文章目录
- 前言
- 一、模型结构
- 二、数据工程
- 总结
前言
Vary的提出让大模型在OCR相关任务的能力有了很大突破,通过提出额外的视觉词汇表模块来弥补单一CLIP编码能力的不足,详情可参考我之前的文章——多模态:Vary。
最近Vary的团队开发了一个更小版本的Vary模型——1.8B Vary-toy,与Vary相比,Vary-toy除了小之外,还优化了新视觉词表。解决了原Vary只用新视觉词表做pdf ocr的网络容量浪费,以及吃不到SAM预训练优势的问题。与Vary-toy同时发布的还有更强的视觉词表网络,其不仅能做pdf-level ocr,还能做通用视觉目标检测。
Vary-toy在消费级显卡可训练、8G显存的老显卡可运行,依旧支持中英文!这个“小”VLM几乎涵盖了目前LVLM主流研究中的所有能力:Document OCR、Visual Grounding、Image Caption、VQA……
Report:https://arxiv.org/abs/2401.12503

一、模型结构
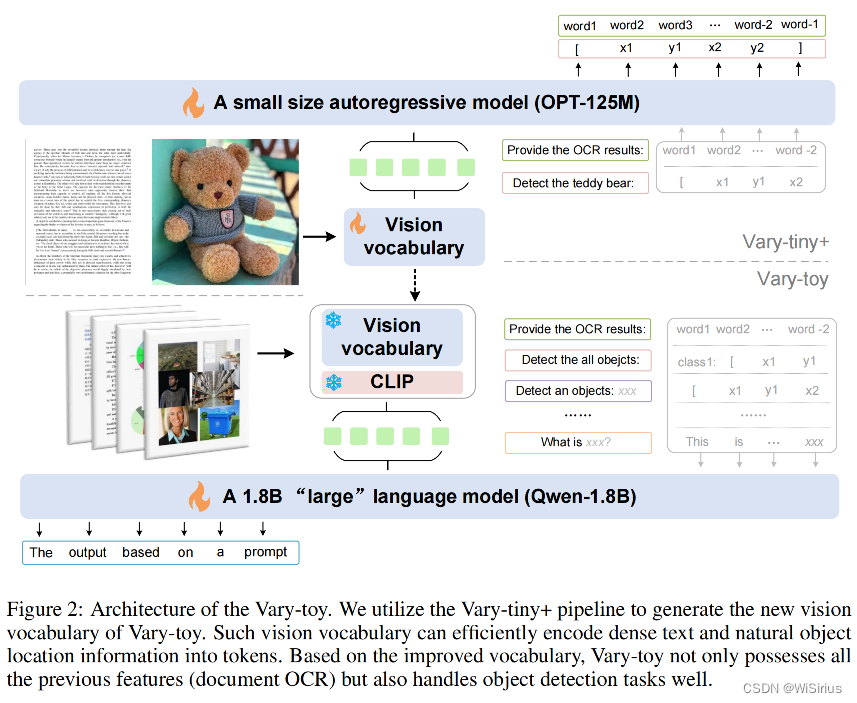
Vary-toy的模型结构和训练流程如上图所示,大体上继承了Vary,使用Vary-tiny+,pretrain出一个更好的视觉词表,然后将训好的视觉词表merge到最终结构进行multi-task training(预训练)/SFT(监督微调)。
(注意这里的Vary-tiny+相比之前的Vary-tiny采用了更精细的数据和prompt)
模型输入与之前的Vary还有一些小的区别。当输入形状为H×W的图像时,新的视觉词汇分支将直接将图像大小调整为1024×1024,而CLIP分支通过中心裁剪获得224×224图像。两个分支都输出256个令牌,通道为1024。Qwen-1.8B输入通道的维数也是2048,所以最简单的方法是直接将两个分支中的图像标记连接起来作为语言模型的输入图像标记。在代码实现方面,为了保持与Vary结构的一致性,仍然在视觉词汇网络后面添加了输入嵌入层。
二、数据工程
一个好的数据配比对于产生一个能力全面的VLM是很重要的。因此在pretrain阶段,作者使用了5种任务类型的数据构建对话,数据配比和示例prompt如下;而在SFT阶段,只使用了LLaVA-80K数据。
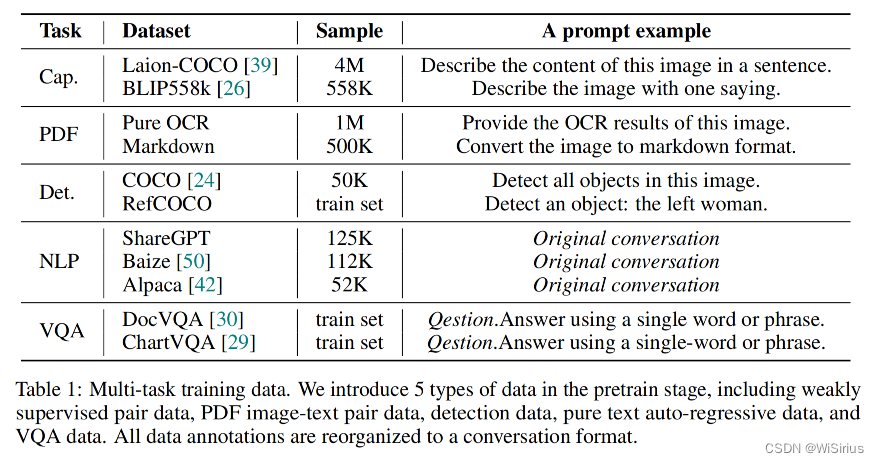
与Vary-tiny的单一输入输出形式不同,Vary-tiny+需要不同的提示来引导模型输出正确的结果,因此需要多种输入格式来适应相应的任务。为了简单起见,作者使用Vicuna v1的模板来构建对话格式的所有ground truth,如
USER: “” “texts input” ASSITANT: “texts output” 。作者添加了“”和“”作为OPT-125M文本标记器的特殊标记,实验发现它可以很好地适应Vicuna模板。对于视觉输入分支,不使用任何增强,只将图像调整为固定分辨率,即1024×1024。
另外为了充分利用视觉词汇网络的能力,从SAM初始化中获得自然的图像感知能力,作者在视觉词汇生成过程中引入了目标检测数据。从两个大型开源数据集中收集样本,即Object365和OpenImage。由于在OPT的文本标记器中坐标(数字文本)编码的效率较低,对于对象过多的图像,ground truth中的标记数量可能会超过OPT- 125m支持的最大标记长度(尽管我们将其插值为4096)。因此,作者将注释重新组织为两个任务:
1) 对象检测: 如果图像中物体框数目<30个,则允许Vary-tiny + pipeline过程中的prompt为Detect all objects in this image。
2) REC(表达理解) : 如果图像中物体框数目>30个,则更换prompt模板为:Detect class1, class2, … in this image。通过上述方式,获得了大约3M的检测数据。

总结
Vary-toy这种小巧且能力强悍的模型还是很值得大家研究改进的,部署落地较为容易,迭代也会比较迅速。虽然天花板较低,但是很适合大模型的初学者进行研究。