本文将以采集全国 5A 景点名单为例,详细介绍如何使用 Python 进行数据采集。
本文采集到全国340家5A景区的名单,包括
景区名称、地区、A级、评定年份这些字段。
一、分析数据源
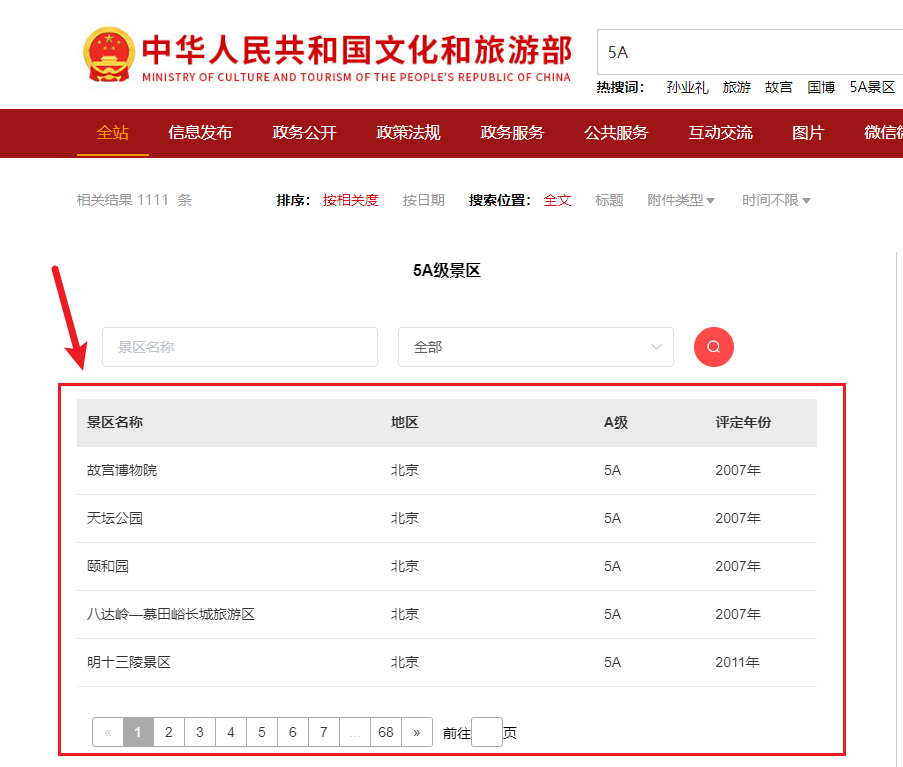
为了获取权威数据,我们来到主管部门的官方网站,在右上角搜索框内搜索“5A”。

可以看到搜索结果有一个列表,通过翻页可以查询到全国所有 5A 景区的景区名称、地区、 A级、评定年份这些字段。
在浏览器右键,检查,找到请求 url、请求方式。

找到请求需要携带的参数。
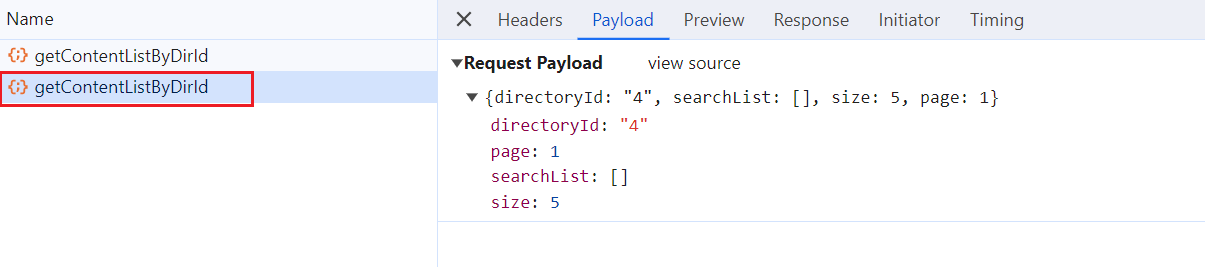
分析返回的 response,content 下面就是我们需要的数据。
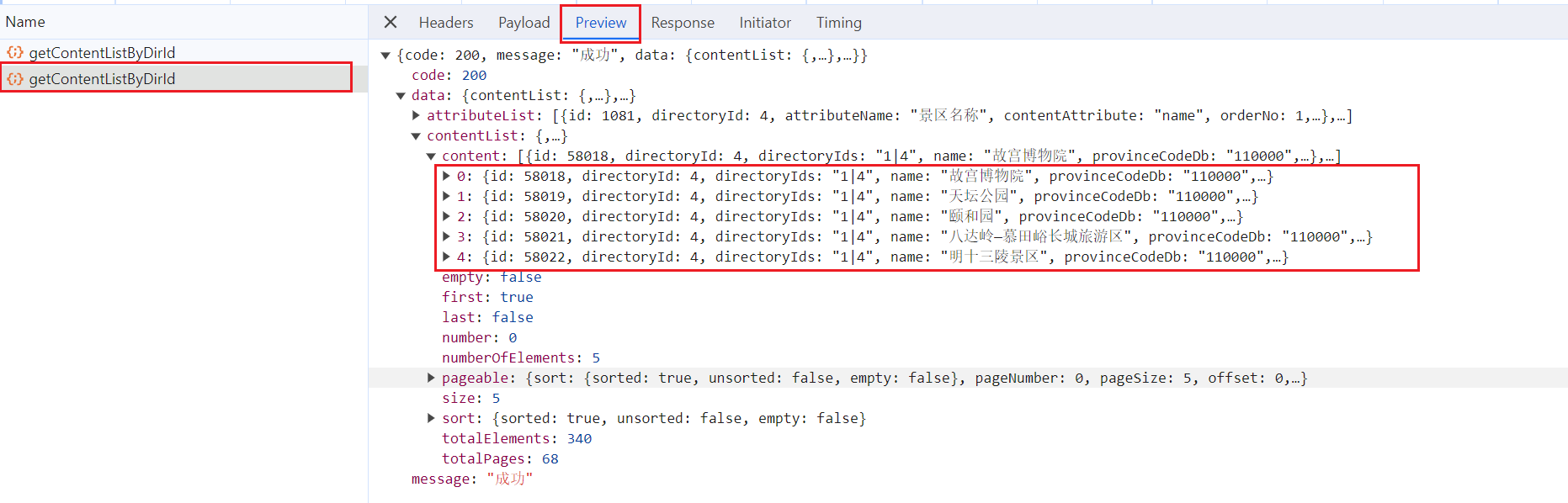
通过以上分析,可以发现想要获取到数据并不难。
接下来,我们可以通过 Python 代码,轻松采集到这些字段信息。
二、开始写代码
1、导入库
import requests
import time
from DataRecorder import Recorder
from tqdm import tqdm
2、请求数据
headers = {'User-Agent': '' #填写自己的
}
json_data = {'directoryId': '4','searchList': [],'size': 5,'page': 1,
}response = requests.post('https://www.mct.gov.cn/tourism/api/content/getContentListByDirId',headers=headers, json=json_data).json()
3、处理response
# contents包含本页景区信息
contents = response['data']['contentList']['content']
# 当前页景区数量
content_num = len(contents)
print(f"**********第{page}页有{content_num}个景区**********")
# 提取每个景区信息:'景区名称'、'地区'、 'A级'、'评定年份'
for content in contents:name = content['name']provinceName = content['provinceName']gradesName = content['gradesName']year = content['year']# 景区信息放入一个字典content_dict = {'景区名称': name, '地区': provinceName, 'A级': gradesName, '评定年份': year}print(content_dict)
这样简单几行代码,就可以完成数据采集了,Pycharm 控制台输出如下。

接下来,可以完善代码,把采集每页景点信息的代码封装为一个函数+实现翻页采集数据+数据存储。
4、封装函数
def get_info(page):headers = {'User-Agent': #填写自己的}json_data = {'directoryId': '4','searchList': [],'size': 5,'page': page,}response = requests.post('https://www.mct.gov.cn/tourism/api/content/getContentListByDirId',headers=headers, json=json_data).json()......
5、翻页采集数据
# 获取第1页到68页的景点信息
for page in tqdm(range(1, 69)):# 调用获取景区信息的函数get_info(page)# 翻页之间设置3秒等待,减小对方网站压力time.sleep(3)
6、数据存储到excel
# 获取当前时间
current_time = time.localtime()
# 格式化当前时间
formatted_time = time.strftime("%Y-%m-%d %H%M%S", current_time)
# 初始化文件
init_file_path = f'全国5A景点名单-{formatted_time}.xlsx'
# 新建一个excel表格,用来保存数据,每500条缓存写入一次本地excel
r = Recorder(path=init_file_path, cache_size=500)
# 景区信息写入缓存
r.add_data(content_dict)
# 避免数据丢失,爬虫结束时强制保存excel文件
r.record()
三、完整代码如下
import requests
import time
from DataRecorder import Recorder
from tqdm import tqdmdef get_info(page):headers = {'User-Agent':#填写自己的}json_data = {'directoryId': '4','searchList': [],'size': 5,'page': page,}response = requests.post('https://www.mct.gov.cn/tourism/api/content/getContentListByDirId',headers=headers, json=json_data).json()# contents包含本页景区信息contents = response['data']['contentList']['content']# 当前页景区数量content_num = len(contents)print(f"**********第{page}页有{content_num}个景区**********")# 提取每个景区信息:'景区名称'、'地区'、 'A级'、'评定年份'for content in contents:name = content['name']provinceName = content['provinceName']gradesName = content['gradesName']year = content['year']# 景区信息放入一个字典content_dict = {'景区名称': name, '地区': provinceName, 'A级': gradesName, '评定年份': year}print(content_dict)# 景区信息写入缓存r.add_data(content_dict)if __name__ == '__main__':# 获取当前时间current_time = time.localtime()# 格式化当前时间formatted_time = time.strftime("%Y-%m-%d %H%M%S", current_time)# 初始化文件init_file_path = f'全国5A景点名单-{formatted_time}.xlsx'# 新建一个excel表格,用来保存数据,每500条缓存写入一次本地excelr = Recorder(path=init_file_path, cache_size=500)# 获取第1页到68页的景点信息for page in tqdm(range(1, 69)):# 调用获取景区信息的函数get_info(page)# 翻页之间设置3秒等待,减小对方网站压力time.sleep(3)# 避免数据丢失,爬虫结束时强制保存excel文件r.record()
Pycharm 控制台输出如下:
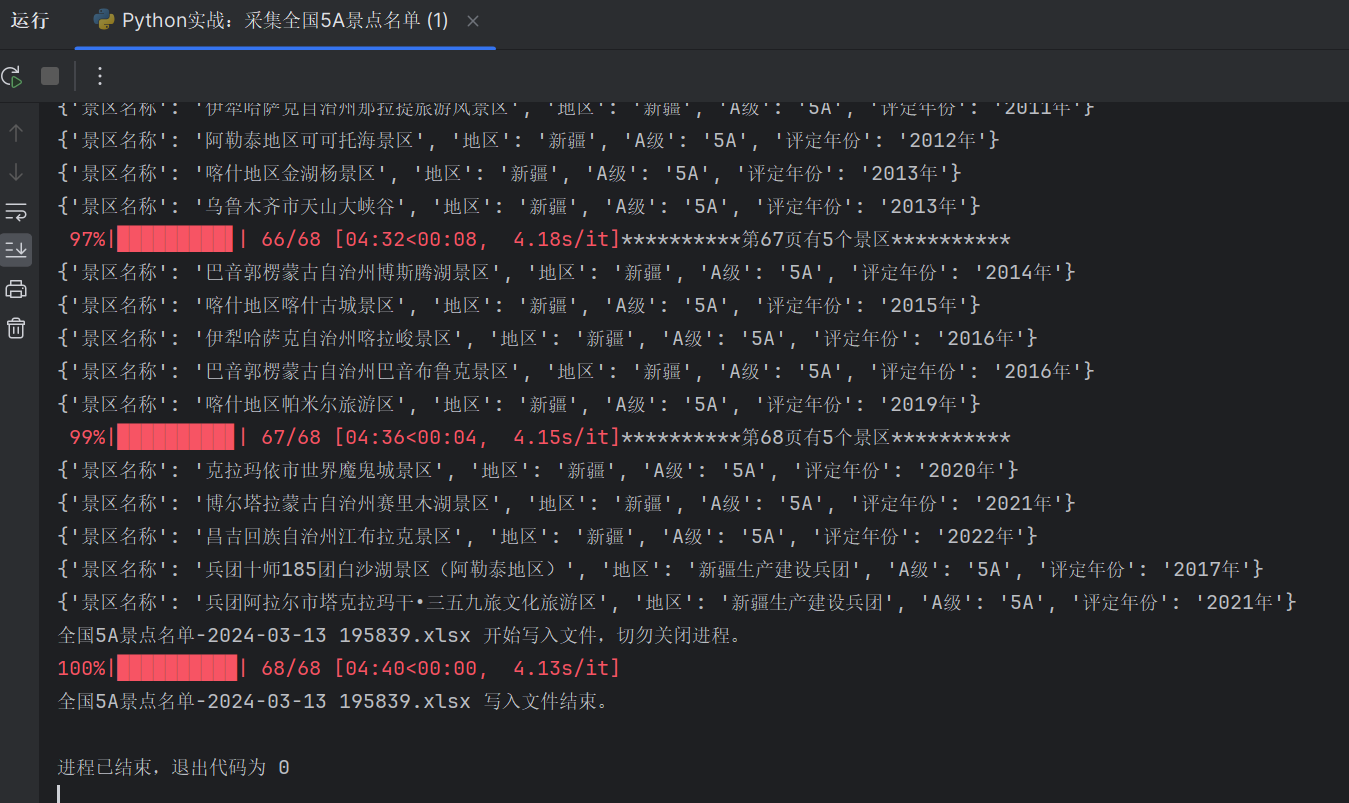
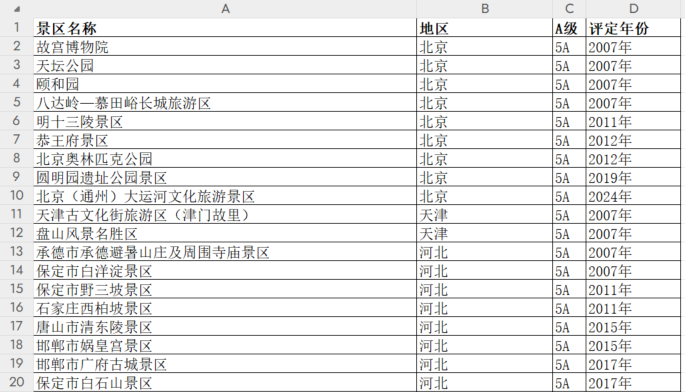
总计获取到 340 个 5A 景区信息,excel 截图如下:
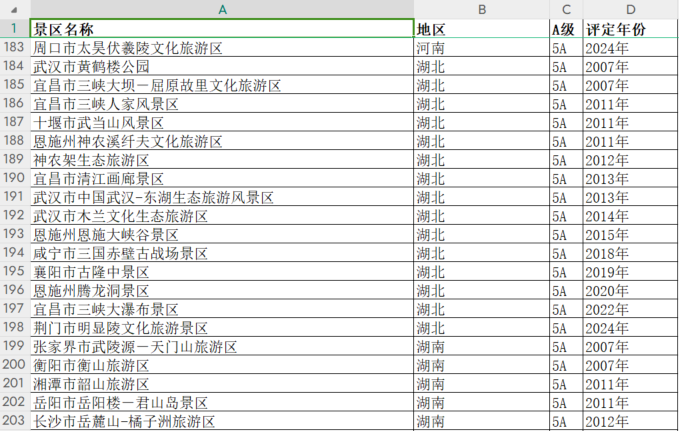
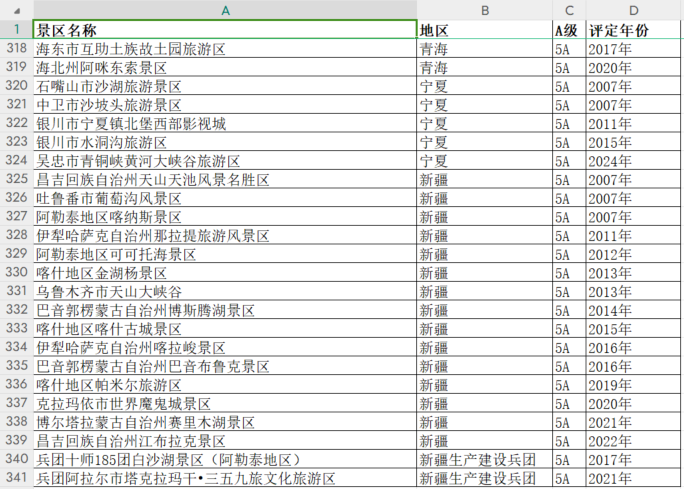
四、数据分析
接下来,可以进行数据分析,由于不是本文重点,而且我之前发过类似文章,就不展开写了,有兴趣的读者可以自行尝试。
比较有趣的是,黄河壶口瀑布旅游区(陕西省延安市·山西省临汾市)这个景区同时属于山西和陕西两个地区,官方网站把他算作 2 条数据,所以也可以说全国有 339 个或 340 个 5A 景区。

五、总结
通过以上步骤,编写这个简单的 Python 代码,就获取到了官方发布的全国 5A 景点信息,一共是 340 个。
这个过程包括获取网页源代码、解析网页源代码、提取所需数据和存储数据等环节。掌握了这些技能,我们可以更加高效地在网上采集所需的信息,为数据分析提供有力支持。
世界那么大,我想去看看。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。还可以通过公众号添加我的私人微信。




![BUUCTF-----[CISCN 2019 初赛]Love Math](https://img-blog.csdnimg.cn/direct/939d29f5dec3424eb4ca38573ec0a971.png)