- HDFS
- Iceberg
- hadoop
- spark
HDFS
面向PB级数据存储的分布式文件系统,可以存储任意类型与格式的数据文件,包括结构化的数据以及非结构化的数据。HDFS将导入的大数据文件切割成小数据块,均匀分布到服务器集群中的各个节点,并且每个数据块多副本冗余存储,保证了数据的可靠性。HDFS还提供专有的接口API,用以存储与获取文件内容。
HDFS的基本架构如图:
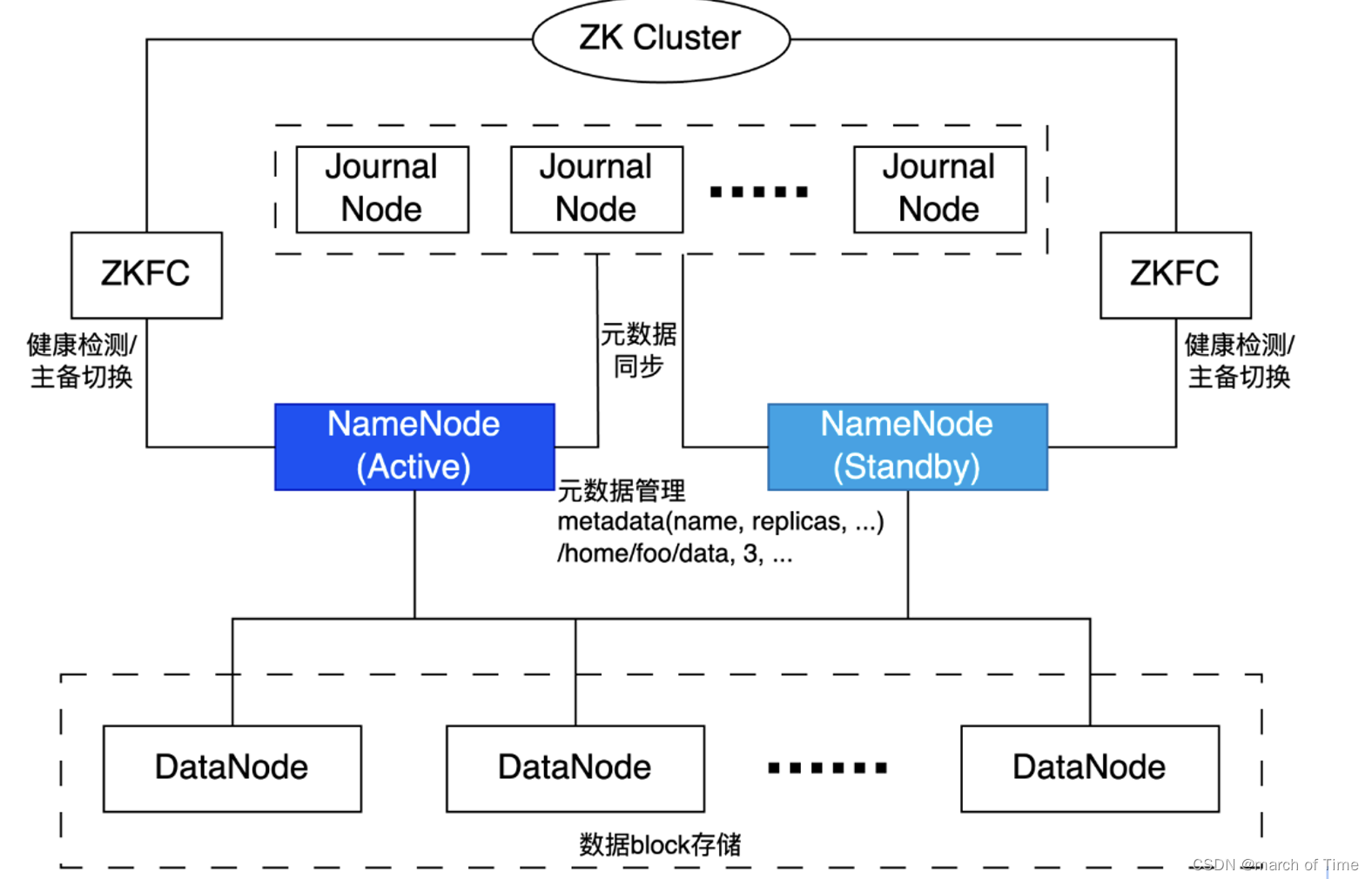
HDFS基础架构主要包含组件:NameNode、Standby NameNode、DataNode等。NameNode是HDFS核心组成部分,DataNode用于数据存储节点。
NameNode:NameNode 是 HDFS 的主节点,负责管理文件系统的元数据,包括文件和目录的结构、文件到数据块(Block)的映射、数据块到数据节点(DataNode)的映射等。在 Hadoop 3.x 版本中,NameNode 的内存效率得到了提高,因为它引入了更紧凑的数据结构和编码方案。
Secondary NameNode:在 Hadoop 3.x 版本中,Secondary NameNode 已经被替换为 Standby NameNode,作为备用的 NameNode。当活动的 NameNode 失效时,Standby NameNode 可以接管其工作,从而提高了系统的可用性。
DataNode:DataNode 是 HDFS 的工作节点,它负责存储和检索数据块。在 Hadoop 3.x 版本中,引入了 Erasure Coding(纠删码)技术,可以在保证数据可靠性的同时,减少存储空间的需求。
Client:Client 是使用 HDFS 的用户或应用程序。Client 通过 NameNode 获取文件的元数据和数据块的位置,然后直接从 DataNode 读取或写入数据块。
Quorum Journal Manager (QJM):在 Hadoop 3.x 版本中,为了提高 NameNode 的可用性和数据的一致性,引入了 Quorum Journal Manager。QJM 是一个协调多个 NameNode 的服务,它记录 NameNode 的操作日志,并在 NameNode 切换时保证数据的一致性。
HDFS Federation:HDFS Federation 允许有多个 NameNode,每个 NameNode 管理文件系统的一部分命名空间(Namespace),从而提高了系统的可扩展性。
通过这种架构,HDFS 在 Hadoop 3.x 版本中提供了更高的可用性、更高的存储效率和更好的可扩展性,更适应大数据处理的需求。
Iceberg
Apache Iceberg 是一种新型的用于大规模数据分析的开源表格式。它被设计用于存储移动缓慢的大型表格数据。它旨在改善 Hive、Trino(PrestoSQL)和 Spark 中内置的事实上的标准表布局。Iceberg 可以屏蔽底层数据存储格式上的差异,向上提供统一的操作 API,使得不同的引擎可以通过其提供的 API 接入。
Apache Iceberg 具备以下能力:
模式演化(Schema evolution):支持 Add(添加)、Drop(删除)、Update(更新)、Rename(重命名)和 Reorder(重排)表格式定义。
分区布局演变(Partition layout evolution):可以随着数据量或查询模式的变化而更新表的布局。
隐式分区(Hidden partitioning):查询不再取决于表的物理布局。通过物理和逻辑之间的分隔,Iceberg 表可以随着数据量的变化和时间的推移发展分区方案。错误配置的表可以得到修复,无需进行昂贵的迁移。
时光穿梭(Time travel):支持用户使用完全相同的快照进行重复查询,或者使用户轻松检查更改。
版本回滚(Version rollback):使用户可以通过将表重置为良好状态来快速纠正问题。
在可靠性与性能方面,Iceberg 可在生产中应用到数十 PB 的数据表,即使没有分布式 SQL 引擎,也可以读取这些巨大规模的表:
扫描速度快,无需使用分布式 SQL 引擎即可读取表或查找文件。
高级过滤,基于表元数据,使用分区和列级统计信息对数据文件进行裁剪。
Iceberg 被设计用来解决最终一致的云对象存储中的正确性问题:
可与任何云存储一起使用,并且通过避免调用 list 和 rename 来减少 HDFS 的 NameNode 拥塞。
可序列化的隔离,表更改是原子性的,用户永远不会看到部分更改或未提交的更改。
多个并发写入使用乐观锁机制进行并发控制,即使写入冲突,也会重试以确保兼容更新成功。
Iceberg 设计为以快照(Snapshot)的形式来管理表的各个历史版本数据。快照代表一张表在某个时刻的状态。每个快照中会列出表在某个时刻的所有数据文件列表。Data 文件存储在不同的 Manifest 文件中,Manifest 文件存储在一个 Manifest List 文件中,Manifest 文件可以在不同的 Manifest List 文件间共享,一个 Manifest List 文件代表一个快照。
Manifest list 文件是元数据文件,其中存储的是 Manifest 文件的列表,每个 Manifest 文件占据一行。
Manifest 文件是元数据文件,其中列出了组成某个快照的数据文件列表。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(例如每列的最大最小值、空值数等)、文件的大小以及文件中数据的行数等信息。
Data 文件是 Iceberg 表真实存储数据的文件,一般是在表的数据存储目录的 data 目录下。
hadoop
Apache™ Hadoop® 项目开发用于可靠、可扩展、分布式计算的开源软件。
Apache Hadoop 软件库是一个框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。 它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。 该库本身不是依靠硬件来提供高可用性,而是旨在检测和处理应用程序层的故障,以便在计算机集群之上提供高可用性服务,而每台计算机都可能容易出现故障。
Hadoop 分布式文件系统 (HDFS) 是一种分布式文件系统,设计用于在商用硬件上运行。 它与现有的分布式文件系统有许多相似之处。 然而,与其他分布式文件系统的区别是显着的。 HDFS 具有高度容错性,旨在部署在低成本硬件上。 HDFS 提供对应用程序数据的高吞吐量访问,适合具有大型数据集的应用程序。 HDFS 放宽了一些 POSIX 要求,以支持对文件系统数据的流式访问。 HDFS 最初是作为 Apache Nutch Web 搜索引擎项目的基础设施而构建的。 HDFS 是 Apache Hadoop Core 项目的一部分。
YARN 的基本思想是将资源管理和作业调度/监控的功能拆分为单独的守护进程。 这个想法是拥有一个全局的 ResourceManager (RM) 和每个应用程序的 ApplicationMaster (AM)。 应用程序可以是单个作业,也可以是作业的 DAG。ResourceManager 和 NodeManager 构成了数据计算框架。 ResourceManager是系统中所有应用程序之间资源仲裁的最终权威。 NodeManager 是每台机器的框架代理,负责容器、监视其资源使用情况(CPU、内存、磁盘、网络)并将其报告给 ResourceManager/Scheduler。每个应用程序的 ApplicationMaster 实际上是一个特定于框架的库,其任务是与 ResourceManager 协商资源并与 NodeManager 一起执行和监视任务。
spark
Apache Spark 是用于大规模数据处理的统一分析引擎。 它提供 Java、Scala、Python 和 R 中的高级 API,以及支持通用执行图的优化引擎。 它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的 Spark SQL、用于 pandas 工作负载的 pandas API on Spark、用于机器学习的 MLlib、用于图形处理的 GraphX 以及用于增量计算和流处理的 Structured Streaming
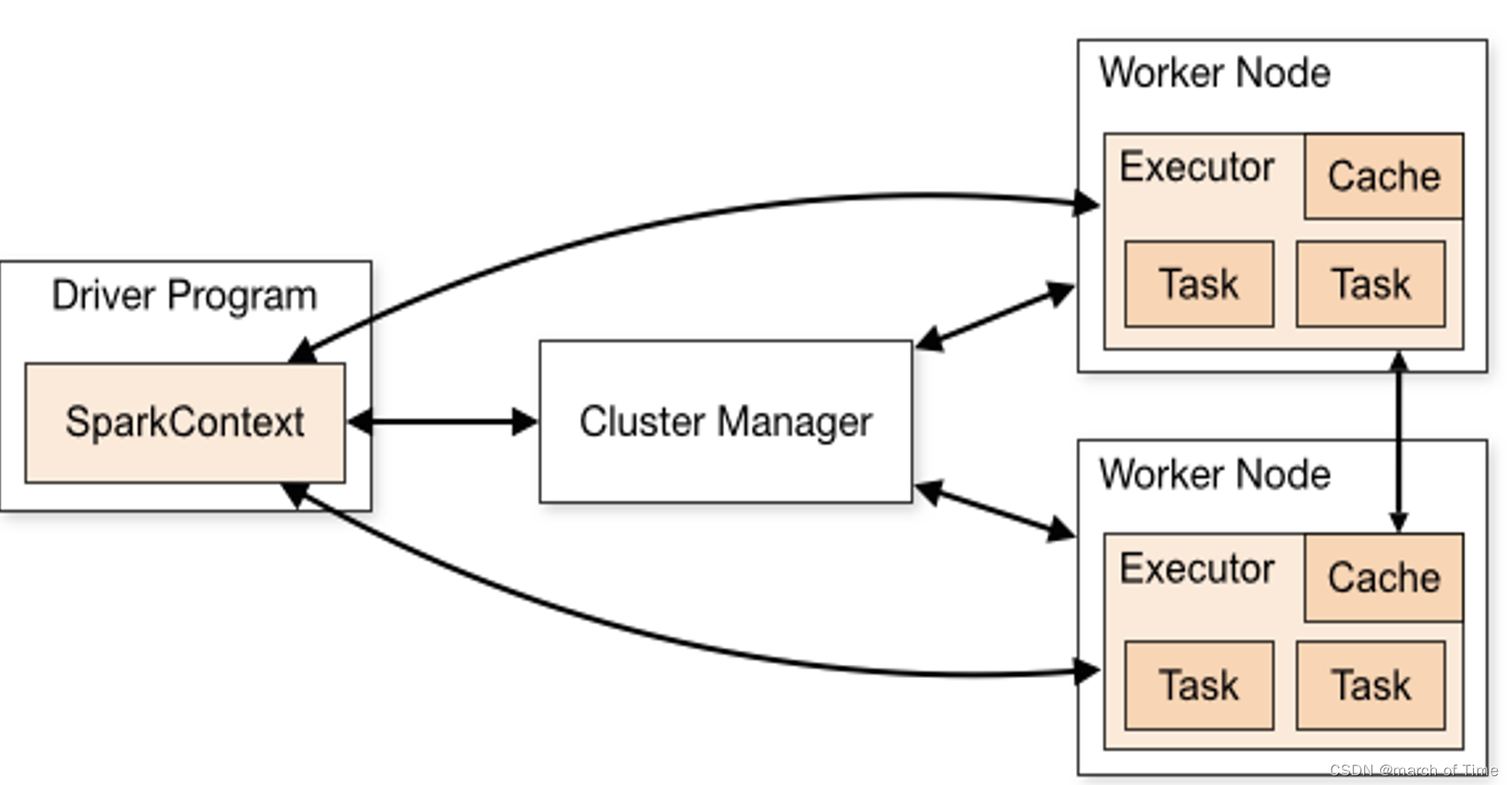
以上Spark架构说明如下:
- 每个应用程序都有自己的执行程序进程,这些进程在整个应用程序的持续时间内保持运行并在多个线程中运行任务。 这样做的好处是可以在调度端(每个驱动程序调度自己的任务)和执行器端(来自不同应用程序的任务在不同的 JVM 中运行)将应用程序彼此隔离。 但是,这也意味着如果不将数据写入外部存储系统,则无法在不同的 Spark 应用程序(SparkContext 实例)之间共享数据。
- Spark 对于底层集群管理器是不可知的。 只要它能够获取执行程序进程,并且这些进程相互通信,即使在也支持其他应用程序(例如 Mesos/YARN/Kubernetes)的集群管理器上运行它也相对容易。
- 驱动程序必须在其整个生命周期中侦听并接受来自其执行程序的传入连接(例如spark.driver.port)。 因此,驱动程序必须可从工作节点进行网络寻址。由于Driver在集群上调度任务,因此它应该靠近工作节点运行,最好在同一局域网上。 如果您想远程向集群发送请求,最好向驱动程序打开 RPC 并让它从附近提交操作,而不是在远离工作节点的地方运行驱动程序。
- 容器自动伸缩
TBDS云原生集群支持Spark运行在容器之上,通过使用Spark的Dynamic Resource Allocation功能实现资源的弹性伸缩,以达到资源的充分利用。Spark的Dynamic Resource Allocation可以根据工作负载动态调整应用程序占用的资源。 这意味着,如果不再使用资源,您的应用程序可能会将资源返还给集群,并在以后有需求时再次请求它们。 如果多个应用程序共享 Spark 集群中的资源,则此功能特别有用。





![[项目前置]如何用webbench进行压力测试](https://img-blog.csdnimg.cn/direct/b6f897b40e38404fbcfd302aee903403.png)