一、redis简介
概述 Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,使用复制来扩展读性能,使用分片来扩展写性能。
二、redis支持的数据类型

三、redis持久化
redis是内存非关系型数据库,如果不将内存中的数据保存到磁盘中,一旦服务器宕机或者重启,数据也将会丢失,所以redis也提供了持久化的功能特性。
RDB(Redis DataBase)
什么是RDB?
在主从复制中,rdb就是备用了,从机上面!
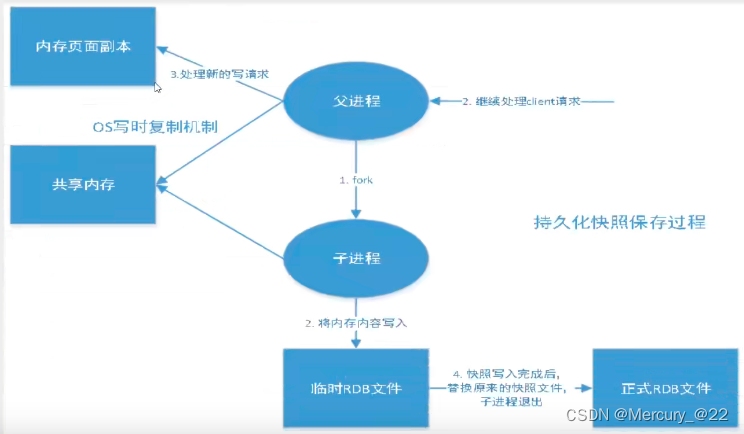
RDB持久化方式:redis会在指定的时间间隔内,将内存中的数据集快照(Snapshot快照)写入磁盘中,服务器重启或者宕机恢复时redis将快照文件直接读到内存中。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入一个临时文件中,待持久化过程都结束了,在用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何的IO操作的,这是确保了极高的性能。如果需要进行大规模数据的恢复,且对数据恢复的完整性不是非常敏感,那么RDB方式要比AOF凡是更高效。RDB方式的缺点就是最后一次的数据可能丢失。
生产环境我们会将这个文件进行备份!
==rdb保存的文件时dump.rdb==,都是在redis.conf配置文件中配置的。

触发机制
-
save规则满足的情况下,会触发rdb规则
-
执行flushall命令,也会触发rdb规则
-
退出redis,也会触发rdb规则,生成rdb文件
备份就会自动生成一个dump.rdb

如何恢复rdb文件
1、只需要将rdb文件放在redis的启动目录就可以,redis启动的时候会自动检查dump.rdb文件恢复其中的数据。
2、查看需要存放的位置

优点、缺点
优点:
1、适合大规模的数据恢复。
2、对数据的完整性要求不高。
缺点:
1、需要一定的时间间隔进行操作,如果redis宕机,最后一次修改的数据丢失。
2、fork进程的时候,会占用一定的内容空间。
AOF(Append Only File)
说白了就是将所有的执行命令记录下来,history,恢复的时候就把这个文件全部执行一遍!
什么是AOF?

AOF持久化方式:以日志的形式记录下来每个写操作,将Redis执行过的所有指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis恢复时会重新将文件中所有的命令执行一遍,以完成数据的恢复。
==Aof保存的是appendonly.aof==
append

默认是不开启的,需要手动配置!默认每秒执行一次! 将上图中的 appendonly no 修改为 appendonly yes就开启了aof持久化方式。重启redis生效!
如果这个aof文件有错误,这个时候redis是启动不起来的,我们需要修复这个aof文件,redis给我们提供了一个文件错误检查和修复的工具 ==redis-check-aof --fix==

如果文件正常,重启就可以直接恢复!
重写规则说明

如果aof文件大于64M,太大了!fork一个新的进程来将我们的文件进行重写!
优点、缺点

优点:
1、每次修改都同步,文件的完整性会更好!
2、每秒同步一次,可能会丢失一秒的数据!
3、从不同步,效率更高
缺点:
1、相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢!
2、aof运行效率也要比rdb慢,因为要进行io操作,所以redis默认配置的是rdb持久化!
扩展:
1、RDB 持久化方式能够在指定的时间间隔内对数据进行快照存储。
2、AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据, AOF命令以Redis协议追加保存每次写的操作到文件末尾, Redis还能对AOF文件进行后台重写.使得AOF文件的体积不至于过大。
3、只做缓存,如果只希望数据在服务器运行的时候存在,你也可以不使用任何持久化。
4、同时开启两种持久化方式。
● 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
● RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?作者建议不要,因为RDB更适合用于备份数据库( AOF在不断变化不好备份) , 快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万- -的手段。
5.性能建议
● 因为RDB文件只用作后备用途,建议只在Slave.上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则。
● 如果Enable AOF ,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了,代价是带来了持续的I0 ,二是AOF rewrite的最后将rewrite 过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率。AOF重写的基础大小默认值64M太小了可以设到5G以 上默认超过原大小100%大小重写可以改到适当的数值。
● 如果不Enable AOF , 仅靠Master-Slave Repllcation实现高可用性也可以。能省掉一大笔IO ,也减少了rewrite时带来的系统波动。代价是如果Master/Slave 同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个Master/Slave中的RDB文件,载入较新的那个,微博就是这种架构。
四、redis发布订阅
Redis 发布订阅(pub/sub)是一种==消息通信模式==:发送者(pub)发送消息,订阅者(sub)接收消息。实例:微信、微博、关注系统!
Redis 客户端可以订阅任意数量的频道。
订阅/发布消息图:

下图展示了频道channel1,以及订阅该频道的三个客户端 -- client1、client2、client3之间的关系:

命令
这些命令被广泛用于构建即时通讯应用,比如网络聊天室和实施广播、实时提醒等。

测试
订阅端:
127.0.0.1:6379> SUBSCRIBE ks
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "ks"
3) (integer) 1
1) "message"
2) "ks"
3) "12121313131"
1) "message"
2) "ks"
3) "1q2weeee"发布端:
127.0.0.1:6379> PUBLISH ks "12121313131"
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> PUBLISH ks "12121313131"
(integer) 1
127.0.0.1:6379> PUBLISH ks 1q2weeee原理
Redis是使用C实现的,通过分析Redis源码里的pubsub.c文件,了解发布和订阅机制的底层实现,籍此加深对Redis的理解。
Redis通过PUBLISH、SUBSCRIBE 和PSUBSCRIBE等命令实现发布和订阅功能。
通过SUBSCRIBE命令订阅某频道后, redis-server 里维护了一一个字典,字典的键就是一个个channel , 而字典的值则是一个链表,链表中保存了所有订阅这个channel的客户端。SUBSCRIBE 命令的关键,就是将客户端添加到给定channel的订阅链表中。

通过PUBLISH命令向订阅者发送消息, redis-server 会使用给定的频道作为键,在它所维护的channel字典中查找记录了订阅这个频道的所有客户端的链表,遍历这个链表,将消息发布给所有订阅者。
Pub/Sub从字面上理解就是发布( Publish )与订阅( Subscribe) , 在Redis中,你可以设定对某- -个key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
使用场景:
1、实时消息系统
2、实时聊天(频道当作聊天室,将消息回显给所有人即可)
3、订阅、关注系统
稍微复杂的场景需要采用消息中间件实现。
五、redis主从复制
概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader) ,后者称为从节点(slave/follower) ;
==数据的复制是单向的,只能由主节点到从节点。Master以写为主, Slave以读为主。==
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点) ,但一个从节点只能有一一个主节点。
主从复制的作用主要包括:
1、数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2、故障恢复: 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际,上是一种服务的冗余。
3、负载均衡: 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点) , 分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4、高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的,原因如下:
1、从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
2、从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G ,也不能将所有内存用作Redis存储内存;
一般来说,单台Redis最大使用内存不应该超过20G。
电商网站上的商品,一般都是一次上传,无数次浏览的,也就是读多写少。
对于这种场景,我们可以采用如下的架构:

主从复制,读写分离,80%的情况下都是在进行读操作,减缓服务器的压力,架构中经常使用。一主二从是最小主从架构!
项目中建议采用主从复制!
环境配置
只配置从库,不配置主库
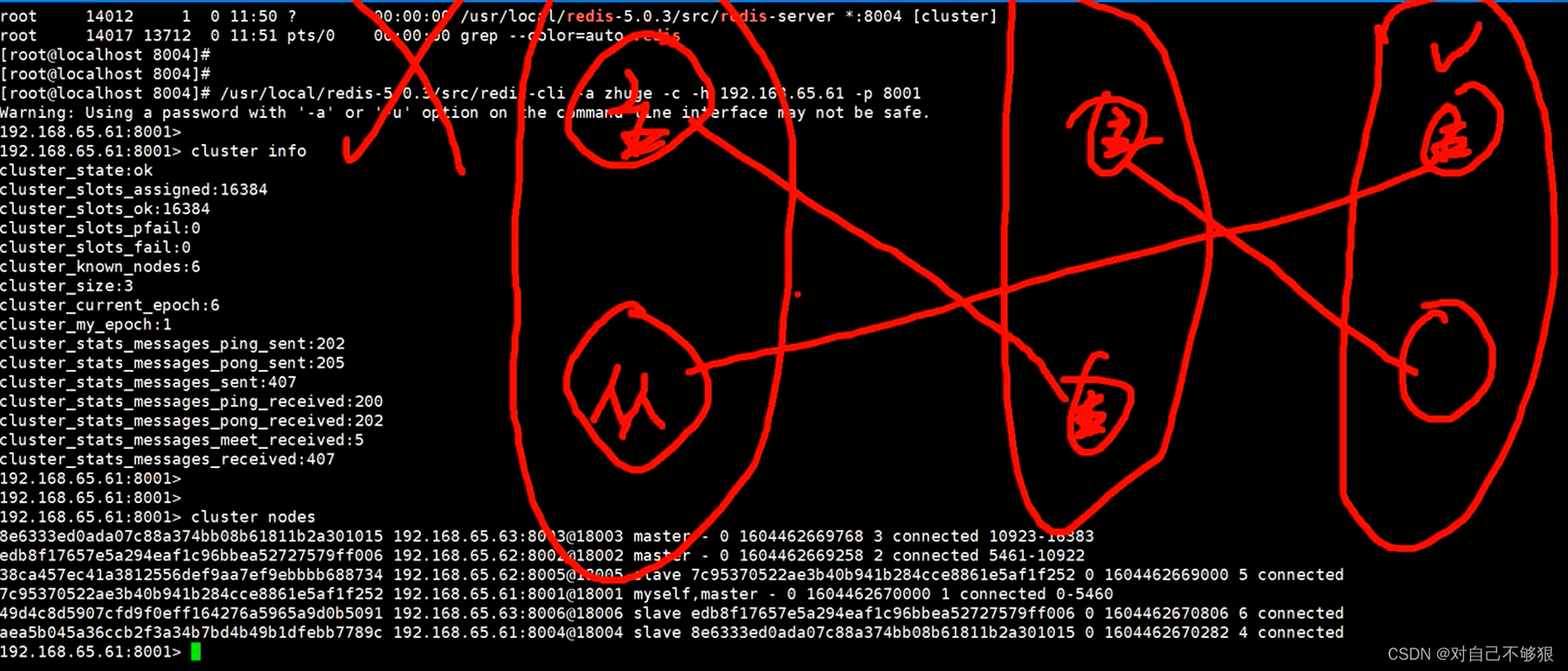
127.0.0.1:6379> info replication ## 查看当前库的信息
# Replication
role:master ## 角色 master
connected_slaves:0 ## 没有从机
master_replid:e94af554391d27e3b2b4349cc991c0175ee7ee36
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0复制3个配置文件,然后修改对应的信息
1、端口
2、pid名字
3、log名称
4、dump.rdb名称
**注意:**如果主机设置了密码,从机的配置文件需要配置主机的密码,例如:masterauth 123456
修改配置文件完成后,启动四个redis服务

一主三从配置例子(采用命令方式配置,实际工作中要采用配置文件配置方式)
==默认情况下,每台redis服务器都是主节点==,一般情况下只需要配置从机就好了。
主:79 从:80、81、82
slaveof host port ## 例如 slaveof 192.168.64.133 6379进入到80的redis-cli
[root@localhost redis]# ./redis-4.0.6/src/redis-cli -p 6380
127.0.0.1:6380> auth 123456 ## 因为设置了密码,所以先认证,在操作
127.0.0.1:6380> slaveof 127.0.0.1 6379 查看主从信息
127.0.0.1:6380> info replication ## 执行查看主从信息
# Replication
role:slave ## 当前节点角色为从节点
master_host:127.0.0.1 ## 主节点ip
master_port:6379 ## 主节点端口
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:1
master_link_down_since_seconds:1631778770
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:e2662f39102f6e88297e4a094720561a92208898
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0其他从节点依次如上操作即可
回到主节点6379查看主从信息:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:3
slave0:ip=127.0.0.1,port=6380,state=online,offset=42,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=42,lag=1
slave2:ip=127.0.0.1,port=6382,state=online,offset=42,lag=1
master_replid:ec660e4e775ad673b60ce9028ddcab0cf7f391cc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:42
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:42主从配置注意
主从配置时要在配置文件配置,这样才不会随着服务重启而导致配置丢失,而不是如上述采用命令方式配置。

如上图所示,在从机的配置文件中做如上配置即可。
细节
主机写操作,从机读操作!!
测试:
127.0.0.1:6379> set k1 v1 ## 主机设置一个键值 OK
127.0.0.1:6380> keys * ## 从机查看键值 1) "k1"
127.0.0.1:6381> keys * ## 从机查看键值 1) "k1"
127.0.0.1:6382> keys * ## 从机查看键值 1) "k1"
如果在从机进行写操作会报错:
127.0.0.1:6382> set k2 v2 (error) READONLY You can't write against a read only slave.
存在的问题
如上述配置,如果主机6379宕机了,那么从机配置的主机信息还是6379的信息,无法进行写操作,需要手动配置切换主机。也就是说没有主机自动选举功能的。
手动处理主机
如果主机断开连接了,可以使用slaveof no one 让自身变为主机,其他的节点就可以手动连接到最新的主节点!
复制原理
slave 启动成功连接到master后会发一个sync同步命令。
master 接到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
- ==全量复制==:slave服务在接收到数据文件数据后,将其存盘并加载到内存中。
- ==增量复制==:master继续将新的所有收集到的修改命令依次传给slave,完成同步。
但是只要是==重连==master,一次完全同步(全量复制)将自动执行。
六、redis哨兵模式
(自动选举主节点模式)
概述
主从切换技术的方法是:当主服务器宕机以后,需要手动把一台从服务器切换为主服务器,这是需要人工干预的,费时费力,还会造成一段时间内服务不可用,这是一种很不好的方法,更多时候,我们需要考虑哨兵模式。redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。
实现后台监控主机是否发生故障,如果故障了根据投票数自动将从节点转换为主节点。
哨兵模式是一种特殊的模式,首先redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。

这里哨兵有两个作用:
- 通过发送命令,让redis服务器返回响应,监控其运行状态,包括主服务器和从服务器。
- 当哨兵检测到master宕机,会自动将slave切换成为master,然后通过**==发布订阅==**通知其他从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多少兵模式。

假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果有一个哨兵发起,进行failover(故障转移)操作,切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主服务器,这个过程称为客观下线。
配置哨兵
1、配置哨兵配置文件sentinel.conf
# sentinel monitor [被监控的服务器名称host] [port] 1
sentinel monitor myredis 127.0.0.1 6379 1# sentinel auth-pass [masterName] [password]
sentinel auth-pass myredis 123456最后的数字1表示主节点宕机,从节点投票看让谁接替成为主机,票数多的就切换成为主节点。
2、启动哨兵
./redis-4.0.6/src/redis-sentinel ./redis-4.0.6/sentinelconfig/sentinel.conf4960:X 16 Sep 20:21:02.538 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
4960:X 16 Sep 20:21:02.539 # Redis version=4.0.6, bits=64, commit=00000000, modified=0, pid=4960, just started
4960:X 16 Sep 20:21:02.539 # Configuration loaded
4960:X 16 Sep 20:21:02.541 * Increased maximum number of open files to 10032 (it was originally set to 1024)._._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 4.0.6 (00000000/0) 64 bit.-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in sentinel mode|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379| `-._ `._ / _.-' | PID: 4960`-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 4960:X 16 Sep 20:21:02.544 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
4960:X 16 Sep 20:21:02.546 # Sentinel ID is b212a965b1d99373c9963b5a0b7edf7edfb30ca5
4960:X 16 Sep 20:21:02.546 # +monitor master myredis 127.0.0.1 6379 quorum 2
4960:X 16 Sep 20:21:02.547 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
4960:X 16 Sep 20:21:02.550 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
4960:X 16 Sep 20:21:02.552 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ myredis 127.0.0.1 6379测试
1、把主节点6379 SHUTDOWN
127.0.0.1:6379> SHUTDOWN not connected> exit [root@localhost redis]#
2、观察setinel服务的控制台变化
5290:X 16 Sep 20:35:31.837 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
5290:X 16 Sep 20:35:31.840 # Sentinel ID is ff7b0e56034455e17d90c8e1fb17dcc2571c805b
5290:X 16 Sep 20:35:31.840 # +monitor master myredis 127.0.0.1 6379 quorum 1
5290:X 16 Sep 20:35:31.842 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:35:31.844 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:35:31.846 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:43.792 # +sdown master myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:43.792 # +odown master myredis 127.0.0.1 6379 #quorum 1/1
5290:X 16 Sep 20:36:43.792 # +new-epoch 1
5290:X 16 Sep 20:36:43.792 # +try-failover master myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:43.797 # +vote-for-leader ff7b0e56034455e17d90c8e1fb17dcc2571c805b 1
5290:X 16 Sep 20:36:43.797 # +elected-leader master myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:43.797 # +failover-state-select-slave master myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:43.866 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:43.866 * +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:43.941 * +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:44.922 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:44.922 # +failover-state-reconf-slaves master myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:44.971 * +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:45.764 * +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:45.764 * +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:45.829 * +slave-reconf-sent slave 127.0.0.1:6382 127.0.0.1 6382 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:46.822 * +slave-reconf-inprog slave 127.0.0.1:6382 127.0.0.1 6382 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:46.822 * +slave-reconf-done slave 127.0.0.1:6382 127.0.0.1 6382 @ myredis 127.0.0.1 6379
5290:X 16 Sep 20:36:46.879 # +failover-end master myredis 127.0.0.1 6379
### 此处进行了主节点的切换
5290:X 16 Sep 20:36:46.880 # +switch-master myredis 127.0.0.1 6379 127.0.0.1 6380
5290:X 16 Sep 20:36:46.881 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6380
5290:X 16 Sep 20:36:46.881 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ myredis 127.0.0.1 63803、查看6380节点状态
127.0.0.1:6380> info replication
# Replication
role:master ### 6380节点已经变成了主节点
connected_slaves:2 ## 从节点有6381、6382两个
slave0:ip=127.0.0.1,port=6381,state=online,offset=20802,lag=1
slave1:ip=127.0.0.1,port=6382,state=online,offset=20802,lag=1
master_replid:9fb64c7537820a99e3f944a55587384258980466
master_replid2:fcf88beb89daffc4efe650e1fcf23f998c4e19bb
master_repl_offset:20934
second_repl_offset:6348
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:20934以上证明哨兵起了切换主节点的作用。
注意:如果之前的主节点重新上线后,只能归并到新的主节点下,当作从节点,这就是哨兵模式的规则。
哨兵模式
优点:
1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有。
2、主从切换,故障可以转移,系统的可用性就会更好。
3、哨兵模式就是主从模式的升级,手动到自动,更加健壮。
缺点:
1、redis 不好在线扩容,集群一旦达到上线,在线扩容就十分麻烦。
2、实现哨兵模式的配置很麻烦,里面有很多选择。
七、redis缓存穿透、雪崩、击穿
服务的高可用问题!!
redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但是同时,它也带来一些问题。其中,就是数据一致性问题,从严格的意义来讲,这个问题无解。如果对数据的一致性要求很高,那么就不要使用缓存。
另外的一些问题时是:缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案。
缓存穿透(查不到)
概念
缓存穿透是指用户查询一个数据的时候,发现redis缓存没有,也就是没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败,当用户很多的时候,缓存都没有命中,于是请求都去请求持久层数据库。这会给数据库造成很大的压力,这时候相当于出现了缓存穿透。
解决方案
布隆过滤器
布隆过滤器是指一种数据结构,对所有可能查询的参数以hash形式存储,在控制层进行校验,不符合则丢弃,从而避免了对底层存储的查询压力。

缓存空对象
当缓存以及数据库中都没有命中后,即使返回空对象也将其存储起来,同时会设置一个过期时间,之后在访问这个数据将从缓存中获取,保护了数据库。

但是这样也产生了一些问题:
1、如果空值能够被缓存起来,这意味着缓存需要更多的空间储存更多的键,因为这当中会有很多的空值的键。
2、即使对控空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于数据一致性的业务有影响。
缓存击穿(量太大,缓存过期)
概念
这里需要注意的和缓存穿透的区别,缓存击穿,是指一个key非常热点,在不停的扛大并发,大并发集中对这个点进行访问,当这个key在失效的瞬间,持续的大并发就击穿缓存,直接请求数据库,就像在屏障上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库查询最新的数据,并且回写缓存,会导致数据库瞬间压力过大。
解决方案
设置热点数据永远不过期
从缓存层面来看,由于没有设置过期时间,所以不会出现热点过期后产生的问题。
加互斥锁
加互斥锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后台服务,其他线程没有得到分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩
概念
缓存雪崩,指的是在某一个时间段,缓存集中过期失效。或者redis宕机。
产生雪崩的原因之一,比如马上双十一零点,准备抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点的时候,这批商品的缓存就都过期了,而对这批商品的访问查询,都落到了数据库上,所以对数据库而言,就产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。

其实集中过期,倒不是非常致命,比较致命的是缓存雪崩,是缓存服务器的某个节点宕机或者断网。因为自然形成的雪蹦,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是周期性的对数据库产生压力而已。而缓存服务器节点的宕机,都会数据库服务器造成的压力是不可预知的,很可能瞬间把数据库压垮。
解决方案
redis高可用
搭建redis集群,保证redis服务高可用。
限流降级
在缓存失效后,通过加锁或者队列来控制读取数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
提前把需要缓存的数据缓存,并且设置合理的过期时间,且每个key的缓存时间设置不同,让缓存失效的时间尽量均匀分布。









![[Linux开发工具]——make/Makefile的使用](https://img-blog.csdnimg.cn/direct/0381afaf457c42b1883104112a2401c1.png)