0. 引言
之前我们讲解过rabbitMQ,本期我们将进入吞吐量更加强大的rocketMQ的学习。
1. 基础概念
如果你是刚接触MQ的同学,还不清楚消息队列的基础概念的,可以参考我之前这篇文章:
https://wu55555.blog.csdn.net/article/details/124678795
2. rocketMQ的应用场景
我们在之前的文章中已经引入了MQ的三种场景:异步调用、流量削峰、服务解耦
而除了这几个作用外,rocketmq支持的几大特性还可以处理以下几种业务场景:
- 顺序消费
所谓顺序消费,就是希望触发的事件按照触发的顺序依次执行,而不要产生混乱。这里大家可能有疑惑,我们正常执行代码不就是顺序消费的吗? 为什么要单独说明,当然是因为执行的事件非常多,我们需要借助MQ缓冲大量消息的特性作为前提,然后又要保证消息是顺序消费执行的,这样才能保证我们后续的业务不会产生混乱。而这一场景就可以依赖rocketmq完成,后续我们会详细讲解实现步骤。
- 分布式事务
熟悉mysql的同学应该清楚事务执行,但分布式事务的操作,一可以依赖一些分布式组件,如seata来实现,但某些场景下,比如还是上述说的,我们有大量事件堆积的情况下,需要MQ来缓冲,而我们有需要满足事务,这种所谓的事务是指什么呢? 就是在这条消息消费并执行完后续的处理事件之前,如果发生了报错,可以让这条消息的消费回退,下次可以再次消费,以此称为分布式事务消息,这类场景也不少见,而rocketmq独有的事务消息可以很好的帮助我们解决该问题。
- 延迟操作
延迟操作在很多业务中都有需求,比如最常见的30分钟未支付自动关闭订单,定时重发等等,这一类的需求就需要MQ支持延迟消息的特性,而rocketmq的延迟消息虽然不如rabbitmq那样支持自定义的延迟时间,但是预设的16级延迟时间档位也足够我们应付绝大部分业务场景
- 定时消息
定时消息实际上是延迟消息的一种变种,可以用定时任务完成,如定时推送订阅消息等,也可以借助延迟消息的特性来完成此类场景
3. rocketMQ与其他MQ的差异
3.1 主要差异
首先引入advanced-java项目中对比的几款常用MQ

其中activeMQ实际已经很少使用,逐渐在退出研发者的视野。重点分析下rabbitMQ、rocektMQ、kafka的差异
rabbitmq相对出现的周期更长,功能性上更加完善,支持很多的拓展插件,如果你的项目对于吞吐量没有那么高的要求,只是需要个万级的MQ来做一些解耦、缓冲等,那么推荐rabbitmq。
但如果考虑后续要增加业务量,或者有不和预期的流量激增,那么更加推荐rocketmq,且因为是阿里开源的,文档性上相对更加友好,代码习惯更加符合国人习惯。但在大批量数据下可能有丢数据的风险,需要经过细致的调优。
kafka主要出现在大数据行业场景,同时像ELK之类的海量日志数据处理也会出现kafka的应用之地,同样有丢消息的诟病,优点是比rocketmq支持更加庞大的吞吐量。
3.2 架构差异
我们之前一起学习过rabbitmq,大家会了解到其中有路由的概念,相对来说rabbitmq的架构是有交换机来做一层分发的

而在rocketmq中就没有交换机的分发了,通过topic来划分不同的队列,消费者通过订阅topic来接收消息,同时消费者、生产者都可以区分不同的群组

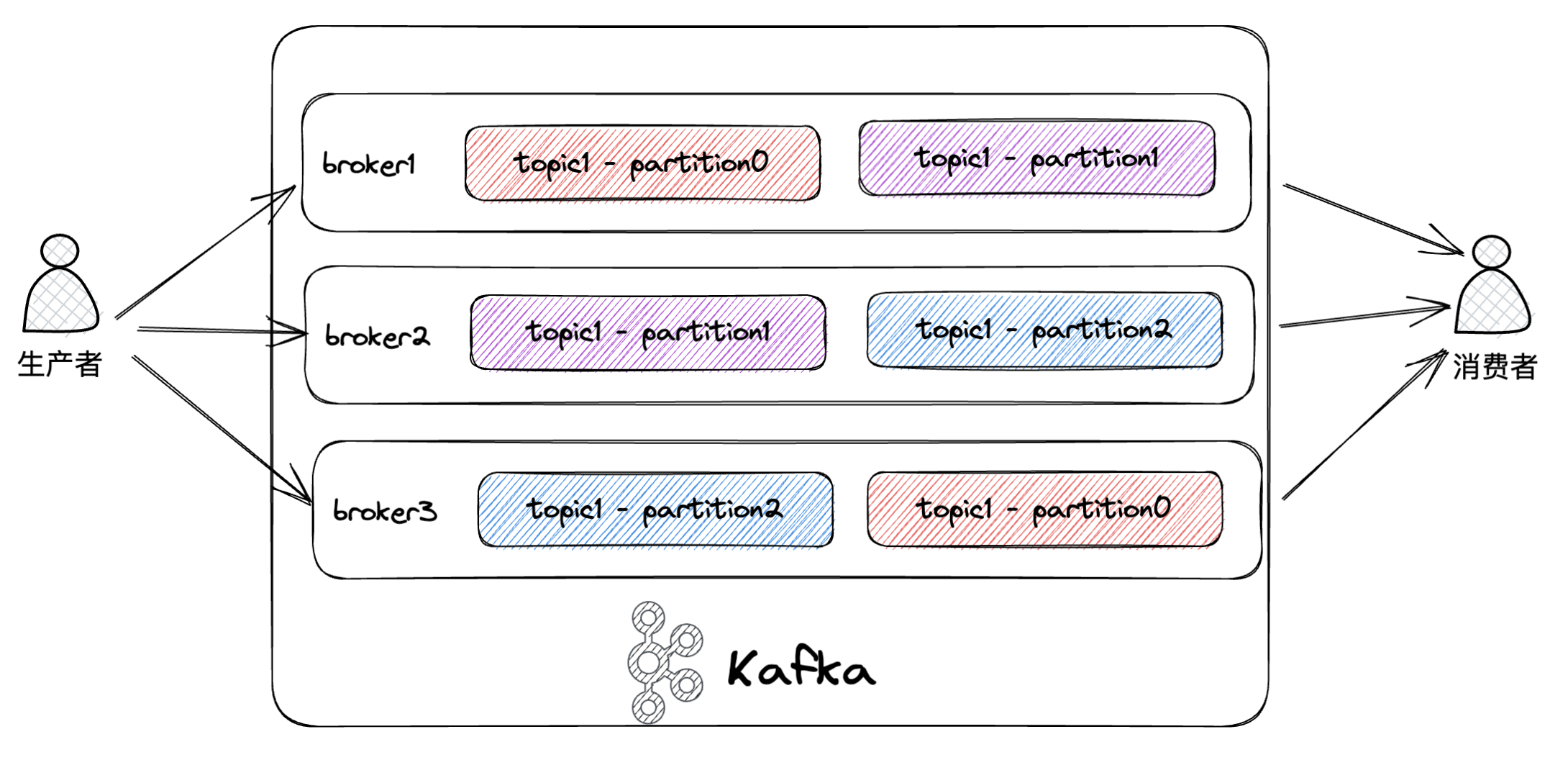
相对kafka的架构就更加复杂,通过zookeeper来管理集群,采用broker服务存储消息,与rocketmq相同的是,也有主题topic的概念,消费者也通过订阅主题来接收相关的消息。不同的是kafka中有分区partition,一个topic会被切分为多个分割成多个较小的、有序的数据单元,每个数据单元就是一个partition。相对来说提高了kafka的并发能力,并且会创建分区副本存储到不同的broker上,以此提高可用性。
4. 总结
从上文可以看到rocketmq中实际上是有namesrv , broker两个组件的,除此之外rocketmq还有一个管理端,而这三个组件之前的关系是什么,如何协同合作的? 我们将在下一节讲解。