目录
字符集知识
1、GBK字符集
2、Unicode字符集(万国码)
3、乱码
4、Java中编码和解码的方法

字符集知识
字符(Character):在计算机和电信技术中,一个字符是一个单位的字形、类字形单位或符号的基本信息。说的简单点字符是各种文字和符号的总称。一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号、一个图形符号或者控制符号等。
字符集(Character Set):是指多个字符的集合。不同的字符集包含的字符个数不一样、包含的字符不一样、对字符的编码方式也不一样。
计算机中常见的几种字符集:
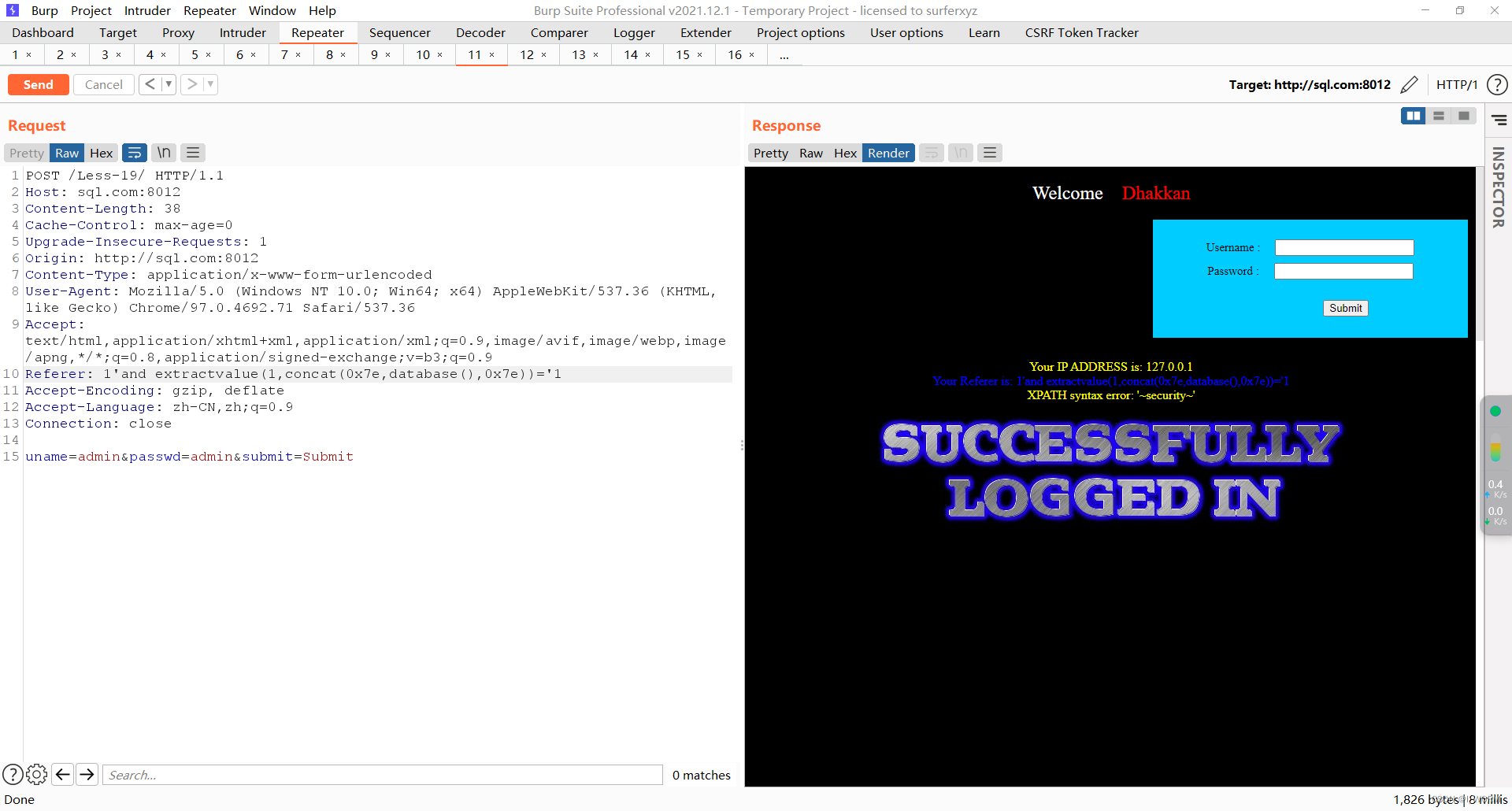
1、GB2312字符集:1980年发布,1981年5月1日实施的简体中文汉字编码国家标准。
收录7445个图形字符,其中包括6763个简体汉字
2、BIG5字符集:台湾地区繁体中文标准字符集,共收录13053个中文字,1984年实施。
3、GBK字符集:2000年3月17日发布,收录21003个汉字,包含国家标准GB 13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。简体中文版windows系统默认使用的就是GBK。系统显示:ANSI (统称为ANSI);GBK字符集完全兼容ASCII字符集4、Unicode字符集:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
1、GBK字符集
(1)计算机的存储规则(英文)(GBK),英文用一个字节存储,完全兼容ASCII
 (2)计算机的存储规则(汉字)(GBK),规则1:汉字两个字节存储;规则2:高位字节二进制一定以1开头,转成十进制之后是一个负数
(2)计算机的存储规则(汉字)(GBK),规则1:汉字两个字节存储;规则2:高位字节二进制一定以1开头,转成十进制之后是一个负数
 (3)英文与汉字区分:GBK当中,英文是用一个字节进行存储的,它是兼容ASCII字符集的,在编码的时候二进制前面要补零,所以英文一个字节二进制一定是以0作为开头的,而中文是两个字节,一定是以1作为开头的,那么底层的二进制文件也是通过这个规则来区分中文和英文的
(3)英文与汉字区分:GBK当中,英文是用一个字节进行存储的,它是兼容ASCII字符集的,在编码的时候二进制前面要补零,所以英文一个字节二进制一定是以0作为开头的,而中文是两个字节,一定是以1作为开头的,那么底层的二进制文件也是通过这个规则来区分中文和英文的

2、Unicode字符集(万国码)
Unicode的编码规则:UTF(Unicode Transfer Format)
UTF-16编码规则:用2~4个字节保存
UTF-32编码规则:固定使用四个字节保存
UTF-8编码规则:用1~4个字节保存
UTF-8编码规则
1个字节表示:ASCII
2个字节表示:拉丁文;希腊文;西里尔字母;亚美尼亚语;
希伯来文;阿拉伯文;叙利亚文
3个字节表示:中日韩文字;东南亚文字;中东文字
4个字节表示:其他语言

示例:把汉字“汉”用UTF-8转换成二进制为 11100110 10110001 10001001
二进制中的红色部分是UTF-8规定要添加的,而黑色的就是用Unicode中查询的汉字对应二进制进行填补得到的结果
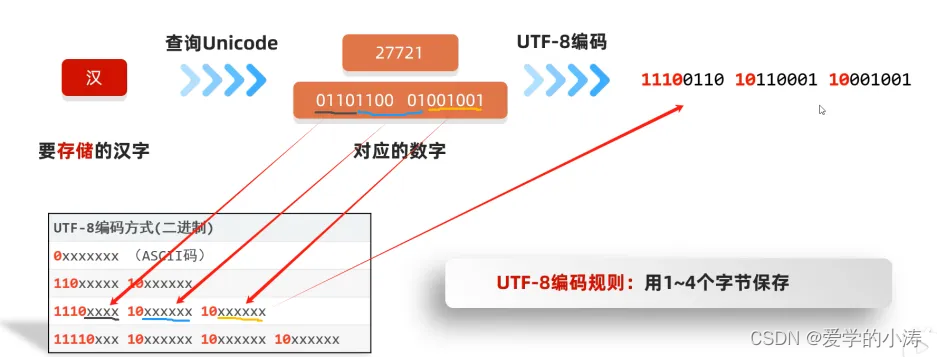
总结:Unicode字符集的UTF-8编码格式
一个英文占一个字节,二进制第一位是0,转成十进制是正数
一个中文占三个字节,二进制第一位是1,第一个字节转成十进制是负数
3、乱码
乱码的原因:
原因1:读取数据时未读完整个汉字,因为字节流是一次读取一个字节,而汉字是用两个字节来存储的,当字节流只读取了一个字节后,把这个字节解码去字符集却查不到对应的数据,所以系统就会显示问号或方框等,这时候就是乱码了。
原因2:编码和解码时的方式不统一,比如一个汉字在编码时用的是UTF-8,而在解码时却用GBK解码,因为UTF-8中用三个字节来存储汉字,而GBK中用两个字节来存储汉字,所以在解码后就会发生乱码。
防止乱码的做法:
1、不要用字节流读取文本文件
2、编码和解码时都使用同一个码表,同一种编码方式
4、Java中编码和解码的方法
Java中编码的方法
| public byte[ ] getBytes() | 使用默认方式进行编码 |
| public byte[ ] getBytes(String charsetName) | 使用指定方式进行编码 |
Java中解码的方法
| String(byte[ ] bytes) | 使用默认方式进行解码 |
| String(byte[ ] bytes, String charsetName) | 使用指定方式进行解码 |
方法示例代码:
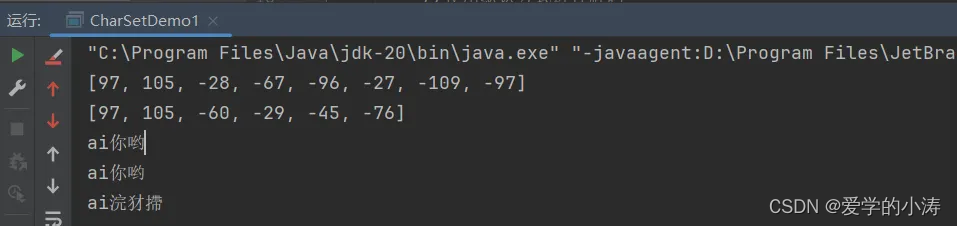
public static void main(String[] args) throws UnsupportedEncodingException {//使用默认方式进行编码String str1 = "ai你哟";byte[] bytes1 = str1.getBytes();System.out.println(Arrays.toString(bytes1));//[97, 105, -28, -67, -96, -27, -109, -97]//使用指定方式GBK进行编码byte[] bytes2 = str1.getBytes("GBK");System.out.println(Arrays.toString(bytes2));//[97, 105, -60, -29, -45, -76]//使用默认方式进行解码String str2 = new String(bytes1);System.out.println(str2);//ai你哟//使用指定方式GBK进行解码String str3 = new String(bytes2,"GBK");System.out.println(str3);//ai你哟//编码时用UTF-8得到的bytes1,却用GBK进行解码String str4 = new String(bytes1, "GBK");System.out.println(str4);//结果为:ai浣犲摕 很明显,乱码了
}运行结果:
了解字符集知识就可以更好的理解字符流了

推荐:
【java基础】IO流(一):字节流的FileOutputStream(文件字节输出流)和 Filelnputstream(文件字节输入流)-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/136631816?spm=1001.2014.3001.5501【java基础】异常处理机制-CSDN博客
https://blog.csdn.net/m0_65277261/article/details/136631816?spm=1001.2014.3001.5501【java基础】异常处理机制-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/136581375?spm=1001.2014.3001.5501【计算机网络】DHCP原理与配置-CSDN博客
https://blog.csdn.net/m0_65277261/article/details/136581375?spm=1001.2014.3001.5501【计算机网络】DHCP原理与配置-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/136230649?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_65277261/article/details/136230649?spm=1001.2014.3001.5501