文章目录
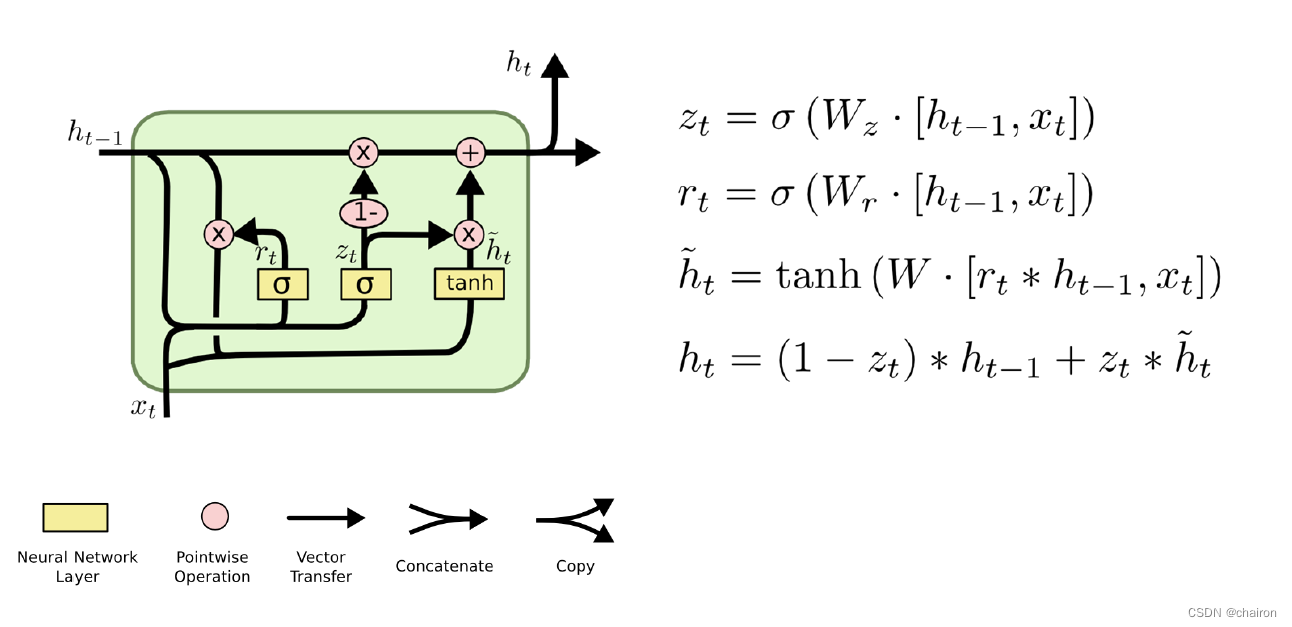
- 基本架构
- Embedding
- Encoder
- self-attention
- Multi-Attention
- 残差连接+LayerNorm
- Decoder
- Mask&Cross Attention
- 线性层&softmax
- 损失函数
论文链接: Attention Is All You Need
参考文章:
- 【NLP】《Attention Is All You Need》的阅读笔记
- 一文了解Transformer全貌(图解Transformer)
- Transformer是什么?看完这篇你就醍醐灌顶
- Transformer 模型详解
- 深度学习之Transformer笔记
- The illurstrated Transformer
Transformer是自然语言处理领域具有里程碑意义的研究成果,后来也逐渐被广泛用于视觉信息处理与分析。之前在总结RNN时有说到,存在一种从长度为M的输入到长度为N的输出的这种seq2seq结构,通过Encoder-Decoder的结构实现对向量化内容的编解码。

基本架构

Transformer的整体架构如上图所示,但从结构来看会觉得很复杂,可以一步一步理解。首先是N层堆叠的编码器结构和N层堆叠的解码器结构组成,如下图所示:

再进一步细化,Encoder的结构都是相同的,但是和RNN不同,Encoder不同的层并不会共享权重。编码器的输入首先通过一个self-attention层,self-attention层的输出反馈给前馈神经网络,如图所示:

解码器也有编码器的两个层,但在这两层之间有一个注意层,帮助解码器关注输入句子的相关部分。

Embedding
Transformer的输入是Embedding后的文本向量,该向量化过程由两部分结果相加得到的,通常向量化表征的维度一般为256或者512(实验确定值,一个时计算资源限制,一个是实验验证效果较好),如图所示:

- 词向量化:通过word2vec的向量化方式,或者通过构造神经网络编码层实现对文本进行向量化;
- 位置编码:对于偶数位置采用sin,奇数位置采用cos的转换方式进行编码。其中 p o s pos pos是时序位置索引, i i i代表位置编码的维度索引。位置编码是一个向量,其维度与模型的嵌入维度( d m o d e l d_{model} dmodel)相同。因此, i i i 的值会从0遍历到 d m o d e l − 1 d_{model}-1 dmodel−1,表示位置编码向量中的每一个元素。

选择正弦和余弦编码的原因:
- 正弦和余弦函数是有界的,其值域在[-1, 1]之间。这有助于限制位置编码的大小,使得训练过程更加稳定。如果位置编码的值过大,可能会导致模型在训练过程中出现梯度爆炸或消失的问题,从而影响模型的性能。
- 正弦和余弦函数在周期性和连续性方面表现出色。这意味着对于相邻的位置,其位置编码的变化是平滑的,有助于模型捕捉序列中单词之间的相对位置关系。这种平滑性也有助于模型在推理时处理未见过的长序列,因为模型可以通过插值来估计未知位置的位置编码。
每个向量化后单词都会流经编码器的两层,如下:

Encoder
编码器接收文本向量列表作为输入,它通过将这些向量传递到“self-attention”层,然后传入前馈神经网络,然后将输出向上发送到下一个编码器来处理。
self-attention
计算self-attention的第一步是从编码器的每个输入向量中创**「建三个向量」(在本例中,输入是每个单词的嵌入)。因此,我们为每个单词创建一个「查询向量」、一个「键向量」和一个「值向量」。这些向量是通过将嵌入乘以我们在训练过程中「训练的三个矩阵」**来创建的,这三个矩阵是需要学习的参数矩阵 W Q 、 W K 、 W V W^Q、W^K、W^V WQ、WK、WV。

假如Thinking、Machines这两个单词经过Embedding后得到向量是 x 1 , x 2 x_{1},x_{2} x1,x2,那么 q 1 = x 1 W Q , q 2 = x 2 W Q q_{1}=x_{1}W^Q,q_{2}=x_{2}W^Q q1=x1WQ,q2=x2WQ,同理可得 k 1 = x 1 W K , k 2 = x 2 W K k_{1}=x_{1}W^K,k_{2}=x_{2}W^K k1=x1WK,k2=x2WK、 v 1 = x 1 W V , v 2 = x 2 W V v_{1}=x_{1}W^V,v_{2}=x_{2}W^V v1=x1WV,v2=x2WV。计算self-attention的第二步是计算分数,假设我们正在计算例子中第一个单词“Thinking”的self-attention,计算当前词与输入句子的每个词的之间相关性:

第三步和第四步是将分数除以 d m o d e l \sqrt {d_{model}} dmodel( 64 = 8 \sqrt {64}=8 64=8)(这一步的操作是为了让梯度的传播更稳定,该值是实验设定,非固定值),然后通过softmax操作传递结果。Softmax将分数标准化,使其全部为正值,加起来等于1。

当最终通过softmax计算出来的归一化分数越高时,说明目标词汇和当前词汇的相关性更高。
第五步是将每个value vector乘以softmax分数。这样通过对计算出来的关联性分数乘以向量,就可以实现对不同部分词汇有不同的关注度。
第六步是对加权值向量求和。这将在该位置(对于第一个单词)生成self-attention层的输出, z i = ∑ i = 1 N s o f t m a x ( q i k i d m o d e l ) v i z_{i}=\sum_{i=1}^{N}softmax(\frac {q_{i}k_{i}}{\sqrt {d_{model}}})v_{i} zi=i=1∑Nsoftmax(dmodelqiki)vi如图所示:

在Transformer中,整个过程是矩阵计算,结合上述步骤,矩阵运算可表达为:

Multi-Attention
论文中通过添加一种称为“多头”注意力机制,进一步细化了self-attention层。这从两个方面提高了注意层的性能:
- 它扩展了模型关注不同位置的能力,self-attention的注意力都集中在自身邻近位置,多头注意力则可以扩散注意力至整个句子;
- 它为注意力层提供了多个“表示子空间”。对于多头注意力,不仅有一组,而且有多组Query/Key/Value 权重矩阵(Transformer设置了8个注意力头,因此每个编码器/解码器有八组)。这些集合中的每一个都是随机初始化的。在训练之后,每一组注意力权重( W Q 、 W K 、 W V W^{Q}、W^{K}、W^{V} WQ、WK、WV)将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间;

如果我们做上面所述的同样的self-attention计算,只需使用不同的权重矩阵进行8次不同的计算,我们最终得到8个不同的Z矩阵。
而前馈层则不需要8个矩阵——它需要一个矩阵(每个单词对应一个向量)。这时就需要一种方法把这8个矩阵压缩成一个矩阵,即将它们乘以一个额外的权重矩阵 W O W^{O} WO进行一次变换:

多头注意力机制的整体流程就可以表示如下:

残差连接+LayerNorm
每个编码器中的每个子层(self-attention,ffnn)在其周围都有一个残差连接,然后是一个层进行归一化步骤。

- 反向传播链式法则易产生梯度消失的问题,而残差则通过相加和shortcut操作避免了梯度为0的情况出现,可以缓解梯度消失。
- Layer Normalization是对每个样本单独计算均值和方差,因此不需要考虑不同位置之间的相关性,也不会破坏向量的位置信息。相比之下,Batch Normalization会计算一个batch内所有样本的均值和方差,这可能会破坏Transformer中每个位置的高维向量表示,因为每个位置都包含重要的语义信息。Layer Normalization能够解决Transformer中的内部协变量位移问题。内部协变量位移是指在训练过程中,神经网络层输入的分布在不断变化,导致网络难以训练。Layer Normalization通过规范化层的输出,使得每一层的输入都保持稳定的分布,有助于加速模型的训练过程并提升模型的性能。
Decoder
Mask&Cross Attention
Decoder的初始输入为开始符号转换成对应的向量作为初始的query向量 Q Q Q,编码器中学习到的注意力向量 K 、 V K、V K、V会作为解码器的Key矩阵和 Value矩阵来使用,之后的每进行一次解码,对应的query会加上上一步的输出结果转换成的向量,再进行下一步的解码,直到解码器输出终止符(如:<EOS>):
Decoder解码过程
解码器中的两大特点:
- mask attention:mask注意力就是在翻译am时,不会参考后续向量数据,仅考虑上文向量;
- cross attention:cross含义就是其中一个序列作为输入的Q(Query),定义了输出的序列长度;另一个序列则提供输入的K(Key)和V(Value)。解码器 Attention层是使用前一层的输出来构造Query 矩阵,而Key矩阵和 Value矩阵来自于编码器最终的输出,也就是上面描述的解码过程。
线性层&softmax
最后一个线性层的工作,后面是一个 Softmax 层。线性层是一个简单的全连接神经网络,它将解码器堆栈产生的向量投影到一个更大的向量中,称为 logits 向量,该向量表示当前输出为当前索引映射词汇的概率,最终输出概率最大的预测结果。

损失函数
最终的目标是使得每个输出结果和目标结果之间的差距最小,一般采用的是交叉熵损失:


![[uni-app] uni.createAnimation动画在APP端无效问题记录](https://img-blog.csdnimg.cn/direct/08ec8d91dd4e4142a75226e74bacc547.png)