3.23
hw机试【二叉树】
剑指offer32
剑指 offer32(一、二、三)_剑指offer 32-CSDN博客
从上到下打印二叉树I
一棵圣诞树记作根节点为 root 的二叉树,节点值为该位置装饰彩灯的颜色编号。请按照从 左 到 右 的顺序返回每一层彩灯编号。
输入:root = [8,17,21,18,null,null,6]输出:[8,17,21,18,6]
层序遍历:
-
Deque添加root
-
while队列不为空
-
size -- > 0;poll
-
子节点不为空,offer进队列
class Solution {public int[] decorateRecord(TreeNode root) {/**层序遍历:1. Deque添加root2. while队列不为空3. size -- > 0;poll4. 子节点不为空,offer进队列,先左后右*/ArrayList<Integer> list = new ArrayList<>();Deque<TreeNode> deque = new LinkedList<>();if(root == null) return new int[0];deque.offer(root);while(!deque.isEmpty()){int size = deque.size();while(size-- > 0){TreeNode cur = deque.poll();list.add(cur.val);if(cur.left != null) deque.offer(cur.left);if(cur.right != null) deque.offer(cur.right); }}int[] res = new int[list.size()];for(int i = 0; i < list.size(); i++){res[i] = list.get(i);}return res;}}
注意细节
-
二叉树的 广度优先遍历 ,其通常借助 队列 的先入先出特性来实现。
-
if(root == null) return new int[0];返回不能直接返回null因为预期输出为[]所以需要新建一个空数组来返回 -
Deque<TreeNode> deque = new LinkedList<>();要用TreeNode -
注意顺序,先加左,再加右
-
ArrayList<Integer> list = new ArrayList<>();不能作为结果返回,需要赋值给数组int[] res = new int[list.size()]; -
时间复杂度 O(N) : N 为二叉树的节点数量,即 BFS 需循环 N 次。 空间复杂度 O(N) : 最差情况下,即当树为平衡二叉树时,最多有 N/2个树节点同时在 queue 中,使用 O(N)大小的额外空间。
从上到下打印二叉树II
LCR 150. 彩灯装饰记录 II - 力扣(LeetCode)
一棵圣诞树记作根节点为 root 的二叉树,节点值为该位置装饰彩灯的颜色编号。请按照从左到右的顺序返回每一层彩灯编号,每一层的结果记录于一行。
输入:root = [8,17,21,18,null,null,6]输出:[[8],[17,21],[18,6]]
-
层序遍历
-
一次性poll出全部,用一个临时列表来接,再整合成一个数组
class Solution {public List<List<Integer>> decorateRecord(TreeNode root) {Deque<TreeNode> deque = new LinkedList<>();List<List<Integer>> res = new ArrayList<>();if(root != null) deque.offer(root);while(!deque.isEmpty()){int size = deque.size();ArrayList<Integer> list = new ArrayList<>();while(size-- > 0){TreeNode temp = deque.poll();list.add(temp.val);if(temp.left != null) deque.offer(temp.left);if(temp.right != null) deque.offer(temp.right);}res.add(list);}return res;}}
注意细节
-
需要返回的是列表形式
-
List<List<Integer>> res = new ArrayList<>();if(root != null) deque.offer(root);直接再root为null的时候不向结果添加内容即可
从上到下打印二叉树III
一棵圣诞树记作根节点为 root 的二叉树,节点值为该位置装饰彩灯的颜色编号。请按照如下规则记录彩灯装饰结果:
-
第一层按照从左到右的顺序记录
-
除第一层外每一层的记录顺序均与上一层相反。即第一层为从左到右,第二层为从右到左。
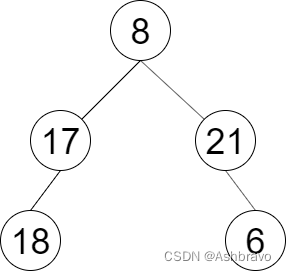
输入:root = [8,17,21,18,null,null,6]输出:[[8],[21,17],[18,6]]
算法流程:
-
特例处理: 当树的根节点为空,则直接返回空列表 [] ;
-
初始化: 打印结果空列表 res ,包含根节点的双端队列 deque ;
-
BFS 循环: 当 deque 为空时跳出;
-
新建列表 tmp ,用于临时存储当前层打印结果;
-
当前层打印循环: 循环次数为当前层节点数(即 deque 长度);
-
出队: 队首元素出队,记为 node;
-
打印: 若为奇数层,将 node.val 添加至 tmp 尾部;否则,添加至 tmp 头部;
-
添加子节点: 若 node 的左(右)子节点不为空,则加入 deque ;
-
-
将当前层结果 tmp 转化为 list 并添加入 res ;
-
-
返回值: 返回打印结果列表 res 即可;
class Solution {public List<List<Integer>> decorateRecord(TreeNode root) {Deque<TreeNode> deque = new LinkedList<>();List<List<Integer>> res = new ArrayList<>();if(root != null) deque.offer(root);while(!deque.isEmpty()){LinkedList<Integer> temp = new LinkedList<>();int size = deque.size();while(size-- > 0){TreeNode cur = deque.poll();if(res.size() % 2 == 0) temp.addLast(cur.val);else temp.addFirst(cur.val);if(cur.left != null) deque.offer(cur.left);if(cur.right != null) deque.offer(cur.right);}res.add(temp);}return res;}}
注意细节
-
节点队列正常添加,只是依据不同层数,输出临时结果的时候排序方式不同
-
需要层数信息,不能直接从节点直到层数信息,但是可以
`List<List<Integer>> res用于存储最终的结果,其中每个子列表代表树的一层,这样当其中一个结果,就是第一层,两个结果就是第二层 -
所以
res % 2 == 0,比如第一层,此前结果有0个,也就是当前处理奇数层,需要 向队尾添加元素,来保持输出正序 -
当
res % 2 != 0比如第二层,此前结果有1个,也就是当前处理偶数层,需要 向队头添加元素,来保持输出逆序 -
LinkedList<Integer> temp = new LinkedList<>();注意temp.addLasttemp.addFirst,结果用LinkedList而不是deque-
双端操作:
LinkedList实现了List接口和Deque接口,这意味着它既可以作为一个列表使用,也支持双端队列的操作(如addFirst和addLast)。在这个场景中,需要根据当前层是奇数层还是偶数层来决定是从列表的头部还是尾部插入节点值,这使得LinkedList成为一个理想的选择。 -
结果组织:最终结果
res是一个List<List<Integer>>,每个子列表代表树的一层。使用LinkedList可以轻松地在列表的前端或后端添加元素,而无需担心性能问题。这对于实现“之字形”添加元素(即一行从左到右,下一行从右到左)特别有用。 -
简化代码:通过使用
LinkedList的addFirst和addLast方法,可以直接根据层数的奇偶性决定添加元素的方向,无需进行额外的条件判断或使用其他数据结构。
在实现层序遍历时,
deque(双端队列)被用来按层存储树的节点,这样可以从队列的前端取出当前层的节点,并根据遍历的需要,将下一层的节点添加到队列的后端。与之相对的,temp列表(一个LinkedList)在每一层的遍历过程中被用来存储当前层的节点值,添加顺序根据当前是奇数层还是偶数层动态决定,从而实现了“之字形”遍历的要求。总之,
LinkedList的使用是为了利用其灵活的元素添加方式(即可从头部也可从尾部添加元素),以符合“之字形”遍历的需求。而deque的使用则是为了有效地进行层序遍历,确保每次都能处理完当前层的所有节点,再按顺序处理下一层的节点。 -
质数
Leetcode204 计数质数
给定整数 n ,返回 所有小于非负整数 n 的质数的数量 。
埃氏筛【重要】
由希腊数学家厄拉多塞(Eratosthenes\rm EratosthenesEratosthenes)提出,称为厄拉多塞筛法,简称埃氏筛。
如果 x是质数,那么大于 x 的 x的倍数 2x,3x,… 一定不是质数,因此我们可以从这里入手。
设立一个isPrime[i],0为合数,1为质数;质数的所有倍数都一定是合数
显然不会将质数标记成合数;另一方面,当从小到大遍历到数 x时,倘若它是合数,则它一定是某个小于 x 的质数 y 的整数倍,故根据此方法的步骤,我们在遍历到 y时,就一定会在此时将 x标记为 isPrime[x]=0。因此,这种方法也不会将合数标记为质数。
对于一个质数 x,如果按上文说的我们从 2x 开始标记其实是冗余的,应该直接从 x⋅x 开始标记,因为 2x,3x,…这些数一定在 x 之前就被其他数的倍数标记过了,例如 2 的所有倍数,3 的所有倍数等。
我们从2号岛屿开始,它是第一个质数岛。按照一开始的想法,我们可能会想从4号岛屿(2的2倍)开始标记。但实际上,当我们继续探索3号岛屿,并确认它也是一个质数岛时,我们会发现3号岛屿的2倍——也就是6号岛屿——已经被作为2号岛屿的3倍标记过了。实际上,所有小于4(2号岛屿的平方)的质数岛的倍数岛屿,都已经被标记过了。
class Solution {public int countPrimes(int n) {// 使用一个整数数组代替布尔数组,提高空间利用效率// 数组的每个位置初始被设置为1,表示该位置对应的数字初始假设为质数int[] isPrime = new int[n];Arrays.fill(isPrime, 1);// 最终的质数计数int ans = 0;// 从2开始遍历到n,因为2是最小的质数for (int i = 2; i < n; ++i) {// 如果当前数字是质数(即isPrime[i] == 1)if (isPrime[i] == 1) {// 对于每个质数i,增加计数ans += 1;// 如果i的平方小于n,开始标记i的倍数// 这里使用了(long)来避免整数溢出的情况if ((long) i * i < n) {// 从i的平方开始,标记i的所有倍数为非质数(即isPrime[j] = 0)// 为什么从i的平方开始标记?因为小于i的平方的倍数在之前已经被标记过了for (int j = i * i; j < n; j += i) {// j += i`意味着在每一次循环中,我们都向`j`添加`i`的值。这实际上是在遍历`i`的所有倍数isPrime[j] = 0;}}}}// 返回计数结果return ans;}}
-
j += i意味着在每一次循环中,我们都向j添加i的值。这实际上是在遍历i的所有倍数:i * i(i的平方)、i * i + i(i的平方加上i)、i * i + 2i(i的平方加上2i),依此类推。这保证了所有i的倍数都会被遍历并标记为非质数。
跳过偶数
class Solution {public int countPrimes(int n) {if(n <= 2) return 0;boolean[] isPrime = new boolean[n];Arrays.fill(isPrime, true);for(int i = 3; i * i < n; i += 2){ // 跳过偶数if(isPrime[i]){for(int j = i * i; j < n; j += 2*i){ // 从i*i开始,间隔为2*i(跳过偶数倍数)isPrime[j] = false;}}}int ans = 1; // 计数器开始时考虑了2,所以从1开始for(int k = 3; k < n; k += 2){ // 只计算奇数ans += isPrime[k] ? 1 : 0;}return ans;}}
枚举(会超时)
当我们检查一个数x是否为质数时,基本的方法是看它是否能被比自己小的任何正整数整除(除了1)。直接的方法是从2遍历到x-1,检查x是否能被这之间的任何数整除。但这种方法在x很大时效率非常低。
为了提高效率,我们使用数学上的一个事实:如果x是合数(即非质数),那么它必定有一对因数a和b,使得a*b=x,其中至少有一个因数不大于√x。换句话说,如果x不能被任何小于或等于√x的正整数整除,那么x就是质数。
直接判断是否整除,遍历从 2 到 该数的平方根(包括平方根)
for (int i = 2; i * i <= x; ++i) {if (x % i == 0) {// 发现一个除数,x不是质数return false;
循环初始化:
for (int i = 2; i * i <= x; ++i)初始化了一个循环变量i,从2开始。2是最小的质数,也是最小的可能因数。循环条件:
i * i <= x。这个条件用于判断i的平方是否仍然小于或等于x。如果i的平方大于x,循环就会停止。这是因为如果x可以被一个大于它平方根的数整除,那么它也必定可以被一个小于或等于它平方根的数整除。因此,检查到x的平方根就足够了。循环体:
if (x % i == 0) { return false; }在循环体内,代码检查x是否可以被i整除,即x % i == 0。如果是,说明找到了一个因数i,这表明x不是质数,因为质数定义为只能被1和它本身整除的数。此时函数返回false。循环迭代:
++i。每次循环结束时,i递增1。这意味着算法将逐一检查所有小于或等于x平方根的正整数,看它们是否能整除x。通过上述过程,如果循环结束都没有发现能整除
x的i(即没有执行return false;),则说明x没有小于或等于其平方根的非1因数,因此x是质数,函数将返回true。
class Solution {public int countPrimes(int n) {int ans = 0; // 初始化质数计数器为0// 从2开始遍历到n(不包括n),因为2是最小的质数for (int i = 2; i < n; ++i) {// 对于每个数i,检查它是否是质数// 如果是,将结果计数器加1ans += isPrime(i) ? 1 : 0;}// 返回小于n的质数的总数return ans;}public boolean isPrime(int x) {// 遍历从2到x的平方根(包括平方根)// 如果x可以被任何这些数整除,则x不是质数for (int i = 2; i * i <= x; ++i) {if (x % i == 0) {// 发现一个除数,x不是质数return false;}}// 如果没有找到任何可以整除x的数,则x是质数return true;}}
Leetcode1175 质数排列
1175. 质数排列 - 力扣(LeetCode)
请你帮忙给从 1 到 n 的数设计排列方案,使得所有的「质数」都应该被放在「质数索引」(索引从 1 开始)上;你需要返回可能的方案总数。让我们一起来回顾一下「质数」:质数一定是大于 1 的,并且不能用两个小于它的正整数的乘积来表示。最后注意计算过程中需要对10的九次方加7取模。
使用埃拉托斯特尼筛法(埃氏筛)来判断单个数字是否为质数并不直接适用,因为埃氏筛的核心优势在于它能高效地筛选出一定范围内所有的质数,而不是检查单个数字的质数状态。然而,当你需要统计一个范围内的质数数量或者需要频繁地检查多个数是否为质数时,使用埃氏筛法就非常高效。
质数判断 + 组合数学
所有合数放在合数索引上,质数放置和合数放置是相互独立的,总的方案数即为「所有质数都放在质数索引上的方案数」×「所有合数都放在合数索引上的方案数」。求「所有质数都放在质数索引上的方案数」,即求质数个数 numPrimes 的阶乘。「所有合数都放在合数索引上的方案数」同理。
class Solution {// 定义MOD为1000000007,用于取模运算,保证结果不会溢出int范围static final int MOD = 1000000007;public int numPrimeArrangements(int n) {// 统计1到n之间质数的数量int numPrimes = 0;for (int i = 1; i <= n; i++) {if (isPrime(i)) {// 如果i是质数,则计数器加一numPrimes++;}}// 计算质数排列方法的数量和非质数排列方法的数量的乘积// 并对MOD取模return (int) (factorial(numPrimes) * factorial(n - numPrimes) % MOD);}// 方法:判断一个数n是否是质数public boolean isPrime(int n) {if (n == 1) {// 1不是质数return false;}for (int i = 2; i * i <= n; i++) {// 如果n可以被任何小于或等于它的平方根的数整除,则n不是质数if (n % i == 0) {return false;}}// 如果没有找到任何能整除n的数,则n是质数return true;}// 方法:计算n的阶乘并对MOD取模public long factorial(int n) {long res = 1;for (int i = 1; i <= n; i++) {// 计算阶乘的同时对MOD取模,避免中间结果溢出res *= i;res %= MOD;}return res;}}res %= MOD;这一操作是进行模运算,确保结果保持在一个安全的数值范围内。这里的MOD是一个常量,值为1000000007(10的9次方加7),它是一个常用的大质数。进行模运算的原因有几个:
防止溢出:在计算阶乘或者其他可能产生很大数值的运算时,结果可能会超出变量类型(如
int或long)的最大表示范围,导致溢出。通过在每一步乘法后立即对MOD取模,可以保证中间结果和最终结果都不会超出long类型的表示范围。数学性质:对于模运算,有
(a * b) % MOD = ((a % MOD) * (b % MOD)) % MOD。这意味着可以在每一步操作后取模,而不影响最终结果,这样做可以持续保持结果的大小在可控范围内。题目要求:在很多编程题目中,特别是涉及大数运算的题目,为了避免处理极大数值和简化问题,通常要求结果对某个质数取模后输出。
1000000007是一个常用的模数,因为它足够大,能够减少因取模引起的冲突(即不同的原始结果在取模后得到相同的结果)。保持结果的正确性:即便是在中间步骤,数值也可能因为过大而失去精度或溢出。通过及时取模,可以确保每一步的计算都是精确的,从而保证最终结果的正确性。
在
factorial函数中使用res %= MOD;是为了在计算过程中不断地将中间结果对MOD取模,这样做可以确保:
无论阶乘计算进行到哪一步,
res的值都不会超过MOD定义的范围。最终的计算结果满足题目对结果数值范围的要求,避免在程序运行过程中出现整数溢出的错误。
hw机试【其他】
HJ108 最小公倍数
package hw;import java.util.Scanner;/*** 正整数A和正整数B 的最小公倍数是指 能被A和B整除的最小的正整数值,设计一个算法,求输入A和B的最小公倍数。* A和B都大于等于1* 输入:* 5 7* 输出:* 35*/public class HJ108_最小公倍数 {/*** min初始化为最大值二者相乘* 取一个大的数,用i从0乘以;如果乘出来的数可以整除另一个小的数,则是最小公倍数*/public static void main(String[] args) {Scanner in = new Scanner(System.in);while (in.hasNextInt()){int a = in.nextInt();int b = in.nextInt();int c = getMin(a,b);System.out.println(c);}}private static int getMin(int a, int b){int big = a>b ? a : b;int small = a<b ? a : b;for(int i = 1;i <= small; i ++){int temp = big * i;if(temp % small == 0){return temp;}}return a*b;}}
HJ28 素数伴侣
质数和素数是同一个概念的两种不同叫法。在数学中,它们都指的是只有1和它本身两个正因数的大于1的自然数。换句话说,一个质数(或素数)是不能被除了1和它自己以外的任何正整数整除的数。例如,2、3、5、7、11等都是质数(或素数)。
匈牙利算法
匈牙利算法的核心思想是先到先得,能让就让。
图解展示(匈牙利算法): 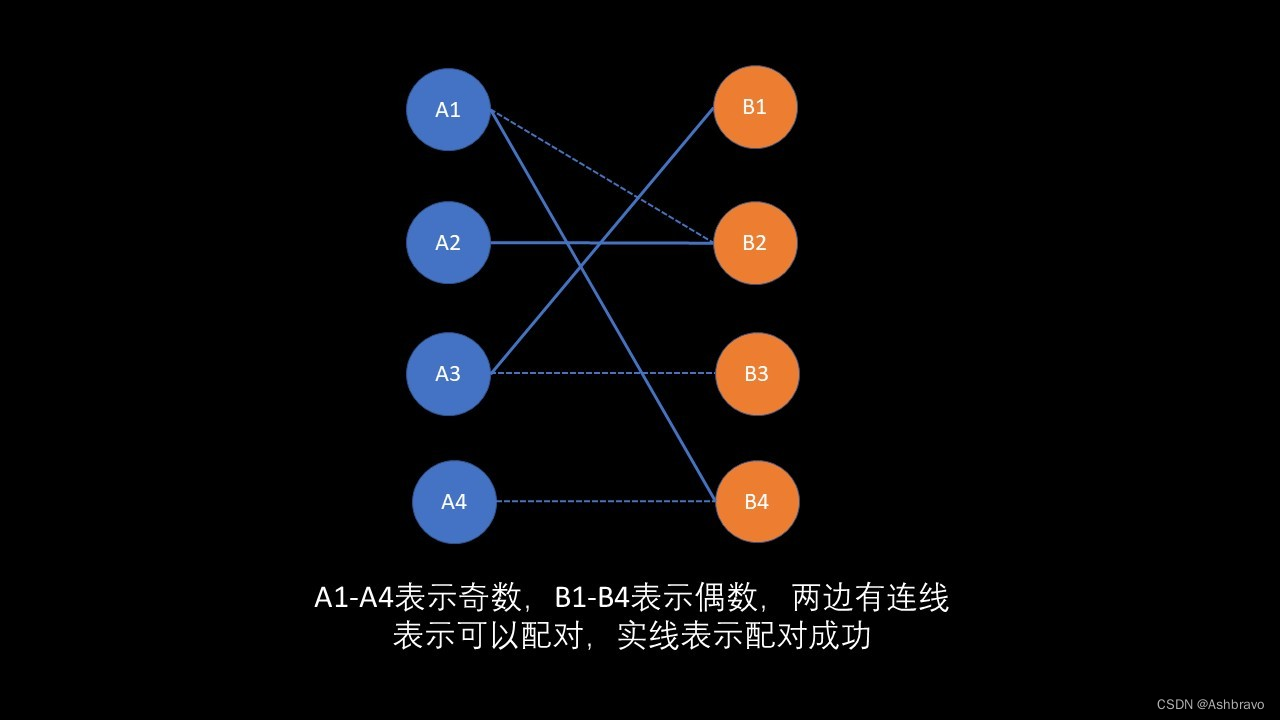
举例说明:如图所示,首先A1和B2配对(先到先得),然后轮到A2,A2也可以和B2配对,这时候B2发现A1还可以和B4配对,所以放弃了A1,选择和A2组成伴侣(能让就让)。接着A3直接和B1配对(先到先得)。最后A4尝试与B4配对,但是这样A1就只能与B2配对,而A2就找不到伴侣了,一层层递归下来,发现不可行,所以A4不能与B4配对。
假设在我们的舞会上,我们有三位女士(奇数号码)和三位男士(偶数号码),并且根据他们号码之和是否为素数,我们已经画出了可能的配对线。现在的挑战是,一位女士(比如说女士A)可能同时与两位男士(比如说男士X和男士Y)号码之和为素数,但是她在之前的配对中已经和男士X成为了舞伴。
现在,男士Y没有舞伴,我们希望看看能否通过一些“重新安排”,让男士Y也找到舞伴,同时不破坏已经形成的舞伴关系。
重新安排过程
检查现有配对:首先,我们发现女士A已经和男士X配对了,但男士Y也想和她配对。
寻找新的可能性:组织者查看女士A是否是男士X唯一可能的配对。如果不是,也就是说男士X还可以和其他女士(比如女士B)号码之和为素数,则我们可以尝试将男士X与女士B配对。
执行调换:如果女士B目前没有舞伴,那么就直接将她和男士X配对,然后男士Y可以和女士A配对。如果女士B已经有了舞伴(比如男士Z),我们就需要继续检查,看是否能为男士Z找到新的舞伴,以此类推。
确保每个人都有舞伴:这个过程一直持续,直到每个想要配对的男士都找到了舞伴,或者确认没有更多的配对方式。这个过程可能涉及到多次调换,但目标是最大化配对数量。
import java.util.*;/*** 若两个正整数的和为素数,则这两个正整数称之为“素数伴侣”,如2和5、6和13,它们能应用于通信加密。* 现在密码学会请你设计一个程序,从已有的 N ( N 为偶数)个正整数中挑选出若干对组成“素数伴侣”,挑选方案多种多样,* 例如有4个正整数:2,5,6,13,如果将5和6分为一组中只能得到一组“素数伴侣”,* 而将2和5、6和13编组将得到两组“素数伴侣”,能组成“素数伴侣”最多的方案称为“最佳方案”,* 当然密码学会希望你寻找出“最佳方案”。* 输入:* 有一个正偶数 n ,表示待挑选的自然数的个数。后面给出 n 个具体的数字。* 4* 2 5 6 13* 输出:* 输出一个整数 K ,表示你求得的“最佳方案”组成“素数伴侣”的对数。* 2*/public class Main {static int[] match; // 匹配关系static boolean[] used; // DFS中用于标记是否访问过static int[][] graph; // 表示图的邻接矩阵public static void main(String[] args) {Scanner scanner = new Scanner(System.in);while (scanner.hasNextInt()) {int n = scanner.nextInt();int[] nums = new int[n];for (int i = 0; i < n; i++) {nums[i] = scanner.nextInt();}// 将输入的数字分为奇数和偶数两组int[] evens = Arrays.stream(nums).filter(num -> num % 2 == 0).toArray();int[] odds = Arrays.stream(nums).filter(num -> num % 2 != 0).toArray();// 初始化图的邻接矩阵graph = new int[evens.length][odds.length];for (int i = 0; i < evens.length; i++) {for (int j = 0; j < odds.length; j++) {// 如果偶数和奇数之和为素数,则在图中添加一条边if (isPrime(evens[i] + odds[j])) {graph[i][j] = 1;}}}match = new int[odds.length];Arrays.fill(match, -1);int res = 0;for (int i = 0; i < evens.length; i++) {used = new boolean[odds.length];if (dfs(i)) res++;}System.out.println(res);}scanner.close();}// 判断一个数是否是素数public static boolean isPrime(int num) {if (num <= 1) return false;for (int i = 2; i * i <= num; i++) {if (num % i == 0) return false;}return true;}// 使用DFS进行匹配public static boolean dfs(int v) {for (int i = 0; i < graph[v].length; i++) {if (graph[v][i] == 1 && !used[i]) {used[i] = true;if (match[i] == -1 || dfs(match[i])) {match[i] = v;return true;}}}return false;}}注意细节
-
int[] evens = Arrays.stream(nums).filter(num -> num % 2 == 0).toArray(); -
Arrays.fill(match, -1); // 初始时,所有的奇数都未被匹配,使用-1表示。注意前面是Arrays -
先到先得,能让就让
-
used = new boolean[odds.length]; // 在每次尝试为一个偶数找匹配前,重置used数组。
-
for (int odd = 0; odd < graph[even].length; odd++) {注意,这里是 遍历graph[even]这一行的odd -
特别注意!!!
if(match[odd] == -1 || dfs(match[odd])){这里后面要搜索的是 当前odd已经匹配的even,做dfs
3.24
HJ60 查找组成一个偶数最接近的两个素数
-
找出小于n的素数
-
n/2 左右各一个数加和等于n
-
min
先找出所有素数再找中间
import java.util.*;import java.util.Scanner;public class Main {public static void main(String[] args) {// 使用Scanner获取控制台的输入Scanner in = new Scanner(System.in);// 持续读取输入直到没有下一个整数while (in.hasNextInt()){// 读取下一个整数,即题目中的偶数nint n = in.nextInt();// 创建一个布尔数组来标记小于n的每个整数是否为素数boolean[] isPrime = new boolean[n];// 默认将所有数标记为素数Arrays.fill(isPrime, true);// 0和1不是素数,手动设置为falseisPrime[0] = isPrime[1] = false;// 使用埃拉托斯特尼筛法筛选出小于n的所有素数for(int i = 2; i < n; i++){// 如果当前数字是素数if(isPrime[i]){// 将当前素数的所有倍数标记为非素数for(int j = i * i; j < n; j+=i){isPrime[j] = false;}}}// 将筛选出的素数存入ArrayList中ArrayList<Integer> prime = new ArrayList<>();for(int i = 0; i < n; i++){if(isPrime[i]){prime.add(i);}}// 调用getAdd方法找出和为n的两个素数,它们的差值最小int[] res = new int[2];res = getAdd(prime, res, n);// 输出这两个素数System.out.println(res[0]);System.out.println(res[1]);}}private static int[] getAdd(ArrayList<Integer> prime, int[] res, int n){// 找到接近n/2的素数对,因为这样差值最小int half = n/2;for(int i = 0; i < prime.size(); i++){// 当找到的素数大于等于n的一半时开始检查if(prime.get(i) >= half){// 向前查找配对的素数for(int j = i; j >= 0; j--){// 当两个素数之和等于n时,就找到了一对符合条件的素数if(prime.get(j) + prime.get(i) == n){// 将这对素数存入res数组并返回res[0] = prime.get(j);res[1] = prime.get(i);return res;}}}}return res; // 如果没有找到,则返回原数组}}
穷举法
import java.util.*;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);while (scanner.hasNext()){int num = scanner.nextInt();solution(num);}}private static void solution(int num) {int min = Integer.MAX_VALUE;int[] res = new int[2];// 从2开始穷举for(int i = 2; i < num; i++) {if(isPrime(i) && isPrime(num - i)) {// 保存最接近的两个素数if(Math.abs(num - i - i) < min) {res[0] = i;res[1] = num - i;min = Math.abs(num - i - i);}}}System.out.println(res[0] + "\n" + res[1]);}// 判断是否素数private static boolean isPrime(int num) {for(int i = 2; i <= Math.sqrt(num); i++) {if(num % i == 0) {return false;}} return true;}}
Leetcode994 腐烂的橘子
994. 腐烂的橘子 - 力扣(LeetCode)
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
-
值
0代表空单元格; -
值
1代表新鲜橘子; -
值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。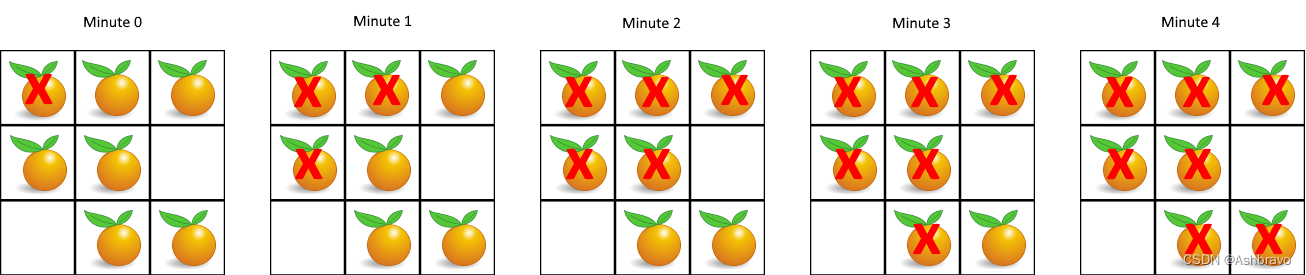
输入:grid = [[2,1,1],[1,1,0],[0,1,1]]输出:4
由题目我们可以知道每分钟每个腐烂的橘子都会使上下左右相邻的新鲜橘子腐烂,这其实是一个模拟广度优先搜索的过程。所谓广度优先搜索,就是从起点出发,每次都尝试访问同一层的节点,如果同一层都访问完了,再访问下一层,最后广度优先搜索找到的路径就是从起点开始的最短合法路径。
上下左右相邻的新鲜橘子就是该腐烂橘子尝试访问的同一层的节点,路径长度就是新鲜橘子被腐烂的时间。我们记录下每个新鲜橘子被腐烂的时间,最后如果单元格中没有新鲜橘子,腐烂所有新鲜橘子所必须经过的最小分钟数就是新鲜橘子被腐烂的时间的最大值。
多源广度优先搜索
观察到对于所有的腐烂橘子,其实它们在广度优先搜索上是等价于同一层的节点的。
假设这些腐烂橘子刚开始是新鲜的,而有一个腐烂橘子(我们令其为超级源点)会在下一秒把这些橘子都变腐烂,而这个腐烂橘子刚开始在的时间是 −1 ,那么按照广度优先搜索的算法,下一分钟也就是第 0 分钟的时候,这个腐烂橘子会把它们都变成腐烂橘子,然后继续向外拓展,所以其实这些腐烂橘子是同一层的节点。那么在广度优先搜索的时候,我们将这些腐烂橘子都放进队列里进行广度优先搜索即可,最后每个新鲜橘子被腐烂的最短时间 dis[x][y]其实是以这个超级源点的腐烂橘子为起点的广度优先搜索得到的结果。
为了确认是否所有新鲜橘子都被腐烂,可以记录一个变量 cnt 表示当前网格中的新鲜橘子数,广度优先搜索的时候如果有新鲜橘子被腐烂,则 cnt-=1 ,最后搜索结束时如果 cnt 大于 0 ,说明有新鲜橘子没被腐烂,返回 −1 ,否则返回所有新鲜橘子被腐烂的时间的最大值即可,也可以在广度优先搜索的过程中把已腐烂的新鲜橘子的值由 1 改为 2,最后看网格中是否由值为 1 即新鲜的橘子即可。
class Solution {// 定义四个方向移动的数组,分别对应上、左、下、右int[] dr = new int[]{-1, 0, 1, 0};int[] dc = new int[]{0, -1, 0, 1};public int orangesRotting(int[][] grid) {int R = grid.length; // 网格的行数int C = grid[0].length; // 网格的列数Queue<Integer> queue = new ArrayDeque<Integer>(); // 使用队列存储腐烂橘子的位置,以整数编码的形式Map<Integer, Integer> depth = new HashMap<Integer, Integer>(); // 存储每个腐烂橘子到其原始位置的“深度”或时间// 遍历整个网格,找到所有一开始就是腐烂的橘子,并将它们添加到队列中for (int r = 0; r < R; ++r) {for (int c = 0; c < C; ++c) {if (grid[r][c] == 2) {int code = r * C + c; // 通过行列计算出唯一编码queue.add(code); // 将腐烂橘子的位置加入队列depth.put(code, 0); // 腐烂橘子的初始深度为0}}}int ans = 0; // 存储最终结果,即所有橘子腐烂所需的最少时间// 执行广度优先搜索while (!queue.isEmpty()) {int code = queue.remove(); // 取出一个腐烂橘子的位置编码int r = code / C, c = code % C; // 通过编码还原行列位置for (int k = 0; k < 4; ++k) { // 遍历四个方向int nr = r + dr[k]; // 新的行位置int nc = c + dc[k]; // 新的列位置// 如果新位置有效并且有新鲜橘子if (0 <= nr && nr < R && 0 <= nc && nc < C && grid[nr][nc] == 1) {grid[nr][nc] = 2; // 将新鲜橘子变为腐烂int ncode = nr * C + nc; // 计算新腐烂橘子的编码queue.add(ncode); // 将新腐烂的橘子加入队列depth.put(ncode, depth.get(code) + 1); // 更新深度信息ans = depth.get(ncode); // 更新所需的最少时间}}}// 检查是否还有新鲜的橘子,如果有,返回-1for (int[] row : grid) {for (int v : row) {if (v == 1) {return -1;}}}return ans; // 返回所有橘子腐烂所需的最少时间}}
广度优先搜索(易懂)
import java.util.LinkedList;import java.util.Queue;public class Solution {public int orangesRotting(int[][] grid) {int M = grid.length; // 网格的行数int N = grid[0].length; // 网格的列数Queue<int[]> queue = new LinkedList<>(); // 使用队列存储腐烂橘子的位置int count = 0; // count用于记录新鲜橘子的数量// 遍历网格,初始化腐烂橘子的队列和新鲜橘子的数量for (int r = 0; r < M; r++) {for (int c = 0; c < N; c++) {if (grid[r][c] == 1) { // 如果是新鲜橘子,计数加一count++;} else if (grid[r][c] == 2) { // 如果是腐烂橘子,加入队列queue.add(new int[]{r, c});}}}int round = 0; // round用于记录传播腐烂所需的轮数,即分钟数// 当还有新鲜橘子且队列中有腐烂橘子时,执行BFSwhile (count > 0 && !queue.isEmpty()) {round++; // 开始新的一轮传播int n = queue.size(); // 当前轮次中腐烂橘子的数量// 对当前所有腐烂橘子进行遍历,让它们传播腐烂for (int i = 0; i < n; i++) {int[] orange = queue.poll(); // 取出一个腐烂橘子int r = orange[0];int c = orange[1];// 尝试向四个方向传播腐烂,如果有新鲜橘子则让它腐烂并加入队列if (r-1 >= 0 && grid[r-1][c] == 1) {grid[r-1][c] = 2;count--;queue.add(new int[]{r-1, c});}if (r+1 < M && grid[r+1][c] == 1) {grid[r+1][c] = 2;count--;queue.add(new int[]{r+1, c});}if (c-1 >= 0 && grid[r][c-1] == 1) {grid[r][c-1] = 2;count--;queue.add(new int[]{r, c-1});}if (c+1 < N && grid[r][c+1] == 1) {grid[r][c+1] = 2;count--;queue.add(new int[]{r, c+1});}}}// 如果还有新鲜的橘子剩下,说明不是所有的橘子都能被腐烂,返回-1if (count > 0) {return -1;} else {// 否则,返回传播腐烂所需的总轮数(分钟数)return round;}}public static void main(String[] args) {Solution solution = new Solution();// 示例网格初始化int[][] grid = {{2,1,1},{1,1,0},{0,1,1}};// 调用方法并打印结果int result = solution.orangesRotting(grid);System.out.println("所有橘子变腐烂所需的最少分钟数: " + result);}}Leetcode204 计数质数
给定整数 n ,返回 所有小于非负整数 n 的质数的数量 。
-
不能缺少
// 这里使用了(long)来避免整数溢出的情况 if ((long) i * i < n) { -
求小于n的质数数量,就定义prime[n],直接prime[i]就是i这个数是否是质数
class Solution {public int countPrimes(int n) {// 声明并初始化一个布尔数组,长度为n。数组中的每个元素表示对应的索引数是否为质数。// 默认情况下,我们将所有数初始化为质数(true)。boolean[] prime = new boolean[n];Arrays.fill(prime, true);// 用于计数质数的变量。int res = 0;// 遍历从2开始到n的每个数,因为1不是质数。for(int i = 2; i < n; i++){// 如果当前的数被认为是质数(即,prime[i]为true)。if(prime[i]){// 增加质数的计数。res += 1;// 检查 i*i 是否小于n,避免整数溢出。如果 i*i 已经超过了n,就不需要进一步标记它的倍数了。// 这是因为如果 i*i 超过了 n,它的倍数也一定超过了 n。if((long) i * i < n){// 从i*i开始(因为小于i*i的倍数在之前已经被标记过了),标记i的所有倍数为非质数(false)。for(int j = i * i; j < n; j += i){prime[j] = false;}}}}// 返回计数的质数数量。return res;}}
HJ25 数据分类处理
数据分类处理牛客题霸牛客网 (nowcoder.com)
使用字符串
-
String iStr = String.valueOf(I[j]); -
if(iStr.contains(rStr)){ -
// 使用TreeSet而不是HashSet来保证元素的唯一性和排序 TreeSet<Integer> r_set = new TreeSet<>(Arrays.asList(R));
import java.util.*;/*** 信息社会,有海量的数据需要分析处理,比如公安局分析身份证号码、 QQ 用户、手机号码、银行帐号等信息及活动记录。* 采集输入大数据和分类规则,通过大数据分类处理程序,将大数据分类输出。* 从R依次中取出R<i>,对I进行处理,找到满足条件的I:* I整数对应的数字需要连续包含R<i>对应的数字。比如R<i>为23,I为231,那么I包含了R<i>,条件满足 。* 按R<i>从小到大的顺序:* (1)先输出R<i>;* (2)再输出满足条件的I的个数;* (3)然后输出满足条件的I在I序列中的位置索引(从0开始);* (4)最后再输出I。* 附加条件:* (1)R<i>需要从小到大排序。相同的R<i>只需要输出索引小的以及满足条件的I,索引大的需要过滤掉* (2)如果没有满足条件的I,对应的R<i>不用输出* (3)最后需要在输出序列的第一个整数位置记录后续整数序列的个数(不包含“个数”本身)* 输入:* 15 123 456 786 453 46 7 5 3 665 453456 745 456 786 453 123* 5 6 3 6 3 0* 输出:* 30 3 6 0 123 3 453 7 3 9 453456 13 453 14 123 6 7 1 456 2 786 4 46 8 665 9 453456 11 456 12 786* 说明:* 将序列R:5,6,3,6,3,0(第一个5表明后续有5个整数)排序去重后,可得0,3,6。* 序列I没有包含0的元素。* 序列I中包含3的元素有:I[0]的值为123、I[3]的值为453、I[7]的值为3、I[9]的值为453456、I[13]的值为453、I[14]的值为123。* 序列I中包含6的元素有:I[1]的值为456、I[2]的值为786、I[4]的值为46、I[8]的值为665、I[9]的值为453456、I[11]的值为456、I[12]的值为786。* 最后按题目要求的格式进行输出即可。*/public class Main {public static void main(String[] args) {Scanner in = new Scanner(System.in);while (in.hasNextInt()){int nums_i = in.nextInt();int[] I = new int[nums_i];for (int i = 0; i < nums_i; i++){I[i] = in.nextInt();}int nums_r = in.nextInt();Integer[] R = new Integer[nums_r];for(int i = 0; i < nums_r; i++){R[i] = in.nextInt();}// 使用TreeSet而不是HashSet来保证元素的唯一性和排序TreeSet<Integer> r_set = new TreeSet<>(Arrays.asList(R));ArrayList<Integer> results = new ArrayList<>();for(int r : r_set){String rStr = String.valueOf(r);ArrayList<Integer> temp = new ArrayList<>();for(int j = 0; j < I.length; j++){String iStr = String.valueOf(I[j]);if(iStr.contains(rStr)){temp.add(j); // 索引temp.add(I[j]); // 值}}// 如果找到匹配的Iif(!temp.isEmpty()){results.add(r); // R的值results.add(temp.size() / 2); // 匹配的I的数量results.addAll(temp); // 添加匹配的索引和值}}// 输出结果System.out.print(results.size() + " ");for(int i = 0; i < results.size(); i++){System.out.print(results.get(i));if (i < results.size() - 1) {System.out.print(" ");}}}}}
R若只一位直接算
最好还是用字符串比较简洁
import javax.print.DocFlavor;import java.util.*;/*** 信息社会,有海量的数据需要分析处理,比如公安局分析身份证号码、 QQ 用户、手机号码、银行帐号等信息及活动记录。* 采集输入大数据和分类规则,通过大数据分类处理程序,将大数据分类输出。* 从R依次中取出R<i>,对I进行处理,找到满足条件的I:* I整数对应的数字需要连续包含R<i>对应的数字。比如R<i>为23,I为231,那么I包含了R<i>,条件满足 。* 按R<i>从小到大的顺序:* (1)先输出R<i>;* (2)再输出满足条件的I的个数;* (3)然后输出满足条件的I在I序列中的位置索引(从0开始);* (4)最后再输出I。* 附加条件:* (1)R<i>需要从小到大排序。相同的R<i>只需要输出索引小的以及满足条件的I,索引大的需要过滤掉* (2)如果没有满足条件的I,对应的R<i>不用输出* (3)最后需要在输出序列的第一个整数位置记录后续整数序列的个数(不包含“个数”本身)* 输入:* 15 123 456 786 453 46 7 5 3 665 453456 745 456 786 453 123* 5 6 3 6 3 0* 输出:* 30 3 6 0 123 3 453 7 3 9 453456 13 453 14 123 6 7 1 456 2 786 4 46 8 665 9 453456 11 456 12 786* 说明:* 将序列R:5,6,3,6,3,0(第一个5表明后续有5个整数)排序去重后,可得0,3,6。* 序列I没有包含0的元素。* 序列I中包含3的元素有:I[0]的值为123、I[3]的值为453、I[7]的值为3、I[9]的值为453456、I[13]的值为453、I[14]的值为123。* 序列I中包含6的元素有:I[1]的值为456、I[2]的值为786、I[4]的值为46、I[8]的值为665、I[9]的值为453456、I[11]的值为456、I[12]的值为786。* 最后按题目要求的格式进行输出即可。*/public class Main {public static void main(String[] args) {Scanner in = new Scanner(System.in);while (in.hasNextInt()){int nums_i = in.nextInt();int[] I = new int[nums_i];for (int i = 0; i < nums_i; i++){I[i] = in.nextInt();}int nums_r = in.nextInt();int[] R = new int[nums_r];for(int i = 0; i < nums_r; i++){R[i] = in.nextInt();}Set<Integer> r_set = new HashSet<>();Arrays.sort(R);for(int i: R){r_set.add(i);}ArrayList<Integer> resCur = new ArrayList<>();for(int i : r_set){ArrayList<Integer> temp = new ArrayList<>();for(int j = 0; j < I.length; j++){int value_j = I[j];while(value_j > 0){int num = value_j % 10;if(num == i){temp.add(j);temp.add(I[j]);break;}value_j /= 10;}}if(temp.size() > 0){resCur.add(i);int curSize = temp.size();resCur.add(curSize / 2);resCur.addAll(temp);}}StringBuilder res_out = new StringBuilder();int count_rex = resCur.size();res_out.append(count_rex + " ");for(int n: resCur){res_out.append(n + " ");}System.out.println(res_out.substring(0,res_out.length()-1));}}}
贪心算法
监控二叉树
代码随想录 (programmercarl.com)
给定一个二叉树,我们在树的节点上安装摄像头。
节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。
计算监控树的所有节点所需的最小摄像头数量。
要从下往上看,局部最优:让叶子节点的父节点安摄像头,所用摄像头最少,整体最优:全部摄像头数量所用最少!
来看看这个状态应该如何转移,先来看看每个节点可能有几种状态:
有如下三种:
-
该节点无覆盖
-
本节点有摄像头
-
本节点有覆盖
我们分别有三个数字来表示:
-
0:该节点无覆盖
-
1:本节点有摄像头
-
2:本节点有覆盖
因为在遍历树的过程中,就会遇到空节点,那么问题来了,空节点究竟是哪一种状态呢? 空节点表示无覆盖? 表示有摄像头?还是有覆盖呢?
回归本质,为了让摄像头数量最少,我们要尽量让叶子节点的父节点安装摄像头,这样才能摄像头的数量最少。
那么空节点不能是无覆盖的状态,这样叶子节点就要放摄像头了,空节点也不能是有摄像头的状态,这样叶子节点的父节点就没有必要放摄像头了,而是可以把摄像头放在叶子节点的爷爷节点上。
所以空节点的状态只能是有覆盖,这样就可以在叶子节点的父节点放摄像头了【状态2】
主要有如下四类情况:
-
情况1:左右节点都有覆盖
左孩子有覆盖,右孩子有覆盖,那么此时中间节点应该就是无覆盖的状态了。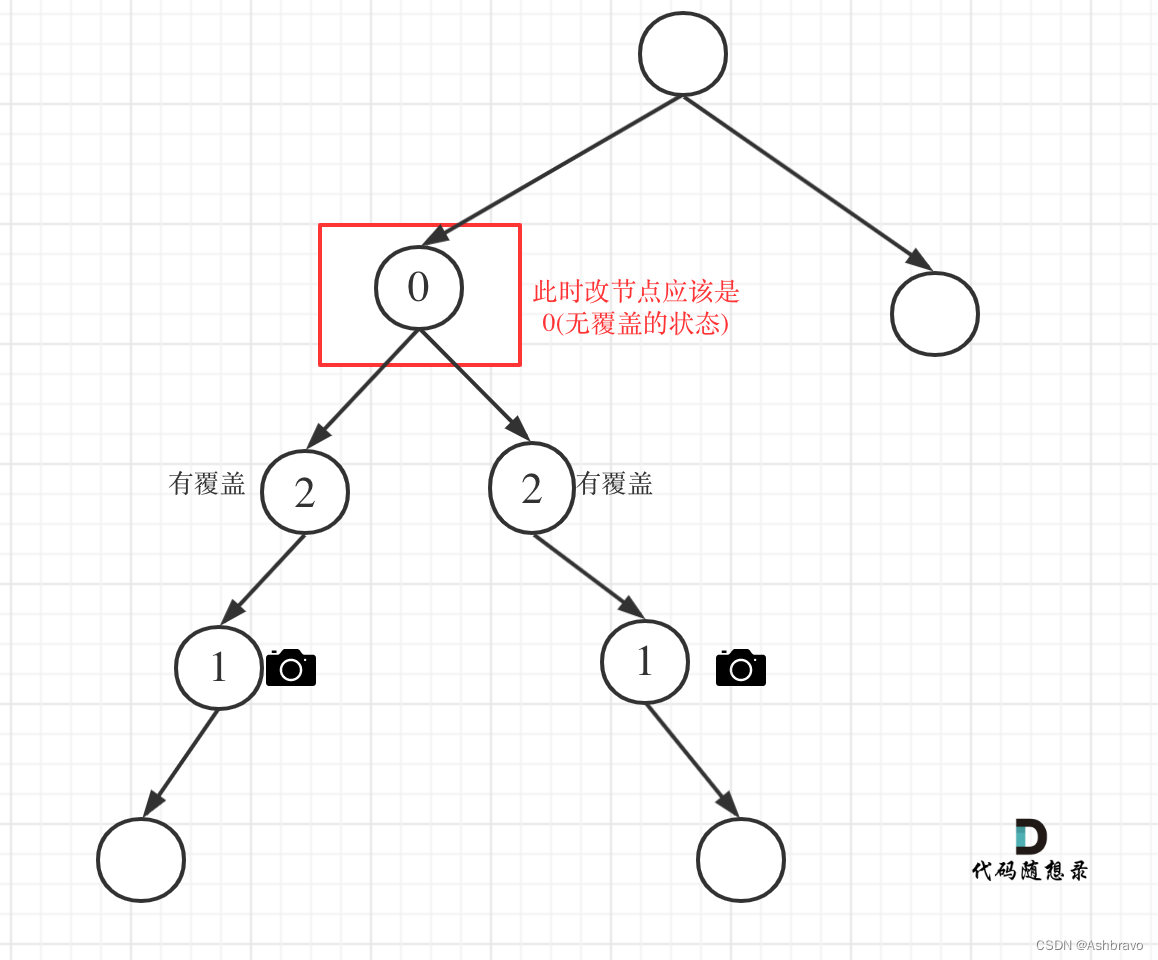
-
情况2:左右节点至少有一个无覆盖的情况
如果是以下情况,则中间节点(父节点)应该放摄像头
-
情况3:左右节点至少有一个有摄像头
如果是以下情况,其实就是 左右孩子节点有一个有摄像头了,那么其父节点就应该是2(覆盖的状态)
-
情况4:头结点没有覆盖
递归结束之后,可能头结点 还有一个无覆盖的情况:
本题的难点首先是要想到贪心的思路,然后就是遍历和状态推导。
在二叉树上进行状态推导,其实难度就上了一个台阶了,需要对二叉树的操作非常娴熟。
-
private int res = 0; // 将res定义为成员变量不要写成static静态变量的值在方法调用之间是持久化的。这意味着如果
minCameraCover方法被多次调用,res的值不会自动重置,导致每次调用的结果都会在上一次调用的基础上增加。-
存储位置:
-
静态变量:存储在类的方法区内,是类级别的变量。对于类的所有实例来说,静态变量只有一份拷贝,被类的所有实例共享。
-
成员变量:存储在堆内存中,每个对象有自己的一份拷贝。成员变量是对象级别的,每创建一个新的对象,都会为成员变量分配新的内存空间。
-
访问方式:
-
静态变量:可以直接通过类名访问(
类名.静态变量名),也可以通过类的对象来访问,但推荐直接通过类名访问。 -
成员变量:只能通过类的实例对象访问(
对象名.成员变量名)。
-
生命周期:
-
静态变量:随着类的加载而加载,随着类的消失而消失。其生命周期较长,通常伴随着程序的运行而存在。
-
成员变量:随着对象的创建而存在,随着对象的被回收而消失。其生命周期取决于对象的生命周期。
-
初始值:
-
静态变量和成员变量在没有明确初始化时,都有默认值。例如,整型的默认值是0,引用类型的默认值是null。但是静态变量的初始化时机和成员变量不同,静态变量在类加载时初始化。
-
用途:
-
静态变量:适用于那些无论创建多少对象,都需要共享的数据,如公司名称、配置信息等。
-
成员变量:适用于每个对象都需要有自己的一份拷贝的属性,如学生的姓名、账户的余额等。
-
-
private int minCame(TreeNode root){不能写成static因为在静态方法中不能直接访问非静态成员变量
res。静态方法是属于类的,而非静态成员变量是属于类的实例的。这意味着静态方法被调用时可能不存在任何类的实例,因此它不能直接访问属于实例的变量。如果你试图在
minCame方法中访问非静态成员变量res,编译器将报错,因为这是不允许的。解决这个问题的一种方式是将res也定义为static,但这通常不是推荐的解决方案,尤其是在这种情况下,因为这会导致res变成全局状态,这在多个实例间共享或者在递归调用中可能会引起意料之外的行为。为了解决这个问题,你可以保持
res作为非静态成员变量,并将minCame(TreeNode root)方法也定义为非静态方法。这样,minCame就能自然地访问和修改res了,而不会违反静态和非静态内容的访问规则。这也意味着minCameraCover方法在调用minCame时,是在同一个实例的上下文中进行的,保持了状态的封装性和实例的独立性。总之,不能将
minCame(TreeNode root)定义为static的原因是因为它需要访问类的非静态成员变量res。在静态方法中访问非静态成员变量是不允许的,因为静态方法不依赖于类的任何特定实例,而非静态成员变量则是实例级别的。
class Solution {int res=0;public int minCameraCover(TreeNode root) {// 对根节点的状态做检验,防止根节点是无覆盖状态 .if(minCame(root)==0){res++;}return res;}/**节点的状态值:0 表示无覆盖1 表示 有摄像头2 表示有覆盖后序遍历,根据左右节点的情况,来判读 自己的状态*/public int minCame(TreeNode root){if(root==null){// 空节点默认为 有覆盖状态,避免在叶子节点上放摄像头return 2;}int left=minCame(root.left);int right=minCame(root.right);// 如果左右节点都覆盖了的话, 那么本节点的状态就应该是无覆盖,没有摄像头if(left==2&&right==2){//(2,2)return 0;}else if(left==0||right==0){// 左右节点都是无覆盖状态,那 根节点此时应该放一个摄像头// (0,0) (0,1) (0,2) (1,0) (2,0)// 状态值为 1 摄像头数 ++;res++;return 1;}else{// 左右节点的 状态为 (1,1) (1,2) (2,1) 也就是左右节点至少存在 1个摄像头,// 那么本节点就是处于被覆盖状态return 2;}}}
动态规划
最长回文子序列
给定一个字符串 s ,找到其中最长的回文子序列,并返回该序列的长度。可以假设 s 的最大长度为 1000 。
示例 1: 输入: "bbbab" 输出: 4 一个可能的最长回文子序列为 "bbbb"。
示例 2: 输入:"cbbd" 输出: 2 一个可能的最长回文子序列为 "bb"。
回文子串是要连续的,回文子序列可不是连续的!
动规五部曲分析如下:
-
确定dp数组(dp table)以及下标的含义
dpi:字符串s在[i, j]范围内最长的回文子序列的长度为dpi。
-
确定递推公式
在判断回文子串的题目中,关键逻辑就是看s[i]与s[j]是否相同。
s[i]与s[j]相同,那么 dp[i][j] = dp[i + 1][j - 1] + 2;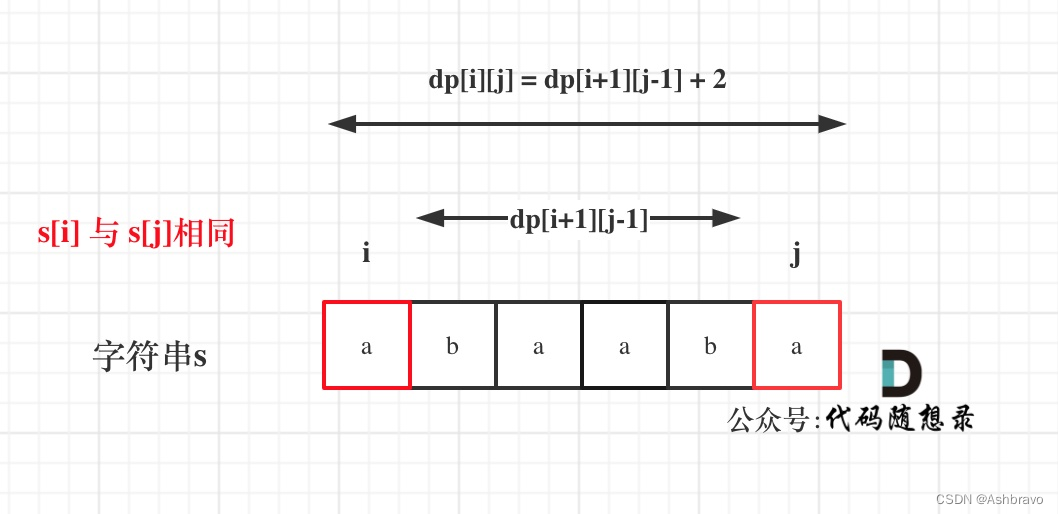
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入 并不能增加[i,j]区间回文子序列的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
加入s[j]的回文子序列长度为 dp[i + 1][j]。
加入s[i]的回文子序列长度为 dp[i][j - 1]。
那么dp[i][j]一定是取最大的,即:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);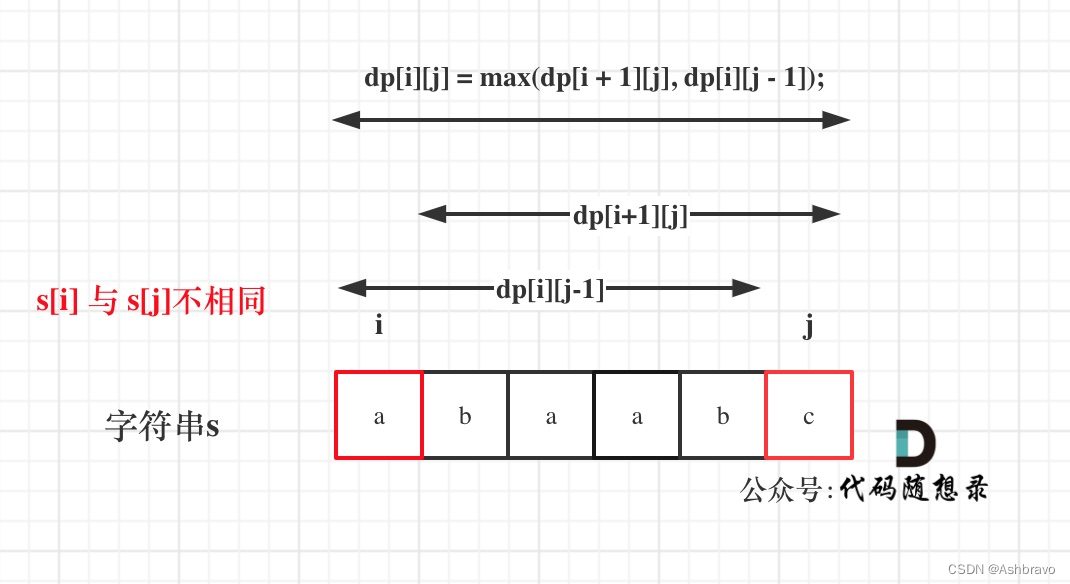
-
dp数组如何初始化
首先要考虑当i 和j 相同的情况,从递推公式:dp[i][j] = dp[i + 1][j - 1] + 2; 可以看出 递推公式是计算不到 i 和j相同时候的情况。
所以需要手动初始化一下,当i与j相同,那么dp[i][j]一定是等于1的,即:一个字符的回文子序列长度就是1。
其他情况dp[i][j]初始为0就行,这样递推公式:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); 中dp[i][j]才不会被初始值覆盖。
-
确定遍历顺序
从递归公式中,可以看出,dp[i][j] 依赖于 dp[i + 1][j - 1] ,dp[i + 1][j] 和 dp[i][j - 1],如图: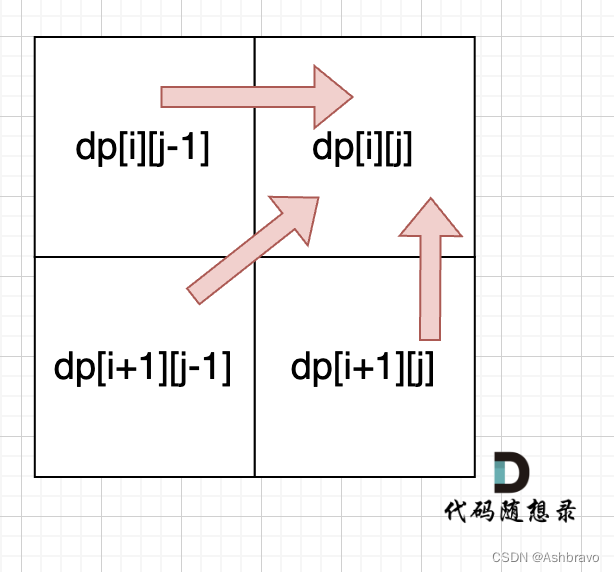
所以遍历 i 的时候一定要从下到上遍历,这样才能保证下一行的数据是经过计算的。
j 的话,可以正常从左向右遍历。
-
举例推导dp数组
输入s:"cbbd" 为例,dp数组状态如图: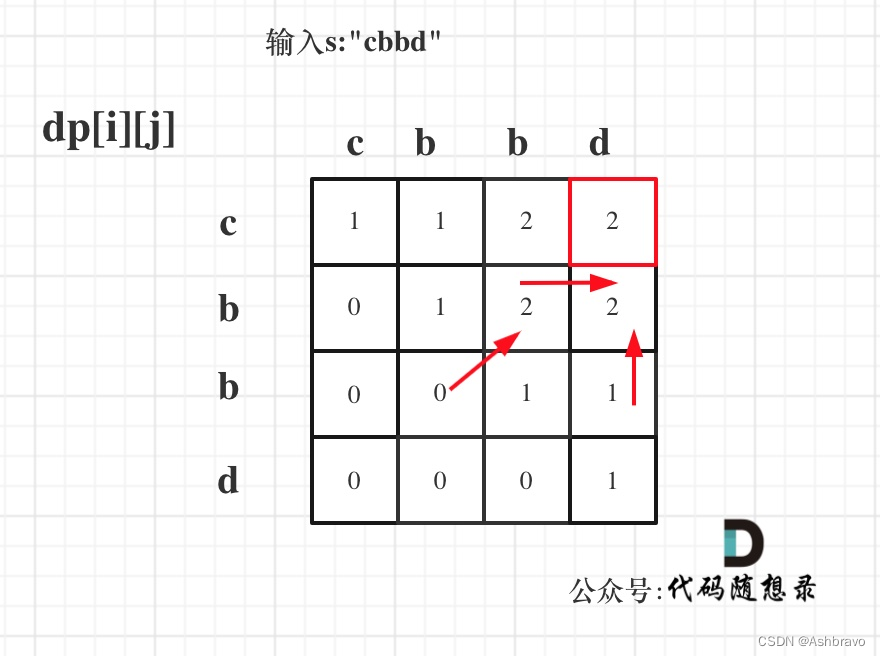
红色框即:dp[0][s.size() - 1]; 为最终结果。
class Solution {public int longestPalindromeSubseq(String s) {// 获取字符串长度int len = s.length();// dp数组用于存储子问题的解,dp[i][j]表示字符串s在[i, j]区间的最长回文子序列长度int[][] dp = new int[len+1][len+1];// 从字符串末尾开始向前遍历,这样可以保证计算dp[i][j]时,dp[i+1][j-1]已被计算for(int i = len-1; i >= 0; i--){// 单个字符也是回文,长度为1dp[i][i] = 1;// 从当前字符开始,向后遍历,寻找以i开始的最长回文子序列for(int j = i + 1; j < len; j++){// 如果两端字符相同,那么最长回文子序列长度为中间部分的最长回文子序列长度加2if(s.charAt(i) == s.charAt(j)){dp[i][j] = dp[i+1][j-1] + 2;}else{// 如果两端字符不同,那么最长回文子序列长度为去掉一个字符(左边或右边)后的最长回文子序列长度的较大值// 注意这里的dp[i][j] = Math.max(dp[i][j], Math.max(dp[i+1][j], dp[i][j-1]))中,// dp[i][j] = Math.max(dp[i][j],...)是多余的,因为dp[i][j]初始值为0,这里应该直接是dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1])dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1]);}}}// 返回整个字符串的最长回文子序列长度return dp[0][len - 1];}}动态规划原理解释
动态规划解决问题的思想是将大问题拆解成小问题,先解决小问题,再逐步解决大问题。在这个问题中,小问题是求字符串
s任意子串[i, j]的最长回文子序列长度。
Base Case:当子串长度为1(即
i == j)时,最长回文子序列长度为1,因为每个单独的字符都是一个回文子序列。Transition:状态转移方程分两种情况:
当
s[i] == s[j]时,说明当前两端字符可以成为最长回文子序列的一部分,所以在它们中间子串[i+1, j-1]的基础上加2。当
s[i] != s[j]时,最长回文子序列要么在子串[i+1, j]中,要么在子串[i, j-1]中,取这两者的最大值。通过这种方式,
dp[0][len - 1]最终存储的是整个字符串s的最长回文子序列长度。
这个问题的核心在于理解动态规划求解回文子序列长度的过程。在这种情况下,使用自底向上的方法来填充动态规划表
dp是非常关键的。我们从字符串的末尾开始向前遍历,因为在计算动态规划表dp[i][j](表示从索引i到j的子字符串的最长回文子序列的长度)的过程中,我们依赖于已经计算出的值:dp[i+1][j-1]、dp[i+1][j]和dp[i][j-1]。下面是详细的解释:动态规划表的依赖关系
dp[i+1][j-1]:代表子字符串s(i+1)到s(j-1)的最长回文子序列的长度。如果s[i]和s[j]相等,那么它们可以形成回文的两端,因此dp[i][j]就等于dp[i+1][j-1]加上这两端的2个字符。
dp[i+1][j]和dp[i][j-1]:分别代表去掉开始字符和结束字符后的子字符串的最长回文子序列的长度。这两个值用于处理s[i]和s[j]不相等的情况,此时dp[i][j]应该等于这两个值中的最大值。自底向上的遍历
从字符串末尾开始向前遍历可以确保在计算
dp[i][j]时,dp[i+1][j-1]、dp[i+1][j]和dp[i][j-1]这三个依赖的值已经被计算出来了。这是因为动态规划表是从下往上、从左到右填充的,所以任何时候计算dp[i][j]时,其依赖的状态都已经解决了。
动态规划状态的依赖关系
在最长回文子序列问题中,我们使用二维DP数组
dp[i][j]表示字符串从索引i到索引j(包含i和j)的子字符串的最长回文子序列的长度。这里的关键点在于理解dp[i][j]依赖于哪些状态:
dp[i+1][j-1]:表示去除当前考虑的子字符串的首尾字符后的最长回文子序列长度。
dp[i+1][j]和dp[i][j-1]:分别表示去除首字符或尾字符后的最长回文子序列长度。从后向前遍历的直观理解
当我们从后向前遍历字符串时(即从字符串的尾部开始向头部遍历),我们是从较短的子字符串向较长的子字符串扩展。
初始化状态:最初,我们知道所有单个字符的子字符串都是回文,长度为1,这是我们的基础情况。
向前扩展:当我们计算
dp[i][j]时,我们实际上是在查看更短的子字符串(即dp[i+1][j-1]、dp[i+1][j]、dp[i][j-1]),这些子字符串的最长回文子序列已经在之前的步骤中被计算过了。从前向后遍历的问题
当尝试从前向后遍历字符串时,我们是从较长的子字符串向较短的子字符串退化,这似乎与直觉相反。为什么这种方式会遇到问题呢?
状态未就绪:在计算
dp[i][j]的过程中,我们需要已知的状态(如dp[i+1][j-1])尚未被计算。这是因为我们还没有向下走到子字符串的处理过程中,这些子字符串的处理是建立在当前字符串的基础上的。