文章目录
- urllib
- urllib.request.urlretrieve
- urllib3 in python3
- PoolManager
- Request
- BeautifulSoup
- 安装 Installation
- 一些函数 Some functions
- get_text
- find_all(name, attrs, recursive, string, limit, **kwargs)
- name - 通过标签名搜索
- kwargs - keyword arguments 关键字参数进行搜索
- CSS class - 通过CSS类进行搜索
- string
- limit - 设置limit参数设置匹配的数量限制
- recursive - 设置recursive参数决定是否进行迭代
- 爬虫程序
- 确定CSS类
- 检查元素复制html文档
-> 使用 Selenium 模拟浏览器操作
urllib
这是一个可以处理和读取url的python库
urllib.request.urlretrieve
函数原型:urlretrieve(url, filename = None, reporthook = None, data = None)
参数表:
| 参数 | 说明 |
|---|---|
| url | 我们所要请求的url地址,不能为空 |
| filename | 下载内容保存的文件,如果没有指明,会自动创建一个临时文件 |
| reporthook | 一个回调函数,我们可以传入一个回调函数,这个回调函数将会接收三个参数:第一个是当前已经传输的数据块的数目,第二个是数据块的大小,第三个是文件的总大小,可以通过这个回调函数在命令行中实现简单的下载进度条的显示 |
| data | 发送给服务器的数据 |
简单起见,我们将使用这个函数来下载图片
urllib3 in python3
PoolManager
如果你希望使用urllib3来进行一些请求操作,在这之前,我们必须创建一个PoolManager对象:
import urllib3http = urllib3.PoolManager()
Request
好了,现在我们有了这个对象,我们试着从某个网页上拉取数据,例如:中山大学官方网站:http://www.sysu.edu.cn/2012/cn/index.htm。这时我们用到PoolManager对象的request方法:
# initialize url
base_url = 'http://www.sysu.edu.cn'
relative_path = '2012/cn/index.htm'
url = base_url + relative_path
# pool
r = http.request('GET', url)
request方法会返回一个HTTPResponse对象,这个对象有三个属性(attributes):
- status
- data
- header
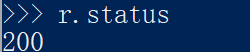
status
这个是请求的状态,200表示请求成功
data
这是我们需要的内容:html文件的文本

headers
这是请求响应报文的头部信息:

所以,通过HTTPResponse.data我们就可以得到网页文本了。接下来,我们要想办法从若干标签中找到我们要的图片标签中的图片地址,然后批量下载。
BeautifulSoup
BeautifulSoup是Python的bs4中的一个的库,在对网页的文档树进行处理上具有非常强大的功能,我们将运用BeautifulSoup来实现我们的网络爬虫程序。
安装 Installation
在命令行中输入:
pip install bs4
通过引入bs4中的BeautifulSoup,我们就可以使用它强大的功能了:
from bs4 import BeautifulSouphtml = 'some html'
# using BeautifulSoup parsing a html document tree
soup = BeautifulSoup(html, 'html_parser')
一些函数 Some functions
get_text
这个函数可以非常方便的获得标签(tag)中的内容,例如:
html = '<div><span>title</span></br><p> some paragrah</p></div>'
我们可以用get_text函数来获得标签内容:
soup = BeautifulSoup(html, 'html_parser')
print(soup.get_text())
最终将会返回一个string类型的结果并进行打印
find_all(name, attrs, recursive, string, limit, **kwargs)
我们经常需要遍历html页面文档树(Searching the tree)来寻找想要的内容,例如图片<img ...>,我们可以利用find_all函数来找到任何符合我们要求的标签以及内容。
name - 通过标签名搜索
这个参数可以制定我们要搜索的标签的名字(tag’s name),例如:
soup.find_all('title')
将会匹配所有的<title>标签
kwargs - keyword arguments 关键字参数进行搜索
这个参数的作用是:我们可以指定html标签的某个属性进行查找,例如当我们传入这样的参数:
images = soup.find_all(class_='rg_ic rg_i')
你会发现,我们传入的参数并不是find_all函数认识(recognize)的参数名,这时,find_all函数会把这个参数名当作html标签(tag)的一个属性(attribute)来进行过滤查找即:找到所有的class为rg_ic rg_i的标签。
假如你希望在一个王爷中找到某个链接,我们可以传入href属性:
soup.find_all(href='https://some-link')
查找某个元素:
soup.find_all(id='some-id')
可以指定任何我们感兴趣的标签属性来进行搜索。
CSS class - 通过CSS类进行搜索
在4.1.2中,如果你传入的参数是class的话,这时将会抛出错误,你必须使用class_作为关键字参数,例如:
soup.find_all(class_='some-class')
而很多时候,网页标签并不总是只有一个CSSclass,这时,任何一个拥有我们检索的class属性的标签都将被我们匹配到:
soup = BeautifulSoup('<img class="rg_ic rg_i" data-src="source">')soup.find_all(class_='rg_ic')soup.find_all(class_='rg_i')
这时,这个<img>标签都会被匹配到。当然,你也可以直接匹配这两个CSS类:
soup.find_all(class_='rg_ic rg_i')
仍然的,我们可以匹配到相同的<img>标签。但是如果字符串不同的话:
soup.find_all(class_='rg_i rg_ic')
将不会检索到相同的结果。
string
此外,我们还可以直接告诉BeautifulSoup我们想要搜索的内容,这时,我们可以利用string参数传入一个字符串,一个列表,一个正则表达式,甚至是一个函数来筛选我们想要的内容:
# 找到文档中所有的 'jade'
soup.find_all(string='jade')
# 找到文档中所有的列表中的内容
soup.find_all(string=['jade' 'jason'])
# 找到文档中包含'jade'的内容
soup.find_all(string=re.compile('jade'))
def is_the_only_string_with_a_tag(s):
# 满足子标签的内容和上层的标签的内容相同的内容,例如:
# <div><p>my dear jade</p></div>
# <div>和<p>这两个标签的内容相同return (s == s.parent.string)
# 找到所有标签的内容,这个标签满足其上层标签的内容依然和这个标签内容相同
soup.find_all(string=is_the_only_string_with_a_tag)
当然,你可以结合其他的参数一起使用,例如:
# 找到所有的内容为'jade'的<a>标签
soup.find_all('a', string='jade')
string参数名是BeautifulSoup在4.4.0中新的特性,在更早的版本中用的是text:
# 找到所有的内容为'jade'的<a>标签
soup.find_all('a', text='jade')
limit - 设置limit参数设置匹配的数量限制
例如:
soup = BeautifulSoup('<p>a</p><p>b</p><p>c</p>')
设置limit为2:
soup.find_all('p', limit = 2)
将之会得到前两个结果:
['<p>a</p>', '<p>b</p>']
recursive - 设置recursive参数决定是否进行迭代
例如:
soup = BeautifulSoup('\<html><head><title> some title </title></head><html>'\
, 'html_parser')
那么,下面的两中方式将会得到不同的结果:
soup.html.find_all('title')
# get ['<title>some title</title>']
soup.html.find_all('title', recursive=False)
# get nothing
爬虫程序
假如我们希望批量的从google images的搜索结果中大量下载相关的图片,这时如果我们手动进行点击下载将会是一个非常繁冗的任务。但是,有了上面的知识为基础,我们只需要简单的编写一个python爬虫程序就可以让计算机自动帮我们完成这个任务。
确定CSS类
既然我们希望下载的是图片,那么不必说,标签自然就是<img>了。那么我们唯一需要解决的问题就是:Google images的图片结果的CSS类是什么?因为除了搜索结果的图片之外,页面中还存在其他一些界面元素,比如一些UI图片,而这些并不是我们的目标。
很简单,首先打开页面源代码,Ctrl+F搜索标签<img,这样我们可以筛选出页面中的图片元素,然后,找到搜索结果集中的地方,可以看到:
alt属性的内容为““fire hydrant”图片的搜索结果”(假如我们要搜索下载消防栓的图片),alt标签的作用是:如果图片无法显示,将用该文本代替显示。所以我们知道了,这个就是我们的图片的搜索结果(你可能会很熟悉,当搜索图片没有刷出来的时候,显示的就是类似这样的文本,可以自己去尝试一下,当然,你也可以去探索更简单的能够检索到图片结果标签的办法)
这样我们就知道了:图片搜索结果的CSS类为class="rg_ic rg_i"
检查元素复制html文档
对于一些动态加载的页面来说,不同于静态网站,图片元素都是通过javascript生成的,所以我们在网页源代码里面看不到这些图片内容。
但是,我们可以通过检查元素来看到这些动态加载的元素:
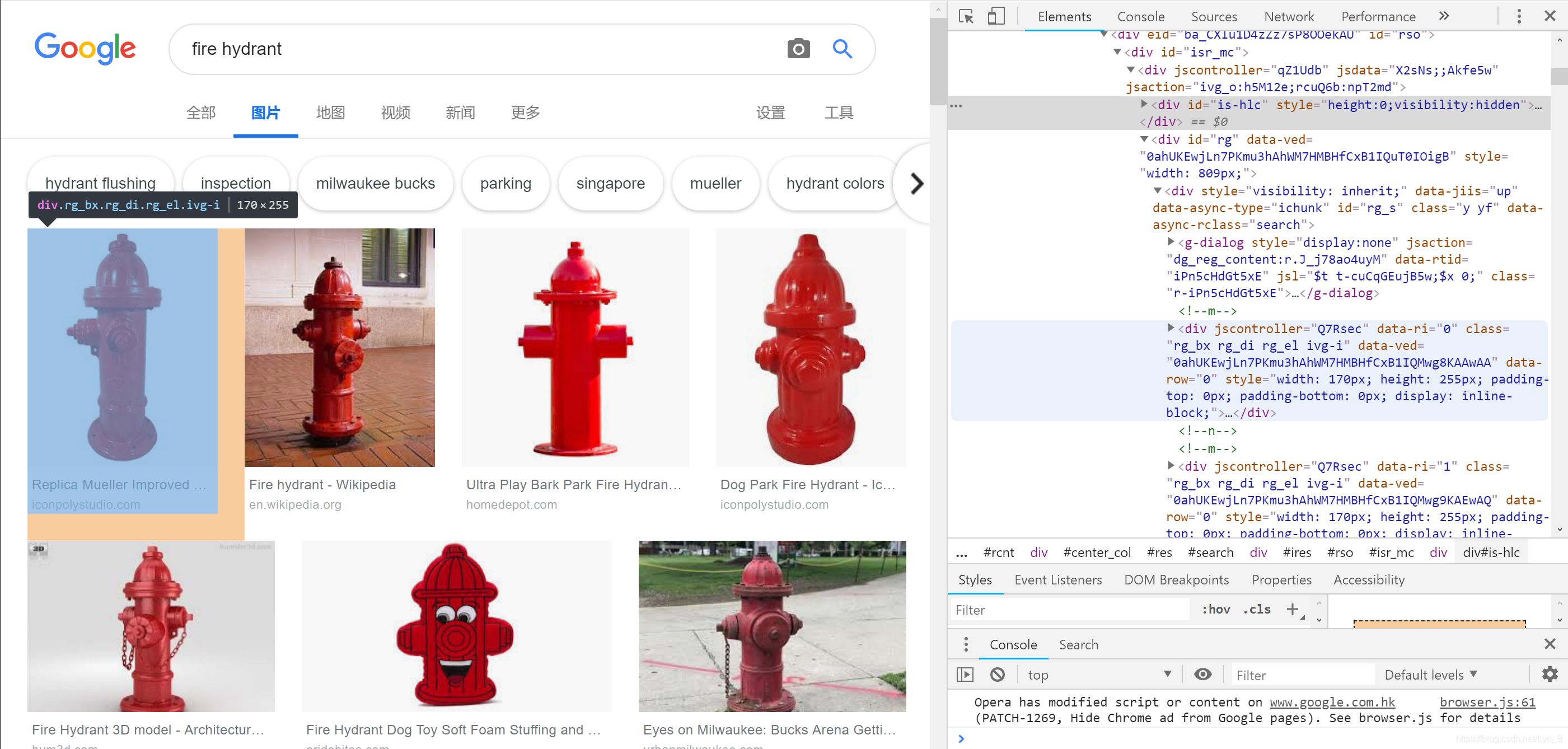
我们可以先在页面上将所有的图片下拉出来,然后再复制上一层元素的内容(包含所有的图片),保存在本地文档中,然后,我们就可以读取这个文档进行处理了。
当然还可以使用Selenium完成这个操作,这个库可以模拟我们的网页操作,这里是进一步的介绍
from bs4 import BeautifulSoup
import urllib
# import urllib3
import time
import os
import sys# report hook with three parameters passed
# count_of_blocks The number of blocks transferred
# block_size The size of block
# total_size Total size of the file
def progress_callback(count_of_blocks, block_size, total_size):# determine current progressprogress = int(50 * (count_of_blocks * block_size) / total_size)if progress > 50:progress = 50# update progress barsys.stdout.write("\r[%s%s] %d%%" % ('█' * progress, ' ' * (50 - progress), progress * 2))sys.stdout.flush()class Crawl:# called once we create a Crawl objectdef __init__(self):# self.url = base_url + message 我的锅# 这里改为我们初始化一个路径变量,为你本地的html文件的路径self.file_path = './your/path/to/your.html'# main functiondef crawl_images(self):# You can use urllib3 to get the html document, like:# http = urllib3.PoolManager()# html = http.request('Get', your_url).data# or copy then simply open the html document as we have shown abovehtml = open('./your/path/to/your.html', encoding='utf-8').read()# create a BeautifulSoup objectsoup = BeautifulSoup(html, 'html.parser')# find all the attributes of <img> with class 'rg_ic rg_i'# class_ instead of classimage_list = soup.findAll('img', class_='rg_ic rg_i')print('find total images: ' + str(len(image_list)))# make directory to store download imagesdir_ = './images'# check if there exists such a directoryif not os.path.exists(dir_):os.makedirs(dir_)# count for imagescount = 0for image in image_list:try:# image per secondtime.sleep(1)print('\ndownloading image ' + str(count) + ': ')# path to save the download imagepath = dir_ + '/image' + str(count) + '.png'# downloadurllib.request.urlretrieve(url = image['src'], filename = path, reporthook = progress_callback, data = None)count = count + 1except urllib.error.HTTPError as http_err:print(http_err)except Exception as err:print(err)def run(self):self.crawl_images()print('Complete!')if __name__ == '__main__':crawl = Crawl()crawl.run();
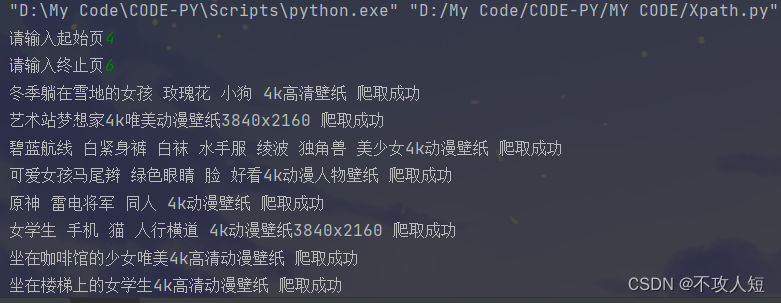
运行结果: