此为视频What are Transformers (Machine Learning Model)?的笔记。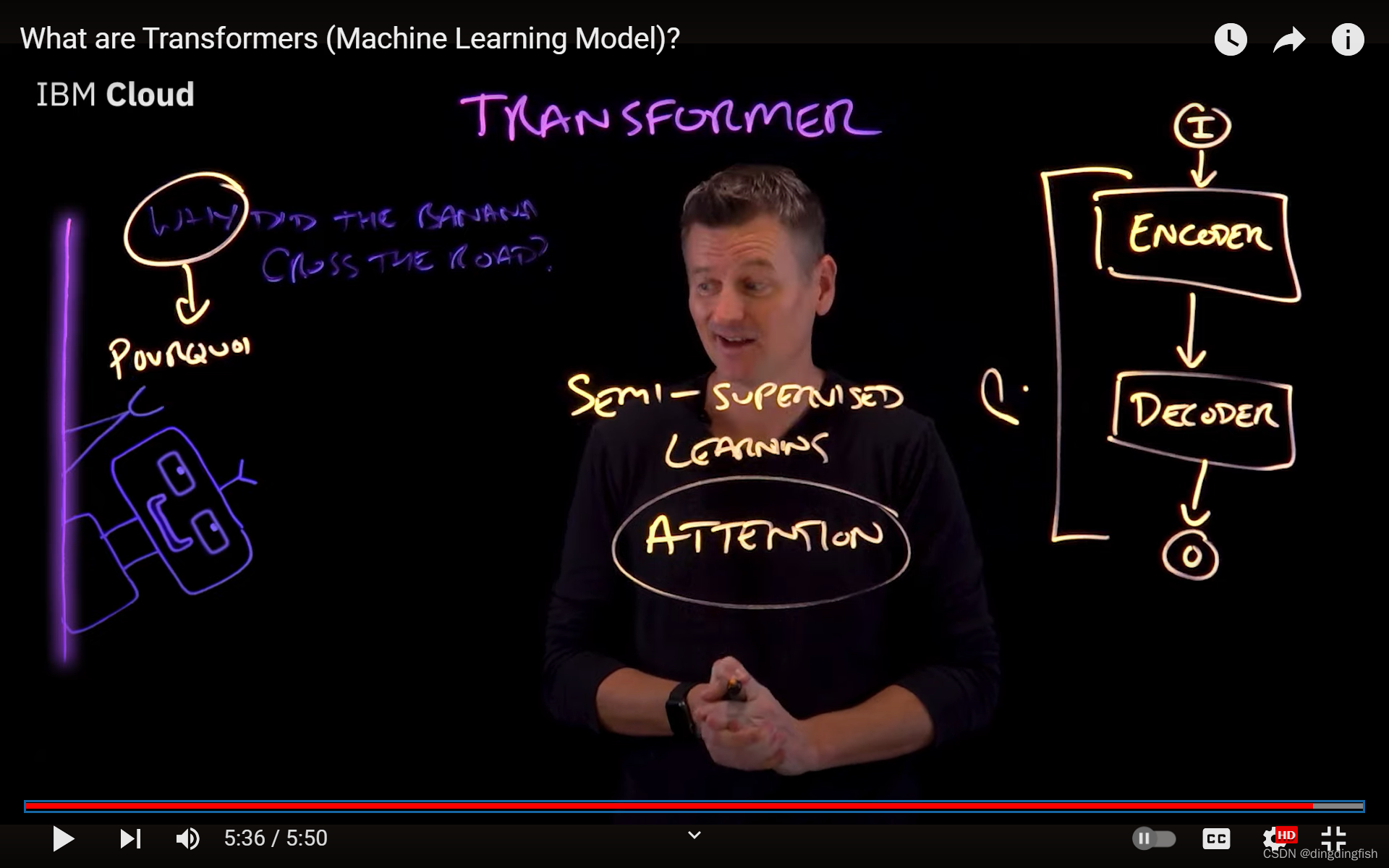
其实标题里已经揭示了最重要的一点:Transformer,也就是GPT中的T,是一种机器学习模型,或者更准确的说,是一种深度学习模型。基于翻译为中文可能会导致误解,所以文章中就不翻译了。
作者首先让gpt-3生成了一个笑话(笑话不重要,重要的是他是gpt生成的),gpt-3 是一种自回归语言模型,它生成的文本看起来像是人类编写的。
gpt-3就是transformer的一个例子,它可以从一个序列转换为另一个序列。
另一个很好的例子是语言翻译。例如翻译“How are you”。transformer由编码器和解码器2部分组成,分别负责输入和输出。
表面上看,翻译不过是简单的查找(lookup)工作,例如将‘Why’翻译为‘为什么’。但实际并非如此,短语中的词序经常会变化。transformer的工作方式是通过序列到序列的学习,其中transformer采用一系列标记(token,在本例中是句子中的单词),并预测输出序列中的下一个单词。
它通过迭代编码器层来实现这一点,以便编码器生成定义输入序列的哪些部分彼此相关的编码,然后将这些编码传递到下一个编码器层。解码器采用所有这些编码并使用它们派生的上下文来生成输出序列。
transformer 是半监督学习的一种形式。半监督是指它们以无监督的方式使用大量未标记的数据集进行预训练,然后通过监督训练进行微调,以使它们现在表现得更好。
Transformer 和循环神经网络或 RNN不同,因为其不一定按顺序处理数据。Transformer 使用称为**注意力机制(attention mechanism)**的东西,这提供了输入序列中项目周围的上下文。
因此,transformer不是以“How”这个词开始翻译,尽管它位于句子的开头。而是尝试识别为序列中每个单词带来含义的上下文,正是这种注意力机制使 transformer比必须按顺序运行的 rnn 等算法更具优势。
Transformer 并行运行多个序列,这大大加快了训练时间。
Transformer 还可用于做文档摘要。您可以将整篇文章作为输入序列,然后生成一个输出序列,该输出序列实际上只是总结要点的几个句子。
Transformer 可以创建全新的文档,例如写一篇完整的博客文章,除了语言之外,Transformer 还可以学习下棋和执行图像处理,甚至可以与卷积神经网络(RNN)的能力相媲美。