什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
上面这句介绍比较全面的描述了什么是布隆过滤器,如果还是不太好理解的话:就可以把布隆过滤器理解为一个set集合,我们可以通过add往里面添加元素,通过contains来判断是否包含某个元素。

布隆过滤器的优缺点
布隆过滤器的优点:
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
- 保密性强,布隆过滤器不存储元素本身
- 存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
用布隆过滤器干什么(重要)
Bloom 筛选器索引以加速进行“大海捞针式”查询。
作为大数据开发我经常需要“大海捞针式”查询我需要的字段,举个例子:
我的数据是 id, date, loctionId, data(其他很多列),默认情况它就先找分区,再全表搜索到底有没有( id, date, loctionId)
如果我基于id, date, loctionid建立一个bloom索引,首先通过布隆过滤器知道有没有( id, date, loctionId),如果在索引里没有,那我就不需要搜索相关的id,节省大量搜索时间。

布隆过滤器原理
把每个key hash之后映射到位图上,位图默认为0,映射到则改为1。

查询就是key hash之后看看位图是不是都是1,如果有一个不是1是0,则这key一定没有
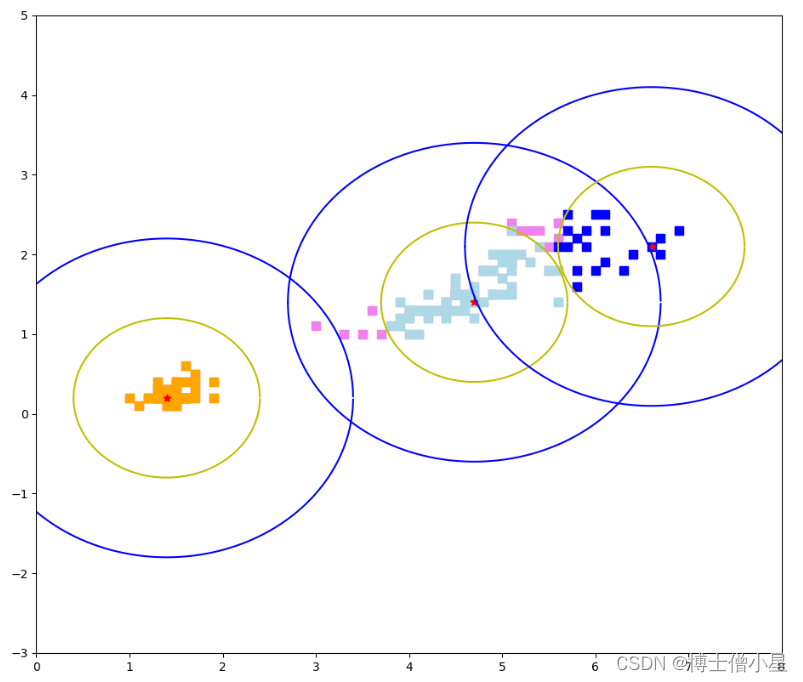
两个key取模,hash后可能hash碰撞, 导致存储的位图一样,如下图所示,xushu跟xushu666存储在bloom的位图都一样,所在存在不一定存在,所以bloom过滤器有一点误差。

不存在一定不存在,存在不一定存在
记住上面这句话,我只要能排除不存在的id,那我就可以减少很多查询时间。
基于误差我可以通过下面两种方式减小误差。

bit位数越长,我hash之后放入同一个位数概率越低,冲突概率越低。

一次hash之后可能冲突,那我对一个key多次hash, 多放几个位数,这样冲突概率也会降低,但是hash太多次也会影响查询效率,因为查询的的时候也需要多次hash
基于detlaTable建bloom过滤器实践
背景基于databricks(spark),可参考思路
// Enable the Bloom filter index capability
SET spark.databricks.io.skipping.bloomFilter.enabled = true;// 数据源加载到detlaTable
from delta.tables import DeltaTable# 加载 Delta Lake 表
delta_table = DeltaTable.forPath(spark, "/path/to/delta-table")# 创建布隆过滤器索引
# FPP 为 10% 时,每个元素需要 5 位,也就是一个key需要hash 5次,存到五个位图
# numItems=50000000 表示期望布隆过滤器包含的唯一元素数量为 5000 万
delta_table.createIndex("bloom_filter_index", "id, date, locationId", "bloom_filter(fpp=0.1, numItems=50000000)")# 查看创建的索引信息
delta_table.describeIndex("bloom_filter_index").show()
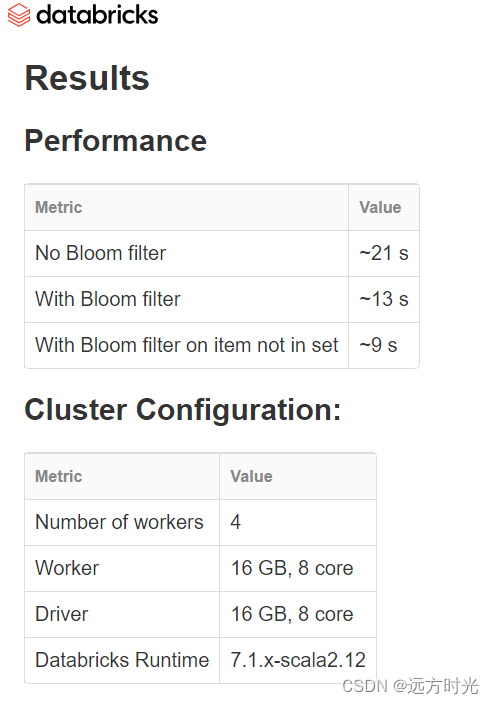
使用bloom过滤器效能(databricks官方测试)
1.5GB数据使用bloom作索引后查询速度 (21s ===> 13s)

---------------------->