当代人打工不息,为手中的饭碗焦虑不止。
前几天还在抱怨自己的职场保质期追不上退休年龄延后的速度,如今又开始忧虑于会被AI取代。

很多人最近都被一个叫“ChatGPT”的人工智能刷屏了。这个去年11月诞生的聊天机器人,现在俨然成了AI消灭人类暴政的急先锋。
即使你过去从不关心科技领域,也难逃相关讨论的包围,而且一个比一个吓人:
“机器人即将取代这10个工种,快看看你的行业在不在其中”“未来底层岗位将消失,几百亿人流离失所!”

我兢兢业业上班,工作咋就被抢了?然而口号一个比一个喊得危言耸听,却没人能解释清楚到底怎么个抢法。
以至于让普通人纷纷产生了某种焦虑的疑惑——“ChatGPT到底是个啥东西?它能比我还便宜吗?”
尽管这几天才真正爆火,但这个聊天机器人其实早在三个月刚诞生时,就已经吸引了不少科技圈爱好者的注意。
当时形象还不是什么“抢饭碗大魔头”,而是一个问什么就答什么的硅基小可爱。

《论AI是如何安慰人类的》。因为能够记住之前的交流内容并联系上下文语境,跟它的对话更像是跟人在聊天。
所以一开始大家喜欢提很多刁钻的问题。
ChatGPT也很争气,不会像市面上的“人工智障”那样,只能重复机械敷衍的回答。
ChatGPT是一款人工智能聊天软件,而他最基础的使用方式,就是聊天。
想要体验chatgpt,打开网站:简凡AI,地址:6om.net 立即开始体验。

相比之下,Siri就傻的好笑。
而是会给出相当像模像样的建议——比如下面这种。

“没有正当理由的情况下,试图取代你的老板是不道德的。”图源Vista氢商业。
另一种特别流行的玩法,是让ChatGPT写论文、写简历离职信等各种文案,甚至是小说、诗歌。
……不瞒各位,我当时也废寝忘食地玩了一个下午,并对它的逻辑性和脑洞深深震惊。

之后看家里的扫地机器人都不太顺眼——
“看看人家AI已经会写小说了,而你连一个桌子腿都绕不过去。”
结果没想到,最后真正一败涂地的是我们自己?
这一波ChatGPT在大众层面上广泛出圈,其实源于最近几个看起来很唬人的新闻。
一是上个月北密歇根大学某位哲学教授在课堂上评出了一篇“全班最佳论文”,
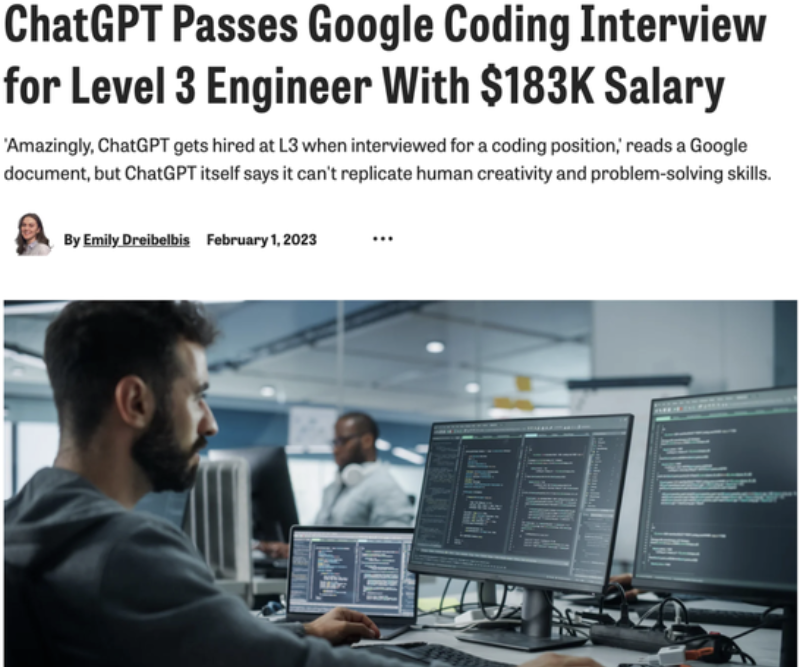
结果发现学生是用ChatGPT写的;二是有人用拿谷歌的编程面试题去问ChatGPT
,结果发现它的准确率达到了L3工程师的水平,而这个岗位的年薪水平差不多在18万美元。
三是它最近在外媒上极高的出镜率:微软说要发布“ChatGPT版搜索引擎”;
新媒体巨头Buzzfeed宣布将用AI创作内容。就连以色列总统的发言稿,都让ChatGPT给他加了几个“金句”。
名校大学生、高薪程序员,都是普通打工人摸不到的高度,结果被AI轻松拿下。
难免会让大家产生危机感——当初各国顶尖棋手在AlphaGo面前纷纷失利,旁观者还以为是新老文明在顶峰水平的智力交锋,跟自己没啥关系。
没想到绝顶聪明的人工智能老爷们,这么快就来抢咱普通人的饭碗了……吗?

如果你这两天经常在逛社交平台,大概率会觉得ChatGPT的出现已经成为了人类的末日。
首先被单方面宣布失业的是程序员。

ChatGPT跟其他聊天机器人最大的区别,就在于它能写代码。
网上又不少程序员晒出了自己的问答截图——如果你的需求提得够精准,的确可以实现比较简单的需求。
注意,是简单的需求,而且还得靠程序员在旁边盯着随时审核。根据业内专家分析,如果完全让ChatGPT独立写一段程序,很可能会因为错误叠加把整个系统写垮。
而程序员后续来查错时也无法一下子找到问题。
但在很多博主的口中,随着身为硅基生命的AI们找回了他们的母语,当初下决心转码的打工人们已然悔不当初。
“现在学编程,就相当于在打字机诞生后成为抄写员。“
紧接着被提上失业日程的岗位,是文案工作者。
其实很多人早就发现用ChatGPT写一些模式化的文本非常好用,
比如辞职信、简历、签证申请文章、周报……

但在各种“ChatGPT颠覆人类”的论调中,整个白领群体已经迅速被扔进了历史的垃圾堆:
“正如机械的发明取代了体力工作者,ChatGPT的出现这次取代的是脑力工作者。”

其中最忙的,还要属职场类网红和教育类网红。
前者掷地有声地建议大家具备危机意识、提早做准备;
后者则一脸严肃,为孩子们未来的择业道路而担忧。
在这种紧张气氛下,不仅是文秘、客服之类的基础文案工作。
就连律师、医生这种专业性更强的工种,似乎都已经摇摇欲坠。
甚至有人干脆喊出了一些匪夷所思的口号——“未来最吃香的工作是保洁、销售一类的服务型蓝领”。
咋说呢,如果AI已经到了如此发达的高度,给自己安个机械臂还不是分分钟的事儿?

但依然拦不住,各行各业纷纷站出来表示自己即将被淘汰,仿佛还没被AI盯上的都算不上什么主流行业。
就连营养师和家居整理师都在谈论,“如何在人工智能面前增加个人的核心竞争力。”

毫不夸张地说,在目前所谓“划时代”的氛围下,人人都理所当然想蹭上这辆车。
最直观的表现是,这几天ChatGPT的概念股一路飙涨。根据“豹变”报道,汉王科技最近获得了连续七个涨停板。
它的发明专利中覆盖了“自然语言处理技术”,而ChatGPT恰恰是一个出色的自然语言识别新模型。

在对ChatGPT最赞不绝口的声音中,不少人将它的意义与苹果造出iPhone类比。
如果真是这样不难理解大众的狂热和恐慌,因为一项彻底的创新往往能摧毁很多行业,也能新生很多行业

好多人在问说:我能训个ChatGPT吗?
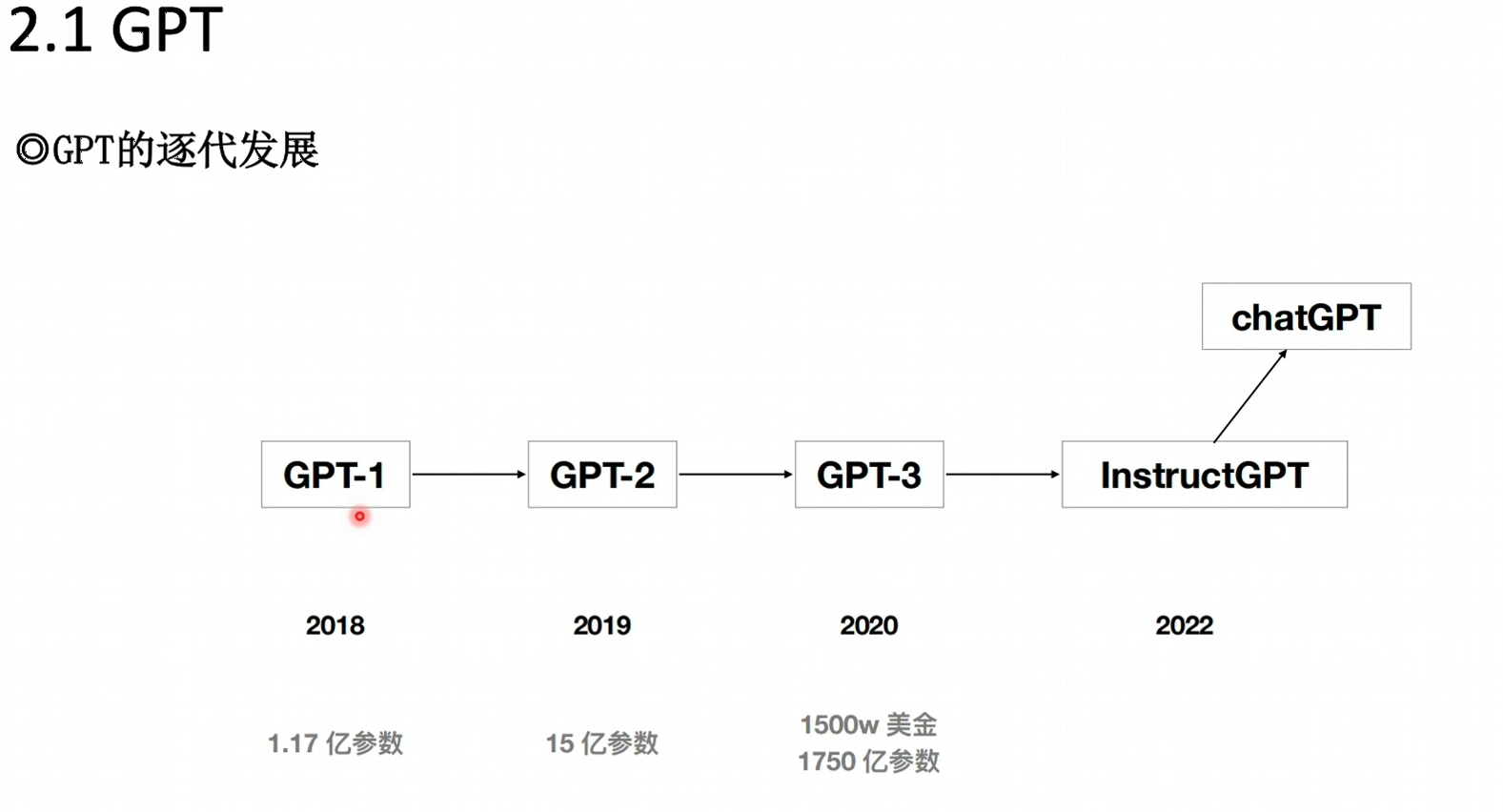
简单地回答:极大概率是不能的。起码在现阶段,这不是招几个人、花些钱就能做成的事,能训出ChatGPT的人可能比做出4纳米芯片的人还要少。
这其中的原因是什么?咱先来捋捋ChatGPT超能力的来源,再对比看看自己手中的家底。
01:算 力
算力,也就是数据的处理能力,与数据、算法,并称为AI三要素。据估计,仅仅训练一次GPT-3,Open AI可是花费了460万美元。对于ChatGPT而言,支撑其算力基础设施至少需要上万颗英伟达A100的GPU,一次模型训练成本超过1200万美元,研发总费用可能高达2760万美元。而且,模型训练完成部署上线后,跑起来仍然要不可小觑的算力。大模型的商业模式下,最终获益的是芯片厂商。 然而,在这些必要非充分条件中,算力是最容易解决的。
0 2:数 据
模型要足够深、足够大,才能解决远距离的语义理解能力、才能产生抽象的推理能力,这些高级的基础的能力具有很好的通用性。因此,高级的能力可能只存在于大型模型中,而训练大模型,需要足够的数据量。全球高质量文本数据的总存量在4.6万亿到17.2万亿个字符之间。这包括了世界上所有的书籍、科学论文、新闻文章、维基百科、公开代码以及网络上经过筛选的达标数据,例如网页、博客和社交媒体。最近的一项研究数据显示,数据总数大约为3.2万亿个字符。DeepMind的Chinchilla模型是在1.4万亿个字符上训练的。也就是说,在这个数量级内,我们很有可能耗尽世界上所有有用的语言训练数据。此外,反观中文网站的数据资源,大致占全世界总资源的1.3%。中文内容相比英文有四五十倍的差距,人工智能脱离不了人类知识的土壤,这方面的先天条件不是短期内花钱或凭一己之力就能解决的。
03:人 才
ChatGPT公开出来的少量材料中,披露出了一系列训练技巧,比如:代码训练、指令微调、上下文学习等。更多的细节目前还没有公开,即便公开了也不见得是全部,即便全部公开也未必能重现。因为整个过程链条非常长,有大量的工程技巧在里边。俗话说魔鬼藏在细节里,具体的实现和工程技巧才是重头戏,好比刚学做菜的人,即便有足够的食材,照着菜谱也不可能做出一套满汉全席。今年2月初,谷歌已向人工智能初创公司Anthropic投资约3亿美元,并获得该公司10%股份。该公司2021年创立,目前团队规模仅在40人左右,初创期的11位核心成员都曾经参与过GPT-2、GPT-3模型的研发。可见,业界对于人才的重视程度以及人才的奇缺性。
划重点
说了这么多,总结一下重点,不管你能记住多少,起码下次在电梯里遇到老板或者在饭局上遇到同学时,聊起ChatGPT,你能插上几句话。关于大规模语言模型:训练时要用到万亿级的数据、花费百万美元的算力,才能使它能说人话,并具有一定的“思维链”推理能力。大模型的超能力:模型要足够深、足够大,才能产生抽象的推理能力,这些高级的基础能力具有很好的通用性。大模型革命的一个关键趋势就是,通用大模型比专用小模型表现地更好,打破了人们一项固有认知:“通用的不好用,好用的不通用。”