On Complementarity Objectives for Hybrid Retrieval
- 摘要
- 1. 引言
- 2. 相关工作
- 2.1 稀疏和密集检索
- 2.2 互补性
- 3. 提出方法
- 3.1 Ratio of Complementarity (RoC)
- 3.2 词汇表示(S)
- 3.3 语义表示(D)
- 3.4 互补目标
- 4. 实验
- 4.1 实验设置
- 4.2 实验结果
- 4.2.1 RQ1:正交性的有效性
- 4.2.2 RQ2:RoC 改进互补性
- 4.2.3 RQ3:混合检索中互补性的影响
- 5. 结论
- 6. 局限性
原文链接:https://aclanthology.org/2023.acl-long.746/
(2023)
摘要
密集检索在各种信息检索任务中都显示出了可喜的结果,而与稀疏检索的优势相结合的混合检索也得到了积极的研究。混合检索的一个关键挑战是使稀疏和稠密互补。现有模型侧重于密集模型,以捕获稀疏模型中忽略的“剩余”特征。我们的主要区别是展示剩余互补性概念是如何受到限制的,并提出一个新的目标,表示为 RoC(互补性比率),它捕获了更全面的互补性概念。我们提出了一种旨在提高 RoC 的两级正交性,然后表明我们模型的改进 RoC 反过来又提高了混合检索的性能。我们的方法在三个代表性 IR 基准上优于所有最先进的方法:MSMARCOPassage、Natural Questions 和 TREC Robust04,具有统计显着性。我们的发现在各种对抗环境中也是一致的.
1)RoC:互补率
2)two-level 正交性 提高 RoC
3)RoC 的提高会提高混合检索的性能
1. 引言
混合检索:稀疏检索与密集检索结果线性相加 取更高得分
两种途径:
1)侧重密集检索,增加 D,捕获被稀疏检索忽略的特征
Ps:缺点是增大 D 的时候,D ∩ S 也会增大
2)本文:侧重 RoC,减少 D 与 S 的交叉
RoC 为什么可以 ?
1)RoC与上面途径1)兼容
2)增大 RoC 本质会增强混合检索
表示和匹配查询和文档(或答案)对于设计信息检索 (IR) 和开放域问答 (QA) 模型至关重要。现有的方法已分为稀疏检索和密集检索。
经典的稀疏(或符号)检索,例如 BM25(Robertson 和 Zaragoza,2009),量化查询 q 和文档 d 之间的词汇重叠(或精确匹配),并按词频 (tf) 和逆文档频率 (idf) 进行加权。这种计算可以有效地定位到一些具有倒排索引的高分 q-d 对,但可能无法匹配术语不匹配的对。例如,具有相同意图的文本对“facebook更改密码”和“fb修改passwd”不共享任何共同词,因此该对无法通过词法检索进行匹配。
为了克服这种不匹配,密集检索模型,例如基于 BERT 的 DPR(Karpukhin 等人,2020 年)或 coCondenser(Gao 和 Callan,2021 年),旨在通过将查询和文档编码为低维嵌入向量来支持软“语义匹配” 。训练密集表示,以便“password”和“passwd”在空间中位置接近,即使它们具有不同的词汇表示。
每个模型的这些互补优势产生了自然激励的混合模型(Gao et al, 2020; Yadav et al, 2020; Ma et al, 2021),我们将其表示为 BM25+DPR,从两个模型中提取分数并选择最高的文档线性组合分数
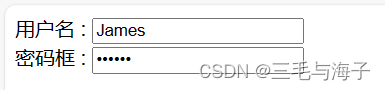
为了说明我们如何推进 BM25+DPR 基线,图 1(a) 显示了 BM25+DPR 在自然问题上的 Recall@10,其中黄色圆圈代表由 BM25 或 S 回答的问题,蓝色圆圈代表由 BM25 或 S 回答的问题DPR,或 D。理想情况下,两个检索器一起应该涵盖 U 域中的所有问题,但失败率为 46.5%,对应于 U − D ∪ S。
改进有两个方向:(1)放大|D| (2)使其与S更具互补性。图1(b)绘制了CLEAR(Gao等人,2020),旨在强调稀疏模型中忽略的“剩余”特征,或者增加|D − S|。
虽然 |D − S|故障率从 15.2%(图 1a)增加到 20.0%(图 1b),正如预期的那样,失败率并没有显着减少,从 46.5%(图 1a)到 41.8%(图 1b)。我们认为,扩大 |D| 会导致失败案例的减少。从 47.6(图 1a)到 54%(图 1b),与保持 D 固定的假设场景相比,但当交叉点减少时,故障案例从 41.8% 显着减少到 14.1%。
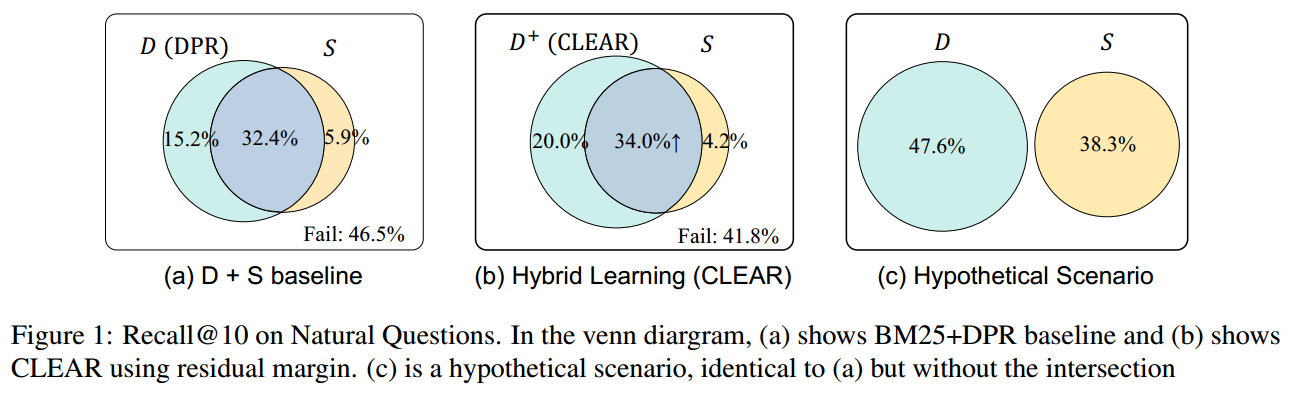
基于这些观察,我们提出了一种新的互补性度量,考虑了剩余互补性|D − S|,但相对于|D|,表示为互补性比率(RoC)。当两个模型不相交时,RoC 被设计为 1(图 1c);当 D 包含在 S 中时,RoC 被设计为 0。
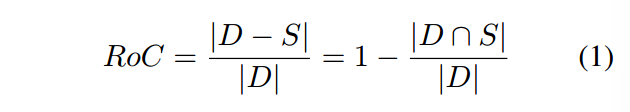
RoC具有以下两个优点:
• RoC向后兼容现有的剩余互补概念。我们稍后得出(第 3 节)优化 RoC 可以分为两个子目标:增加 |D − S|和 |D ∩ S|,其中前者与剩余互补性兼容。
• RoC 乘以|D ∪ S| 时,可直接近似混合模型可以回答的问题数量。因此,以提高 RoC 作为目标,自然与提高混合猎犬的性能相关。
凭借这些优势,我们使用表 1 中的指标来解释 CLEAR 仅建立在剩余互补性上的局限性。 CLEAR 增加 |D − S|按预期,但增加 |D ∩ S|由于它们的相关性,将其作为其副产品(见图 1b)。
相比之下,我们提出了一种简单但有效的双级正交性来解决这种相关性,并实现了两个子目标,从而显着提高了 RoC。表 1 显示 RoC 的提高也与召回率的提高相关*。
我们验证了 RoC 的增强可以提高三个 IR 数据集上的混合检索性能:MS MARCO、Natural Questions 和 TREC Robust04
2. 相关工作
2.1 稀疏和密集检索
稀疏(或符号)空间通常是独立的,使得诸如倒排索引或位图之类的数据结构可以有效地识别具有精确匹配的匹配候选,并且也可以有效地计算排名。 BM25(Robertson 和 Zaragoza,2009)是一种著名的使用词袋表示的词汇排名模型。
同时,密集检索模型(Shen等,2014;Guo等,2016;Zhai等,2016;Nogueira和Cho,2019;Zhan等,2020)被提出来解决术语不匹配问题,可以将其分类为分为两组(Guo et al, 2016):(1)基于嵌入的模型和(2)基于交互的模型。我们的目标场景是前者,将查询 q 和文档 d 表示为两个独立的密集向量,并使用向量相似度来匹配 q-d。然而,我们还讨论了如何将我们的想法应用于基于交互的排名方法(Nogueira 和 Cho,2019;McDonald 等人,2018),在没有向量的情况下捕获逐词交互,我们在第 3.3 节中将其作为非嵌入模型讨论。
2.2 互补性
为了利用互补性,已经有一些方法可以将两个空间结合起来,或者将知识从一个空间转移到另一个空间。
首先,对于组合,一种简单的方法是聚合两个空间的分数(Ma et al, 2021),然后将其改进为更复杂的模型,例如 CLEAR(Gao et al, 2020)通过 BM25 的残差进行学习。具体来说,当q-d对在词汇上难以匹配时,边距变大,那么语义匹配的损失就被强调。换句话说,模型经过训练
其次,对于迁移,SparTerm(Bai et al, 2020)通过将 BERT 的上下文知识提炼到词袋空间中来学习稀疏表示。具体来说,基于 BERT 编码器,SparTerm 首先生成词汇术语语义重要性的密集分布,然后控制每个术语的激活,确保最终表示的稀疏性。这意味着,基于术语的匹配方法的表示能力可以提高到语义级匹配。我们的属于结合两个空间的第一类,但我们提出了一个名为 RoC 的新指标来直接评估混合检索中的互补性。表 1 显示了现有的互补性指标仅部分覆盖 RoC。同时,我们还讨论了如何将我们的方法与第二类方法(即 SparTerm)相结合,以实现进一步的收益(第 4.3 节)。
3. 提出方法
3.1 RoC 的优化目标
1)D∩S 变小
2)D-S 变大
3.2 & 3.3
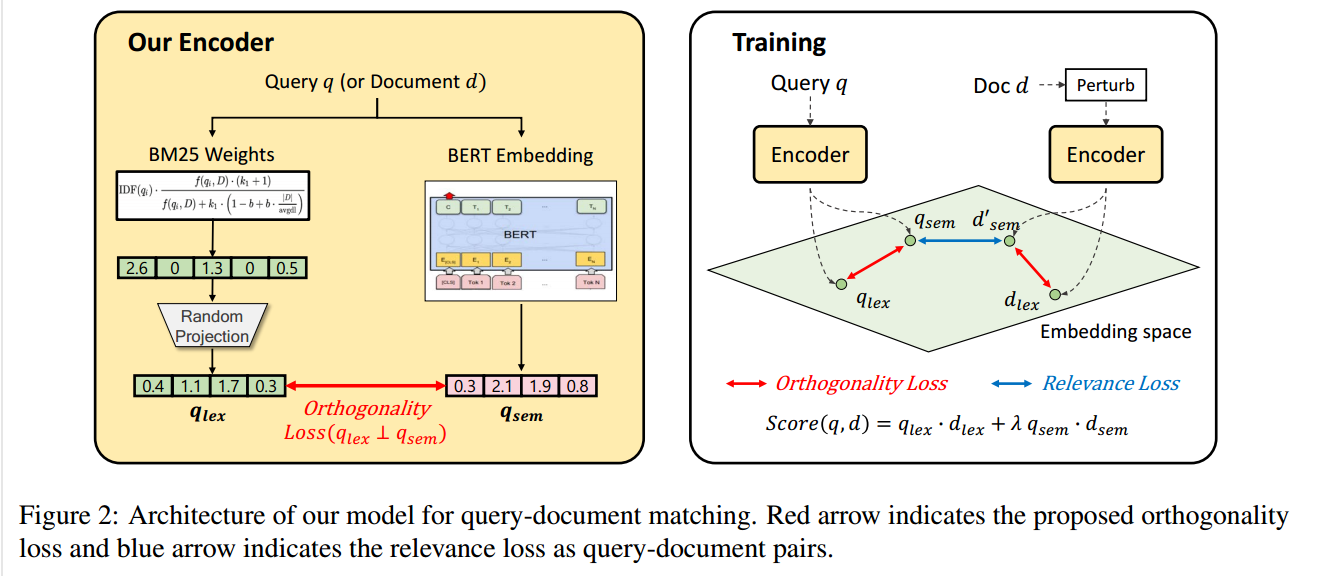
词汇表示 和 语义表示 都表示成向量
3.4 两种正交性
1)嵌入正交性,通过损失函数限制词汇表示向量和语义表示向量在表示空间正交
2)输入正交性,因为稀疏方法在语义相似但不同的term上表现差,通过加入扰动,使得精确匹配变得不精确,增强模型学习不精确匹配的能力
我们在 3.1 节中提出 RoC,然后讨论 S(3.2 节)和 D(3.3 节)是如何实现的。 3.4 节讨论了如何组合 D 和 S 来优化 RoC。
3.1 Ratio of Complementarity (RoC)
RoC 是一个可以衡量互补性并直接近似图 1 中的失败案例的度量,即 RoC ∝ |U − F ail|其中 U 表示所有答复文件。基于这个假设,我们的目标是最大化 |D ∪ S| · 罗克。我们将这个目标描述为两个子目标如下:
(∝ :正比于符号;≃:渐近等于)
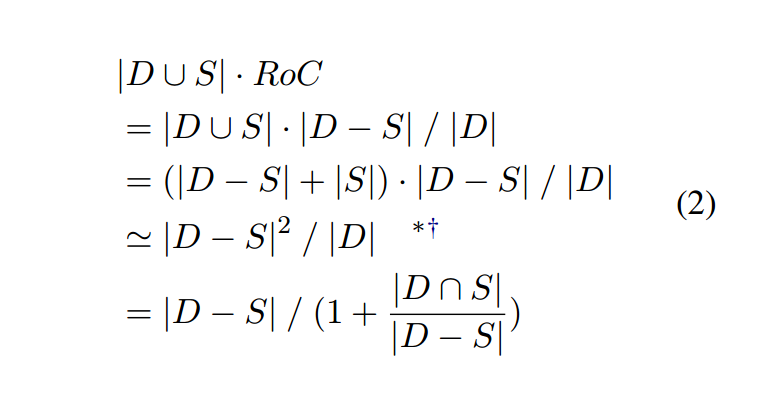
第一个子目标是优化 |D ∩ S|,为此我们将稀疏模型和稠密模型捕获的特征彼此分开。第二个子目标是最大化 |D −S|,为此我们建议捕获稀疏模型的剩余特征。我们在 3.3 节中描述了如何实现每个子目标。
3.2 词汇表示(S)
虽然可以使用任何词汇检索器,但我们使用 BM25(Robertson 和 Zaragoza,2009)描述我们的方法来构建符号表示(图 2(左)中的绿色向量 qlex),以捕获词汇匹配。 BM25 分数可以写为查询和文档的词袋表示之间的内积。我们将 BM25 的 q 和 d 表示定义为 qbm25 和 dbm25 ∈ R |V |分别,其中表示 qbm25 和 dbm25 的第 i 个元素可以写成如下:
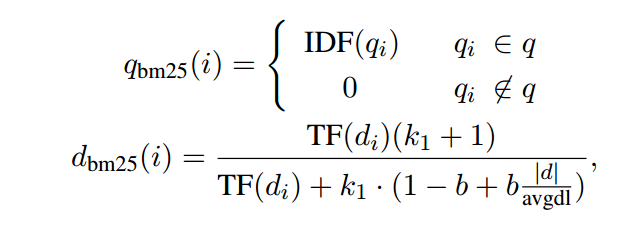
其中 IDF(·) 是术语 i 的逆文档频率,TF(·) 是给定文档中术语 i 的频率。因此,BM25(q,d)可以表示为qbm25和dbm25之间的内积。
由于词汇表示的维数比语义表示的维数大得多,因此需要将 qbm25 和 dbm25 压缩到低维空间。对于这种压缩,Luan 等人 (2020) 发现随机投影 (Vempala, 2004) 对于保留文档排名有效,我们在本工作中采用了这种方法。
尽管存在压缩损失,但可以通过改变嵌入维度 k 来限制该损失。在 NQ 实验中,我们遵循 Luan 等人(2020)的协议,将 k 设置为 715,这保证了 768 维 BERT 嵌入的错误低于 0.038。随机投影是通过矩阵 A 进行线性变换,矩阵 A ∈ R 768×|V |是从 Rademacher 分布中以相等的概率从两个值中随机采样的:{− 1 √ 768 , 1 √ 768 }。
最终的词法表示 qlex 和 dlex 可以通过以下方式获得:
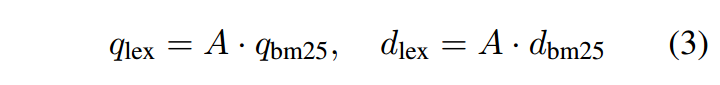
与等式。 (3),qlex 和 dlex 与 BERT 的语义向量位于同一维空间,同时保留排名。此外,我们的目标是加强与 3.3 节中语义向量的互补性。
根据词汇表示,查询 q 和文档 d 之间的最终相关性得分通过内积计算,如下所示:
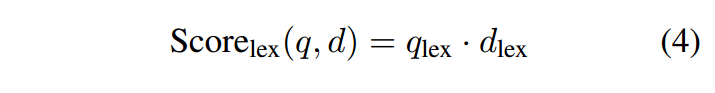
这个相关性分数近似于BM25分数,同时,我们可以在语义空间中处理qlex和dlex这两个向量。
3.3 语义表示(D)
对于语义表示(图 2(左)中的粉色向量),我们采用最先进的(coCondenser;(Gao 和 Callan,2021))用于解释目的,由基于 BERT 的双编码器结构组成(德夫林等人,2019)。因此,我们的密集检索遵循 BERT 的架构、设置和超参数。遵循 BERT 的输入风格,我们将 wordpiece tokenizer 应用于输入文档和查询,然后在开头添加 [CLS] 标记,在末尾添加 [SEP] 标记,如下所示:
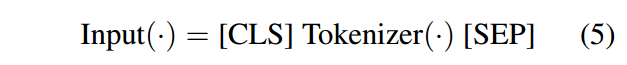
然后,我们从 [CLS] 标记处的 BERT 表示中获取查询和文档的嵌入。 q 和 d 的语义表示可以表述如下:
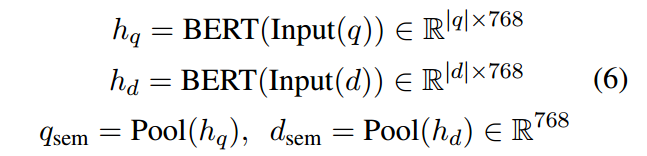
其中 Pool(·) 表示 [CLS] 池化提取隐藏状态 h 上的第一个向量。它们的语义相关性Scoresem是通过qsem和dsem的内积来计算的:Scoresem = qsem·dsem。
DPR 的训练损失是正通道的负对数似然:
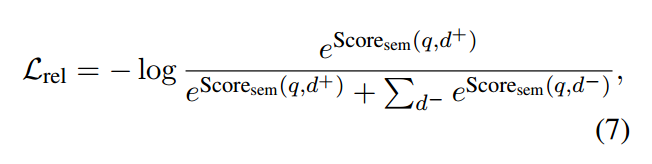
其中 d + 和 d − 表示对应于给定查询 q 的正文档和负文档。为了选择负面文档,我们遵循之前作品中的惯例(Karpukhin et al, 2020; Sachan et al, 2021; Gau et al, 2020),即硬负抽样,选择从 BM25 检索到的排名靠前的文档不包含答案。
3.4 互补目标
我们提出嵌入级和输入级正交性约束,这会减少 |D ∩ S|并分别增加|D − S|。
嵌入级正交性
为了减少|D∩S|,我们将语义和词汇表示空间之间的特征分开。具体来说,我们强制词汇和语义表示之间的正交性(即 qlex ⊥ qsem)。通过方程式训练 BERT 时(7),我们使用余弦相似度施加额外的约束,对特征进行归一化,以约束两个向量(lex 和 sem)的方向。我们定义正交性的损失函数如下:
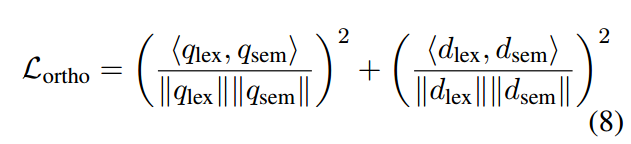
其中⟨·,·⟩是内积。如果两个向量完全垂直,则损失等于 0;否则,它具有正值。
这与我们最小化两个向量的共同特征的目标是一致的,从而减少重叠 |D ∩ S|语义 (D) 和词汇 (S) 模型,如图 1© 所示。添加此正交性损失,BERT-ranker 的最终损失函数计算如下:
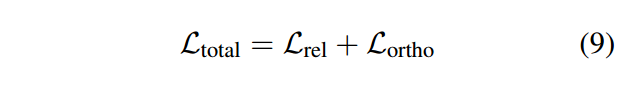
虽然我们可以调整上述聚合,但我们根据经验发现 1:1 聚合是有效的。
输入级正交性
增加 |D − S|在输入级别,我们遵循使用稀疏模型忽略的残差特征的约定,例如不匹配术语之间的同义词,例如“password = passwd”。为了这个目标,我们提出了一种扰乱匹配标记子集的方法,以学习不匹配的术语,类似于去噪自动编码器(Hill 等人,2016)。在去噪自动编码器中,输入文本被随机噪声函数破坏,然后训练解码器恢复原始文本,学习方差的鲁棒特征(Vincent 等人,2008)。相反,虽然我们的令牌扰动没有恢复解码器,但我们的区别是破坏精确匹配,重点是软匹配。给定 q-d 对,我们将 d 中的一组完全匹配的标记表示为 XEM = {xi |xi ∈ q 和 xi ∈ d}。通过随机采样,我们将 Xem 中的标记替换为 [MASK] 标记,并将新序列 d ’ 输入到 BERT 中。通过令牌扰动,我们修改式(1)中的 dsem。 (6) 转为 d ′ sem,计算如下:

其中 Sample(·) 是标记的随机采样。‡ 此扰动仅适用于训练过程,我们不会在推理时使用它。
这种扰动使得解缠结思想不仅能够应用于新模型,而且能够应用于各种现有模型(参见第 4.1 节)。
最终相关性得分
为了汇总两个 IR 模型的分数,我们遵循主要基线的约定(Karpukhin 等人,2020;Gao 等人,2020;Ma 等人,2021),使用线性组合
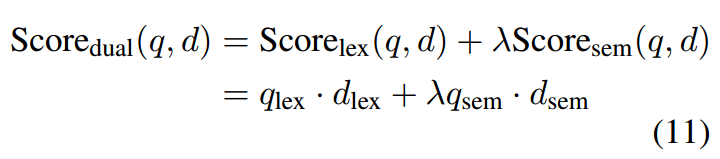
其中 λ 是控制不同尺度权重的超参数。
4. 实验
4.2
1)两级正交成功增强了 RoC
2)增强 RoC 能够增强互补性,对于 bm25 来说困难的例子(不依赖词汇的例子),增强RoC之后变现更好
3)混合检索效果也变好
在本节中,我们描述实验设置并制定我们的研究问题来指导我们的实验。
4.1 实验设置
数据集
为了验证我们方法的有效性,我们对以下三个数据集进行查询-段落(或查询文档)匹配,这些数据集被广泛使用且具有统计多样性(表 2):
MS MARCO-Passage§(Nguyen 等人,2016):该基准提供了 880 万个段落,标签是从 Bing 搜索引擎检索到的前 10 个结果中获取的。由于官方测试集的相关标签未公开,因此我们仅评估开发集。我们使用 MRR@10 和 R@100 来评估全排序检索的性能。
NQ(Kwiatkowski 等人,2019):在此数据集中,我们的目标是从总共 25 万个段落中找到回答给定问题的相关段落,并且标签来自注释者识别的维基百科文章中的跨度。遵循 DPR(Karpukhin 等人,2020),我们将包含答案的段落视为评估 R@k 时的相关段落。
• TREC Robust04 (Voorhees et al, 2005):该数据集包含 250 个主题查询和 528K 文档。由于 Robust04 中没有发布正式的训练/测试分割,我们遵循 McDonald 等人 (2018) 中提供的分割设置,使用 5 折交叉验证。
我们尊重原始工作中使用的指标,它解释了不同数据集的不同指标。 Robust04 使用广泛,但尺寸较小,因此我们也遵循研究尺寸较大的 MS MARCO 和 Natural Questions 的惯例。
实现
对于 DPR 编码器,我们使用 BERT 的基本版本(Uncased)(Devlin 等人,2019)。对于训练,我们设置批量大小 10 并使用 Adam(Kingma 和 Ba,2015)优化器,学习率为 0.0002。为了稳定训练,我们使用范数为 1.0 的梯度裁剪(Pascanu et al, 2013),并且在 3 个 epoch 的训练迭代后,我们将每个 epoch 的学习率减半。我们遵循 DPR(Karpukhin 等人,2020)的其他训练细节,例如硬负采样。
作为超参数,我们根据开发集上的 MAP 自动找到 λ 的最佳值,其中我们以 0.1 步长在 [0, 2] 范围内搜索 λ。在 MARCO-Passage、Natural Questions 和 Robust04 上,λ 的最佳配置分别为 1.5、1.3 和 2.0。
评价指标
对于任务评估,我们计算以下指标并报告平均性能:平均倒数排名 (MRR)、平均平均精度 (MAP)、归一化折扣累积增益 (nDCG) 和前 k 个排名的召回率 (R@k)。对于召回率,我们遵循之前的工作 (Karpukhin et al, 2020),该工作被计算为 top-k 检索到的段落包含答案的问题的比例。对于 MAP 和 nDCG,我们使用最新的 TREC 评估脚本**来计算这些指标。采用 Bonferroni 校正的 t 检验的 p 值 < 0.05 结果在表 3 中以粗体显示。
基线
我们将我们的模型与以下最先进的检索基线进行比较。我们使用 SPARTERM(Bai 等人,2020)、COCONDENSER(Gao 和 Callan,2021)和 BM25 作为基线。
SPARTERM 是一种使用 BERT 的基于术语的检索模型,并给出词汇匹配分数。 BM25是一种著名的使用TF和IDF的词法匹配方法。对于 BM25,我们使用 Pyserini†† 开源实现。
对于 coCondenser,我们使用开源实现来重现。
另一方面,我们使用混合空间基线,例如 COCONDENSER+BM25 (Naive sum) 和 CLEAR (Gao et al, 2020)。
两种方法都通过合并稀疏模型和稠密模型的分数来给出相似性分数。请注意,我们的 CLEAR 实现比他们发布的结果表现更好,因为我们使用 coCondenser 更新了其基本变压器。为了公平比较,我们的和 CLEAR 都建立在相同的 coCondenser 实现之上。
4.2 实验结果
研究问题
为了评估我们方法的有效性,我们解决了以下研究问题:
• RQ1:两级正交性是否改善了RoC?
• RQ2:改进的RoC 是否有助于更好的互补性?
• RQ3:改进的互补性是否改善了混合检索?
4.2.1 RQ1:正交性的有效性
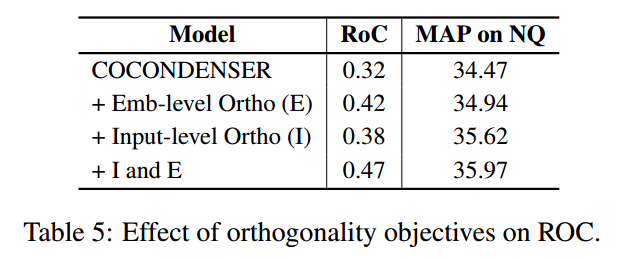
我们进行了消融研究,以确认这两个正交约束是否有助于改善 RoC。如表 5 所示,与朴素求和相比,嵌入级正交性将 RoC 提高了 0.1,输入级正交性提高了 0.06。应用这两种方法将 RoC 提高了 0.15,这与 CLEAR 相比是一个显着的改进,而 CLEAR 仅比朴素总和提高了 0.05
4.2.2 RQ2:RoC 改进互补性
在本节中,我们展示了我们的方法通过使用混合检索的召回以及对抗性评估来提高互补性。
首先,我们的(图 3)显示 RoC 比 CLEAR 高 0.15,因为与 CLEAR(图 1b)相比,RoC 有所改善,并且故障案例减少。换句话说,RoC 是 |D ∪ S| 的更可靠的预测因子,它与性能直接相关。

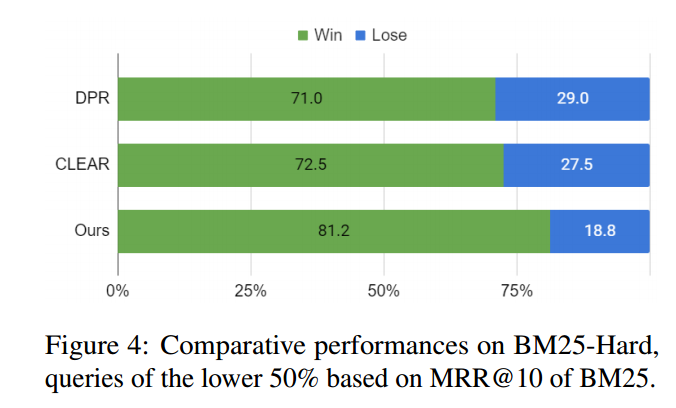
其次,我们还可以观察到逆境下的互补性。我们遵循(Wei 和 Zou,2019)的约定,将查询分为两组:BM25-Easy 和 BM25-Hard。具体来说,我们通过对所有查询的 BM25 的 MRR@10 分数进行排序来定义简单集和困难集。前 50% 是 BM25-Easy,其中仅 BM25 就已经具有竞争力,其余的是 BM25-Hard,这对词汇检索器不利。
我们希望混合模型能够在硬集上超越 BM25 排名。带着这样的期望,我们在图 4 上比较了混合模型提供更好排名的比率(相对于 MRR@10)。令人惊讶的是,CLEAR 并没有将 DPR 的比率提高很多(+1.5%),这与图 5 中的结果一致。相比之下,我们将该比率显着提高了+10.2%。
观察不利场景的另一种方法是构建具有较少匹配项的不利数据集。具体来说,查询和文档之间词汇匹配的术语被同义词替换(如(Wei 和 Zou,2019)中类似的做法)。图 5 比较了 CLEAR 和我们的方法如何推广到这个不利的集合。原始数据集上的两个模型在早期 epoch 中都快速提高了 MRR,而直到 epoch 5 之前,在逆向集上的 MRR 提升并不明显。然而,这种差距仅在我们的模型中减小(图 5b),而在 CLEAR 中保持不变(图 5a),表明 CLEAR 仍在继续专注于词汇匹配,同时我们学习利用语义匹配。
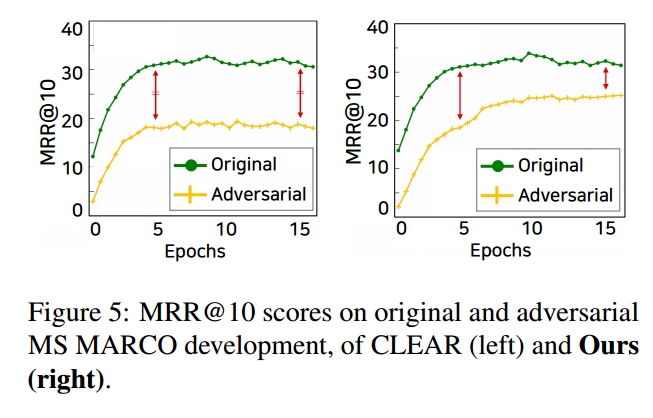
4.2.3 RQ3:混合检索中互补性的影响
在这个实验中,我们验证了增强互补性对各个性能方面的影响。
我们首先比较混合模型和我们的模型的性能,以表明我们的两级正交性提高了混合检索性能以及两个模型之间的互补性。在表3中,与coCondenser+BM25(Naive sum)相比,我们的方法在MSMARCO上将MRR@10提高了0.78,在NQ和Robust04上将MAP分别提高了1.50和2.21,这表明互补性提高了文档排名。与最先进的模型 CLEAR 相比,我们的方法在 MSMARCO 上实现了 0.64 的 MRR@10 增益,在 NQ 和 Robust04 上分别实现了 1.04 和 0.88 的 MAP 增益。请注意,我们的方法具有统计上显着的性能改进,如表 3 中的上标所示。
嵌入级和输入级方法的消融研究
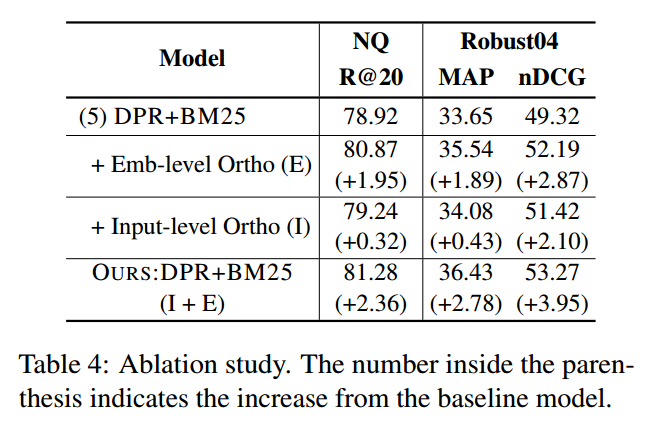
为了研究两级正交性对混合检索性能的孤立影响,我们在 NQ 和 Robust04 中进行了消融研究,如表 4 所示。为此,我们将每个组件(嵌入级或输入级目标)添加到基线模型中:DPR+BM25(朴素总和)。在这两个数据集中,我们观察到嵌入级和输入级方法可以在基线上实现显着改进,这表明增强的互补性提高了混合检索性能。请注意,嵌入级目标比输入级目标更有效,这与表 5 中的互补性改进结果一致。
我们还可以在表 6 中看到,输入级目标甚至适用于非嵌入模型。
长度泛化性
基于 BERT 在 NQ 数据集中对长文档准确率较低的众所周知的弱点(Luan 等人,2020),我们验证了改进的互补性对长文档鲁棒性的影响。我们提出的模型优于 CLEAR,并且在除一组之外的所有长度上都获得了最佳分数。
这表明互补性在长度泛化中起着至关重要的作用。结果和详细信息在 A.1 节中描述
5. 结论
我们研究混合检索的问题,其中现有的最先进技术追求部分互补的概念。相比之下,我们提出了 RoC,这是一种能够更全面地描述稀疏模型和密集模型之间互补性概念的指标。然后,我们提出一个简单但有效的两级正交目标来增强 RoC,并验证优化 RoC 可以增强互补性和检索性,从而在三个代表性 IR 基准(MSMARCO-Passage、Natural Questions 和 TREC Robust04)中表现优于最先进的水平,并推广到对抗性设置。
6. 局限性
我们利用 MS-MARCO,这是一种提供大规模相关注释的资源。然而,与大多数检索数据集一样,该数据集可能包含注释偏差。鉴于数据集提供的语料库中存在大量文档,相关性注释分布稀疏,所有其他文档都被认为是不相关的。
因此,一些相关文档可能会被错误地标记为不相关,从而导致漏报。 MSMARCO 中一个值得注意的注释偏差是相关标签与精确匹配术语高度相关(Xiong 等人,2020)。
这种偏差在训练或评估阶段造成了限制。为了适当地解决这种注释偏差,我们可能需要使用人类或神经注释器重新组织标记过程,或者我们可以旨在设计和训练一个能够适应这种偏差的模型。我们将此任务保留给未来的研究工作。