用 Rust Reqwest 编写 Web 爬虫

您是否曾考虑过建立自己的 潜在业务数据库,用于潜在客户开发或产品价格数据,以便您可以毫不费力地以最便宜的价格获得产品?网络爬虫可以让您无需亲自执行任何手动工作即可做到这一点。Rust通过允许显式地处理错误和并发地运行任务,让您可以做一些事情,比如将web服务 路由 到爬虫 或输出数据的Discord bot。
在本 Rust 网络爬虫指南中,将编写一个 Rust 网络爬虫,它将抓取 Amazon 上的 Raspberry Pi 产品并获取其价格,然后将它们存储在 PostgresQL 数据库中以供进一步处理。
可以在此处找到本文的 Github 代码库。
入门
让我们使用 cargo shuttle init 创建一个新项目。对于这个项目,我们将简单地将其称为 webscraper - 您需要框架的 none 选项,这将生成一个添加了 shuttle-runtime 的新 Cargo 项目(由于我们当前没有使用 Web 框架,因此我们不需要选择任何其他选项)。
使用以下代码来安装依赖项:
cargo add chrono reqwest scraper tracing shuttle-shared-db sqlx --features shuttle-shared-db/postgres,sqlx/runtime-tokio-native-tls,sqlx/postgres
还需要安装 sqlx-cli ,它是管理 SQL 迁移的有用工具。可以通过运行以下命令来安装它:
cargo install sqlx-cli
如果在项目文件夹中使用 sqlx migrate add schema ,将获得 SQL 迁移文件,该文件可以在 migrations 文件夹中找到!该文件的格式将包含创建迁移的日期和时间,然后是为其指定的名称(在本例中为 schema )。出于我们的目的,以下是将使用的迁移脚本:
-- migrations/schema.sql
CREATE TABLE IF NOT EXISTS products (id SERIAL PRIMARY KEY,name VARCHAR NOT NULL,price VARCHAR NOT NULL,old_price VARCHAR,link VARCHAR,scraped_at DATE NOT NULL DEFAULT CURRENT_DATE
);
在开始之前,需要创建一个实现 shuttle_runtime::Service 的结构,这是一个异步trait。还需要设置user agent,以减少被拦截的可能性。值得庆幸的是,可以通过在主函数中返回一个结构来完成所有这一切,如下所示:
// src/main.rs
use reqwest::Client;
use tracing::error;
use sqlx::PgPool;struct CustomService {ctx: Client,db: PgPool
}// Set up our user agent
const USER_AGENT: &str = "Mozilla/5.0 (Linux x86_64; rv:115.0) Gecko/20100101 Firefox/115.0";// note that we add our Database as an annotation here so we can easily get it provisioned to us
#[shuttle_runtime::main]
async fn main(#[shuttle_shared_db::Postgres] db: PgPool
) -> Result<CustomService, shuttle_runtime::Error> {
// automatically attempt to do migrations
// we only create the table if it doesn't exist which prevents data wipingsqlx::migrate!().run(&db).await.expect("Migrations failed");
// initialise Reqwest client here so we can add it in later onlet ctx = Client::builder().user_agent(USER_AGENT).build().unwrap();Ok(CustomService { ctx, db })
}#[shuttle_runtime::async_trait]
impl shuttle_runtime::Service for CustomService {async fn bind(mut self, _addr: std::net::SocketAddr) -> Result<(), shuttle_runtime::Error> {scrape(self.ctx, self.db).await.expect("scraping should not finish");error!("The web scraper loop shouldn't finish!");Ok(())}
}
现在我们已经完成了,可以开始在 Rust 中进行网页抓取了!
完成网络爬虫
制作网络抓取工具的第一部分是向目标 URL 发出请求,以便可以获取响应正文进行处理。值得庆幸的是,亚马逊的 URL 语法非常简单,因此我们可以通过添加我们想要查找的搜索词的名称来轻松自定义 URL 查询参数。由于亚马逊返回多页结果,我们还希望能够将页码设置为可变动态变量,每次请求成功时该变量都会增加 1。
// src/main.rs
use chrono::NaiveDate;#[derive(Clone, Debug)]
struct Product {name: String,price: String,old_price: Option<String>,link: String,
}async fn scrape(ctx: Client) -> Result<(), String> {let mut pagenum = 1;let mut retry_attempts = 0;let url = format!("https://www.amazon.com/s?k=raspberry+pi&page={pagenum}");let res = match ctx.get(url).send().await { Ok(res) => res,Err(e) => {error!("Error while attempting to send HTTP request: {e}");break}};let res = match res.text().await {Ok(res) => res,Err(e) => {error!("Error while attempting to get the HTTP body: {e}");break}};
}
您可能已经注意到,上边代码添加了一个名为 retry_attempts 的变量。这是因为有时当抓取时,亚马逊(或任何其他网站)可能会给我们一个 503 服务不可用的消息,这意味着抓取将失败。有时这可能是由于服务器过载或抓取太快造成的,因此可以像这样对错误处理进行建模:
// src/main.rsuse reqwest::StatusCode;
use std::thread::sleep as std_sleep;
use tokio::time::Duration;let mut retry_attempts = 0;if res.status() == StatusCode::SERVICE_UNAVAILABLE {error!("Amazon returned a 503 at page {pagenum}");retry_attempts += 1;if retry_attempts >= 10 {// take a break if too many retry attemptserror!("It looks like Amazon is blocking us! We will rest for an hour.");// sleep for an hour then retry on current iterationstd_sleep(Duration::from_secs(3600));continue;} else {std_sleep(Duration::from_secs(15));continue;}
}retry_attempts = 0;
假设 HTTP 请求成功,我们将获得一个可以使用 scraper crate 解析的 HTML body。
如果您在浏览器中访问亚马逊并搜索“raspberry pi”,您将收到一份产品列表。您可以使用浏览器上的开发工具功能检查此产品列表(在本例中,它是 Firefox 中的检查功能,但您也可以使用 Chrome Devtools、Microsoft Edge DevTools 等…)。它应该如下所示:
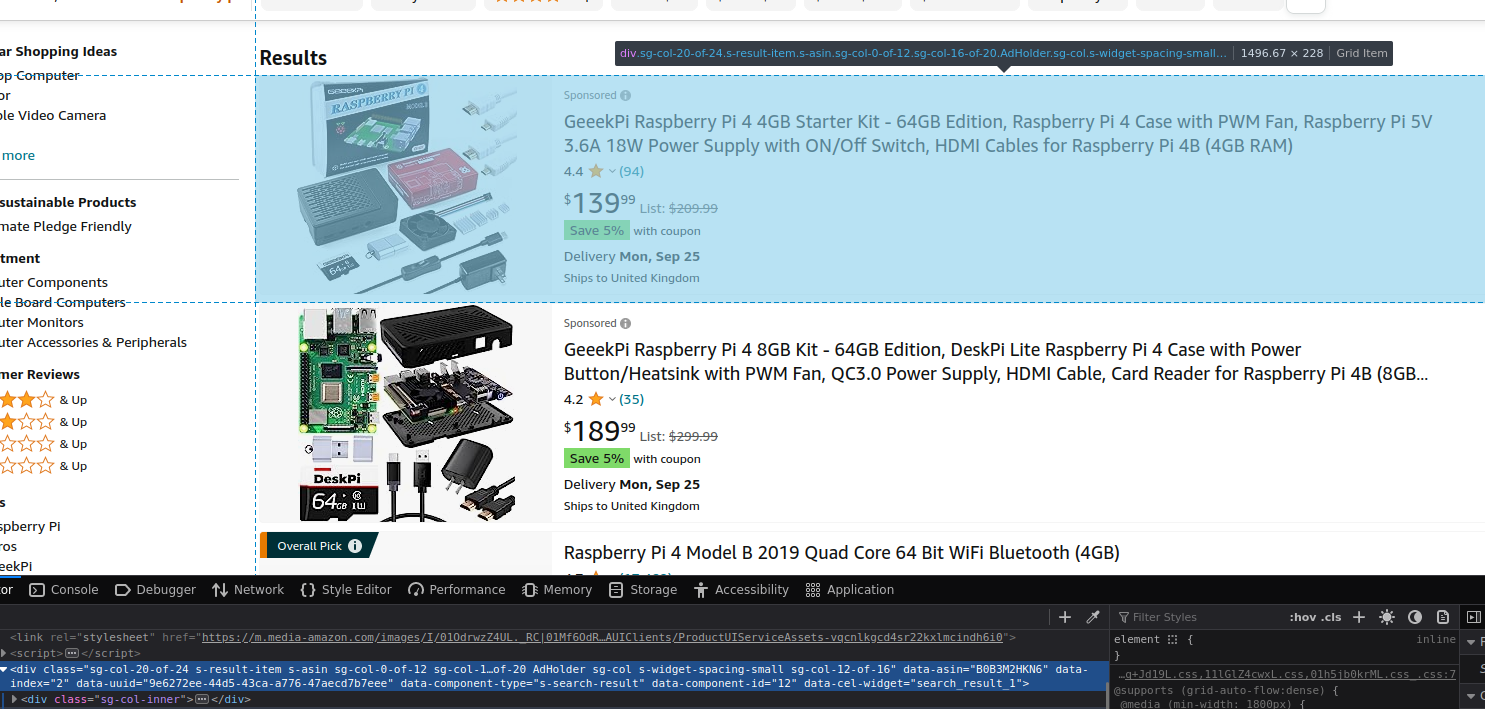
注意到 div 元素具有 data-component-type 的数据属性,其值为 s-search-result 。这很有帮助,因为除了想要抓取的页面组件之外,没有其他页面组件具有该属性!因此,可以通过选择它作为 CSS 选择器来抓取数据(有关更多信息,请参阅下文)。需要确保通过将 HTML 解析为 HTML 片段来准备 HTML,然后可以声明初始 scraper::Selector :
// src/main.rs
use scraper::{Html, Selector};let html = Html::parse_fragment(&res);
let selector = Selector::parse("div[data-component-type='s-search-result']").unwrap();
如您所见, Selector 使用 CSS 选择器来解析 HTML。在本例中,我们专门尝试搜索具有名为“data-component-type”且值为“s-search-result”的数据属性的 HTML div 元素。
如果现在尝试运行我程序并按照 scraper 文档 html.select(&selector) 运行,您将看到它返回一个 HTML 元素的迭代器。然而,因为迭代计数在技术上也可以为零,所以需要确保实际上有我们可以迭代的东西 - 所以让通过添加一个 if 语句来检查迭代器计数来确保我们覆盖了这一点:
// src/main.rs
if html.select(&selector).count() == 0 {error!("There's nothing to parse here!");break
};
在应用程序的最终迭代中,这应该会退出循环,因为这通常表明没有更多的产品可以检索,因为在第一种情况下应该始终有产品结果。
现在已经完成了各自的错误处理,可以迭代条目并创建一个产品,然后将其附加到我们的产品向量中。
// src/main.rs
for entry in html.select(&selector) {
// declaring more Selectors to use on each entrylet price_selector = Selector::parse("span.a-price > span.a-offscreen").unwrap();let productname_selector = Selector::parse("h2 > a").unwrap();let name = entry.select(&productname_selector).next().expect("Couldn't find the product name").text.next().unwrap().to_string();// Amazon products can have two prices: a current price, and an "old price". We iterate through both of these and map them to a Vec<String>.let price_text = entry.select(&price_selector).map(|x| x.text().next().unwrap().to_string()).collect::<Vec<String>>();// get local date from chrono for database storage purposeslet scraped_at = Local::now().date_naive();// here we find the anchor element and find the value of the href attribute - this should always exist so we can safely unwraplet link = entry.select(&productname_selector).map(|link| {format!("https://amazon.co.uk{}", link.value().attr("href").unwrap())}).collect::<String>();vec.push(Product {name, price: price_text[0].clone(),old_price: Some(price_text[1].clone()),link, scraped_at,});
}pagenum += 1;
std_sleep(Duration::from_secs(20));
请注意,在上面的代码块中,我们使用标准库中的 sleep - 如果尝试使用 tokio::time::sleep ,编译器将返回一个关于在等待点上持有非 Send future 的错误。
现在已经编写了用于处理从网页收集的数据的代码,可以将到目前为止编写的内容包装在循环中,移动 Vec<Product> 和 pagenum 和 db.commit 来完成。检查下面的代码:
// src/main.rs
let transaction = db.begin().await.unwrap();for product in vec {if let Err(e) = sqlx::query("INSERT INTO products (name, price, old_price, link, scraped_at) VALUES ($1, $2, $3, $4, $5) ").bind(product.name).bind(product.price).bind(product.old_price).bind(product.link).bind(product.scraped_at).execute(&db).await.unwrap() {error!("There was an error: {e}");error!("This web scraper will now shut down.");transaction.rollback().await.unwrap();break}
}
transaction.commit().await.unwrap();
在这里所做的只是对已抓取的产品列表运行一个 for 循环,并将它们全部插入数据库,然后在最后提交以完成它。
现在理想情况下,希望 爬虫 休息一段时间,以便页面有时间更新 - 否则,如果一直抓取页面,您很可能会得到大量重复数据。假设我们想让它休息到午夜:
// src/main.rs
use tokio::time::{sleep as tokio_sleep, Duration};// get the local time, add a day then get the NaiveDate and set a time of 00:00 to it
let tomorrow_midnight = Local::now().checked_add_days(Days::new(1)).unwrap().date_naive()
.and_hms_opt(0, 0, 0)
.unwrap();// get the local time now
let now = Local::now().naive_local();// check the amount of time between now and midnight tomorrow
let duration_to_midnight = tomorrow_midnight.signed_duration_since(now).to_std().unwrap();// sleep for the required time
tokio_sleep(Duration::from_secs(duration_to_midnight.as_secs())).await;
现在已经完成了!
你的最终抓取函数应该如下所示:
// src/main.rs
async fn scrape(ctx: Client, db: PgPool) -> Result<(), String> {debug!("Starting scraper...");loop {let mut vec: Vec<Product> = Vec::new();let mut pagenum = 1;let mut retry_attempts = 0;loop {let url = format!("https://www.amazon.com/s?k=raspberry+pi&page={pagenum}");let res = match ctx.get(url).send().await {Ok(res) => res,Err(e) => {error!("Something went wrong while fetching from url: {e}");StdSleep(StdDuration::from_secs(15));continue;}};if res.status() == StatusCode::SERVICE_UNAVAILABLE {error!("Amazon returned a 503 at page {pagenum}");retry_attempts += 1;if retry_attempts >= 10 {error!("It looks like Amazon is blocking us! We will rest for an hour.");StdSleep(StdDuration::from_secs(3600));continue;} else {StdSleep(StdDuration::from_secs(15));continue;}}let body = match res.text().await {Ok(res) => res,Err(e) => {error!("Something went wrong while turning data to text: {e}");StdSleep(StdDuration::from_secs(15));continue;}};debug!("Page {pagenum} was scraped");let html = Html::parse_fragment(&body);let selector =Selector::parse("div[data-component-type= ' s-search-result ' ]").unwrap();if html.select(&selector).count() == 0 {break;};for entry in html.select(&selector) {let price_selector = Selector::parse("span.a-price > span.a-offscreen").unwrap();let productname_selector = Selector::parse("h2 > a").unwrap();let price_text = entry.select(&price_selector).map(|x| x.text().next().unwrap().to_string()).collect::<Vec<String>>();vec.push(Product {name: entry.select(&productname_selector).next().expect("Couldn't find the product name!").text().next().unwrap().to_string(),price: price_text[0].clone(),old_price: Some(price_text[1].clone()),link: entry.select(&productname_selector).map(|link| {format!("https://amazon.co.uk{}", link.value().attr("href").unwrap())}).collect::<String>(),});}pagenum += 1;retry_attempts = 0;StdSleep(StdDuration::from_secs(15));}let transaction = db.begin().await.unwrap();for product in vec {if let Err(e) = sqlx::query("INSERT INTO products (name, price, old_price, link, scraped_at) VALUES ($1, $2, $3, $4, $5)").bind(product.name).bind(product.price).bind(product.old_price).bind(product.link).execute(&db).await{error!("There was an error: {e}");error!("This web scraper will now shut down.");break;}}transaction.commit().await.unwrap();// get the local time, add a day then get the NaiveDate and set a time of 00:00 to itlet tomorrow_midnight = Local::now().checked_add_days(Days::new(1)).unwrap().date_naive().and_hms_opt(0, 0, 0).unwrap();// get the local time nowlet now = Local::now().naive_local();// check the amount of time between now and midnight tomorrowlet duration_to_midnight = tomorrow_midnight.signed_duration_since(now).to_std().unwrap();// sleep for the required timeTokioSleep(TokioDuration::from_secs(duration_to_midnight.as_secs())).await;}Ok(())
}
搞定!
部署
如果您在 Shuttle 服务器上初始化项目,则可以使用 cargo shuttle deploy 开始(如果在脏 Git 分支上,则添加 --allow-dirty )。如果没有,您将需要使用 cargo shuttle project start --idle-minutes 0 来启动并运行您的项目。
尾声
感谢您阅读这篇文章!我希望您能够更全面地了解如何使用 Rust Reqwest 和 scraper crate 在 Rust 中开始网页抓取。
原文地址:Writing a Web Scraper in Rust using Reqwest