程处于暂停状态 -
WSTOPSIG(status)如果上宏为真,获取使进程暂停的信号的编号 -
WIFCONTINUED(status)非 0 ,进程暂停后已经继续运行
注:仅供学习参考,如有不足,欢迎指正!