前言
在我们学习C语言或者C++时肯定都听过老师讲过地址的概念而且老师肯定还会讲栈区、堆区等区域的概念,那么这个地址是指的物理内存地址吗?这里这些区域又是如何划分的呢?
我们在使用C语言的malloc或者C++的new函数开辟空间时,开辟的空间是在物理内存上吗?
通过本篇内容的学习相信你的这些疑问都将会被解答,并且会对进程的地址空间有个全新的认识
一、初识进程地址空间
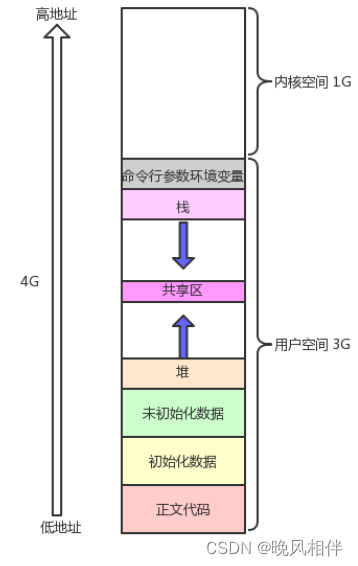
当我们学习C语言或者C++的时候,老师肯定都会画下面这幅图,但是我们并不理解。
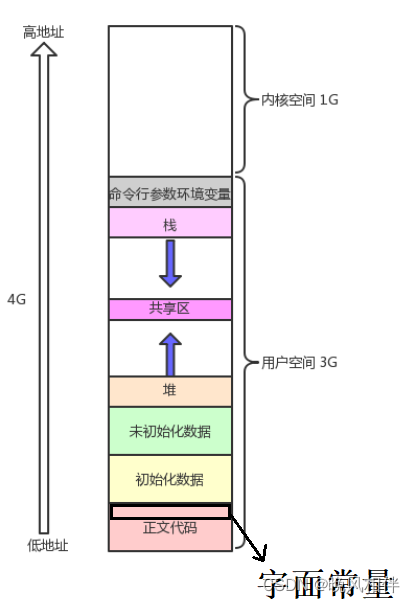
其实下面的这幅图描绘的就是进程地址空间中各个区域的分布。
验证地址空间的分布
用段代码来验证地址空间的排布
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int g_unval;//未初始化数据
int g_val = 100;//初始化数据int main(int argc, char* argv[], char* env[])
{printf("code addr: %p\n", main);//正文代码printf("init global addr: %p\n", &g_val);//初始化数据printf("uninit global add:%p\n", &g_unval);//未初始化数据char* head_memory = (char*)malloc(10);printf("heap addr:%p\n", head_memory);//堆区printf("stack addr:%p\n", &head_memory);//栈区for(int i = 0; i < argc; i++){printf("argv[%d]:%p\n", i, argv[i]);//命令行参数}for(int i = 0; env[i]; i++){printf("env[%d]:%p\n", i, env[i]);//环境变量}
}

从打印结果可以看出地址是由低到高的,也确实是上图所画的那样,那么上面还有两个箭头又是怎么回事呢。
我们将上面代码进行小小的改造来观察一下结果。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int g_unval;//未初始化数据
int g_val = 100;//初始化数据int main(int argc, char* argv[], char* env[])
{printf("code addr: %p\n", main);//正文代码printf("init global addr: %p\n", &g_val);//初始化数据printf("uninit global add:%p\n", &g_unval);//未初始化数据char* head_memory = (char*)malloc(10);char* head_memory1 = (char*)malloc(10);char* head_memory2 = (char*)malloc(10);char* head_memory3 = (char*)malloc(10);printf("heap addr:%p\n", head_memory);//堆区printf("heap addr:%p\n", head_memory1);//堆区printf("heap addr:%p\n", head_memory2);//堆区printf("heap addr:%p\n", head_memory3);//堆区printf("stack addr:%p\n", &head_memory);//栈区printf("stack addr:%p\n", &head_memory1);//栈区printf("stack addr:%p\n", &head_memory2);//栈区printf("stack addr:%p\n", &head_memory3);//栈区for(int i = 0; i < argc; i++){printf("argv[%d]:%p\n", i, argv[i]);//命令行参数}for(int i = 0; env[i]; i++){printf("env[%d]:%p\n", i, env[i]);//环境变量}
}
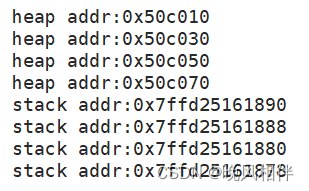
观察分析打印结果,我们知道了上图的两个箭头其实是代表着堆栈的增长方向,堆区是向高地址方向增长,栈区是向低地址方向增长。记忆口诀:堆栈相对而生
正文代码
顾名思义就是用来存放我们的正文代码的,其实我们的main函数也就是保存在正文代码中
初始化数据和未初始化数据(全局)
当我们声明一个全局变量时,并且给这个全局变量一个初始值,那么这个全局变量就属于初始化数据;而没有给这个全局变量初始值,那么这个全局变量就属于未初始化数据。
堆区
当我们在用C语言或者C++的malloc、new等开辟空间的函数时,它们所开辟空间的区域就是堆区。
栈区
由编译器自动分配释放,存放函数的参数值、返回值和局部变量,在程序运行过程中实时分配和释放,栈区由操作系统自动管理。
共享区
主要用来加载动态库的
命令行参数和环境变量
也就是main函数的参数,前两个参数用来获取命令行参数,第三个参数即为环境变量。
想了解环境变量的内容可以看看这篇文章哦——Linux下环境变量
字面常量
再来看看下面代码能编过吗
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int g_unval;//未初始化数据
int g_val = 100;//初始化数据int main(int argc, char* argv[], char* env[])
{"helloworld";10;'a';printf("code addr: %p\n", main);//正文代码printf("init global addr: %p\n", &g_val);//初始化数据printf("uninit global add:%p\n", &g_unval);//未初始化数据
}
很显然"helloworld"、10、'a’是能编过的,因为它们是属于字面常量,那么字面常量在内存中又存储在那个区域呢?我们可以打印一下它们的地址看看
int main(int argc, char* argv[], char* env[])
{const char* str = "helloworld";printf("code addr: %p\n", main);//正文代码printf("init global addr: %p\n", &g_val);//初始化数据printf("uninit global add:%p\n", &g_unval);//未初始化数据printf("read only string addr:%p\n", str);
}
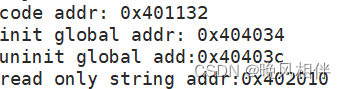
从打印结果可以看出字面常量的地址和正文代码的地址比较接近,所以字面常量和正文代码是放在一起的
static变量
那么static变量有是存在那个区域的呢?
让我们打印它的地址来看看
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int g_unval;//未初始化数据
int g_val = 100;//初始化数据int main(int argc, char* argv[], char* env[])
{const char* str = "helloworld";static int a = 10;printf("code addr: %p\n", main);//正文代码printf("init global addr: %p\n", &g_val);//初始化数据printf("uninit global add:%p\n", &g_unval);//未初始化数据printf("a stack addr:%p\n", &a);printf("read only string addr:%p\n", str);}
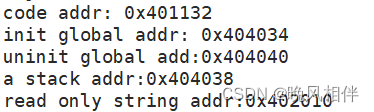
可以看到静态变量和初始化、未初始化的地址接近说明是在这之间
因此得出结论:static修饰局部变量,本质是将该变量开辟在全局区。
二、进程地址空间
虚拟地址空间的提出
在操作系统刚出来那会,我们直接去使用的是物理地址,当我们磁盘中的可执行程序加载到物理内存中时,由于我们使用的是物理内存,那么我们在一个进程中定义一个指针,这个指针指向了另一个进程,那么这个进程就可以访问到另一个进程中的内容了。

如果你的进程2是存放了你的游戏账号和密码的,那么这种行为是及其不安全的。
为了避免这样的问题存在,所以在现代计算机中提出了虚拟地址空间的概念
所以现在进程中的地址空间其实说的就是虚拟地址空间
虚拟地址空间通过一种映射关系就能找到物理地址,而这个映射关系称之为页表。如下图所示
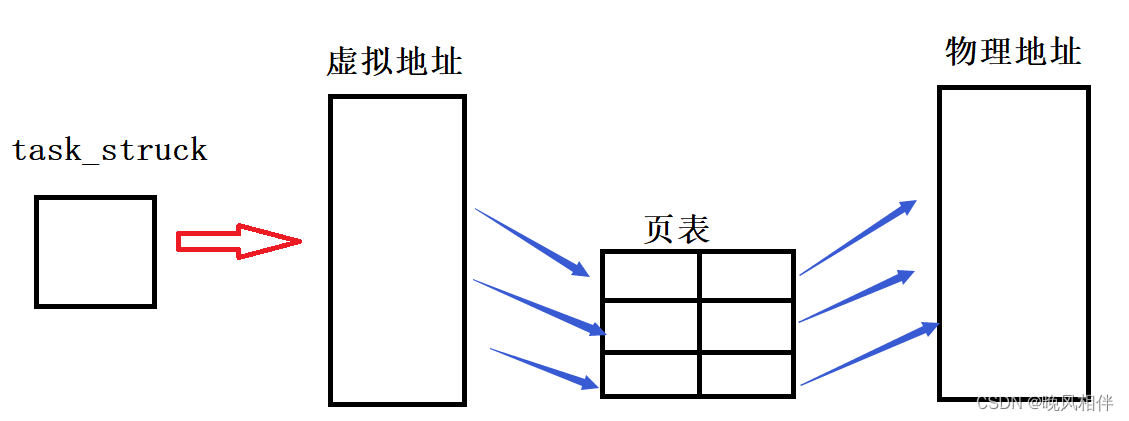
如果虚拟地址中存在野指针或者是其它不安全的行为时操作系统会禁止通过页表访问到物理内存。
区域划分的理解
在我们上面那副彩图中是划分了各种区域的,那么我们如何理解各种区域的划分呢?
所谓区域的划分其实本质上是在定义start和end从而来标定一个范围。这个就比如你和你的同桌划分38线一样,这左边区域属于你,右边区域属于你的同桌,谁都不许越界。
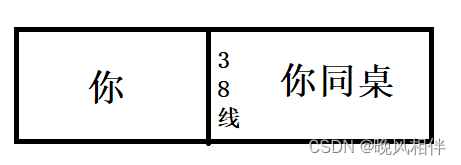
那么在地址空间中也是一样的,地址空间本质是一个结构体,在这个结构体中会存在着大量的start和end来划分这些区域。那么对于栈区向低地址方向增长和堆区向高地址方向增长,本质上也就是给start和end加减上一定的值。
在Linux内核中把这个进程地址空间定义为了mm_struct的结构体

这就是进程空间里定义的范围
进程地址空间和页表是每个进程都私有一份的,只要保证,每一个进程的页表映射的是物理内存的不同区域,就能做到进程之间不会互相干扰,从而保证进程的独立性。
验证虚拟地址空间的存在
那么让我们用一段代码来见识一下虚拟地址空间的存在
#include <stdio.h>
#include <unistd.h>int g_val = 100;int main()
{pid_t id = fork();if(id == 0){//childint cnt = 0;while(1){printf("I am father,pid: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);sleep(1);cnt++;if(cnt == 5){g_val = 200;printf("child chage g_val 100 -> 200 success\n");}}}else{//fatherwhile(1){printf("I am child,pid: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);sleep(1);}}
}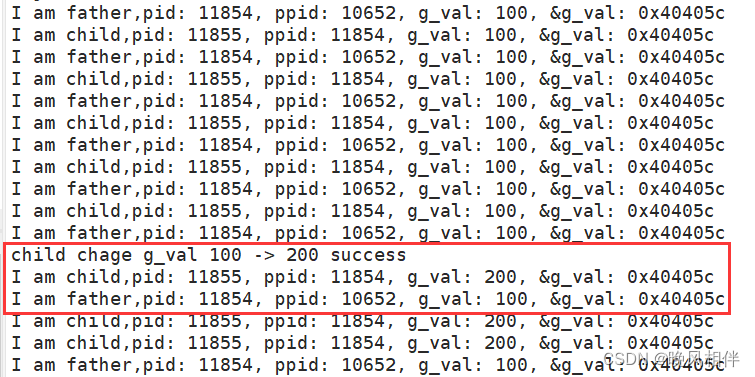
在5秒之前父进程和子进程的g_val值是一样的,5秒之后对子进程中的g_val值进行修改
从这里就可以看出来问题了,父子进程的g_val的地址明明是一样的,但是为什么打印出来的值是不一样的呢?
解释
其实这里的地址就是虚拟地址,因为只有是虚拟地址才能解释的通,地址是一样的,值却不一样的原因。
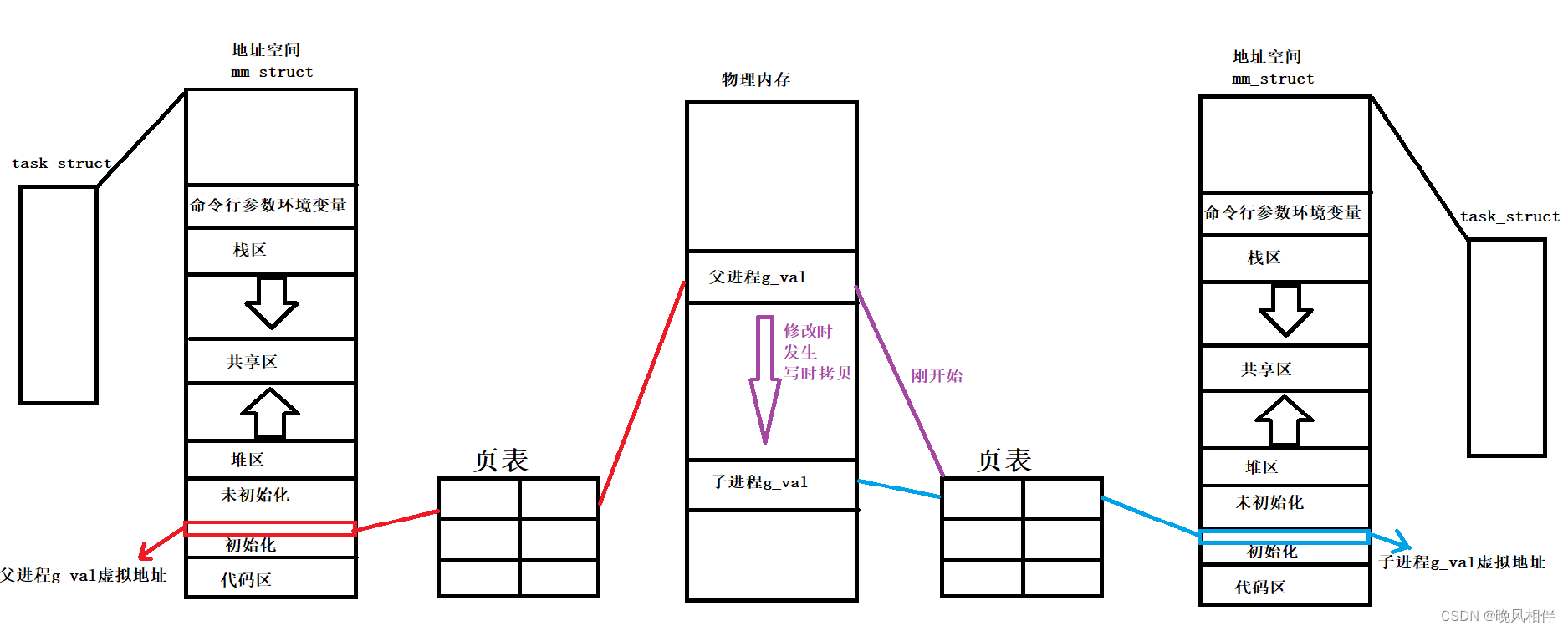
在子进程被创建时,子进程会继承父进程的很多属性的,其中就包括了地址空间和页表,既然子进程和父进程的地址空间一样,页表一样,那么父子进程的g_val虚拟地址也是一样的,并且子进程和父进程的g_val通过页表映射到物理内存时指向的是同一个变量。
当在子进程中对g_val进行修改时,操作系统没有立即更改,而是给子进程重新开辟了一块空间,然后再修改子进程页表中的映射关系,所以子进程会在新开辟的这块空间中把g_val的值给改了。在这当中地址空间的虚拟地址,没有发生变化,但是物理内存经过页表映射被映射到了不同的区域,所以在打印时,会看到地址一样而值却不一样的现象。而这种现象叫做写时拷贝。这也就可以解释为什么fork会有两个返回值了,其实就是因为返回时发生了写时拷贝。
深入理解虚拟地址
我们的程序在编译,形成可执行程序,还没有加载到内存的时候,我们的程序内部就已经有地址了,那么这个地址是虚拟地址吗
答案是:是的,是虚拟地址
可执行程序在编译的时候,内部已经有地址了
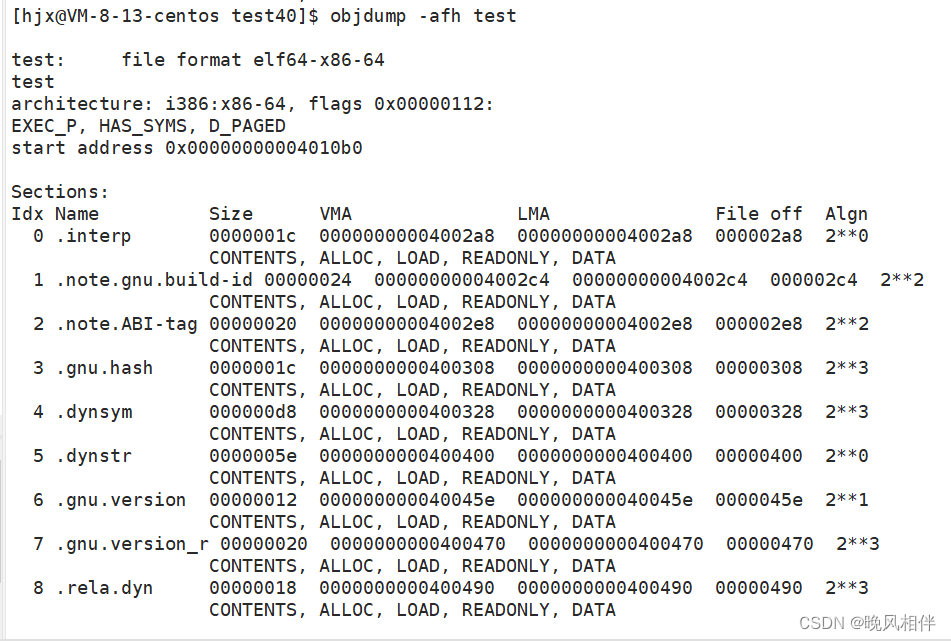
objdump指令是用来查看反汇编的,这里显示的VMA(virtual memory address)其实就是虚拟地址。
地址空间不仅仅是操作系统内部需要遵守的,编译器同样也要遵守,即编译器编译代码时,就已经给我们形成了各个区域(代码区、栈区、堆区等),并且采用的是和Linux内核中一样的编址地址的方式,给每一行代码都进行了编址,所以程序在编译的时候,每一个字段早已经具有了一个虚拟地址了
有了上面的铺垫,让我们再继续往深处理解一下
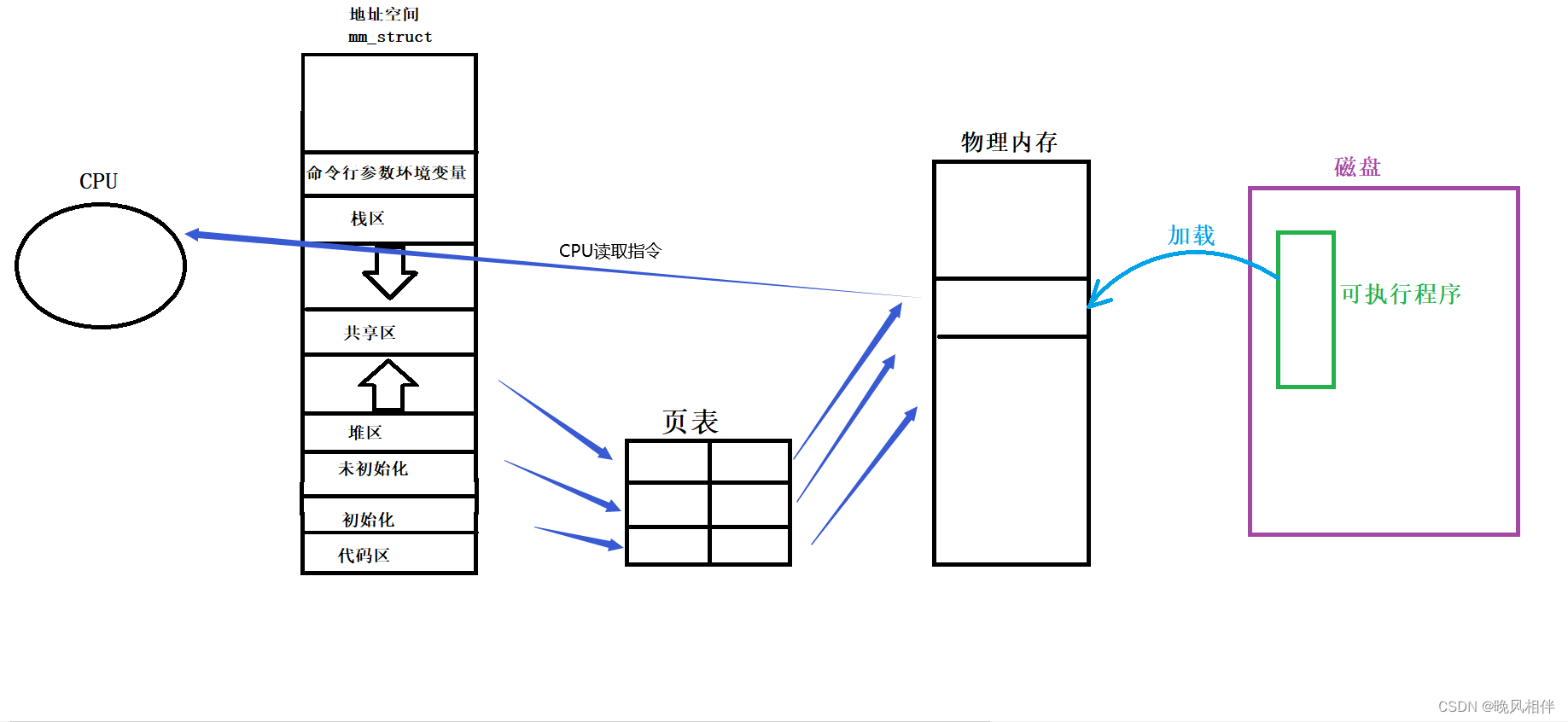
当我们的可执行程序加载到物理内存时,操作系统会根据可执行程序中的每一个变量,每一个函数的虚拟地址来填充mm_struct的start和end,然后再通过页表和物理内存建立映射关系。所以虚拟地址和页表最开始的数据是从编译器给代码形成的地址中来的。
那么当我们的CPU需要读取的时候,是先找到虚拟地址,然后根据页表的映射关系,读到了在物理内存上的某一个指令。
注意问题来了,当CPU读到这条指令的时候,指令内部也有地址,那么这个地址是虚拟地址还是物理地址呢?
答案当然还是虚拟地址啦
CPU读取到这个指令内部的还是虚拟地址,如果这个指令是一个函数跳转,需要跳转到下一条指令,那么通过这个虚拟地址,就会跳转到mm_struct的指定位置,再利用页表,通过页表的映射再到物理内存上拿到对应的指令,然后再加载到CPU中,而CPU读取这个指令,其内部的地址依旧是虚拟地址,因此CPU读取到的还是虚拟地址。所以CPU拿到的地址永远都是虚拟地址。
这里可能有点绕,多读几遍并结合图理解就好了
小结
- 地址空间本质是一个结构体,在这个结构体中存在着大量的start和end来划分各个区域。
- 编译器编译代码时,会在程序内部会形成地址,形成地址是虚拟地址
- 当CPU读取这个可执行程序时,进入到mm_struct里,通过页表映射,然后从物理内存中读取,但是从物理内存中读到的依旧是虚拟地址。
为什么要有进程地址空间
- 有了地址空间的存在,可以对用户的一些非法操作进行有效拦截,从而有效的保护了物理内存。因为地址空间和页表是操作系统创建并维护的,这也就意味着凡是想使用地址空间和页表进行映射,也一定要早操作系统的监督下来进行访问,所以这样也就保护了物理内存中的所有的合法数据,包括各个进程以及内核中相关的有效数据。
- 因为有地址空间和页表的存在,我们未来的数据可以在物理内存中的任意位置进行加载,因为可以通过页表的映射找到在物理内存中对应的位置,那么物理内存的分配和进程的管理就做到了没有关系,也就是说内存管理模块和进程管理模块实现了解耦合(解耦合表示的是模块和模块之间关联性不强)。
- 因为地址空间的存在,所以在上层申请空间时,其实是先在地址空间上申请的,物理内存可以一个字节都不给你,而当你真正对物理内存进行访问时,才会执行内存的管理算法,给你申请内存,构建页表的映射关系,然后你就可以进行内存的访问了。(这样做是可以有效避免了当你在C语言使用malloc或者在C++上使用new来开辟空间时,如果开辟空间是直接在物理内存上的那么你对这块空间不去使用,那么就会造成内存空间的浪费,非常影响效率;但如果是先在地址空间上开辟空间,等你真正要使用这块空间才在物理内存上开辟它,这样就可以对内存的使用效率达到100%,而这样的策略就叫做延迟分配,可以有效的提高整机的效率)
- 每一个进程都有一份自己的地址空间和页表,并且各个区域是有序的,进而可以通过页表映射到物理内存的不同区域(映射到物理内存时也是有序的),从而实现了进程的独立性。(进程需要共享时也就是把页表的映射改掉即可)
今天的分享就到这里,如果内容有误,还望指出,谢谢!!!


![[C语言]——内存函数](https://img-blog.csdnimg.cn/direct/e8e6c78f039044ad8a436cf14e24b8a3.png)