RepViT: Revisiting Mobile CNN From ViT Perspective
论文链接:https://arxiv.org/abs/2307.09283
代码链接:https://github.com/THU-MIG/RepViT
一、摘要
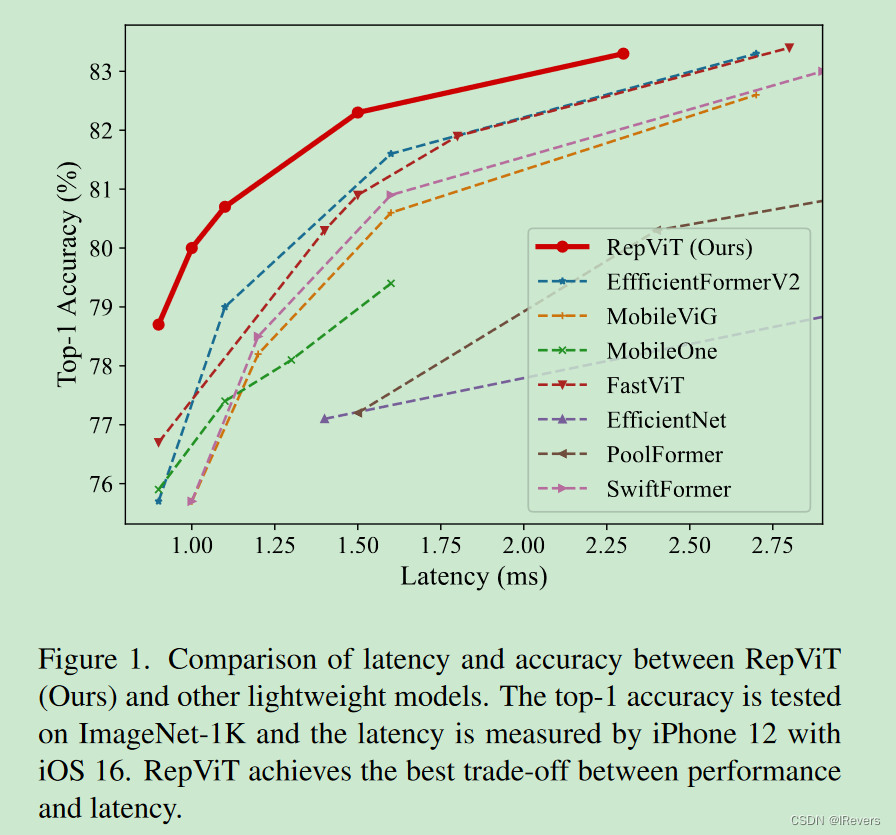
探究了许多轻量级ViTs和轻量级CNNs之间的结构联系。文中从ViT的视角重新审视轻量级CNNs的高效设计,并强调它们在移动设备上的前景。具体而言,通过整合轻量级ViTs的高效架构设计,逐步增强了标准轻量级CNN,最终形成了一系列全新的纯轻量级CNNs,即RepViT。大量实验证明,RepViT优于现有的轻量级ViTs,并在各种视觉任务中表现出有利的延迟。值得注意的是,在ImageNet上,RepViT在iPhone 12上以1.0毫秒的延迟实现了超过80%的top-1准确率,这是轻量级模型首次实现。最大的模型RepViT-M2.3,在只有2.3毫秒的延迟下获得了83.7%的准确率。此外,当RepViT遇到SAM时,RepViT-SAM比先进的MobileSAM实现了近10倍更快的推断速度。
二、原理
论文分别从分离token混合器和通道混合器、减小扩展比并增加宽度、起始卷积、更深的下采样层、分类器设计、整体比例、卷积核大小选择、SE层的放置等几个方面对MobileNetv3网络进行改进。
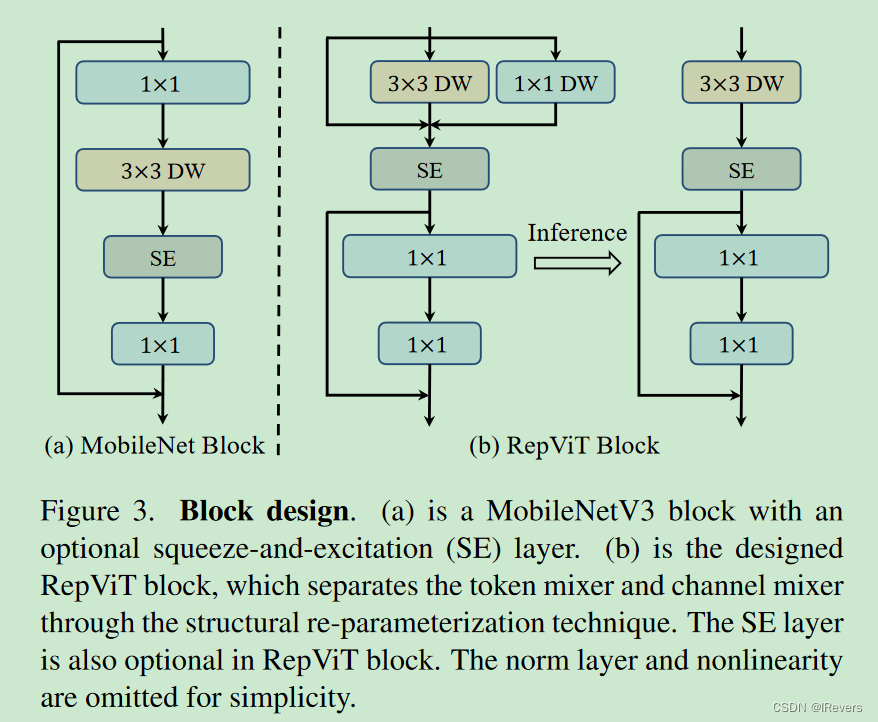
1、分离token混合器和通道混合器(DW卷积)
ViTs的有效性主要源于它们的通用令牌混合器和通道混合器架构,即MetaFormer架构,而不是配备的特定令牌混合器。在MobileNetV3块中分离了令牌混合器和通道混合器。我们进一步采用了一种广泛使用的结构重参数化技术来增强模型在训练期间的学习。由于结构重参数化技术,我们可以消除推断期间与跳过连接相关的计算和内存成本,这对移动设备尤为有利。我们将这样的块命名为RepViT块(图3.(b)),将MobileNetV3-L的延迟降低到0.81毫秒,同时将性能暂时降低到68.3%。
2、减小扩展比并增加宽度
在RepViT块中,将通道混合器中的扩展比设置为2,增加网络宽度以弥补大量参数减少,适用于所有阶段,这导致延迟降低到0.65毫秒。在每个阶段之后将通道加倍,最终得到48、96、192和384个通道。这些修改可以将top-1准确率提高到73.5%,延迟为0.89毫秒。
通过直接调整原始MobileNetV3块上的扩展比和网络宽度,我们在类似的延迟0.91毫秒下获得了73.0%的top-1准确率,性能较差。因此,在块设计中,默认情况下,我们采用RepViT块的新扩展比和网络宽度。
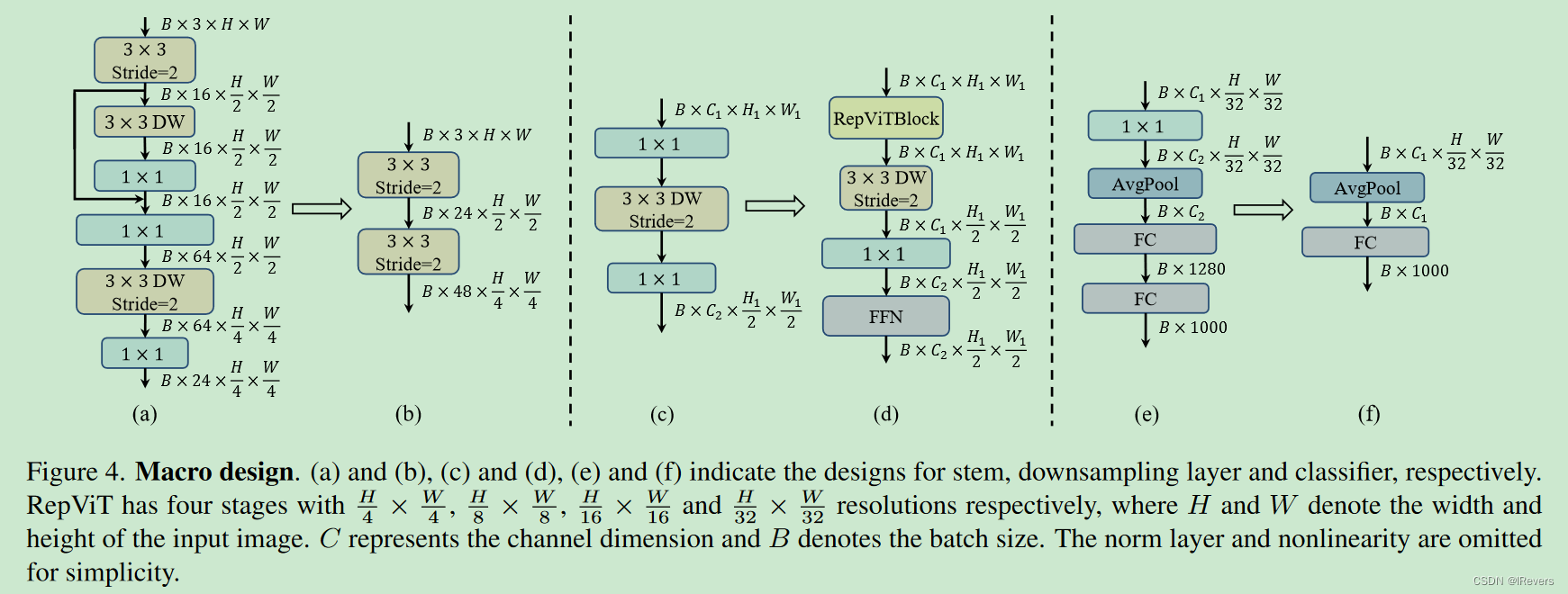
3、起始卷积
MobileNetV3-L将初始的滤波器数量减少到16,这限制了起始卷积的表示能力。简单地将两个步幅为2的3×3卷积作为起始卷积。如图4.(b)所示,第一个卷积中的滤波器数量设置为24,第二个卷积中的滤波器数量设置为48。整体延迟降低到0.86毫秒。同时,top-1准确率提高到73.9%。
4、更深的下采样层
MobileNetV3-L仅通过一个带有DW卷积的反向瓶颈块实现下采样,步幅为2,如图4.©所示。这种设计可能缺乏足够的网络深度,导致信息丢失并对模型性能产生负面影响。因此,为了实现一个单独且更深的下采样层,我们首先使用步幅为2的DW卷积和一个点卷积1×1卷积来执行空间下采样并调节通道维度,如图4.(d)所示。此外,我们在1×1卷积后面添加了一个RepViT块,进一步加深了下采样层。在1×1卷积之后放置了一个FFN模块,以记忆更多的潜在信息。因此,这样更深的下采样层将top-1准确率提高到75.4%,延迟为0.96毫秒。
5、分类器设计
MobileNetV3-L采用了一个复杂的分类器,其中包括一个额外的1×1卷积层和一个额外的线性层,将特征扩展到更高维空间。考虑到最终阶段的输出通道较小。然而,这反过来会给移动设备的延迟带来沉重负担。将其替换为一个简单的分类器,即一个全局平均池化层和一个线性层,如图4.(f)所示。这一步导致准确率下降了0.6%,但使延迟降低到0.77毫秒。
6、整体比例
EfficientFormer-L2采用了一个阶段比例为1:1:3:1.5。同时,Conv2Former表明,更激进的阶段比例和更深的布局对于小型模型效果更好。因此,它们分别为Conv2Former-T和Conv2Former-S采用了1:1:4:1和1:1:8:1的阶段比例。在这里,我们为网络采用了一个阶段比例为1:1:7:1。然后我们增加网络深度为2:2:14:2,实现更深的布局。这一步将top-1准确率提高到76.9%,延迟为0.91毫秒。
7、卷积核大小选择
CNN的性能和延迟通常受卷积核大小的影响。例如,为了捕获类似MHSA的远程依赖关系,ConvNeXt采用了大尺寸的卷积核,表现出性能提升。类似地,Re-pLKNet [15]展示了一种利用超大卷积核在CNN中的强大范例。然而,大尺寸卷积核对于移动设备来说并不友好,因为它的计算复杂性和内存访问成本。此外,与3×3卷积相比,更大的卷积核通常不太受编译器和计算库的高度优化。MobileNetV3-L主要采用3×3卷积,在某些块中使用少量的5×5卷积。为了确保在移动设备上的推理效率,在所有模块中优先考虑简单的3×3卷积。这种替换可以保持76.9%的top-1准确率,同时将延迟降低到0.89毫秒。
8、SE层的放置
与卷积相比,自注意力模块的一个优势是根据输入调整权重的能力,即数据驱动属性。作为一个通道注意力模块,SE层可以弥补卷积在缺乏数据驱动属性方面的局限性,带来更好的性能。MobileNetV3-L在某些块中整合了SE层,主要集中在后两个阶段。然而,低分辨率特征图的阶段与高分辨率特征图的阶段相比,准确性收益较小。与性能提升同时,SE层也引入了不可忽略的计算成本。因此,我们设计了一种策略,以跨块的方式利用SE层,即在每个阶段的第1、3、5…个块中采用SE层,以最大化准确性收益并最小化延迟增量。这一步将将top-1准确率提高到77.4%,延迟为0.87毫秒。
多个RepViT变体,包括RepViT-M0.9/M1.0/M1.1/M1.5/M2.3。后缀“-MX”表示相应模型在移动设备上(即iOS 16上的iPhone 12)的延迟为X毫秒。这些变体通过每个阶段中的通道数和块数来区分。
三、实验部分
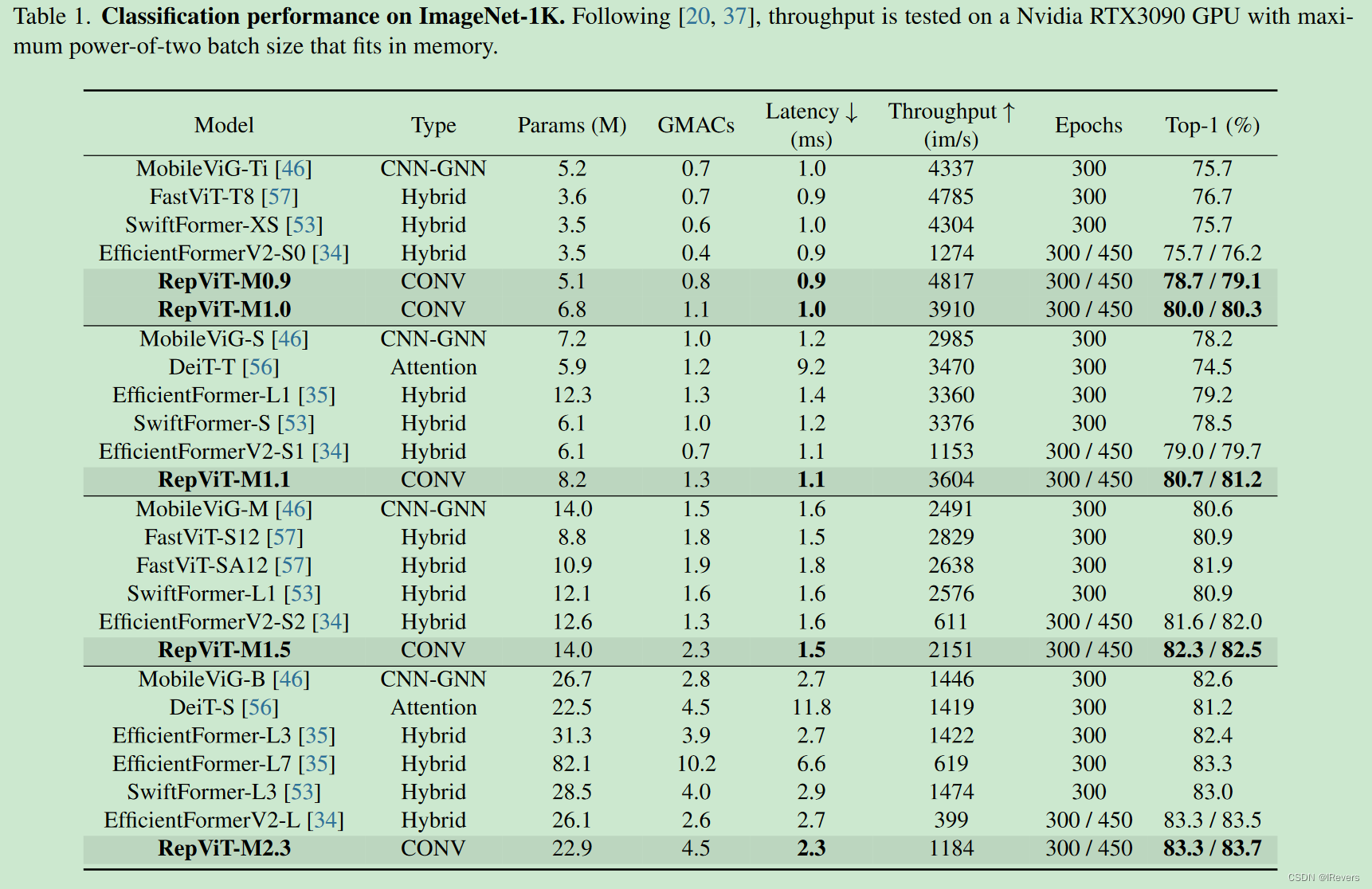
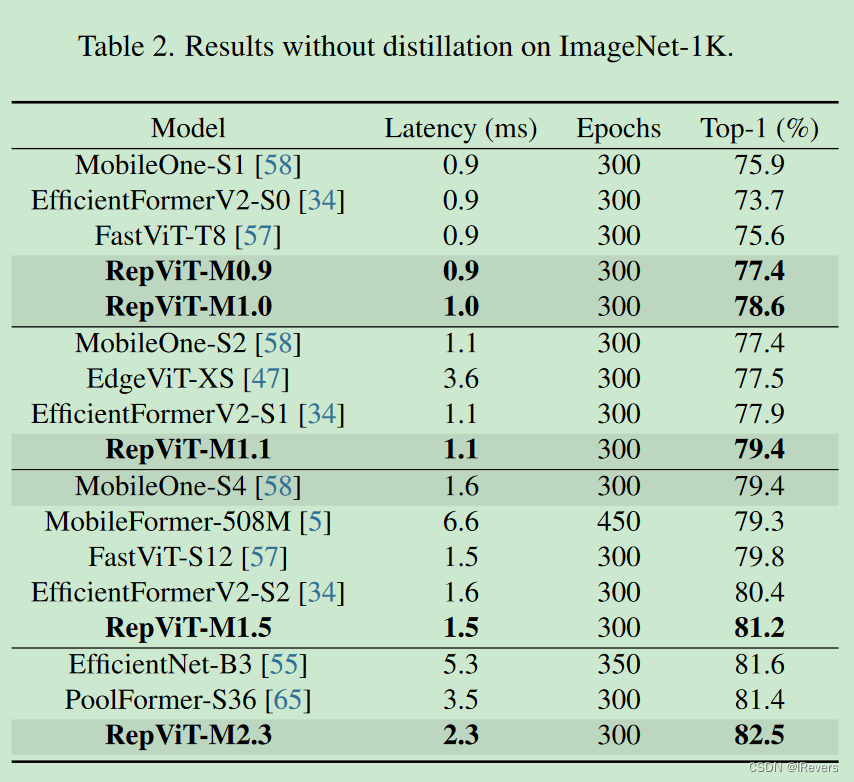
1、图像分类
为了公平比较,RegNetY-16GF模型的top-1准确率为82.9%,被用作蒸馏的教师模型。按照[34,35,58]的方法,在iPhone 12上使用Core ML Tools编译的模型,在批量大小为1的情况下测量延迟。需要注意的是,RepViT-M0.9是与MobileNetV3-L对等的模型。
2、SAM和零样本边缘检测
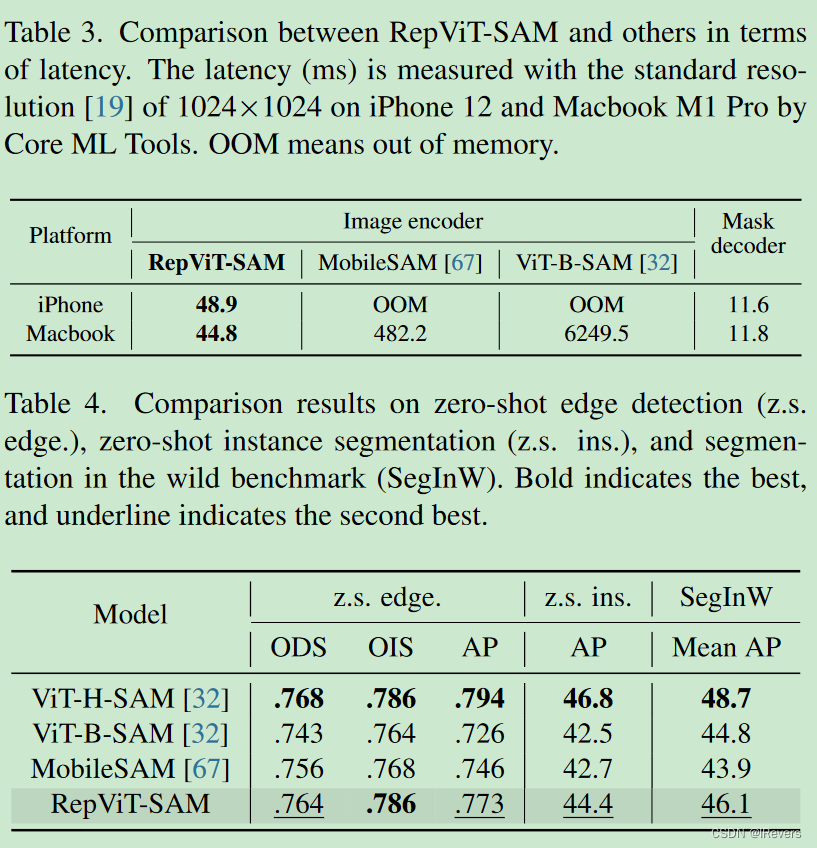
将SAM中的沉重图像编码器替换为我们的RepViT模型,最终得到RepViT-SAM模型。具体而言,RepViT-SAM采用RepViT-M2.3作为图像编码器,并在与[67]相同的设置下进行了为期8个时期的训练。与MobileSAM [67]一样,我们仅使用SAM-1B数据集中的1%数据进行训练。
在iPhone 12上,我们的RepViT-SAM可以顺利执行模型推断,而两个竞争对手均无法运行。在Macbook M1 Pro上,RepViT-SAM几乎比最先进的MobileSAM快10倍。
使用BSDS500进行零样本边缘检测,使用COCO进行零样本实例分割,以及使用SegInW进行野外分割基准测试。如表4所示,我们的RepViT-SAM在所有基准测试中均优于MobileSAM和ViT-B-SAM。与ViT-H-SAM相比,后者是具有超过615M参数的最大SAM模型,我们的小型RepViT-SAM在零样本边缘检测的ODS和OIS方面可以获得可比的性能。
3、下游任务(目标检测和实例分割)
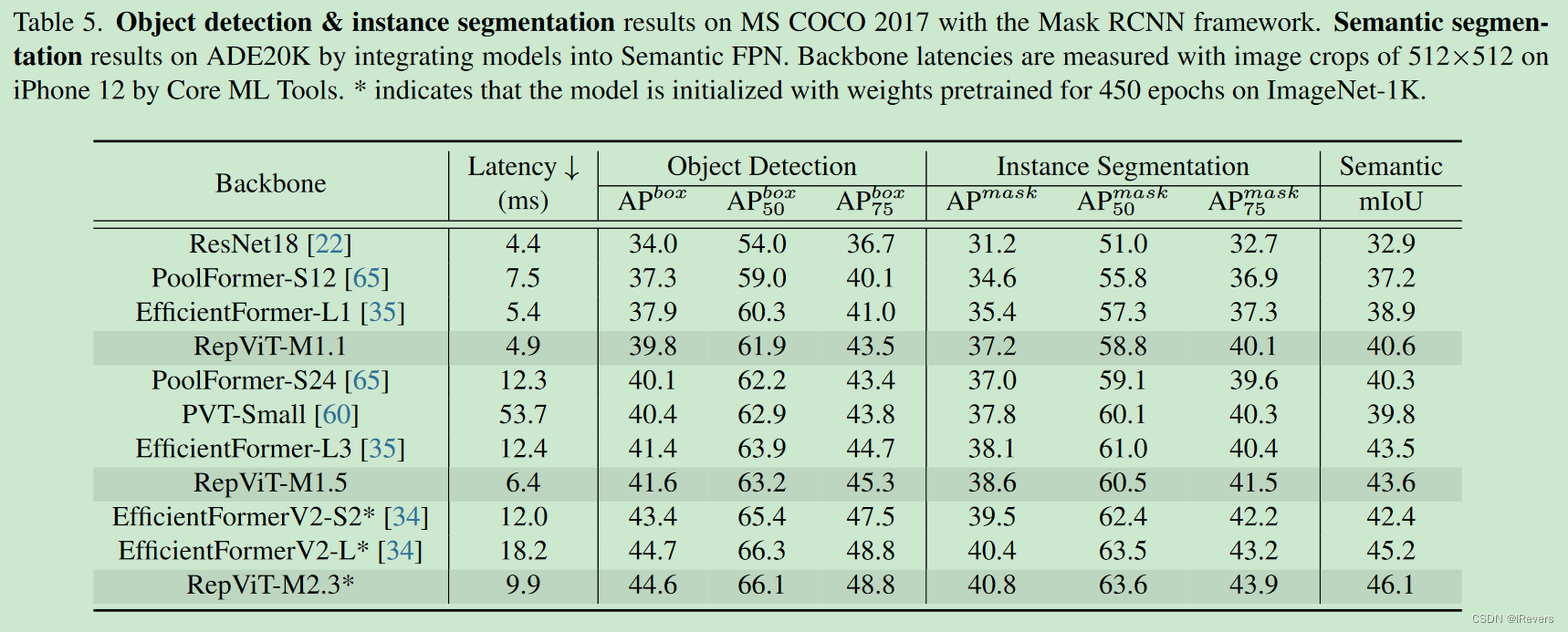
RepViT-M1.1在延迟更小的情况下,显著优于EfficientFormer-L1骨干网络1.9个AP框和1.8个AP掩码。对于更大的模型尺寸,RepViT-M1.5在享有可比性能的同时,比EfficientFormer-L3快近2倍。与EfficientFormerV2-L相比,RepViT-M2.3在几乎50%的延迟下实现了可比的AP框和更高的AP掩码,突显了轻量级CNN在高分辨率视觉任务中的重大优势。
将RepViT作为Semantic FPN框架中的骨干网络。如表5所示,RepViT在不同模型尺寸下始终展现出有利的mIoU-延迟权衡。例如,RepViT-M1.1在更快的速度下,比EfficientFormer-L1高出1.7个mIoU。RepViT-M1.5在几乎50%的延迟减少的同时,比EfficientFormerV2-S2高出1.2个mIoU。与EfficientFormerV2-L相比,RepViT-M2.3在几乎2倍的速度下呈现出0.9个mIoU的增加。
4、模型分析
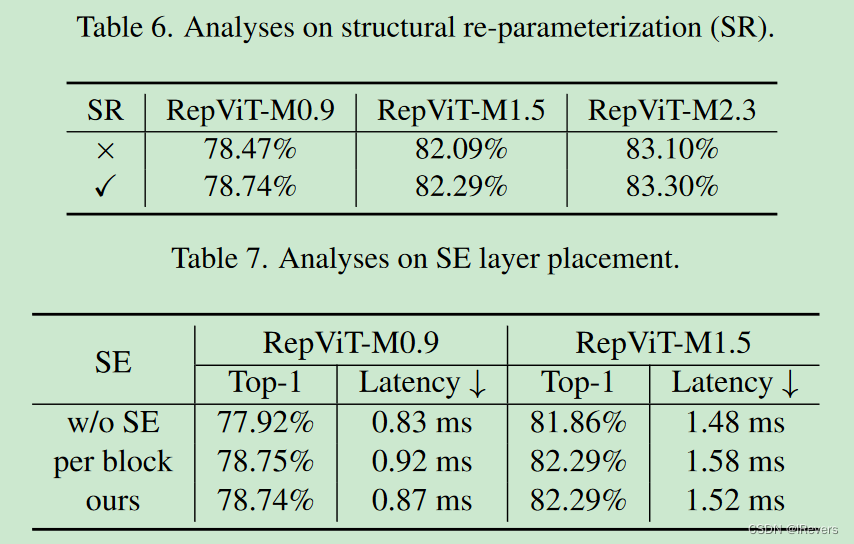
结构重参数化(SR)。为了验证在RepViT块中SR的有效性,我们通过在ImageNet-1K上去除训练时SR的多分支拓扑结构进行消融研究。如表6所示,没有SR时,所提出的RepViT的不同变体都表现出持续的性能下降。结果充分证明了SR的积极影响。
SE层的放置。为了验证在所有阶段交叉块方式利用SE层的优势,我们通过在ImageNet-1K上进行消除所有SE层(即“无SE”)和在每个块中采用SE层(即“每个块”)的消融研究。如表7所示,交替在块中采用SE层显示出更有利的精度和延迟权衡。
四、总结
作者从ViT的角度出发重新设计了MobileNetv3,得到了一系列全新的纯轻量级CNN,即RepViT。在ImageNet数据集分类任务上,RepViT在iPhone 12上实现了超过80%的top-1准确率,延迟为1.0毫秒。文中也在SAM、零样本边缘检测、目标检测和实例分割任务上进行了实验,效果相比轻量级的ViT更具有竞争力。