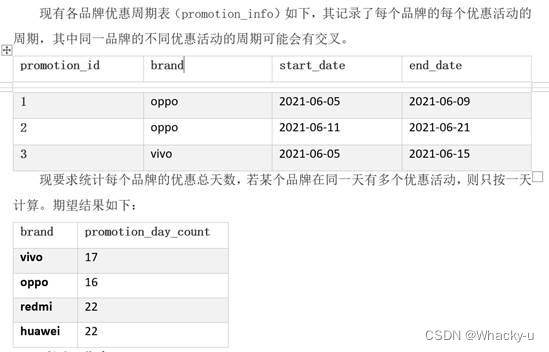
思路一:
首先想到的是借助炸裂函数,一行变成多行,就可以进行去重操作,然后再统计日期。
用到炸裂函数,就首先需要可以拿到起始和终止日期差大小的数组,然后再炸裂
那这个指定长度数组怎么获取呢?
先通过datediff + 1,就可以知道我们需要的数组是多大的
通过spilt( repeat(“,” , 4) ,’ , ') 这样就创建了一个有5个空字符串的数组,数组长度是5
所以就是spilt( repeat(“,” , diff) , ’,’ ) 【注意这个diff是不需要加1的,因为创建长度是五的数组,这个diff只要是4就够了】
炸完之后是下面这样,然后再进行一次row_number,进行排序,最后把排序的序号给start_date加上就行

或者直接不用explode(arr),直接用posexplode(arr) tmp as pos,item
这就不用row_number,可以直接加上这个pos了
思路二:
(1, ‘oppo’, ‘2021-06-05’, ‘2021-06-09’),
(2, ‘oppo’, ‘2021-06-11’, ‘2021-06-21’),
(3, ‘vivo’, ‘2021-06-05’, ‘2021-06-15’),
(4, ‘vivo’, ‘2021-06-09’, ‘2021-06-21’),
(5, ‘redmi’, ‘2021-06-05’, ‘2021-06-21’), 1974-01-01
(6, ‘redmi’, ‘2021-06-09’, ‘2021-06-15’), 2021-06-21
(7, ‘redmi’, ‘2021-06-17’, ‘2021-06-26’), 2021-06-26
(8, ‘huawei’, ‘2021-06-05’, ‘2021-06-26’),
(9, ‘huawei’, ‘2021-06-09’, ‘2021-06-15’),
(10, ‘huawei’, ‘2021-06-17’, ‘2021-06-21’);
但是也可以用一个别的思路:相当于就是通过更新start_date,来解决可能的时间交叉或者包含关系
同一个品牌,到当前行为止,去用到当前行之前的最大end_date日期,去比对当前的start_date如果大于最大end_date,那就说明没有交集,这一行的start_date就是原本的这个。否则start_date就是****date_add(max_end_date,1)
最后end - start 最后如果是正数就留下,负数就说明是算过了




![[保姆级教程]Windows安装MongoDB教程](https://img-blog.csdnimg.cn/direct/9ca554922b7e41a4adac42a7a114af10.png)