使用Amazon SageMaker构建高质量AI作画模型Stable Diffusion
- 0. 前言
- 1. Amazon SageMaker 与机器学习
- 1.1 机器学习流程
- 1.2 Amazon SageMaker 简介
- 1.3 Amazon SageMaker 优势
- 2. AIGC 与 Stable Diffusion
- 2.1 步入 AIGC 时代
- 2.2 Stable Diffusion 介绍
- 3. 使用 Amazon SageMaker 创建 Stable Diffusion 模型
- 3.1 准备工作
- 3.2 创建 Amazon SageMaker Notebook 实例
- 3.3 端到端体验 AIGC
- 3.4 模型生成效果
- 5. Amazon SageMaker 使用体验
- 小结
- 云上探索实验室活动
0. 前言
近来,随着新一代 AI 大型聊天机器人 ChatGPT 火遍科技圈,人工智能生成内容( Artificial Intelligence Generated Content, AIGC )这一领域开始受到学术界、工业界甚至普通用户的广泛关注。AIGC 凭借其独特的“创造力”与人类无法企及的创作生成速度掀起了一股人工智能狂潮。但是,利用人工智能模型生成图片、视频等要用到大量数据训练模型,对于算力的要求相较于简单模型也呈指数级的提升,为了快速高效的处理数据集和构建生成模型,在云中训练和部署人工智能模型成为大多数用户和公司的首选。
最近受邀参加了亚马逊云科技的云上探索实验室活动,并基于 Amazon SageMaker 创建、部署了 Stable Diffusion 生成模型,用于生成高质量图片,在整个模型构建流程中充分体验到 Amazon SageMaker 提供的全面的机器学习工具带来的优势,能够更快速、高效地执行机器学习任务,同时还具有灵活性、扩展性和易用性等诸多优势。接下来,我们一起回顾生成模型模型构建的全部流程吧!
本文,将首先介绍 AIGC 的基本概念与发展进程,并介绍了当前先进的图像生成模型 Stable Diffusion,然后介绍 Amazon SageMaker 的主要组件及其如何解决人工智能模型构建过程中的痛点问题,最后通过利用 Amazon SageMaker 构建 Stable Diffusion 模型来展示 Amazon SageMaker 在人工智能模型构建、训练和部署过程中的优势。
1. Amazon SageMaker 与机器学习
1.1 机器学习流程
人工智能 (Artificial Intelligence, AI) 是研究用于模拟和扩展人类智能的理论、方法及应用的一门系统性科学技术,其令计算机根据可用数据执行相应策略而无需以明确的编程方式执行策略,AI 通过使用计算机程序模拟人类行为从而使机器实现智能。人工智能的目标是创造能与人类思维相似的智能机器,或者通过人工智能技术来扩展人类智能从而解决实际问题。在过去几年里,许多人工智能系统取得了突破性进展,已经可以应用于解决各种复杂问题。
一般而言,一个完整的机器学习流程通常包括以下步骤:
- 数据收集和准备:在机器学习过程中,数据是至关重要的,需要收集相关数据,并对其进行预处理和清洗,以确保训练数据质量和一致性
- 特征工程:对数据进行特征选择、特征提取和特征转换等操作,以提取有用的信息,并将其转化为可用于训练模型的形式
- 模型构建和训练:根据实际应用场景,选择并构建合适的模型,并使用训练数据对其进行训练,通常需要进行模型选择、超参数调整、模型构建、模型训练和模型评估等过程
- 模型验证和优化:对模型进行验证和优化,以确保模型的准确性和稳定性,通常包括模型验证、模型优化和模型调整等过程,以进一步保证模型在实际生产环境中的鲁棒性
- 模型部署和监控:将模型部署到生产环境中,并对其进行监控和管理,以确保模型的可靠性和高效性,通常包括模型部署、模型监控和模型更新等过程

总之,机器学习流程是一个非常复杂和有挑战性的过程,需要对数据、模型和算法等方面进行深入的研究和探索,通常机器学习模型从数据收集到模型部署应用的完整流程需要大约 6-18 个月时间,并且通常会面临以下问题:
- 机器学习模型训练需要大量的数据,并且数据必须经过清洗和预处理,以确保数据质量及其一致性,往往需要耗费大量的时间和精力
- 在机器学习模型训练过程中,需要选择合适的模型,并进行超参数调优等操作,以获得最佳的模型性能,通常需要进行多次实验和测试
- 机器学习模型训练需要大量的计算资源,包括
CPU、GPU、内存和存储空间等,特别是在处理大规模数据集和复杂模型时,需要大量的前期投资,这对于普通用户和小公司而言并不具备可行性
机器学习模型训练流程中需要多种工具配合、大量时间和精力进行数据处理等,没有集成化的工具用于整个机器学习的工作流,机器学习模型的开发将十分复杂和昂贵。AWS (Amazon Web Services) 以为每一个开发者和数据科学家打造机器学习平台为使命,为机器学习提供了诸多有力的解决方案以提高机器学习模型构建、训练、部署的效率和质量。AWS 是由 Amazon 公司提供的一种云计算服务,是一种灵活、可扩展的云平台,提供了大量的基础设施、平台和软件服务,以帮助构建和运行各种应用程序和服务,其服务包括计算、存储、数据库、分析、网络和安全等诸多方面,以提供高可靠性、高可扩展性和低成本的云计算解决方案。
自从 2018 年起,亚马逊云科技发布了一系列的用于机器学习的产品和服务,例如 Amazon SageMaker、Amazon Machine Learing 等,极大的降低了机器学习的门槛,使得用户构建机器学习应用变得越来越容易,推动了机器学习的普及与应用。
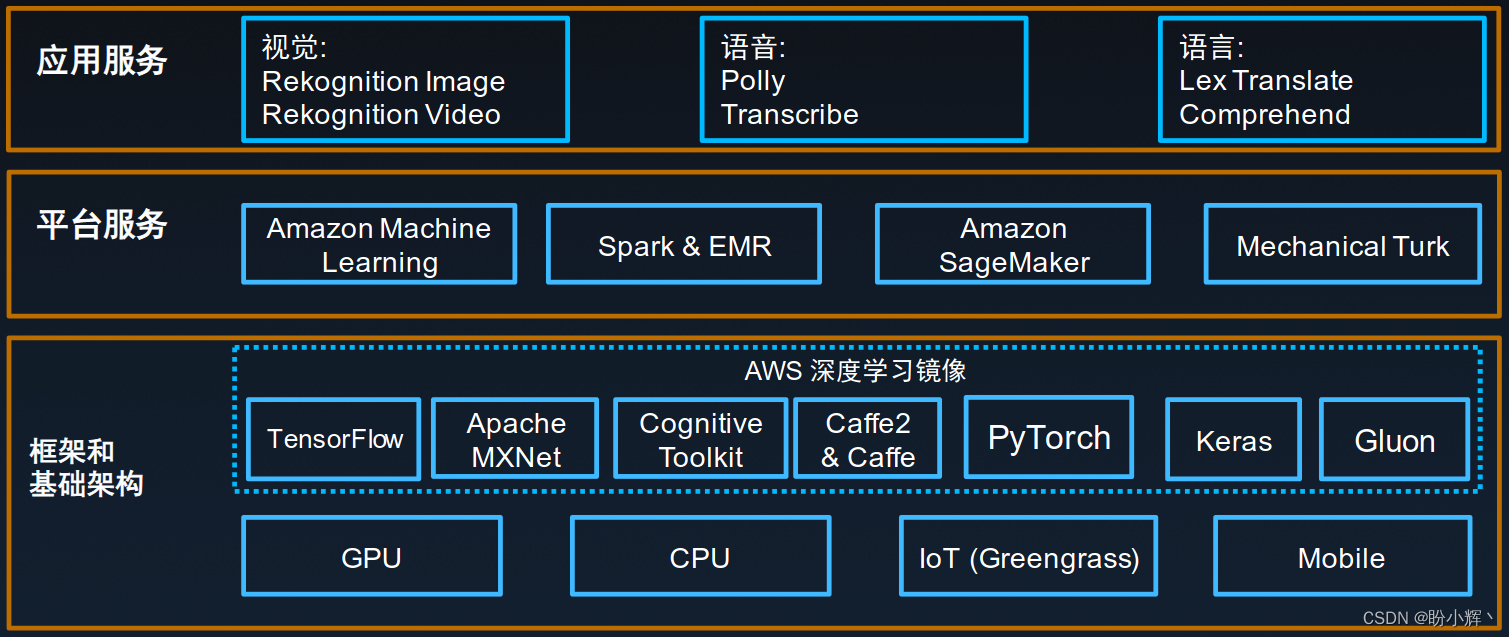
1.2 Amazon SageMaker 简介
Amazon SageMaker 是一项完全托管的机器学习服务,为数据科学家、开发人员和企业提供了一种简单的方式来构建、训练和部署机器学习模型,而无需考虑底层基础设施的复杂性。
Amazon SageMaker 提供了一整套机器学习工具,涵盖了数据标记、数据处理、模型训练、超参数调优、模型部署及持续模型监控等基本流程,也提供了自动打标签、自动机器学习、监控模型训练等高阶功能。其通过全托管的机器学习基础设施和对主流框架的支持,可以降低客户机器学习的成本。Amazon SageMaker 能够完全消除机器学习过程中各个步骤中繁重的工作,使得开发高质量模型变得更加轻松。
用户可以选择使用 Amazon SageMaker 的预置算法来快速构建和训练模型,也可以使用自己的算法和框架,Amazon SageMaker 提供了一整套完整的机器学习工具,帮助用户构建、训练和部署高性能的机器学习模型,其包含多个功能组件。接下来,我们介绍其中一些主要的组件:
- 模型构建
Amazon SageMaker Studio,作为首个适用于机器学习的集成开发环境 (Integrated Development Environment,IDE),Amazon SageMaker Studio包含完备的功能,可以在统一的可视化界面中操作Notebook、创建模型、管理模型试验、调试以及检测模型偏差Amazon SageMaker Notebooks,用于加快模型构建与团队协作,解决了以下两个问题:1) 用户使用单台服务器运行Jupyter Notebook时需要管理底层资源;2) 在共享给其他用户时,需要修改一系列系统配置以及网络权限。支持一键启动Jupyter Notebook,亚马逊云科技负责底层计算资源的托管,同时还支持一键共享Notebook,推动机器学习团队无缝协作Amazon SageMaker Autopilot,实现模型自动构建与优化,通常在构建机器学习模型时,我们需要花费大量的时间寻找有效的算法来解决机器学习问题,Amazon SageMaker Autopilot可以自动检查原始数据、选择最佳算法参数集合、训练和调优多个模型、跟踪模型性能,并根据性能对模型进行排序,从而大幅缩短了寻找最佳模型所需的时间- 支持多种深度学习框架,包括
TensorFlow、PyTorch、Apache MXNet、Chainer、Keras、Gluon、Horovod和Scikit-learn等,除了默认支持的框架,其他任何框架均可以通过自带容器的方式在Amazon SageMaker中训练和部署模型
- 模型训练
Amazon SageMaker Experiments,用于组织、跟踪和评估模型训练过程中的运行情况。通常,为了得到能够部署应用的模型,需要多次迭代和不断调优,包括尝试不同算法、超参数、调整选取的特征等,Amazon SageMaker Experiments通过自动捕获输入参数、配置和结果并进行存储来管理模型迭代,结合Amazon SageMaker Studio的可视化界面来还可以浏览进行中的实验,与先前的实验结果进行直观的对比与评估Amazon SageMaker Debugger,用途分析、检测和提醒与机器学习相关的问题。由于目前大多数机器学习流程并不透明,而且训练模型需要花费较长时间,因此导致优化过程极其耗时,为了解决此问题,Amazon SageMaker Debbuger会在训练期间自动捕获实时指标(例如混淆矩阵和学习梯度等),其还会对常见问题发出警告并提供修复建议,令训练流程更加透明,可以更好地理解和解释模型工作原理,并最终提高模型精度- 大幅降低训练成本,
Amazon SageMaker支持基于托管的Spot竞价实例进行训练,训练成本降低最多可达90%,并且,Amazon SageMaker支持周期性自动保存checkpoint以避免Spot实例中断导致模型重新开始训练
- 模型部署
- 支持一键部署模型,针对实时或批量数据生成预测,可以跨多个可用区在自动扩展的实例上一键部署模型,在实现高冗余的同时无需进行任何基础设施运维操作。
Amazon SageMaker可以自动管理计算实例和模型部署,并为API访问提供安全的https终端节点,应用程序只需要调用这个API接口就可以实现低延迟、高吞吐量的推理 Amazon SageMaker Model Monitor,用于保持模型在部署后的精确性,受限于训练数据集,当目标变量随着时间推移发生改变时,模型会出现不再适用的问题,这通常称为概念漂移 (Concept Drift)。例如,经济环境变化可能会导致利率的波动,从而影响购房模型的预测结果,Amazon SageMaker Model Monitor能够检测已部署模型的概念漂移问题,提供详细的警报,同时通过Amazon SageMaker训练的模型会自动发送关键指标,以帮助确定问题根源,这为一些训练数据有限的场景提供了一个自动化机制,方便通过线上数据不断调优模型,而不必因为没有收集到足够数据或缺少自动化流程而推迟模型部署- 与
Kubernetes集成以进行编排和管理。目前,许多机器学习团队的工作平台基于Kubernetes平台,而且一些现有工作流编排和应用不易迁移,为了解决这些问题,Amazon SageMaker提供了Kubernetes Operator来与基于Kubernetes的工作流集成 Amazon SageMaker Neo,支持模型一次训练,多处运行。Amazon SageMaker Neo实现了机器学习模型训练一次即可在云上或者边缘计算节点中的不同硬件和系统环境中运行,以便在云实例和边缘设备上进行推理,从而以更快的速度运行而不会损失准确性,该功能可优化模型以在特定的硬件上运行,为给定模型和硬件目标提供最佳可用性能,优化后的模型运行速度最多可提高两倍,并且可以消耗更少的资源
- 支持一键部署模型,针对实时或批量数据生成预测,可以跨多个可用区在自动扩展的实例上一键部署模型,在实现高冗余的同时无需进行任何基础设施运维操作。
总之,通过 Amazon SageMaker 提供的一系列功能组件,涵盖了机器学习流程的各个方面,可以大大提高机器学习的效率和质量,并为用户构建、训练和部署模型提供全面的支持和保障。
1.3 Amazon SageMaker 优势
通过以上介绍,我们可以总结出 Amazon SageMaker 作为一款全面的机器学习平台具有以下优势:
- 高效性:
Amazon SageMaker提供了一系列高效的功能组件,如自动化模型调优、高性能的模型训练和部署、丰富的监控和调试工具等,可以显著提高机器学习的效率和质量 - 灵活性:
Amazon SageMaker提供了多种模型部署和管理方式,用户可以根据需求选择合适的部署方式 - 扩展性:
Amazon SageMaker可以轻松地扩展计算和存储资源,以应对不同规模和复杂度的机器学习任务 - 安全性:
Amazon SageMaker提供了多种安全性措施,包括数据隐私和保护、访问控制和加密等,以确保用户数据的安全和保密性 - 成本效益:
Amazon SageMaker提供了多种付费模式,用户可以根据需求选择合适的付费方式,并通过使用Amazon SageMaker自动化优化功能,减少机器学习任务的成本
总之,Amazon SageMaker 具有高效、灵活、可扩展、安全和成本效益等优势,可以为用户提供全面的机器学习支持和保障,帮助用户更加轻松地构建、训练和部署高质量的机器学习模型。接下来,我们将基于 Amazon SageMaker 创建、部署 Stable Diffusion 生成模型,用于生成高质量图片。
2. AIGC 与 Stable Diffusion
2.1 步入 AIGC 时代
目前人工智能模型可以分为两大类别,包括判别模型 (Discriminative Model) 与生成模型 (Generative Model)。判别模型根据一组输入数据,例如文本、X 射线图像或者游戏画面,经过一系列计算得到相应目标输出结果,例如单词翻译结果、X 光图像的诊断结果或游戏中下一时刻要执行的动作。判别模型可能是我们最熟悉的一类 AI 模型,其目的是在一组输入变量和目标输出之间创建映射。
而生成模型,并不会不会对输入变量计算分数或标签,而是通过学习输入和输出之间的关系生成新的数据样本,这类模型可以接受与实际值无关的向量(甚至是随机向量),生成复杂输出,例如文本、音乐或图像。人工智能生成( Artificial Intelligence Generated Content, AIGC) 内容泛指指利用机器学习和自然语言处理技术,让计算机生成人类可理解的文本、音频、图像等内容,主要由深度学习算法和神经网络构成,可以通过学习大量的数据来模拟人类的思维和创造力,从而产生高质量的内容。下图是使用 stable diffusion 模型生成的图像,可以看出生成的图像不仅具有很高的质量,同时能够很好的契合给定的输入描述。

AIGC 通过机器学习方法从原始数据中学习数据特征,进而生成全新的、原创的数据,这些数据与训练数据保持相似,而非简单复制原始数据。AIGC 已经取得了重大进展,并在各个领域得到广泛应用:
- 内容创作:可以辅助创作者完成图画、文章、小说、音乐等内容的创作
- 设计:可以帮助设计师进行平面设计、
UI设计等 - 游戏:可以生成游戏中的角色、道具等元素
- 视频制作:可以生成特效、动画等内容
- 智能客服:可以生成自然语言对话,实现智能客服等应用
AIGC 可以视为未来的战略技术,其将极大加速人工智能生成数据的速度,正在深刻改变人类社会,推动人类创作活动,包括写作、绘画、编程等,甚至也将推动科学研究,例如生成科学假设和科学现象等。AIGC 是一个快速发展的领域,将为各个行业带来革命性的变化。未来,通过学术界和工业界持续探索新的算法和技术,将进一步提高生成内容的质量和多样性。
总的来说,判别模型关注的是输入和输出之间的关系,直接预测输出结果,而生成模型则关注数据的分布,通过学习数据的统计特征来生成新的样本数据。判别模型推动了人工智能前数十年的发展,而生成模型将成为人工智能未来十年的重点发展方向。
2.2 Stable Diffusion 介绍
最近 AI 作画取得如此巨大进展的原因很大程度上可以归功于开源模型 Stable Diffusion,Stable diffusion 是一个基于潜在扩散模型 (Latent Diffusion Models, LDM) 的文图生成 (text-to-image) 模型,经过训练可以逐步对随机高斯噪声进行去噪以获得感兴趣的数据样本,该模型使用来自 LAION-5B 数据库 (LAION-5B 是目前最大、可自由访问的多模态数据集)子集的 512x512 图像进行训练,使用这个模型,可以生成包括人脸在内的任何图像。在使用 Stable Diffusion 生成高质量图像之前,我们首先介绍该模型的原理与架构,Stable Diffusion 模型架构如下图所示:

Diffusion model 相比生成对抗网络 (Generative Adversarial Network, GAN) 具有更好的图片生成效果,但由于该模型是一种自回归模型,需要反复迭代计算,因此训练和推理代价都很高,主要原因是它们在像素空间中运行,特别是在生成高分辨率图像时,需要消耗大量内存。Latent diffusion 通过在较低维度的潜空间上应用扩散过程而不是使用实际的像素空间来减少内存和计算成本,所以 Stable Diffusion 引入了 Latent diffusion 的方式来解决计算代价昂贵的问题,能够极大地减少计算复杂度,同时可以生成质量较高的图像,Latent Diffusion 的主要包括以下三个组成部分:
- 变分自编码器 (
Variational autoEncoder,VAE)
VAE模型主要包含两个部分:编码器和解码器,其中编码器用于将图像转换为低维的潜在表示,得到的低维潜在表示将作为U-Net模型的输入,而解码器用于将潜在表示转换回图像。在Latent diffusion训练期间,编码器用于获得正向扩散过程的图像的潜在表示,正向扩散在每一步中逐步使用越来越多的噪声。在推断过程中,使用VAE解码器将反向扩散过程生成的去噪潜在表示转换回图像 U-Net
U-Net同样包含编码器和解码器两部分,且都由ResNet块组成,编码器将图像表示压缩成较低分辨率的图像表示,解码器将较低分辨率图像表示解码回原始较高分辨率的图像表示。为了防止U-Net在下采样时丢失重要信息,通常在编码器的下采样ResNet和解码器的上采样ResNet之间添加捷径连接 (Short-cut Connections),此外,U-Net能够通过cross-attention层将其输出条件设置在文本嵌入上,cross-attention层被添加到U-Net的编码器和解码器部分,通常用在ResNet块之间Text-Encoder
Text-Encoder负责将输入提示转换到U-Net可以理解的嵌入空间,它通常是一个简单的基于Transformer的编码器,将输入分词序列映射到潜在文本嵌入序列。受Imagen的启发,Stable Diffusion在训练过程中并不会训练Text-Encoder,只使用CLIP预训练过的Text-Encoder——CLIPTextModel
但是,纵然由于 Latent diffusion 可以在低维潜在空间上进行操作,与像素空间扩散模型相比,它极大的降低了内存和计算需求,但如果需要生成高质量照片,模型仍然需要在 16GB 以上 GPU 上运行,具体而言,在本地计算机上搭建 Stable Diffusion 模型会遇到以下困难:
- 软件环境:
Stable Diffusion模型的构建需要使用特定的软件和库,在本地计算机上搭建软件环境可能会遇到版本不兼容、依赖关系复杂等问题,需要花费大量时间和精力进行调试和解决 - 数据处理:
Stable Diffusion模型训练需要处理大量的高质量图像数据,在本地计算机上处理大量数据可能会导致内存不足、速度慢等问题 - 计算资源限制:
Stable Diffusion模型训练需要大量的计算资源,包括高显存GPU和大量内存,如果本地计算机的计算资源不足,将无法训练模型 - 超参数:
Stable Diffusion模型需要设置大量参数,如扩散系数、边界条件、学习率等,这些超参数的选择需要经过大量调试,否则可能会导致模型不收敛或者收敛速度过慢 - 模型验证:
Stable Diffusion模型需要进行大量模型验证和测试,以确保模型的正确性和可靠性
综上所述,搭建 Stable Diffusion 模型需要克服计算资源限制、软件兼容问题、数据处理和超参数选择等困难。因此,选择云计算平台来简化这些工作便成为自然的选择,而 Amazon SageMaker 作为完全托管的机器学习服务成为构建、训练与部署复杂模型(例如 Stable Diffusion )的首选。
3. 使用 Amazon SageMaker 创建 Stable Diffusion 模型
在本节中,我们将介绍基于 Amazon SageMaker 使用 Amazon SageMaker Notebook 实例测试、验证 AIGC 模型并
部署 AIGC 模型至 Amazon SageMaker Inference Endpoint。
3.1 准备工作
为了确保能够将 AIGC 模型部署至 Amazon SageMaker Inference Endpoint,需要确保有足够的限额。为此,我们首先需要通过服务配额页面检查配额,在搜索框中输入 ml.g4dn.xlarge for endpoint usage,若此配额的第二列为 0,则需要提高配额:

提高限额,需首先选中 ml.g4dn.xlarge for endpoint usage,点击“请求增加配额”按钮:

在输入框中输入所需的限额,例如 “1”,填写完毕后,点击“请求”按钮提交请求:

等待配额请求通过后,就可以继续该实验过程。
3.2 创建 Amazon SageMaker Notebook 实例
Amazon SageMaker Notebook 实例是运行 Jupyter Notebook 应用程序的机器学习计算实例。Amazon SageMaker 用于管理实例和相关资源的创建,我们可以在 Notetbook 实例中使用 Jupyter Notebook 准备和处理数据、编写代码来训练模型、或将模型部署到 Amazon SageMaker 中,并测试或验证模型。接下来,我们将创建 Amazon SageMaker Notebook 示例,用于运行相关 Jupyter Notebook 代码。
(1) 登录 Amazon 云科技控制台,并将当前区域修改为 Tokyo 区域:

(2) 在搜索框中搜索 Amazon SageMaker,并点击进入 Amazon SageMaker 服务:
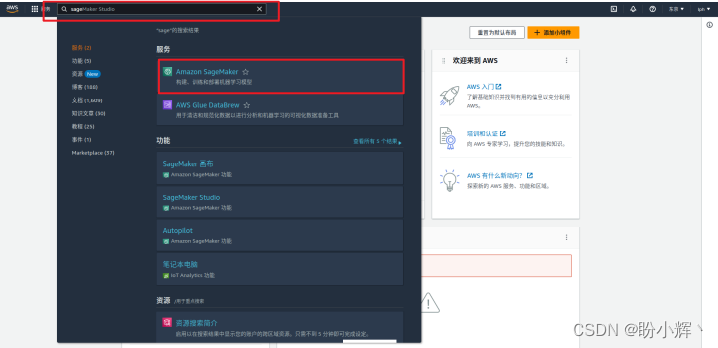
(3) 在左侧菜单栏,首先点击“笔记本”按钮,然后点击“笔记本实例”,进入笔记本 (Notebook) 实例控制面板,并点击右上角”创建笔记本实例“按钮:

(4) 配置笔记本实例设置,在创建笔记本实例详情页中,配置笔记本实例的基本信息,包括笔记本实例名称(例如 stable-diffusion)、笔记本实例类型(选择 ml.g4dn.xlarge 实例类型,该类型实例搭载 NVIDIA T4 Tensor Core GPU 显卡,提供了模型所需执行浮点数计算的能力)、平台标识符( Amazon Linux 2, Jupyter Lab 3 )和在“其他配置”下的卷大小(推荐至少 75GB 磁盘大小,用于存储机器学习模型):

(5) 配置笔记本实例权限,为笔记本实例创建一个 IAM 角色,用于调用包括 Amazon SageMaker 和 S3 在内的服务,例如上传模型,部署模型等。在“权限和加密”下的 IAM 角色中,点击下拉列表,单击“创建新角色”:

在配置页面中,保持默认配置,并点击“创建角色”按钮:

成功创建 IAM 角色后,可以得到类似下图的提示信息:

(6) 检查配置的信息,确认无误后点击“创建笔记本实例”按钮,等待实例创建完成。

(7) 当笔记本状态变为 InService 后,点击“打开Jupyter”进入 Jupyter Notebook:

3.3 端到端体验 AIGC
接下来,我们可以下载保存 Notebook 代码文件,并将其上传到 Jupyter Notebook,然后直接运行代码,但亲手编写代码的体验是无与伦比,我们将介绍代码文件的主要内容,从头开始端到端体验 AIGC!需要注意的是,需要确保 Kernel 以 conda_pytorch 开头。
(1) 安装相关库并进行环境配置工作:
# 检查环境版本
!nvcc --version
!pip list | grep torch
# 安装Notebook运行模型所需的库文件
!sudo yum -y install pigz
!pip install -U pip
!pip install -U transformers==4.26.1 diffusers==0.13.1 ftfy accelerate
!pip install -U torch==1.13.1+cu117 -f https://download.pytorch.org/whl/torch_stable.html
!pip install -U sagemaker
!pip list | grep torch
(2) 下载模型文件,我们将使用 Stable Diffusion V2 版本,其包含一个具有鲁棒性的文本生成图像模型,能够极大的提高了图像生成质量,模型相关介绍参见 Github:
# 安装git lfs以克隆模型仓库
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
!sudo yum install git-lfs -y
# 设定模型版本的环境变量,使用 Stable Diffusion V2
SD_SPACE="stabilityai/"
SD_MODEL = "stable-diffusion-2-1"
# 克隆代码仓库
# Estimated time to spend 3min(V1), 8min(V2)
%cd ~/SageMaker
!printf "=======Current Path========%s\n"
!rm -rf $SD_MODEL
# !git lfs clone https://huggingface.co/$SD_SPACE$SD_MODEL -X "*.safetensors"
!mkdir $SD_MODEL
%cd $SD_MODEL
!git init
!git config core.sparseCheckout true
!echo "/*" >> .git/info/sparse-checkout
!echo "!**/*.safetensors" >> .git/info/sparse-checkout
!git remote add -f master https://huggingface.co/$SD_SPACE$SD_MODEL
!git pull master main
%cd ~/SageMaker
!printf "=======Folder========%s\n$(ls)\n"
(3) 在 Notebook 中配置并使用模型,首先加载相关库与模型:
import torch
import datetime
from diffusers import StableDiffusionPipeline
# Load stable diffusion
pipe = StableDiffusionPipeline.from_pretrained(SD_MODEL, torch_dtype=torch.float16)
使用 GPU 进行运算并设定超参数,部分超参数如下:
- prompt (str 或 List[str]):引导图像生成的文本提示或文本列表
- height (int, *optional, V2 默认模型可支持到
768像素):生成图像的高度(以像素为单位) - width (int, *optional, V2 默认模型可支持到
768像素):生成图像的宽度(以像素为单位) - num_inference_steps (int, *optional, 默认降噪步数为
50):降噪步数,更多的降噪步数通常会以较慢的推理为代价获得更高质量的图像 - guidance_scale (float, *optional, 默认指导比例为
7.5):较高的指导比例会导致图像与提示密切相关,但会牺牲图像质量,当guidance_scale<=1时会被忽略 - negative_prompt (str or List[str], *optional):不引导图像生成的文本或文本列表
- num_images_per_prompt (int, *optional, 默认每个提示生成
1张图像):每个提示生成的图像数量
# move Model to the GPU
torch.cuda.empty_cache()
pipe = pipe.to("cuda")print(datetime.datetime.now())
prompts =["Eiffel tower landing on the Mars","a photograph of an astronaut riding a horse,van Gogh style",
]
generated_images = pipe(prompt=prompts,height=512,width=512,num_images_per_prompt=1
).images # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)print(f"Prompts: {prompts}\n")
print(datetime.datetime.now())for image in generated_images:display(image)
(4) 将模型部署至 Sagemaker Inference Endpoint,构建和训练模型后,可以将模型部署至终端节点,以获取预测推理结果:
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=Noneif sagemaker_session_bucket is None and sess is not None:# set to default bucket if a bucket name is not givensagemaker_session_bucket = sess.default_bucket()try:role = sagemaker.get_execution_role()
except ValueError:iam = boto3.client('iam')role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
创建自定义推理脚本 inference.py:
!mkdir ./$SD_MODEL/code
# 为模型创建所需依赖声明的文件
%%writefile ./$SD_MODEL/code/requirements.txt
diffusers==0.13.1
transformers==4.26.1
# 编写 inference.py 脚本
%%writefile ./$SD_MODEL/code/inference.py
import base64
import torch
from io import BytesIO
from diffusers import StableDiffusionPipelinedef model_fn(model_dir):# Load stable diffusion and move it to the GPUpipe = StableDiffusionPipeline.from_pretrained(model_dir, torch_dtype=torch.float16)pipe = pipe.to("cuda")return pipedef predict_fn(data, pipe):# get prompt & parametersprompt = data.pop("prompt", "")# set valid HP for stable diffusionheight = data.pop("height", 512)width = data.pop("width", 512)num_inference_steps = data.pop("num_inference_steps", 50)guidance_scale = data.pop("guidance_scale", 7.5)num_images_per_prompt = data.pop("num_images_per_prompt", 1)# run generation with parametersgenerated_images = pipe(prompt=prompt,height=height,width=width,num_inference_steps=num_inference_steps,guidance_scale=guidance_scale,num_images_per_prompt=num_images_per_prompt,)["images"]# create responseencoded_images = []for image in generated_images:buffered = BytesIO()image.save(buffered, format="JPEG")encoded_images.append(base64.b64encode(buffered.getvalue()).decode())# create responsereturn {"generated_images": encoded_images}
打包模型并上传至 S3 桶:
#Package model, Estimated time to spend 2min(V1),5min(V2)
!echo $(date)
!tar --exclude .git --use-compress-program=pigz -pcvf ./$SD_MODEL'.tar.gz' -C ./$SD_MODEL/ .
!echo $(date)from sagemaker.s3 import S3Uploaderprint(datetime.datetime.now())
# upload model.tar.gz to s3, Estimated time to spend 30s(V1), 1min(V2)
sd_model_uri=S3Uploader.upload(local_path=f"{SD_MODEL}.tar.gz", desired_s3_uri=f"s3://{sess.default_bucket()}/stable-diffusion")
print(f"=======S3 File Location========\nmodel uploaded to:\n{sd_model_uri}")print(datetime.datetime.now())
使用 HuggingFace 将模型部署至 Amazon SageMaker:
#init variables
huggingface_model = {}
predictor = {}from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model[SD_MODEL] = HuggingFaceModel(model_data=sd_model_uri, # path to your model and scriptrole=role, # iam role with permissions to create an Endpointtransformers_version="4.17", # transformers version usedpytorch_version="1.10", # pytorch version usedpy_version='py38', # python version used
)# deploy the endpoint endpoint, Estimated time to spend 8min(V2)
print(datetime.datetime.now())predictor[SD_MODEL] = huggingface_model[SD_MODEL].deploy(initial_instance_count=1,instance_type="ml.g4dn.xlarge",endpoint_name=f"{SD_MODEL}-endpoint"
)print(f"\n{datetime.datetime.now()}")
基于推理终端节点生成自定义图片:
from PIL import Image
from io import BytesIO
import base64# helper decoder
def decode_base64_image(image_string):base64_image = base64.b64decode(image_string)buffer = BytesIO(base64_image)return Image.open(buffer)response = predictor[SD_MODEL].predict(data={"prompt": ["A bird is flying in space","a photograph of an astronaut riding a horse",],"height" : 512,"width" : 512,"num_images_per_prompt":1}
)#decode images
decoded_images = [decode_base64_image(image) for image in response["generated_images"]]#visualize generation
for image in decoded_images:display(image)
3.4 模型生成效果
接下来,我们使用部署完成的模型,查看图像生成效果,例如我们使用 A bird is flying in space 和 Photos of horseback riding under the sea 可以得到以下图像:

可以看到,即使我们只给出关键词也能够生成纹理清晰、质量上乘的图像,我们也可以使用其他文本测试部署完成的图像生成模型。
最后,需要注意的是,在试验结束后清除本次实验开启的资源,在控制台逐一删除 S3 存储桶,以及 SageMaker 里创建的 Notebook、Endpoint 以及 Model 等资源
5. Amazon SageMaker 使用体验
在利用 Amazon SageMaker 搭建和部署机器学习模型过程中,充分体验了 Amazon SageMaker 提供的机器学习功能和工具,能够更快速、高效地进行机器学习任务,同时还具有灵活性、扩展性和易用性等诸多优势,总体而言,使用体验如下:
Amazon SageMaker提供了完备的机器学习工具,能够更快速地开发、训练和部署模型,Amazon SageMaker的自动化功能也可以帮助用户快速优化模型和参数,减少了机器学习的复杂度和工作量Amazon SageMaker提供了一个易于使用的交互式笔记本,能够更快速地探索和处理数据,也更容易地共享代码和笔记本,从而更容易地进行协作和交流Amazon SageMaker提供了多种不同的模型部署和管理方式,可以满足使用过程中在不同场景下的需求Amazon SageMaker平台提供了完善的监控和调试工具,能够更好地跟踪和分析模型性能,确保模型的稳定性和可靠性
小结
人工智能生成内容( Artificial Intelligence Generated Content, AIGC )凭借其独特的“创造力”与人类无法企及的创作生成速度掀起了一股人工智能狂潮。但是,由于生成模型构建的复杂性,在云中训练和部署人工智能模型成了大多 AIGC 用户和公司的首选。Amazon SageMaker 作为一款非常优秀的云端机器学习平台,提供了丰富的功能和工具,可以帮助我们更加高效地构建、训练和部署机器学习模型,解决了生成模型对于算力要求高昂的问题。本文主要回顾在参与亚马逊云科技的云上探索实验室活动过程中,基于 Amazon SageMaker 创建、部署 Stable Diffusion 模型的相关要点,充分展示了 Amazon SageMaker 在人工智能模型构建、训练和部署过程中的优势。
云上探索实验室活动
云上探索实验室旨在用技术实验、产品体验、案例应用等方式,让用户亲身感受最新、最热门的亚马逊云科技开发者工具与服务。云上探索实验室活动目前正在火热进行,通过群内指导和动手体验的形式开展,官方提供多套体验教程和快速上手资料,参与者可根据自身情况自行选择不同难度的实验进行实操,并通过提交不同形式的体验作品,通过这次活动,不仅可以探索更多机器学习和 AI 技术的应用场景,还可以结识更多志同道合的开发者。云上探索实验室活动地址:https://dev.amazoncloud.cn/experience,快来一起体验吧!